Azure Data Factory ve Synapse Analytics'te desteklenen dosya biçimleri ve sıkıştırma codec'leri (eski)
UYGULANANLAR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu makale şu bağlayıcılar için geçerlidir: Amazon S3, Azure Blob, Azure Data Lake Storage 1. Nesil, Azure Data Lake Storage 2. Nesil, Azure Dosyalar, Dosya Sistemi, FTP, Google Cloud Storage, HDFS, HTTP ve SFTP.
Önemli
Hizmette yeni biçim tabanlı veri kümesi modeli kullanıma sunulmuştur. Ayrıntılarla ilgili biçim makalesine bakın:
- Avro biçimi
- İkili biçim
- Sınırlandırılmış metin biçimi
- JSON biçimi
- ORC biçimi
- Parquet biçimi
Bu makalede bahsedilen geri kalan yapılandırmalar geriye dönük compabitility için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
Metin biçimi (eski)
Not
Sınırlandırılmış metin biçimi makalesindeki yeni modeli öğrenin. Dosya tabanlı veri deposu veri kümesinde aşağıdaki yapılandırmalar geriye dönük uyumluluk için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
Bir metin dosyasından okumak veya metin dosyasına yazmak istiyorsanız, veri kümesinin type format bölümündeki özelliğini TextFormat olarak ayarlayın. İsterseniz format bölümünde aşağıdaki isteğe bağlı özellikleri de belirtebilirsiniz. Yapılandırma adımları için TextFormat örneği bölümünü inceleyin.
| Özellik | Açıklama | İzin verilen değerler | Zorunlu |
|---|---|---|---|
| columnDelimiter | Bir dosyadaki sütunları ayırmak için kullanılan karakterdir. Verilerinizde mevcut olmayan nadir bir yazdırılamayan karakter kullanmayı düşünebilirsiniz. Örneğin, Başlık Başlangıcını (SOH) temsil eden "\u0001" değerini belirtin. | Yalnızca bir karaktere izin verilir. Varsayılan değer virgül (",") olarak belirlenmiştir. Unicode karakteri kullanmak için, ilgili kodu almak için Unicode Karakterleri'ne bakın. |
Hayır |
| rowDelimiter | Bir dosyadaki satırları ayırmak için kullanılan karakterdir. | Yalnızca bir karaktere izin verilir. Varsayılan değer, okuma sırasında ["\r\n", "\r", "\n"] değerlerinden biri, yazma sırasında ise "\r\n" olarak belirlenmiştir. | Hayır |
| escapeChar | Giriş dosyasının içeriğindeki bir sütun ayırıcısına kaçış karakteri eklemek için kullanılan özel karakterdir. Bir tablo için hem escapeChar hem de quoteChar parametrelerini aynı anda belirtemezsiniz. |
Yalnızca bir karaktere izin verilir. Varsayılan değer yoktur. Örnek: Sütun sınırlayıcısı olarak virgül (',') varsa ancak metinde virgül karakteri olmasını istiyorsanız (örnek: "Merhaba, dünya"), kaçış karakteri olarak '$' tanımlayabilir ve kaynakta "Hello$, world" dizesini kullanabilirsiniz. |
Hayır |
| quoteChar | Bir dize değerini tırnak içine almak için kullanılan karakterdir. Tırnak işareti içindeki sütun ve satır sınırlayıcıları, dize değerinin bir parçası olarak kabul edilir. Bu özellik hem giriş hem de çıkış veri kümelerine uygulanabilir. Bir tablo için hem escapeChar hem de quoteChar parametrelerini aynı anda belirtemezsiniz. |
Yalnızca bir karaktere izin verilir. Varsayılan değer yoktur. Örneğin, sütun sınırlayıcısı olarak virgül (',') varsa ancak metinde virgül karakteri olmasını istiyorsanız (örnek: <Merhaba, dünya>), tırnak karakteri olarak " (çift tırnak) tanımlayabilir ve kaynakta "Merhaba, dünya" dizesini kullanabilirsiniz. |
