Azure Machine Learning ile modeli hiper parametre ayarlama (v1)
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v1
Azure CLI ml uzantısı v1
Önemli
Bu makaledeki Azure CLI komutlarından bazıları Azure Machine Learning için uzantısını veya v1'i kullanır azure-cli-ml. v1 uzantısı desteği 30 Eylül 2025'te sona erecektir. Bu tarihe kadar v1 uzantısını yükleyebilecek ve kullanabileceksiniz.
30 Eylül 2025'e kadar , veya v2 uzantısına geçmenizi mlöneririz. v2 uzantısı hakkında daha fazla bilgi için bkz . Azure ML CLI uzantısı ve Python SDK v2.
Azure Machine Learning (v1) HyperDrive paketini kullanarak verimli hiper parametre ayarlamayı otomatikleştirin. Azure Machine Learning SDK'sı ile hiper parametreleri ayarlamak için gereken adımları tamamlamayı öğrenin:
- Parametre arama alanını tanımlama
- İyileştireceğiniz birincil ölçümü belirtme
- Düşük performanslı çalıştırmalar için erken sonlandırma ilkesi belirtme
- Kaynak oluşturma ve atama
- Tanımlı yapılandırmayla deneme başlatma
- Eğitim çalıştırmalarını görselleştirme
- Modeliniz için en iyi yapılandırmayı seçin
Hiper parametre ayarlama nedir?
Hiper parametreler , model eğitim sürecini denetlemenize olanak sağlayan ayarlanabilir parametrelerdir. Örneğin sinir ağları ile gizli katman sayısına ve her katmandaki düğüm sayısına siz karar verirsiniz. Model performansı büyük ölçüde hiper parametrelere bağlıdır.
Hiper parametre iyileştirmesi olarak da adlandırılan hiper parametre ayarlaması, en iyi performansa neden olan hiper parametre yapılandırmasını bulma işlemidir. İşlem genellikle işlem açısından pahalı ve el ile gerçekleştirilir.
Azure Machine Learning, hiper parametreleri verimli bir şekilde iyileştirmek için hiper parametre ayarlamasını otomatikleştirmenize ve denemeleri paralel olarak çalıştırmanıza olanak tanır.
Arama alanını tanımlama
Her hiper parametre için tanımlanan değer aralığını keşfederek hiper parametreleri ayarlayın.
Hiper parametreler ayrık veya sürekli olabilir ve parametre ifadesi tarafından açıklanan değerlerin dağılımına sahiptir.
Ayrık hiper parametreler
Ayrık hiper parametreler, ayrık değerler arasında belirtilir choice . choice şu olabilir:
- bir veya daha fazla virgülle ayrılmış değer
- nesne
range - herhangi bir rastgele
listnesne
{
"batch_size": choice(16, 32, 64, 128)
"number_of_hidden_layers": choice(range(1,5))
}
Bu durumda, [16, batch_size 32, 64, 128] değerlerinden biri ve number_of_hidden_layers [1, 2, 3, 4] değerlerinden birini alır.
Aşağıdaki gelişmiş ayrık hiper parametreler bir dağıtım kullanılarak da belirtilebilir:
quniform(low, high, q)- Yuvarlak(tekdüzen(düşük, yüksek) / q) * q gibi bir değer verirqloguniform(low, high, q)- Round(exp(uniform(low, high)) / q) * q gibi bir değer döndürürqnormal(mu, sigma, q)- Round(normal(mu, sigma) / q) * q gibi bir değer verirqlognormal(mu, sigma, q)- Round(exp(normal(mu, sigma)) / q) * q gibi bir değer verir
Sürekli hiper parametreler
Sürekli hiper parametreler, sürekli bir değer aralığı üzerinden bir dağıtım olarak belirtilir:
uniform(low, high)- Düşük ve yüksek arasında tekdüzen dağıtılmış bir değer döndürürloguniform(low, high)- Dönüş değerinin logaritmasının tekdüzen olarak dağıtıldığı exp(tekdüzen(düşük, yüksek)) değerine göre çizilmiş bir değer döndürürnormal(mu, sigma)- Normal olarak ortalama mu ve standart sapma sigması ile dağıtılmış gerçek bir değer döndürürlognormal(mu, sigma)- Dönüş değerinin logaritması normal olarak dağıtılmış olacak şekilde exp(normal(mu, sigma)) değerine göre çizilmiş bir değer döndürür
Parametre alanı tanımı örneği:
{
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1)
}
Bu kod iki parametreye sahip bir arama alanı tanımlar: learning_rate ve keep_probability. learning_rate ortalama değeri 10 ve standart sapması 3 olan normal bir dağılıma sahiptir. keep_probability en az 0,05 ve en yüksek değer 0,1 olan tekdüzen bir dağılıma sahiptir.
