Azure Machine Learning için algoritmaları seçme
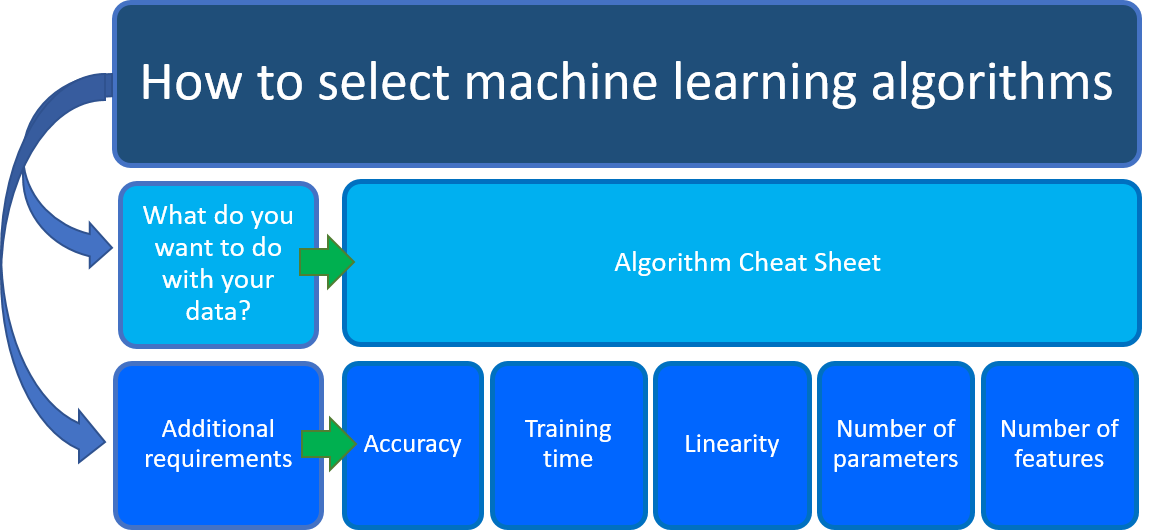
Hangi makine öğrenmesi algoritmasını kullanacağınızı merak ediyorsanız, yanıt öncelikle veri bilimi senaryonuzun iki yönüne bağlıdır:
Verilerinizle ne yapmak istiyorsunuz? Özellikle, geçmiş verilerinizden öğrenerek yanıtlamak istediğiniz iş sorusu nedir?
Veri bilimi senaryonuzun gereksinimleri nelerdir? Çözümünüzün desteklediği özellikler, doğruluk, eğitim süresi, doğrusallık ve parametreler nelerdir?
Not
Azure Machine Learning tasarımcısı iki bileşen türünü destekler: klasik önceden oluşturulmuş bileşenler (v1) ve özel bileşenler (v2). Bu iki bileşen türü UYUMLU DEĞİlDİ.
Klasik önceden oluşturulmuş bileşenler öncelikle veri işlemeye ve regresyon ve sınıflandırma gibi geleneksel makine öğrenmesi görevlerine yöneliktir. Bu bileşen türü desteklenmeye devam eder ancak yeni bileşen eklenmez.
Özel bileşenler, kendi kodunuzu bileşen olarak sarmalamanıza olanak sağlar. Çalışma alanları arasında bileşenleri paylaşmayı ve Studio, CLI v2 ve SDK v2 arabirimlerinde sorunsuz yazma desteği sunar.
Yeni projeler için, AzureML V2 ile uyumlu olan ve yeni güncelleştirmeleri almaya devam edecek özel bileşenler kullanmanızı kesinlikle öneririz.
Bu makale, önceden oluşturulmuş klasik bileşenler için geçerlidir ve CLI v2 ve SDK v2 ile uyumlu değildir.
Azure Machine Learning Algoritması Bilgi Sayfası
Azure Machine Learning Algoritması Bilgi Sayfası, ilk dikkate alınacak noktalarda size yardımcı olur: Verilerinizle ne yapmak istiyorsunuz? Başvuru sayfasında, yapmak istediğiniz görevi bulun ve tahmine dayalı analiz çözümü için bir Azure Machine Learning tasarımcı algoritması bulun.