Hayır |
| nullValue | Bir null değeri temsil etmek için kullanılan bir veya daha fazla karakterdir. | Bir veya daha fazla karakter olabilir. Varsayılan değerler okuma sırasında "\N" ve "NULL", yazma sırasında ise "\N" olarak belirlenmiştir. | Hayır |
| encodingName | Kodlama adını belirtir. | Geçerli bir kodlama adı. Bkz. Encoding.EncodingName Özelliği. Örnek: windows-1250 veya shift_jis. Varsayılan değer UTF-8 olarak belirlenmiştir. | Hayır |
| firstRowAsHeader | İlk satırın üst bilgi olarak kabul edilip edilmeyeceğini belirtir. Bir giriş veri kümesi için, hizmet ilk satırı üst bilgi olarak okur. Bir çıkış veri kümesi için, hizmet ilk satırı üst bilgi olarak yazar. Örnek senaryolar için bkz. firstRowAsHeader ve skipLineCount kullanım senaryoları. |
True False (varsayılan) |
Hayır |
| skipLineCount | Giriş dosyalarından veri okurken atlanacak boş olmayan satır sayısını gösterir. Hem skipLineCount hem de firstRowAsHeader parametresi belirtilirse önce satırlar atlanır, ardından giriş dosyasındaki üst bilgi bilgileri okunur. Örnek senaryolar için bkz. firstRowAsHeader ve skipLineCount kullanım senaryoları. |
Tamsayı | Hayır |
| treatEmptyAsNull | Bir giriş dosyasından veri okuma sırasında null veya boş dizenin null değer olarak kabul edilip edilmeyeceğini belirtir. | True (varsayılan) False |
Hayır |
TextFormat örneği
Bir veri kümesi için aşağıdaki JSON tanımında, isteğe bağlı özelliklerden bazıları belirtilir.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
quoteChar yerine escapeChar kullanmak için quoteChar yazan satırı şu escapeChar ile değiştirin:
"escapeChar": "$",
firstRowAsHeader ve skipLineCount kullanım senaryoları
- Dosya olmayan bir kaynaktan bir metin dosyasına kopyalama yapıyorsunuz ve şema meta verilerini (örneğin, SQL şeması) içeren bir üst bilgi satırı eklemek istiyorsunuz. Bu senaryo için çıkış veri kümesinde
firstRowAsHeaderparametresini true olarak belirleyin. - Üst bilgi satırı içeren bir metin dosyasından dosya olmayan bir havuza kopyalama yapıyorsunuz ve üst bilgi satırını almak istemiyorsunuz. Giriş veri kümesinde
firstRowAsHeaderparametresini true olarak belirleyin. - Bir metin dosyasından kopyalama yapıyorsunuz ve dosyanın başındaki veri içermeyen veya üst bilgi bilgilerini içeren birkaç satırı atlamak istiyorsunuz. Atlanacak satır sayısını belirtmek için
skipLineCountdeğerini belirtin. Dosyanın geri kalan kısmında üst bilgi satırı varsafirstRowAsHeaderdeğerini de belirtebilirsiniz. HemskipLineCounthem defirstRowAsHeaderparametresi belirtilirse önce satırlar atlanır, ardından giriş dosyasındaki üst bilgi bilgileri okunur.
JSON biçimi (eski)
Not
JSON biçimindeki yeni modeli öğrenin makalesi. Dosya tabanlı veri deposu veri kümesinde aşağıdaki yapılandırmalar geriye dönük uyumluluk için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
Bir JSON dosyasını Azure Cosmos DB'de olduğu gibi içeri/dışarı aktarmak için Azure Cosmos DB'ye/Azure Cosmos DB'den verileri taşıma makalesindeki JSON belgelerini içeri/dışarı aktarma bölümüne bakın.