Hiper parametre alanını örnekleme
Hiper parametre alanı üzerinden kullanılacak parametre örnekleme yöntemini belirtin. Azure Machine Learning aşağıdaki yöntemleri destekler:
- Rastgele örnekleme
- Kılavuz örnekleme
- Bayes örneklemesi
Rastgele örnekleme
Rastgele örnekleme , ayrık ve sürekli hiper parametreleri destekler. Düşük performanslı çalıştırmaların erken sonlandırılmasına destek olur. Bazı kullanıcılar rastgele örneklemeyle ilk aramayı yapar ve ardından sonuçları geliştirmek için arama alanını iyileştirir.
Rastgele örneklemede hiper parametre değerleri tanımlı arama alanından rastgele seçilir.
from azureml.train.hyperdrive import RandomParameterSampling
from azureml.train.hyperdrive import normal, uniform, choice
param_sampling = RandomParameterSampling( {
"learning_rate": normal(10, 3),
"keep_probability": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
Kılavuz örnekleme
Kılavuz örneklemesi ayrı hiper parametreleri destekler. Arama alanında kapsamlı arama yapmak için bütçe ayırabiliyorsanız kılavuz örneklemeyi kullanın. Düşük performanslı çalıştırmaların erken sonlandırılmasına destek sağlar.
Kılavuz örnekleme, tüm olası değerler üzerinde basit bir kılavuz araması yapar. Kılavuz örneklemesi yalnızca hiper parametrelerle choice kullanılabilir. Örneğin, aşağıdaki alanda altı örnek vardır:
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
param_sampling = GridParameterSampling( {
"num_hidden_layers": choice(1, 2, 3),
"batch_size": choice(16, 32)
}
)
Bayes örneklemesi
Bayes örneklemesi , Bayes iyileştirme algoritmasını temel alır. Yeni örneklerin birincil ölçümü geliştirmesi için önceki örneklerin yaptıklarına göre örnekleri seçer.
Hiper parametre alanını keşfetmek için yeterli bütçeniz varsa Bayes örneklemesi önerilir. En iyi sonuçları elde etmek için, ayarlanmış hiper parametre sayısının 20 katı veya daha fazla çalıştırma olmasını öneririz.
Eş zamanlı çalıştırma sayısının, ayarlama işleminin etkinliği üzerinde etkisi vardır. Daha az sayıda eşzamanlı çalıştırma daha iyi örnekleme yakınsamasına yol açabilir, çünkü daha küçük paralellik derecesi daha önce tamamlanan çalıştırmalardan yararlanan çalıştırma sayısını artırır.
Bayes örneklemesi yalnızca arama alanı üzerinde , uniformve quniform dağıtımlarını desteklerchoice.
from azureml.train.hyperdrive import BayesianParameterSampling
from azureml.train.hyperdrive import uniform, choice
param_sampling = BayesianParameterSampling( {
"learning_rate": uniform(0.05, 0.1),
"batch_size": choice(16, 32, 64, 128)
}
)
Birincil ölçümü belirtme
Hiper parametre ayarlamasının iyileştirmesini istediğiniz birincil ölçümü belirtin. Her eğitim çalıştırması birincil ölçüm için değerlendirilir. Erken sonlandırma ilkesi, düşük performanslı çalıştırmaları belirlemek için birincil ölçümü kullanır.
