Üretimdeki modellerden veri toplama
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, Azure Kubernetes Service (AKS) kümesinde dağıtılan bir Azure Machine Learning modelinden nasıl veri toplayacağınız gösterilmektedir. Toplanan veriler daha sonra Azure Blob depolamada depolanır.
Koleksiyon etkinleştirildikten sonra, topladığınız veriler size yardımcı olur:
Topladığınız üretim verileri üzerindeki veri kaymalarını izleyin.
Toplanan verileri Power BI veya Azure Databricks kullanarak analiz etme
Modelinizi yeniden eğitme veya iyileştirme konusunda daha iyi kararlar alın.
Toplanan verilerle modelinizi yeniden eğitin.
Sınırlamalar
- Model veri toplama özelliği yalnızca Ubuntu 18.04 görüntüsüyle çalışabilir.
Önemli
10.03.2023 itibarıyla Ubuntu 18.04 görüntüsü kullanım dışı bırakılmıştır. Ubuntu 18.04 görüntüleri için destek, Ocak 2023'te 30 Nisan 2023'te EOL'ye ulaştığında bırakılacaktır.
MDC özelliği Ubuntu 18.04 dışındaki herhangi bir görüntüyle uyumsuzdur ve Ubuntu 18.04 görüntüsü kullanım dışı bırakıldıktan sonra kullanılamaz.
Başvurabileceğiniz mMore bilgileri:
Not
Veri toplama özelliği şu anda önizleme aşamasındadır; üretim iş yükleri için önizleme özellikleri önerilmez.
Toplananlar ve nereye gittiği
Aşağıdaki veriler toplanabilir:
AKS kümesinde dağıtılan web hizmetlerinden gelen giriş verilerini modelleyin. Ses, görüntü ve video toplanmaz .
Üretim giriş verilerini kullanarak model tahminleri.
Not
Bu verilerdeki ön toplama ve ön hesaplamalar şu anda toplama hizmetinin bir parçası değildir.
Çıktı Blob depolama alanına kaydedilir. Veriler Blob depolamaya eklendiğinden, analizi çalıştırmak için sık kullandığınız aracı seçebilirsiniz.
Blobdaki çıkış verilerinin yolu şu söz dizimini izler:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Not
Python için Azure Machine Learning SDK'sının 0.1.0a16 sürümünden designation önceki sürümlerinde bağımsız değişken olarak adlandırılır identifier. Kodunuzu önceki bir sürümle geliştirdiyseniz, buna göre güncelleştirmeniz gerekir.
Önkoşullar
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Azure Machine Learning çalışma alanı, betiklerinizi içeren yerel bir dizin ve Python için Azure Machine Learning SDK'sı yüklenmelidir. Bunların nasıl yükleneceğini öğrenmek için bkz . Geliştirme ortamını yapılandırma.
AKS'ye dağıtılması için eğitilmiş bir makine öğrenmesi modeline ihtiyacınız vardır. Modeliniz yoksa Görüntü sınıflandırma modelini eğitma öğreticisine bakın.
AKS kümesine ihtiyacınız var. Bir tane oluşturma ve bu modele dağıtma hakkında bilgi için bkz . Makine öğrenmesi modellerini Azure'a dağıtma.
Ortamınızı ayarlayın ve Azure Machine Learning İzleme SDK'sını yükleyin.
modeldatacollector'ın temel bağımlılığı olan Ubuntu
libssl 1.0.018.04'ü temel alan bir docker görüntüsü kullanın. Önceden oluşturulmuş görüntülere başvurabilirsiniz.
Veri toplamayı etkinleştirme
Azure Machine Learning veya diğer araçlar aracılığıyla dağıttığınız modelden bağımsız olarak veri toplamayı etkinleştirebilirsiniz.
Veri toplamayı etkinleştirmek için şunları yapmanız gerekir:
Puanlama dosyasını açın.
Dosyanın en üstüne aşağıdaki kodu ekleyin:
from azureml.monitoring import ModelDataCollectorİşlevinizde veri toplama değişkenlerinizi
initbildirin:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId isteğe bağlı bir parametredir. Modeliniz gerekli değilse kullanmanız gerekmez. CorrelationId kullanımı, LoanNumber veya CustomerId gibi diğer verilerle daha kolay eşlemenize yardımcı olur.
Identifier parametresi daha sonra blobunuzda klasör yapısını oluşturmak için kullanılır. Ham verileri işlenen verilerden ayırmak için kullanabilirsiniz.
İşleve aşağıdaki kod satırlarını
run(input_df)ekleyin:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobAKS'de bir hizmet dağıttığınızda veri toplama otomatik olarak true olarak ayarlanmaz. Aşağıdaki örnekte olduğu gibi yapılandırma dosyanızı güncelleştirin:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Ayrıca bu yapılandırmayı değiştirerek hizmet izleme için Application Insights'i etkinleştirebilirsiniz:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Yeni bir görüntü oluşturmak ve makine öğrenmesi modelini dağıtmak için bkz . Makine öğrenmesi modellerini Azure'a dağıtma.
Web hizmeti ortamının conda bağımlılıklarına 'Azure-Monitoring' pip paketini ekleyin:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Veri toplamayı devre dışı bırakma
İstediğiniz zaman veri toplamayı durdurabilirsiniz. Veri toplamayı devre dışı bırakmak için Python kodunu kullanın.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Verilerinizi doğrulama ve analiz etme
Blob depolama alanınızda toplanan verileri analiz etmek için tercih ettiğiniz bir aracı seçebilirsiniz.
Blob verilerinize hızla erişin
Azure portalda oturum açın.
Çalışma alanınızı açın.
Depolama’yı seçin.