JSON dosyalarını ayrıştırmak veya verileri JSON biçiminde yazmak istiyorsanız, bölümündeki özelliğini format JsonFormat olarak ayarlayıntype. İsterseniz format bölümünde aşağıdaki isteğe bağlı özellikleri de belirtebilirsiniz. Yapılandırma adımları için JsonFormat örneği bölümünü inceleyin.
| Özellik | Açıklama | Gerekli |
|---|---|---|
| filePattern | Her bir JSON dosyasında depolanan verilerin desenini belirtir. İzin verilen değerler: setOfObjects ve arrayOfObjects. Varsayılan değer setOfObjects olarak belirlenmiştir. Bu desenler hakkında ayrıntılı bilgi için bkz. JSON dosyası desenleri. | Hayır |
| jsonNodeReference | Bir dizi alanındaki aynı desene sahip verileri yinelemek ve ayıklamak istiyorsanız o dizinin JSON yolunu belirtin. Bu özellik yalnızca JSON dosyalarından veri kopyalarken desteklenir. | Hayır |
| jsonPathDefinition | Her sütun için JSON yolu ifadesini belirtin ve özel bir sütun adıyla eşleyin (küçük harfle başlatın). Bu özellik yalnızca JSON dosyalarından veri kopyalarken desteklenir ve nesneden veya diziden veri ayıklayabilirsiniz. Kök nesne altındaki alanlar için root $ ile, jsonNodeReference özelliği tarafından seçilen dizinin içindeki alanlar için ise dizi öğesiyle başlayın. Yapılandırma adımları için JsonFormat örneği bölümünü inceleyin. |
Hayır |
| encodingName | Kodlama adını belirtir. Geçerli kodlama adlarının listesi için bkz. Encoding.EncodingName Özelliği. Örneğin: windows-1250 veya shift_jis. Varsayılan değer UTF-8 olarak belirlenmiştir. | Hayır |
| nestingSeparator | İç içe geçme düzeylerini ayırmak için kullanılan karakterdir. Varsayılan değer "." (nokta) olarak belirlenmiştir. | Hayır |
Not
Dizideki verileri birden çok satıra çapraz uygulama durumu için (JsonFormat örneklerinde örnek 1 -> örnek 2), yalnızca özelliğini jsonNodeReferencekullanarak tek diziyi genişletmeyi seçebilirsiniz.
JSON dosyası desenleri
Kopyalama etkinliği JSON dosyalarının aşağıdaki desenlerini ayrıştırabilir:
1. Tür: setOfObjects
Her dosya tek bir nesne veya satırlara ayrılmış/bitiştirilmiş birden fazla nesne içerir. Bu seçenek bir çıkış veri kümesinde belirlendiğinde, kopyalama etkinliği her satırda bir nesnenin bulunduğu (satırlara ayrılmış) tek bir JSON dosyası üretir.
tek nesne JSON örneği
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }satırlara ayrılmış JSON örneği
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}bitiştirilmiş JSON örneği
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
2. Tür: arrayOfObjects
Her dosya bir nesne dizisi içerir.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat örneği
Örnek Durum 1: JSON dosyalarından veri kopyalama
Örnek 1: nesne ve diziden veri ayıklama
Bu örnekte, bir kök JSON nesnesinin tablosal sonuçtaki tek bir kayıtla eşleşmesi beklenir. Aşağıdaki içeriğe sahip bir JSON dosyanız varsa:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
ve hem nesne hem de diziden veri ayıklayarak bir Azure SQL tablosuna aşağıdaki biçimde kopyalamak istersiniz:
| Kimlik | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
JsonFormat türüne sahip giriş veri kümesi şu şekilde tanımlanır: (yalnızca ilgili bölümlerin gösterildiği kısmi tanım). Daha açık belirtmek gerekirse:
structurebölümü, tablo verilerine dönüştürme sırasında kullanılan özelleştirilmiş sütun adlarını ve karşılık gelen veri türünü tanımlar. Bu bölüm isteğe bağlıdır ve yalnızca sütun eşleme için kullanmanız gerekir. Daha fazla bilgi için bkz . Kaynak veri kümesi sütunlarını hedef veri kümesi sütunlarına eşleme.jsonPathDefinition, her sütun için verilerin ayıklanacağı JSON yolunu belirtir. Diziden veri kopyalamak için,array[x].propertynesnedenxthverilen özelliğin değerini ayıklamak için veya bu özelliği içeren herhangi bir nesneden değeri bulmak için kullanabilirsinizarray[*].property.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Örnek 2: diziden aynı desene sahip birden fazla nesneyi çapraz uygulama
