Data Lakehouse nedir?
Data Lakehouse, veri göllerinin ve veri ambarlarının avantajlarını birleştiren bir veri yönetim sistemidir. Bu makalede lakehouse mimari deseni ve Azure Databricks'te bununla neler yapabileceğiniz açıklanmaktadır.
Data Lakehouse ne için kullanılır?
Data Lakehouse, makine öğrenmesi (ML) ve iş zekası (BI) gibi farklı iş yüklerini işlemek için yalıtılmış sistemlerden kaçınmak isteyen modern kuruluşlar için ölçeklenebilir depolama ve işleme özellikleri sağlar. Data Lakehouse tek bir gerçeklik kaynağı oluşturmaya, gereksiz maliyetleri ortadan kaldırmaya ve verilerin güncelliğini sağlamaya yardımcı olabilir.
Data lakehouse'lar genellikle hazırlama ve dönüştürme katmanlarında ilerledikçe verileri artımlı olarak geliştiren, zenginleştiren ve iyileştiren bir veri tasarımı deseni kullanır. Göl binasının her katmanı bir veya daha fazla katman içerebilir. Bu desen genellikle madalyon mimarisi olarak adlandırılır. Daha fazla bilgi için bkz . Madalyon göl evi mimarisi nedir?
Databricks lakehouse nasıl çalışır?
Databricks, Apache Spark üzerine kurulmuştur. Apache Spark, depolama alanından ayrılmış işlem kaynakları üzerinde çalışan yüksek düzeyde ölçeklenebilir bir altyapı sağlar. Daha fazla bilgi için bkz. Azure Databricks'te Apache Spark
Databricks lakehouse iki temel teknoloji daha kullanır:
- Delta Lake: ACID işlemlerini ve şema zorlamayı destekleyen iyileştirilmiş bir depolama katmanı.
- Unity Kataloğu: Veriler ve yapay zeka için birleşik, ayrıntılı bir idare çözümü.
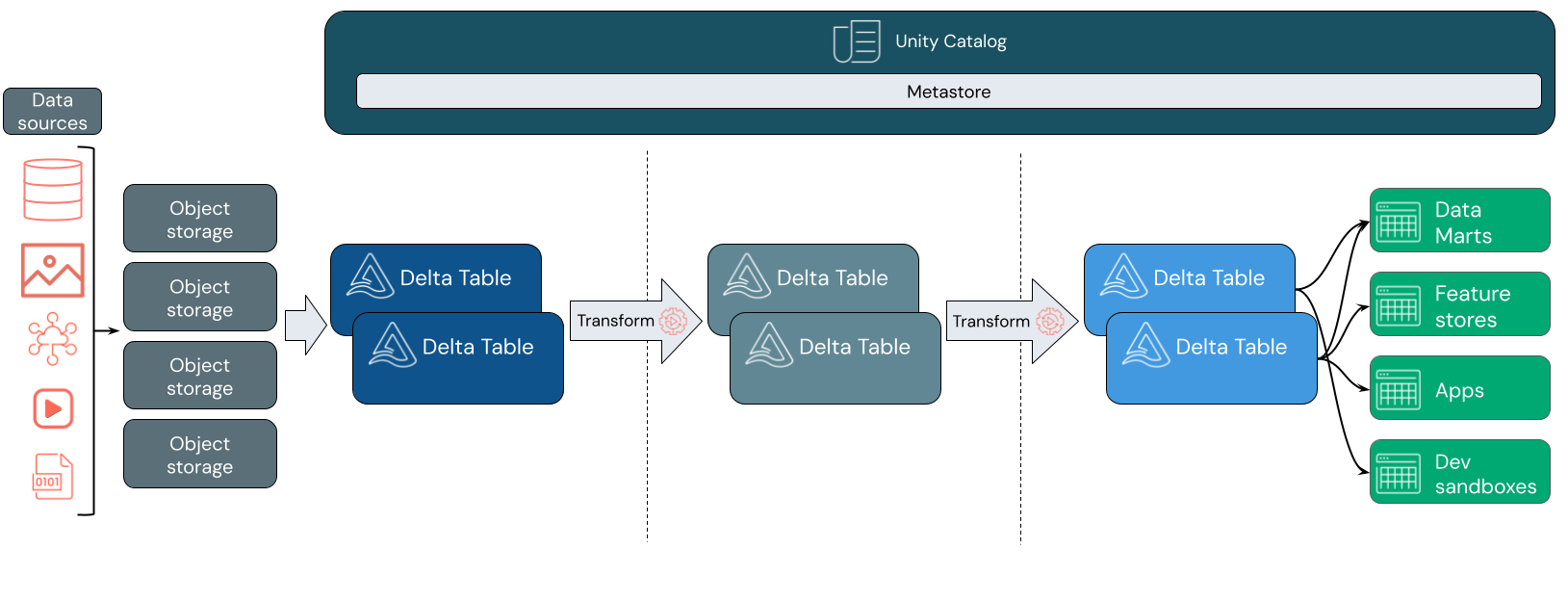
Veri alımı
Alım katmanında, toplu iş veya akış verileri çeşitli kaynaklardan ve çeşitli biçimlerde gelir. Bu ilk mantıksal katman, bu verilerin ham biçimine inmek için bir yer sağlar. Bu dosyaları Delta tablolarına dönüştürürken, eksik veya beklenmeyen verileri denetlemek için Delta Lake'in şema zorlama özelliklerini kullanabilirsiniz. Unity Kataloğu'nu kullanarak tabloları veri idare modelinize ve gerekli veri yalıtımı sınırlarına göre kaydedebilirsiniz. Unity Kataloğu, verilerinizin dönüştürüldükçe ve iyileştirildikçe kökenini izlemenize ve hassas verileri gizli ve güvenli tutmak için birleşik bir idare modeli uygulamanıza olanak tanır.
