Öğretici: Azure HDInsight'ta Apache Spark kümesinde veri yükleme ve sorgu çalıştırma
Bu öğreticide, csv dosyasından veri çerçevesi oluşturmayı ve Azure HDInsight'ta Apache Spark kümesinde etkileşimli Spark SQL sorguları çalıştırmayı öğreneceksiniz. Spark’ta dataframe, adlandırılmış sütunlar halinde düzenlenmiş, dağıtılmış bir veri koleksiyonudur. Dataframe kavramsal olarak, ilişkisel bir veritabanındaki tabloya veya R/Python’daki veri çerçevesine eşdeğerdir.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Bir csv dosyasından dataframe oluşturma
- Dataframe üzerinde sorgular çalıştırma
Önkoşullar
HDInsight üzerinde bir Apache Spark kümesi. Bkz . Apache Spark kümesi oluşturma.
Jupyter Notebook oluşturma
Jupyter Notebook, çeşitli programlama dillerini destekleyen etkileşimli bir not defteri ortamıdır. Not defteri, verilerle etkileşim kurmanıza, kodu markdown metniyle birleştirmenize ve basit görselleştirmeler gerçekleştirmenize olanak sağlar.
yerine Spark kümenizin adını yazarak
SPARKCLUSTERURL'yihttps://SPARKCLUSTER.azurehdinsight.net/jupyterdüzenleyin. Ardından, düzenlenen URL'yi bir web tarayıcısına girin. İstendiğinde, küme için küme oturum açma kimlik bilgilerini girin.Jupyter web sayfasındaki Spark 2.4 kümeleri için Yeni>PySpark'ı seçerek not defteri oluşturun. Spark 3.1 sürümü için, PySpark çekirdeği artık Spark 3.1'de kullanılamadığından not defteri oluşturmak için bunun yerine Yeni>PySpark3'i seçin.
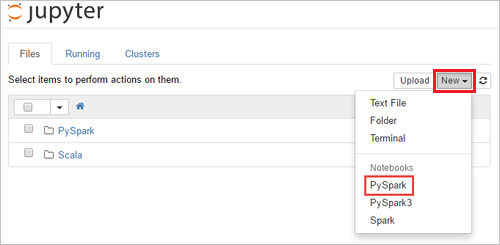
Adsız()
Untitled.ipynbadıyla yeni bir not defteri oluşturulur ve açılır.Not
Not defteri oluşturmak için PySpark veya PySpark3 çekirdeğini kullanarak, ilk kod hücresini
sparkçalıştırdığınızda oturum sizin için otomatik olarak oluşturulur. Belirtik şekilde bir oturum oluşturmanız gerekmez.
Bir csv dosyasından dataframe oluşturma
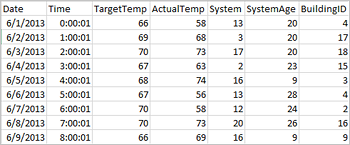
Uygulamalar doğrudan Azure Depolama veya Azure Data Lake Storage gibi uzak depolamadaki dosyalardan veya klasörlerden veri çerçeveleri oluşturabilir; Hive tablosundan; veya Spark tarafından desteklenen Azure Cosmos DB, Azure SQL DB, DW gibi diğer veri kaynaklarından. Aşağıdaki ekran görüntüsünde, bu öğreticide kullanılan HVAC.csv dosyasının bir anlık görüntü gösterilmektedir. Csv dosyası, tüm HDInsight Spark kümeleriyle birlikte gelir. Veriler, bazı binaların sıcaklık varyasyonlarını yakalar.
Aşağıdaki kodu Jupyter Not Defteri'nin boş bir hücresine yapıştırın ve kodu çalıştırmak için SHIFT + ENTER tuşlarına basın. Kod, bu senaryo için gerekli olan türleri içeri aktarır:
from pyspark.sql import * from pyspark.sql.types import *Jupyter'da etkileşimli bir sorgu çalıştırdığınızda, web tarayıcısı penceresi veya sekme resim yazısı not defteri başlığıyla birlikte bir (Meşgul) durumu gösterir. Ayrıca sağ üst köşedeki PySpark metninin yanında içi dolu bir daire görürsünüz. İş tamamlandıktan sonra bu simge boş bir daireye dönüşür.