Tasarımcı, Çok Sınıflı Karar Ormanı, Öneri sistemleri, Sinir Ağı Regresyonu, Çok Sınıflı Sinir Ağı ve K Ortalamaları Kümelemesi gibi kapsamlı bir algoritma portföyü sağlar. Her algoritma, farklı türde bir makine öğrenmesi sorununu ele almak için tasarlanmıştır. Her algoritmanın nasıl çalıştığı ve algoritmayı iyileştirmek için parametrelerin nasıl ayarlayacağı hakkında belgelerle birlikte tam bir liste için algoritma ve bileşen başvurusuna bakın.
Bu kılavuzla birlikte, makine öğrenmesi algoritması seçerken diğer gereksinimleri de göz önünde bulundurun. Aşağıda doğruluk, eğitim süresi, doğrusallık, parametre sayısı ve özellik sayısı gibi dikkate alınması gereken ek faktörler yer alır.
Makine öğrenmesi algoritmalarının karşılaştırması
Bazı algoritmalar, verilerin yapısı veya istenen sonuçlar hakkında belirli varsayımlarda bulunur. İhtiyaçlarınıza uygun bir sonuç bulabilirseniz, size daha yararlı sonuçlar, daha doğru tahminler veya daha hızlı eğitim süreleri sağlayabilir.
Aşağıdaki tabloda sınıflandırma, regresyon ve kümeleme ailelerinden algoritmaların en önemli özelliklerinden bazıları özetlemektedir:
| Algoritma | Doğruluk | Eğitim süresi | Doğrusallık | Parametreler | Notlar |
|---|---|---|---|---|---|
| Sınıflandırma ailesi | |||||
| İki sınıflı lojistik regresyon | İyi | Hızlı | Yes | 4 | |
| İki sınıflı karar ormanı | Mükemmel | Orta | Hayır | 5 | Daha yavaş puanlama sürelerini gösterir. Birikmiş ağaç tahminlerinde iş parçacığı kilitlemenin neden olduğu daha yavaş puanlama süreleri nedeniyle One-Vs-All Çoklu Sınıfı ile çalışmamanızı öneririz |
| İki sınıflı artırılmış karar ağacı | Mükemmel | Orta | Hayır | 6 | Büyük bellek ayak izi |
| İki sınıflı sinir ağı | İyi | Orta | Hayır | 8 | |
| İki sınıflı ortalama algılama | İyi | Orta | Yes | 4 | |
| İki sınıflı destek vektör makinesi | İyi | Hızlı | Yes | 5 | Büyük özellik kümeleri için iyi |
| Çok sınıflı lojistik regresyon | İyi | Hızlı | Yes | 4 | |
| Çok sınıflı karar ormanı | Mükemmel | Orta | Hayır | 5 | Daha yavaş puanlama sürelerini gösterir |
| Çok sınıflı artırılmış karar ağacı | Mükemmel | Orta | Hayır | 6 | Daha az kapsama riski olan küçük bir riskle doğruluğu artırma eğilimindedir |
| Çok sınıflı sinir ağı | İyi | Orta | Hayır | 8 | |
| Bire bir çoklu sınıf | - | - | - | - | Seçilen iki sınıflı yöntemin özelliklerine bakın |
| Regresyon ailesi | |||||
| Doğrusal regresyon | İyi | Hızlı | Yes | 4 | |
| Karar ormanı regresyonu | Mükemmel | Orta | Hayır | 5 | |
| Artırılmış karar ağacı regresyonu | Mükemmel | Orta | Hayır | 6 | Büyük bellek ayak izi |
| Sinir ağı regresyonu | İyi | Orta | Hayır | 8 | |
| Kümeleme ailesi | |||||
| K ortalamaları kümeleme | Mükemmel | Orta | Yes | 8 | Kümeleme algoritması |
Veri bilimi senaryosu gereksinimleri
Verilerinizle ne yapmak istediğinizi öğrendikte, veri bilimi senaryonuz için diğer gereksinimleri belirlemeniz gerekir.
Aşağıdaki gereksinimler için seçimler yapın ve büyük olasılıkla dengeler sağlayın:
- Doğruluk
- Eğitim süresi
- Doğrusallık
- Parametre sayısı
- Özellik sayısı
Doğruluk
Makine öğrenmesindeki doğruluk, gerçek sonuçların toplam vakalara oranı olarak modelin verimliliğini ölçer. Tasarımcıda, Modeli Değerlendir bileşeni bir dizi endüstri standardı değerlendirme ölçümünü hesaplar. Eğitilmiş bir modelin doğruluğunu ölçmek için bu bileşeni kullanabilirsiniz.