Veri işleme, seçme ve tümleştirme
Doğrulandıktan sonra verilerinizi iyileştirmeye ve iyileştirmeye başlayabilirsiniz. Veri bilimcileri ve makine öğrenmesi uygulayıcıları, yeni özellikleri birleştirmeye veya oluşturmaya ve veri temizlemeyi tamamlamaya başlamak için bu aşamada verilerle sık sık çalışır. Verileriniz iyice temizlendikten sonra, belirli iş gereksinimlerinizi karşılayacak şekilde tasarlanmış tablolar halinde tümleştirilebilir ve yeniden düzenlenebilir.
Delta şema evrimi özellikleriyle birlikte bir şema üzerinde yazma yaklaşımı, verileri son kullanıcılarınıza sunan aşağı akış mantığını yeniden yazmak zorunda kalmadan bu katmanda değişiklik yapabileceğiniz anlamına gelir.
Veri sunma
Son katman, son kullanıcılara temiz, zenginleştirilmiş veriler sağlar. Son tablolar, tüm kullanım örneklerinize yönelik verileri sunmak üzere tasarlanmalıdır. Birleşik idare modeli, veri kökenini tek bir gerçeklik kaynağınıza kadar izleyebildiğiniz anlamına gelir. Farklı görevler için iyileştirilmiş veri düzenleri, son kullanıcıların makine öğrenmesi uygulamaları, veri mühendisliği ve iş zekası ile raporlama verilerine erişmesine olanak tanır.
Delta Lake hakkında daha fazla bilgi edinmek için bkz . Delta Lake nedir? Unity Kataloğu hakkında daha fazla bilgi edinmek için bkz . Unity Kataloğu nedir?
Databricks lakehouse'un özellikleri
Databricks üzerine kurulu bir lakehouse, modern veri şirketleri için veri göllerine ve veri ambarlarına olan mevcut bağımlılığın yerini alır. Gerçekleştirebileceğiniz bazı önemli görevler şunlardır:
- Gerçek zamanlı veri işleme: Anında analiz ve eylem için akış verilerini gerçek zamanlı olarak işleme.
- Veri tümleştirmesi: İşbirliğini etkinleştirmek ve kuruluşunuz için tek bir gerçek kaynağı oluşturmak için verilerinizi tek bir sistemde birleştirin.