Birincil ölçümünüz için aşağıdaki öznitelikleri belirtin:
primary_metric_name: Birincil ölçümün adının eğitim betiği tarafından günlüğe kaydedilen ölçümün adıyla tam olarak eşleşmesi gerekirprimary_metric_goal: Ya daPrimaryMetricGoal.MAXIMIZEPrimaryMetricGoal.MINIMIZEolabilir ve çalıştırmaları değerlendirirken birincil ölçümün en üst düzeye çıkarılıp büyütülmeyeceğini veya simge durumuna küçültüleceğini belirler.
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
Bu örnek "doğruluğu" en üst düzeye çıkarır.
Hiper parametre ayarlama için günlük ölçümleri
Modelinizin eğitim betiği, HyperDrive'ın hiper parametre ayarlaması için erişebilmesi için model eğitimi sırasında birincil ölçümü günlüğe kaydetmelidir.
Eğitim betiğinizdeki birincil ölçümü aşağıdaki örnek kod parçacığıyla günlüğe alın:
from azureml.core.run import Run
run_logger = Run.get_context()
run_logger.log("accuracy", float(val_accuracy))
Eğitim betiği, öğesini hesaplar val_accuracy ve birincil ölçüm "doğruluk" olarak günlüğe kaydeder. Ölçüm her günlüğe kaydedilişinde hiper parametre ayarlama hizmeti tarafından alınır. Raporlama sıklığını belirlemek size bağlıdır.
Model eğitim çalıştırmalarındaki günlük değerleri hakkında daha fazla bilgi için bkz . Azure Machine Learning eğitim çalıştırmalarında günlüğe kaydetmeyi etkinleştirme.
Erken sonlandırma ilkesini belirtme
Kötü performans gösteren çalıştırmaları otomatik olarak erken sonlandırma ilkesiyle sonlandır. Erken sonlandırma işlem verimliliğini artırır.
İlkenin ne zaman uygulanacağını denetleyebilen aşağıdaki parametreleri yapılandırabilirsiniz:
evaluation_interval: ilkenin uygulanma sıklığı. Eğitim betiği her günlüğe kaydedişinde birincil ölçüm tek aralık olarak sayılır. 1'inden birievaluation_interval, eğitim betiği birincil ölçümü her bildirişinde ilkeyi uygular. İlkeyievaluation_intervalher seferinde 2'nin biri uygular. Belirtilmezse,evaluation_intervalvarsayılan olarak 1 olarak ayarlanır.delay_evaluation: belirtilen aralık sayısı için ilk ilke değerlendirmesini geciktirir. Bu, tüm yapılandırmaların en az sayıda aralıkla çalışmasına izin vererek eğitim çalıştırmalarının erken sonlandırılmasını önleyen isteğe bağlı bir parametredir. Belirtilirse, ilke delay_evaluation'den büyük veya buna eşit evaluation_interval her katını uygular.
Azure Machine Learning aşağıdaki erken sonlandırma ilkelerini destekler:
Eşkıya ilkesi
Eşkıya ilkesi slack faktörünü/bolluk miktarını ve değerlendirme aralığını temel alır. Eşkıya, birincil ölçüm en başarılı çalıştırmanın belirtilen slack faktörü/bolluk miktarı içinde olmadığında çalıştırmaları sonlandırır.
Not
Bayes örneklemesi erken sonlandırmayı desteklemez. Bayes örneklemesini kullanırken değerini ayarlayın early_termination_policy = None.