Mümkün olan en doğru yanıtı almak her zaman gerekli değildir. Bazen bir yaklaşık değer, ne için kullanmak istediğinize bağlı olarak yeterli olur. Böyle bir durum söz konusuysa, daha fazla yaklaşık yöntemle işlem sürenizi önemli ölçüde azaltabilirsiniz. Yaklaşık yöntemler de doğal olarak fazla uygunluktan kaçınma eğilimindedir.
Modeli Değerlendir bileşenini kullanmanın üç yolu vardır:
- Modeli değerlendirmek için eğitim verileriniz üzerinde puanlar oluşturun.
- Modelde puanlar oluşturun, ancak bu puanları ayrılmış test kümesindeki puanlarla karşılaştırın.
- Aynı veri kümesini kullanarak iki farklı ama ilgili modelin puanlarını karşılaştırın.
Makine öğrenmesi modellerinin doğruluğunu değerlendirmek için kullanabileceğiniz ölçümlerin ve yaklaşımların tam listesi için bkz . Model bileşenini değerlendirme.
Eğitim süresi
Denetimli öğrenmede eğitim, hataları en aza indiren bir makine öğrenmesi modeli oluşturmak için geçmiş verileri kullanmak anlamına gelir. Modeli eğitmek için gereken dakika veya saat sayısı algoritmalar arasında çok fazla değişiklik gösterir. Eğitim süresi genellikle doğrulukla yakından bağlantılıdır; biri genellikle diğerine eşlik eder.
Ayrıca, bazı algoritmalar veri noktası sayısına diğerlerinden daha duyarlıdır. Özellikle veri kümesi büyük olduğunda zaman sınırlamanız olduğundan belirli bir algoritma seçebilirsiniz.
Tasarımcıda makine öğrenmesi modeli oluşturmak ve kullanmak genellikle üç adımlı bir işlemdir:
Belirli bir algoritma türünü seçip parametrelerini veya hiper parametreleri tanımlayarak modeli yapılandırın.
Etiketlenmiş ve algoritmayla uyumlu verileri olan bir veri kümesi sağlayın. Hem verileri hem de modeli Modeli Eğit bileşenine bağlayın.
Eğitim tamamlandıktan sonra, yeni veriler hakkında tahminlerde bulunmak için puanlama bileşenlerinden biriyle eğitilen modeli kullanın.
Doğrusallık
İstatistiklerde ve makine öğrenmesinde doğrusallık, veri kümenizdeki bir değişken ile sabit arasında doğrusal bir ilişki olduğu anlamına gelir. Örneğin, doğrusal sınıflandırma algoritmaları sınıfların düz bir çizgiyle (veya daha yüksek boyutlu analog ile) ayrılabileceğini varsayar.
Çok sayıda makine öğrenmesi algoritması doğrusallığı kullanır. Azure Machine Learning tasarımcısında şunları içerir:
Doğrusal regresyon algoritmaları, veri eğilimlerinin düz bir çizgi izlediğini varsayar. Bu varsayım bazı sorunlar için kötü değildir, ancak diğerleri için doğruluğu azaltır. Dezavantajlarına rağmen doğrusal algoritmalar ilk strateji olarak popülerdir. Algoritmik olarak basit ve hızlı eğitilmeye eğilimlidirler.
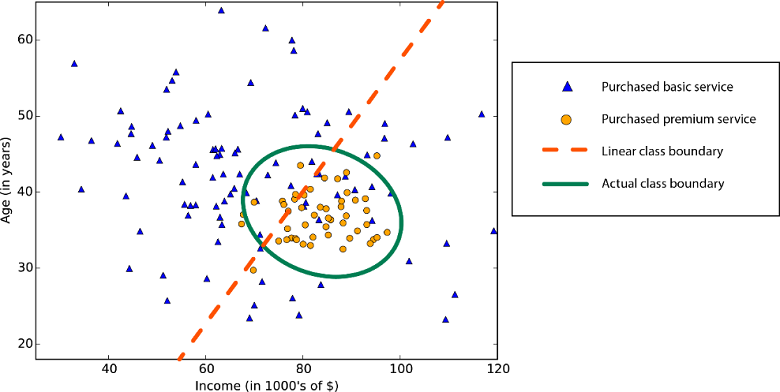
Doğrusal olmayan sınıf sınırı: Doğrusal sınıflandırma algoritmasına bağlı olmak düşük doğrulukla sonuçlanır.