- Şema evrimi: Mevcut veri işlem hatlarını kesintiye uğratmadan değişen iş gereksinimlerine uyum sağlamak için zaman içinde veri şemasını değiştirin.
- Veri dönüştürmeleri: Apache Spark ve Delta Lake kullanmak verilerinize hız, ölçeklenebilirlik ve güvenilirlik getirir.
- Veri analizi ve raporlama: Veri ambarı iş yükleri için iyileştirilmiş bir altyapıyla karmaşık analitik sorgular çalıştırın.
- Makine öğrenmesi ve yapay zeka: Tüm verilerinize gelişmiş analiz teknikleri uygulayın. Verilerinizi zenginleştirmek ve diğer iş yüklerini desteklemek için ML kullanın.
- Veri sürümü oluşturma ve köken: Veri başarısı ve izlenebilirlik sağlamak için veri kümeleri için sürüm geçmişini koruyun ve kökeni izleyin.
- Veri idaresi: Verilerinize erişimi denetlemek ve denetimler gerçekleştirmek için tek, birleşik bir sistem kullanın.
- Veri paylaşımı: Ekipler arasında seçilmiş veri kümelerinin, raporların ve içgörülerin paylaşılmasını sağlayarak işbirliğini kolaylaştırın.
- operasyonel analiz: Lakehouse izleme verilerine makine öğrenmesi uygulayarak veri kalitesi ölçümlerini, model kalitesi ölçümlerini ve kaymayı izleyin.
Lakehouse ile Data Lake ve Veri Ambarı karşılaştırması
Veri ambarları, yaklaşık 30 yıldır iş zekası (BI) kararlarını güçlendirerek veri akışını kontrol eden sistemler için bir dizi tasarım yönergesi olarak gelişmiştir. Kurumsal veri ambarları, BI raporları için sorguları iyileştirir, ancak sonuçların oluşturulması dakikalar, hatta saatler sürebilir. Yüksek sıklıkta değişme olasılığı düşük olan veriler için tasarlanan veri ambarları, eşzamanlı olarak çalıştırılan sorgular arasındaki çakışmaları önlemeye çalışır. Birçok veri ambarı, genellikle makine öğrenmesi desteğini sınırlayan özel biçimlere dayanır. Azure Databricks'te veri ambarı, Databricks lakehouse ve Databricks SQL'in özelliklerinden yararlanıyor. Daha fazla bilgi için bkz . Azure Databricks'te veri ambarı nedir?.
Veri depolama alanındaki teknolojik gelişmelerle desteklenen ve veri türlerindeki ve hacmindeki üstel artışlarla desteklenen veri gölleri son on yılda yaygın kullanıma girmiştir. Veri gölleri verileri ucuz ve verimli bir şekilde depolar ve işler. Veri gölleri genellikle veri ambarlarına karşı olarak tanımlanır: Veri ambarı, BI analizi için temiz, yapılandırılmış veriler sunarken, bir veri gölü de her tür doğadaki verileri herhangi bir biçimde kalıcı ve ucuz bir şekilde depolar. Birçok kuruluş veri bilimi ve makine öğrenmesi için veri göllerini kullanır, ancak yaygın olmayan yapısı nedeniyle BI raporlaması için kullanmaz.
data lakehouse, veri göllerinin ve veri ambarlarının avantajlarını birleştirir ve aşağıdakileri sağlar:
- Standart veri biçimlerinde depolanan verilere açık ve doğrudan erişim.
- Makine öğrenmesi ve veri bilimi için iyileştirilmiş dizin oluşturma protokolleri.
- BI ve gelişmiş analizler için düşük sorgu gecikme süresi ve yüksek güvenilirlik.
Data Lakehouse, iyileştirilmiş bir meta veri katmanını bulut nesne depolamada standart biçimlerde depolanan doğrulanmış verilerle birleştirerek veri bilimcilerinin ve ML mühendislerinin aynı veri temelli BI raporlarından modeller oluşturmasına olanak tanır.
Sonraki adım
Databricks kullanarak bir göl evi uygulama ve çalıştırma ilkeleri ve en iyi yöntemleri hakkında daha fazla bilgi edinmek için bkz . İyi tasarlanmış data lakehouse'a giriş