Bu örnekte, bir kök JSON nesnesinin tablosal sonuçtaki birden fazla kayda dönüştürülmesi beklenir. Aşağıdaki içeriğe sahip bir JSON dosyanız varsa:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
ve bunu bir Azure SQL tablosuna aşağıdaki biçimde, dizi içindeki verileri düzleştirerek ve ortak kök bilgileriyle çapraz birleşim yaparak kopyalamak istiyorsanız:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
JsonFormat türüne sahip giriş veri kümesi şu şekilde tanımlanır: (yalnızca ilgili bölümlerin gösterildiği kısmi tanım). Daha açık belirtmek gerekirse:
structurebölümü, tablo verilerine dönüştürme sırasında kullanılan özelleştirilmiş sütun adlarını ve karşılık gelen veri türünü tanımlar. Bu bölüm isteğe bağlıdır ve yalnızca sütun eşleme için kullanmanız gerekir. Daha fazla bilgi için bkz . Kaynak veri kümesi sütunlarını hedef veri kümesi sütunlarına eşleme.jsonNodeReference, dizisindeorderlinesaynı desene sahip nesnelerden verileri yinelemeyi ve ayıklamayı gösterir.jsonPathDefinition, her sütun için verilerin ayıklanacağı JSON yolunu belirtir. Bu örnekte ,ordernumberorderdatevecity, ile başlayan$.order_pdJSON yolu ile kök nesnenin altındadır veorder_priceolmadan$.dizi öğesinden türetilen yol ile tanımlanır.
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Aşağıdaki noktalara dikkat edin:
structurevejsonPathDefinitionveri kümesinde tanımlanmamışsa, Kopyalama Etkinliği şemayı ilk nesneden algılar ve nesnenin tamamını düzleştirmeyi sağlar.- JSON girişi bir diziye sahipse, Copy Activity dizi değerinin tamamını varsayılan olarak bir dizeye dönüştürür. Verileri
jsonNodeReferenceve/veyajsonPathDefinitionkullanarak ayıklayabilir ya dajsonPathDefinitioniçinde belirtmeden atlayabilirsiniz. - Aynı düzeyde birden fazla ad varsa Copy Activity sonuncusunu alır.
- Özellik adları büyük/küçük harfe duyarlıdır. Aynı ada ancak farklı büyük/küçük harf düzenine sahip iki özellik, iki ayrı özellik olarak kabul edilir.
Durum 2: JSON dosyasına veri yazma
SQL Veritabanı'da aşağıdaki tabloya sahipseniz:
| Kimlik | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | Kategori 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
ve her kayıt için bir JSON nesnesine aşağıdaki biçimde yazmayı beklersiniz:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
JsonFormat türüne sahip çıkış veri kümesi şu şekilde tanımlanır: (yalnızca ilgili bölümlerin gösterildiği kısmi tanım). Daha açık belirtmek gerekirse, structure bölüm hedef dosyadaki nestingSeparator özelleştirilmiş özellik adlarını tanımlar; (".") adından iç içe katmanı tanımlamak için kullanılır. Bu bölüm isteğe bağlıdır ve kaynak sütunu adıyla karşılaştırarak özellik adını değiştirmek veya özelliklerin bazılarını iç içe yerleştirmek için kullanmanız gerekir.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet biçimi (eski)
Not
Parquet biçimi makalesinden yeni modeli öğrenin. Dosya tabanlı veri deposu veri kümesinde aşağıdaki yapılandırmalar geriye dönük uyumluluk için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
Parquet dosyalarını ayrıştırmak veya verileri Parquet biçiminde yazmak istiyorsanız, özelliğini ParquetFormat olarak ayarlayın format type. typeProperties bölümünün içindeki Format bölümünde herhangi bir özellik belirtmenize gerek yoktur. Örnek:
"format":
{
"type": "ParquetFormat"
}
Aaşağıdaki noktaları unutmayın:
- Karmaşık veri türleri desteklenmez (MAP, LIST).
- Sütun adında boşluk desteklenmiyor.