Aşağıdaki yapılandırma parametrelerini belirtin:
slack_factorveyaslack_amount: en iyi performans gösteren eğitim çalıştırmasına göre izin verilen bolluk.slack_factororan olarak izin verilebilen bolluğu belirtir.slack_amountizin verilebilen bolluğu oran yerine mutlak bir miktar olarak belirtir.Örneğin, 10 aralıkta uygulanan bir Eşkıya ilkesini göz önünde bulundurun. 10 aralıkta en iyi performans gösteren çalıştırmanın birincil ölçümü en üst düzeye çıkarma hedefiyle 0,8 olduğunu varsayalım. İlke 0,2'yi belirtirse
slack_factor, 10 aralığındaki en iyi ölçümü 0,66'dan (0,8/(1+slack_factor)) küçük olan tüm eğitimler sonlandırılır.evaluation_interval: (isteğe bağlı) ilkeyi uygulama sıklığıdelay_evaluation: (isteğe bağlı) belirtilen aralık sayısı için ilk ilke değerlendirmesini geciktirir
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5)
Bu örnekte, erken sonlandırma ilkesi ölçümler raporlandığında her aralıkta uygulanır ve değerlendirme aralığı 5'den başlar. En iyi ölçüm (1/(1+0,1) veya en iyi performans gösteren çalıştırmanın %91'inden küçük olan tüm çalıştırmalar sonlandırılır.
Ortanca durdurma ilkesi
Ortanca durdurma , çalıştırmalar tarafından bildirilen birincil ölçümlerin çalışan ortalamalarını temel alan bir erken sonlandırma ilkesidir. Bu ilke, tüm eğitim çalıştırmalarında çalışan ortalamaları hesaplar ve birincil ölçüm değeri ortalamaların ortanca değerinden daha kötü olan çalıştırmaları durdurur.
Bu ilke aşağıdaki yapılandırma parametrelerini alır:
evaluation_interval: ilkeyi uygulama sıklığı (isteğe bağlı parametre).delay_evaluation: belirtilen aralık sayısı (isteğe bağlı parametre) için ilk ilke değerlendirmesini geciktirir.
from azureml.train.hyperdrive import MedianStoppingPolicy
early_termination_policy = MedianStoppingPolicy(evaluation_interval=1, delay_evaluation=5)
Bu örnekte erken sonlandırma ilkesi, 5 değerlendirme aralığından başlayarak her aralıkta uygulanır. En iyi birincil ölçümü tüm eğitim çalıştırmalarında 1:5 aralıklarıyla çalışan ortalamaların ortanca değerinden daha kötüyse, çalıştırma 5 aralığında durdurulur.
Kesme seçimi ilkesi
Kesme seçimi , her değerlendirme aralığında en düşük performanslı çalıştırma yüzdesini iptal eder. Çalıştırmalar birincil ölçüm kullanılarak karşılaştırılır.
Bu ilke aşağıdaki yapılandırma parametrelerini alır:
truncation_percentage: Her değerlendirme aralığında sonlandıracak en düşük performansa sahip çalıştırmaların yüzdesi. 1 ile 99 arasında bir tamsayı değeri.evaluation_interval: (isteğe bağlı) ilkeyi uygulama sıklığıdelay_evaluation: (isteğe bağlı) belirtilen aralık sayısı için ilk ilke değerlendirmesini geciktirirexclude_finished_jobs: ilkeyi uygularken tamamlanmış işlerin dışlanıp dışlanmayacağını belirtir
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Bu örnekte erken sonlandırma ilkesi, 5 değerlendirme aralığından başlayarak her aralıkta uygulanır. Bir çalıştırma, 5 aralığındaki performansı 5 aralığındaki tüm çalıştırmaların performansının en düşük %20'sindeyse 5 aralığında sonlandırılır ve ilke uygulanırken tamamlanmış işleri dışlar.