Bu söz dizimi ile blob çıkış verilerinin yolunu izleyin:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Power BI kullanarak model verilerini analiz etme
Power BI Desktop'ı indirip açın.
Veri Al'ı ve Azure Blob Depolama'yi seçin.

Depolama hesabı adınızı ekleyin ve depolama anahtarınızı girin. Blobunuzda Ayarlar>Erişim anahtarları'nı seçerek bu bilgileri bulabilirsiniz.
Model veri kapsayıcısını seçin ve Düzenle'yi seçin.

Sorgu düzenleyicisinde Ad sütununun altına tıklayın ve depolama hesabınızı ekleyin.
Model yolunuzu filtreye girin. Yalnızca belirli bir yıl veya aydaki dosyalara bakmak istiyorsanız, filtre yolunu genişletmeniz gerekir. Örneğin, yalnızca Mart verilerine bakmak için şu filtre yolunu kullanın:
/modeldata/<subscriptionid>/<resourcegroupname/<workspacename>>/<webservicename/<modelname>>/<modelversion>/<designation>/<year>/3
Ad değerlerine göre sizinle ilgili verileri filtreleyin. Tahminleri ve girişleri depoladıysanız, her biri için bir sorgu oluşturmanız gerekir.
Dosyaları birleştirmek için İçerik sütun başlığının yanındaki aşağı doğru çift okları seçin.

Tamam'ı seçin. Veriler önceden yüklenir.

Kapat ve Uygula'yı seçin.
Girişler ve tahminler eklediyseniz, tablolarınız RequestId değerlerine göre otomatik olarak sıralanır.
Model verileriniz üzerinde özel raporlarınızı oluşturmaya başlayın.




Azure Databricks kullanarak model verilerini analiz etme
Azure Databricks çalışma alanı oluşturun.
Databricks çalışma alanınıza gidin.
Databricks çalışma alanınızda Verileri Karşıya Yükle'yi seçin.

Yeni Tablo Oluştur'u seçin ve Diğer Veri Kaynakları> Azure Blob Depolama> Not Defteri'nde Tablo Oluştur'u seçin.