- Parquet dosyası sıkıştırmayla ilgili şu seçeneklere sahiptir: NONE, SNAPPY, GZIP ve LZO. Hizmet, LZO dışında bu sıkıştırılmış biçimlerden herhangi birinde Parquet dosyasından veri okumayı destekler. Verileri okumak için meta verilerdeki sıkıştırma codec'ini kullanır. Ancak, bir Parquet dosyasına yazarken hizmet, Parquet biçimi için varsayılan olan SNAPPY'yi seçer. Şu anda bu davranışı geçersiz kılma seçeneği yoktur.
Önemli
Şirket içi ve bulut veri depoları arasında şirket içinde barındırılan Integration Runtime tarafından güçlendirilen kopyalama için Parquet dosyalarını olduğu gibi kopyalamazsanız, IR makinenize 64 bit JRE 8 (Java Çalışma Zamanı Ortamı) veya OpenJDK yüklemeniz gerekir. Daha fazla ayrıntı içeren aşağıdaki paragrafa bakın.
Parquet dosya serileştirme/seri durumdan çıkarma ile Şirket içinde barındırılan IR üzerinde çalışan kopyalama için hizmet, önce JRE için kayıt defterini (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) denetleyerek Java çalışma zamanını bulur, bulunamazsa ikinci olarak OpenJDK için sistem değişkenini JAVA_HOME denetler.
- JRE'yi kullanmak için: 64 bit IR için 64 bit JRE gerekir. Buradan bulabilirsiniz.
- OpenJDK'yi kullanmak için: IR sürüm 3.13'ten beri desteklenir. jvm.dll OpenJDK'nin diğer tüm gerekli derlemeleriyle şirket içinde barındırılan IR makinesine paketleyin ve sistem ortamı değişkenini buna göre JAVA_HOME ayarlayın.
İpucu
Şirket İçinde Barındırılan Tümleştirme Çalışma Zamanı'nı kullanarak Parquet biçiminden veri kopyalayıp "Java çağrılırken bir hata oluştu, ileti: java.lang.OutOfMemoryError:Java yığın alanı" hatasıyla karşılaşırsanız, şirket içinde barındırılan IR'yi barındıran makineye JVM'nin bu kopyayı güçlendirmek için en küçük/en büyük yığın boyutunu ayarlamak üzere bir ortam değişkeni _JAVA_OPTIONS ekleyebilir ve ardından işlem hattını yeniden çalıştırabilirsiniz.
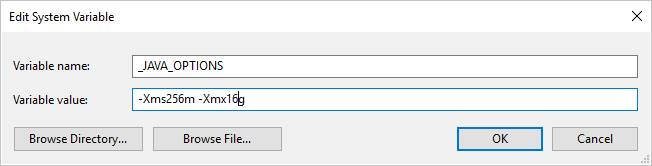
Örnek: değeriyle -Xms256m -Xmx16gdeğişken _JAVA_OPTIONS ayarlama. bayrağı Xms bir Java Sanal Makinesi (JVM) için ilk bellek ayırma havuzunu belirtirken Xmx , en yüksek bellek ayırma havuzunu belirtir. Bu, JVM'nin bellek miktarıyla Xms başlatılacağı ve en fazla Xmx bellek miktarını kullanabileceği anlamına gelir. Varsayılan olarak hizmet en az 64 MB ve en fazla 1G kullanır.
Parquet dosyaları için veri türü eşlemesi
| Ara hizmet veri türü | Parquet Temel Türü | Parquet Özgün Türü (Seri Durumdan Çıkar) | Parquet Özgün Türü (Serileştir) |
|---|---|---|---|
| Boolean | Boolean | Yok | Yok |
| SByte | Int32 | Int8 | Int8 |
| Bayt | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/İkili | UInt64 | Ondalık |
| Tekli | Satışa Arz | Yok | Yok |
| Çift | Çift | Yok | Yok |
| Ondalık | İkilik | Ondalık | Ondalık |
| String | İkilik | Utf8 | Utf8 |
| DateTime | Int96 | Yok | Yok |
| TimeSpan | Int96 | Yok | Yok |
| DateTimeOffset | Int96 | Yok | Yok |
| ByteArray | İkilik | Yok | Yok |
| GUID | İkilik | Utf8 | Utf8 |
| Char | İkilik | Utf8 | Utf8 |
| CharArray | Desteklenmez | Yok | Yok |
ORC biçimi (eski)
Not
ORC biçimindeki yeni modeli öğrenin makalesi. Dosya tabanlı veri deposu veri kümesinde aşağıdaki yapılandırmalar geriye dönük uyumluluk için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
ORC dosyalarını ayrıştırmak veya verileri ORC biçiminde yazmak istiyorsanız, özelliğini OrcFormat olarak ayarlayın format type. typeProperties bölümünün içindeki Format bölümünde herhangi bir özellik belirtmenize gerek yoktur. Örnek:
"format":
{
"type": "OrcFormat"
}
Aaşağıdaki noktaları unutmayın:
- Karmaşık veri türleri desteklenmez (STRUCT, MAP, LIST, UNION).