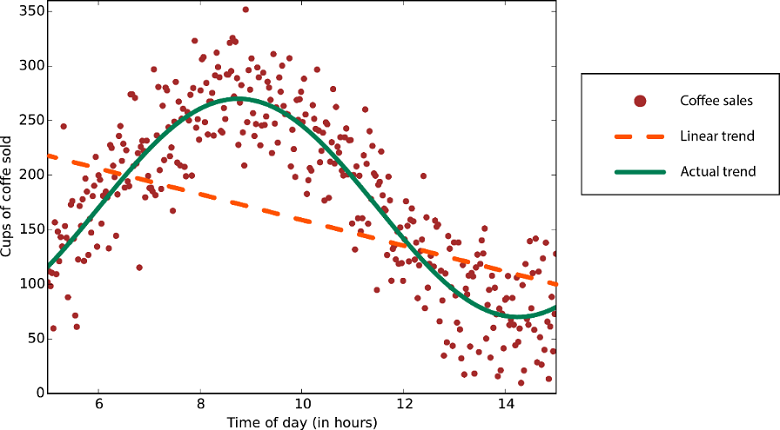
Doğrusal olmayan eğilime sahip veriler: Doğrusal regresyon yöntemi kullanmak gerektiğinden çok daha büyük hatalar oluşturabilir.
Parametre sayısı
Parametreler, bir veri bilimcisinin algoritmayı ayarlarken döndürecekleri düğmelerdir. Bunlar, hataya dayanıklılık veya yineleme sayısı gibi algoritmanın davranışını etkileyen sayılar ya da algoritmanın davranış biçimleri arasındaki seçeneklerdir. Algoritmanın eğitim süresi ve doğruluğu bazen doğru ayarları almaya duyarlı olabilir. Genellikle, çok sayıda parametre içeren algoritmalar iyi bir bileşim bulmak için en fazla deneme ve hata gerektirir.
Alternatif olarak, tasarımcıda Tune Model Hyperparameters bileşeni de bulunur. Bu bileşenin amacı, bir makine öğrenmesi modeli için en uygun hiper parametreleri belirlemektir. Bileşen, ayarların farklı bileşimlerini kullanarak birden çok model oluşturur ve test eder. Ayarların kombinasyonlarını elde etmek için tüm modellerdeki ölçümleri karşılaştırır.
Bu, parametre alanını yaydığınızdan emin olmak için harika bir yol olsa da, modeli eğitmek için gereken süre parametre sayısıyla birlikte katlanarak artar. Bunun iyi tarafı, birçok parametreye sahip olmanın genellikle bir algoritmanın daha fazla esnekliğe sahip olduğunu belirtmesidir. Parametre ayarlarının doğru bileşimini bulabilmeniz koşuluyla genellikle çok iyi bir doğruluk elde edebilir.
Özellik sayısı
Makine öğrenmesinde bir özellik, analiz etmeye çalıştığınız fenomenin ölçülebilir bir değişkenidir. Belirli veri türleri için özellik sayısı, veri noktası sayısına kıyasla çok büyük olabilir. Bu durum genellikle genetik veya metinsel veriler için geçerlidir.
Çok sayıda özellik, bazı öğrenme algoritmalarını çökertebilir ve bu da eğitim zamanının uygun olmayan bir şekilde uzun olmasına neden olabilir. Destek vektör makineleri , çok sayıda özelliğe sahip senaryolar için çok uygundur. Bu nedenle, bilgi alımından metin ve görüntü sınıflandırmasına kadar birçok uygulamada kullanılmıştır. Destek vektör makineleri hem sınıflandırma hem de regresyon görevleri için kullanılabilir.
Özellik seçimi, belirtilen bir çıkış verilip girişlere istatistiksel testler uygulama işlemini ifade eder. Amaç, hangi sütunların çıkış için daha tahmine dayalı olduğunu belirlemektir. Tasarımcıdaki Filtre Tabanlı Özellik Seçimi bileşeni, aralarından seçim yapabileceğiniz birden çok özellik seçimi algoritması sağlar. Bileşen, Pearson bağıntısı ve kikare değerleri gibi bağıntı yöntemlerini içerir.
Ayrıca, veri kümeniz için bir dizi özellik önem puanı hesaplamak için Permütasyon Özelliği Önem Derecesi bileşenini de kullanabilirsiniz. Daha sonra bu puanları bir modelde kullanılacak en iyi özellikleri belirlemenize yardımcı olması için kullanabilirsiniz.