Verilerinizin konumunu güncelleştirin. Örnek aşağıda verilmiştir:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"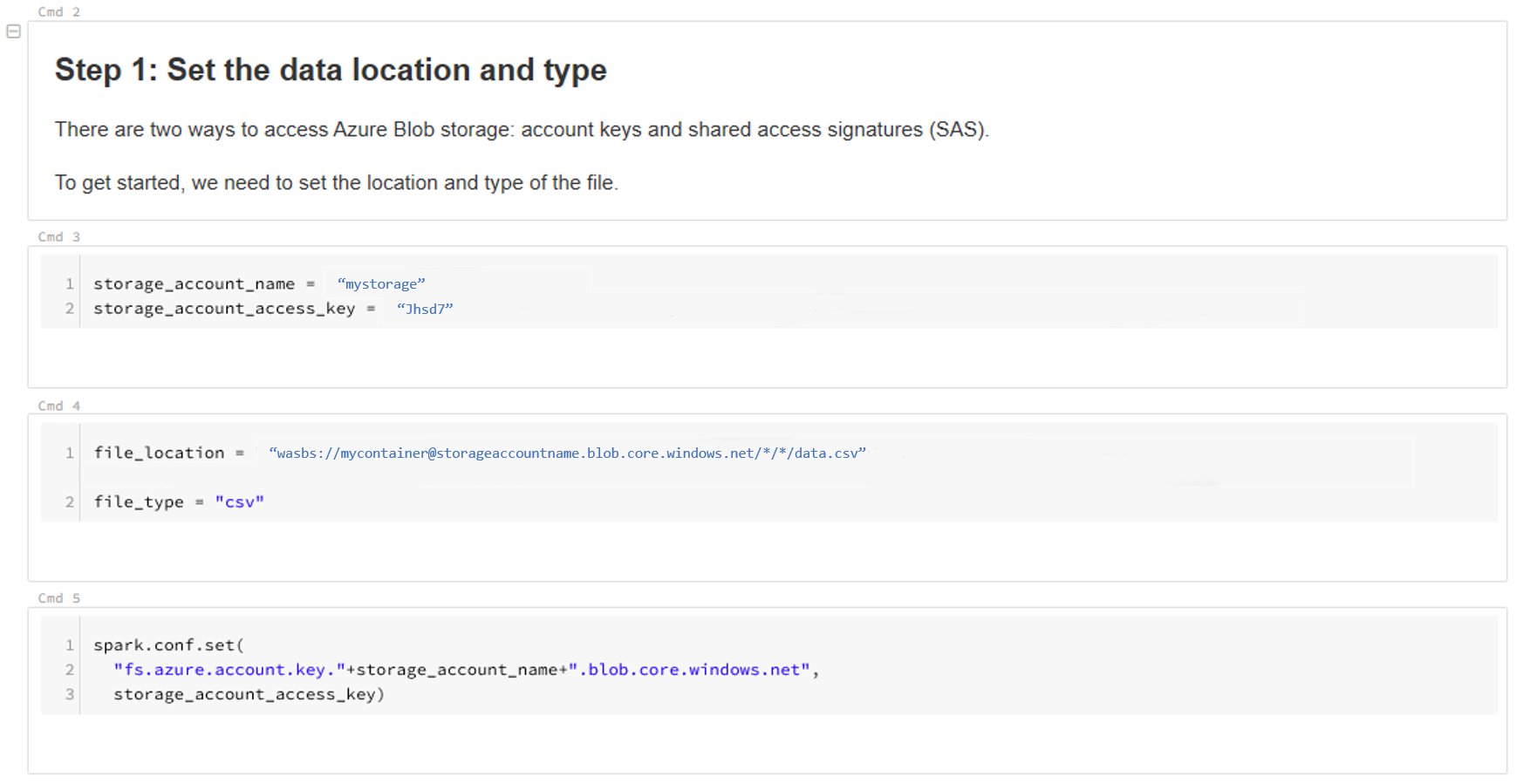
Verilerinizi görüntülemek ve analiz etmek için şablondaki adımları izleyin.



Sonraki adımlar
Topladığınız verilerde veri kayma algılama.