- Sütun adında boşluk desteklenmiyor.
- ORC dosyası sıkıştırmayla ilgili üç seçeneğe sahiptir: NONE, ZLIB, SNAPPY. Hizmet, bu sıkıştırılmış biçimlerden herhangi birinde ORC dosyasından veri okumayı destekler. Verileri okumak için meta verilerdeki sıkıştırma kodlayıcısı/kod çözücüsünü kullanır. Ancak, bir ORC dosyasına yazarken hizmet, ORC için varsayılan olan ZLIB'yi seçer. Şu anda bu davranışı geçersiz kılma seçeneği yoktur.
Önemli
Şirket içi ve bulut veri depoları arasında şirket içinde barındırılan Integration Runtime tarafından güçlendirilen kopyalama için, ORC dosyalarını olduğu gibi kopyalamıyorsanız, IR makinenize 64 bit JRE 8 (Java Çalışma Zamanı Ortamı) veya OpenJDK yüklemeniz gerekir. Daha fazla ayrıntı içeren aşağıdaki paragrafa bakın.
ORC dosya serileştirme/seri durumdan çıkarma ile Şirket içinde barındırılan IR üzerinde çalışan kopyalama için hizmet, ilk olarak JRE için kayıt defterini (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) denetleyerek Java çalışma zamanını bulur, bulunamazsa ikinci olarak OpenJDK için sistem değişkenini JAVA_HOME denetler.
- JRE'yi kullanmak için: 64 bit IR için 64 bit JRE gerekir. Buradan bulabilirsiniz.
- OpenJDK'yi kullanmak için: IR sürüm 3.13'ten beri desteklenir. jvm.dll OpenJDK'nin diğer tüm gerekli derlemeleriyle şirket içinde barındırılan IR makinesine paketleyin ve sistem ortamı değişkenini buna göre JAVA_HOME ayarlayın.
ORC dosyaları için veri türü eşlemesi
| Ara hizmet veri türü | ORC türleri |
|---|---|
| Boolean | Boolean |
| SByte | Bayt |
| Bayt | Kısa |
| Int16 | Kısa |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Uzun |
| Int64 | Uzun |
| UInt64 | String |
| Tekli | Satışa Arz |
| Çift | Çift |
| Ondalık | Ondalık |
| String | String |
| DateTime | Zaman damgası |
| DateTimeOffset | Zaman damgası |
| TimeSpan | Zaman damgası |
| ByteArray | İkilik |
| GUID | String |
| Char | Char(1) |
AVRO biçimi (eski)
Not
Avro biçimi makalesinden yeni modeli öğrenin. Dosya tabanlı veri deposu veri kümesinde aşağıdaki yapılandırmalar geriye dönük uyumluluk için olduğu gibi hala desteklenmektedir. Bundan sonra yeni modeli kullanmanız önerilir.
Avro dosyalarını ayrıştırmak veya verileri Avro biçiminde yazmak istiyorsanız, özelliğini AvroFormat olarak ayarlayın format type. typeProperties bölümünün içindeki Format bölümünde herhangi bir özellik belirtmenize gerek yoktur. Örnek:
"format":
{
"type": "AvroFormat",
}
Hive tablosunda Avro biçimini kullanmak için Apache Hive'ın öğreticisine başvurabilirsiniz.
Aaşağıdaki noktaları unutmayın:
- Karmaşık veri türleri desteklenmez (kayıtlar, sabit listeleri, diziler, haritalar, birleşimler ve sabit).