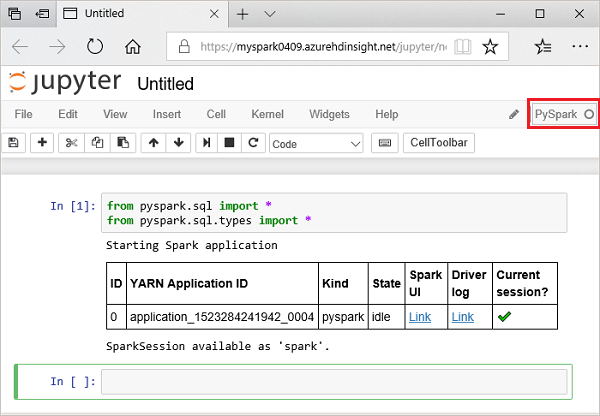
Döndürülen oturum kimliğini not edin. Yukarıdaki resimde oturum kimliği 0'dır. İsterseniz, CLUSTERNAME'in Spark kümenizin adı, kimliği ise oturum kimlik numaranız olduğu yere giderek
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsoturum ayrıntılarını alabilirsiniz.Aşağıdaki kodu çalıştırarak bir dataframe ve geçici bir tablo (hvac) oluşturun.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Datanami üzerinde sorgu çalıştırma
Tablo oluşturulduktan sonra veriler üzerinde etkileşimli bir sorgu çalıştırabilirsiniz.
Not defterinin boş bir hücresinde aşağıdaki kodu çalıştırın:
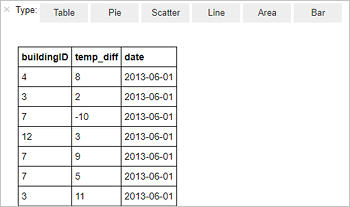
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Aşağıdaki tablo çıktısı görüntülenir.
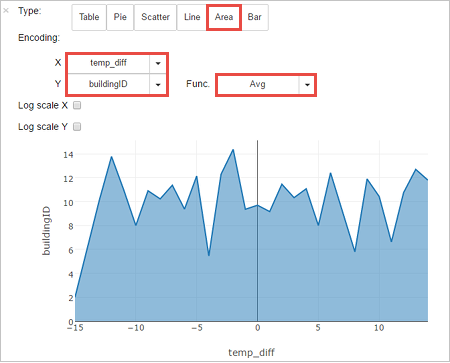
Sonuçları diğer görselleştirmelerde de görebilirsiniz. Aynı çıktı için bir alan grafiği görmek için Alan’ı seçin ve sonra gösterildiği gibi diğer değerleri ayarlayın.
Not defteri menü çubuğundan Dosya>Kaydetme ve Denetim Noktası'na gidin.
Sonraki öğreticiyi şimdi başlatıyorsanız, not defterini açık bırakın. Aksi takdirde, küme kaynaklarını serbest bırakmak için not defterini kapatın: not defteri menü çubuğundan Dosya>Kapat ve Durdur'a gidin.
Kaynakları temizleme
HDInsight ile verileriniz ve Jupyter Notebook'larınız Azure Depolama'da veya Azure Data Lake Storage'da depolandığından, kullanılmadığında kümeyi güvenle silebilirsiniz. Kullanımda olmasa bile HDInsight kümesi için de ücretlendirilirsiniz. Küme ücretleri depolama ücretlerinden çok daha fazla olduğundan, kullanımda olmayan kümeleri silmek ekonomik bir anlam ifade eder. Sonraki öğretici üzerinde hemen çalışmayı planlıyorsanız, kümeyi tutmak isteyebilirsiniz.
Azure portalında kümeyi açıp Sil’i seçin.
Kaynak grubu adını seçerek de kaynak grubu sayfasını açabilir ve sonra Kaynak grubunu sil’i seçebilirsiniz. Kaynak grubunu silerek hem HDInsight Spark kümesini hem de varsayılan depolama hesabını silersiniz.
Sonraki adımlar
Bu öğreticide, csv dosyasından veri çerçevesi oluşturmayı ve Azure HDInsight'ta Apache Spark kümesinde etkileşimli Spark SQL sorguları çalıştırmayı öğrendiniz. Apache Spark'a kaydettiğiniz verilerin Power BI gibi bir BI analiz aracına nasıl çekilebileceğini görmek için sonraki makaleye ilerleyin.