Sıkıştırma desteği (eski)
Hizmet, kopyalama sırasında verileri sıkıştırmayı/sıkıştırmayı kaldırmayı destekler. Bir giriş veri kümesinde özellik belirttiğinizde compression , kopyalama etkinliği kaynaktan sıkıştırılmış verileri okur ve sıkıştırmasını kaldırır; bir çıkış veri kümesinde özelliği belirttiğinizde kopyalama etkinliği sıkıştırır ve havuza veri yazar. Aşağıda birkaç örnek senaryo verilmiştir:
- Azure blobundan GZIP sıkıştırılmış verilerini okuyun, açın ve sonuç verilerini Azure SQL Veritabanı yazın. Giriş Azure Blob veri kümesini özelliğiyle
compressiontypeGZIP olarak tanımlarsınız. - Şirket içi Dosya Sistemi'nden düz metin dosyasındaki verileri okuyun, GZip biçimini kullanarak sıkıştırın ve sıkıştırılmış verileri bir Azure blob'ına yazın. GZip özelliğine sahip
compressiontypebir çıkış Azure Blob veri kümesi tanımlarsınız. - FTP sunucusundan .zip dosyasını okuyun, dosyaları içeri almak için açın ve bu dosyaları Azure Data Lake Store'a alın. ZipDeflate özelliğine
compressiontypesahip bir giriş FTP veri kümesi tanımlarsınız. - Azure blobundan GZIP ile sıkıştırılmış verileri okuyun, açın, BZIP2 kullanarak sıkıştırıp sonuç verilerini bir Azure blob'a yazın. GZIP olarak ayarlanmış giriş Azure Blob veri kümesini
compressiontypeve BZIP2 olarak ayarlanmış çıkış veri kümesinicompressiontypetanımlarsınız.
Bir veri kümesinin sıkıştırmasını belirtmek için aşağıdaki örnekte olduğu gibi JSON veri kümesindeki sıkıştırma özelliğini kullanın:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Sıkıştırma bölümünün iki özelliği vardır:
Tür: GZIP, Deflate, BZIP2 veya ZipDeflate olabilecek sıkıştırma codec bileşeni. ZipDeflate dosyalarının sıkıştırmasını açmak ve dosya tabanlı havuz veri deposuna yazmak için kopyalama etkinliğini kullanırken dosyalar şu klasöre ayıklanır:
<path specified in dataset>/<folder named as source zip file>/.Düzey: En uygun veya en hızlı olabilecek sıkıştırma oranı.
En hızlı: Elde edilen dosya en iyi şekilde sıkıştırılmasa bile sıkıştırma işlemi mümkün olan en hızlı şekilde tamamlanmalıdır.
En uygun: İşlemin tamamlanması daha uzun sürse bile sıkıştırma işlemi en iyi şekilde sıkıştırılmalıdır.
Daha fazla bilgi için Bkz . Sıkıştırma Düzeyi konusu.
Not
Sıkıştırma ayarları AvroFormat, OrcFormat veya ParquetFormat içindeki veriler için desteklenmez. Bu biçimlerdeki dosyaları okurken, hizmet meta verilerdeki sıkıştırma codec bileşenini algılar ve kullanır. Bu biçimlerdeki dosyalara yazarken, hizmet bu biçim için varsayılan sıkıştırma codec'ini seçer. Örneğin, OrcFormat için ZLIB ve ParquetFormat için SNAPPY.
Desteklenmeyen dosya türleri ve sıkıştırma biçimleri
Desteklenmeyen dosyaları dönüştürmek için genişletilebilirlik özelliklerini kullanabilirsiniz. azure batch kullanarak Azure İşlevleri ve özel görevler iki seçenektir.
Tar dosyasının içeriğini ayıklamak için Azure işlevi kullanan bir örnek görebilirsiniz. Daha fazla bilgi için bkz. Azure İşlevleri etkinliği.
Bu işlevi özel bir dotnet etkinliği kullanarak da oluşturabilirsiniz. Daha fazla bilgiye buradan ulaşabilirsiniz
İlgili içerik
Desteklenen dosya biçimleri ve sıkıştırmalarından desteklenen en son dosya biçimlerini ve sıkıştırmalarını öğrenin.