Sonlandırma ilkesi yok (varsayılan)
İlke belirtilmezse, hiper parametre ayarlama hizmeti tüm eğitim çalıştırmalarının tamamlanmak üzere yürütülmesini sağlar.
policy=None
Erken sonlandırma ilkesi seçme
- Gelecek vaat eden işleri sonlandırmadan tasarruf sağlayan muhafazakar bir ilke için 1 ve
delay_evaluation5 ileevaluation_intervalOrtanca Durdurma İlkesi'ni göz önünde bulundurun. Bunlar, birincil ölçümde (değerlendirme verilerimize göre) hiçbir kayıp olmadan yaklaşık %25-35 tasarruf sağlayabilen muhafazakar ayarlardır. - Daha agresif tasarruflar için izin verilebilen daha küçük bir bolluk ile Eşkıya İlkesi'ni veya daha büyük kesme yüzdesine sahip Kesme Seçim İlkesi'ni kullanın.
Kaynak oluşturma ve atama
En fazla eğitim çalıştırması sayısını belirterek kaynak bütçenizi denetleyin.
max_total_runs: En fazla eğitim çalıştırması sayısı. 1 ile 1000 arasında bir tamsayı olmalıdır.max_duration_minutes: (isteğe bağlı) Hiper parametre ayarlama denemesinin dakika cinsinden maksimum süresi. Bu sürenin sonundaki çalıştırmalar iptal edilir.
Not
Hem hem de max_total_runs max_duration_minutes belirtilirse, hiper parametre ayarlama denemesi bu iki eşikten ilki ulaşıldığında sonlandırılır.
Ayrıca, hiper parametre ayarlama aramanız sırasında eşzamanlı olarak çalıştırılacak en fazla eğitim çalıştırması sayısını belirtin.
max_concurrent_runs: (isteğe bağlı) Eşzamanlı olarak çalışabilecek en fazla çalıştırma sayısı. Belirtilmezse, tüm çalıştırmalar paralel olarak başlatılır. Belirtilirse, 1 ile 100 arasında bir tamsayı olmalıdır.
Not
Eş zamanlı çalıştırma sayısı, belirtilen işlem hedefinde kullanılabilen kaynaklara bağlıdır. İşlem hedefinin istenen eşzamanlılık için kullanılabilir kaynaklara sahip olduğundan emin olun.
max_total_runs=20,
max_concurrent_runs=4
Bu kod, hiper parametre ayarlama denemesini, aynı anda dört yapılandırma çalıştırarak en fazla 20 toplam çalıştırma kullanacak şekilde yapılandırılır.
Hiper parametre ayarlama denemesi yapılandırma
Hiper parametre ayarlama denemenizi yapılandırmak için aşağıdakileri sağlayın:
- Tanımlanan hiper parametre arama alanı
- Erken sonlandırma ilkeniz
- Birincil ölçüm
- Kaynak ayırma ayarları
- ScriptRunConfig
script_run_config
ScriptRunConfig, örneklenen hiper parametrelerle çalışan eğitim betiğidir. İş başına kaynakları (tek veya çok düğümlü) ve kullanılacak işlem hedefini tanımlar.
Not
içinde script_run_config kullanılan işlem hedefinin eşzamanlılık düzeyinizi karşılamak için yeterli kaynağa sahip olması gerekir. ScriptRunConfig hakkında daha fazla bilgi için bkz . Eğitim çalıştırmalarını yapılandırma.
Hiper parametre ayarlama denemenizi yapılandırın:
from azureml.train.hyperdrive import HyperDriveConfig
from azureml.train.hyperdrive import RandomParameterSampling, BanditPolicy, uniform, PrimaryMetricGoal
param_sampling = RandomParameterSampling( {
'learning_rate': uniform(0.0005, 0.005),
'momentum': uniform(0.9, 0.99)
}
)
early_termination_policy = BanditPolicy(slack_factor=0.15, evaluation_interval=1, delay_evaluation=10)
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
, HyperDriveConfig öğesine geçirilen ScriptRunConfig script_run_configparametreleri ayarlar. sırayla script_run_config, parametreleri eğitim betiğine geçirir. Yukarıdaki kod parçacığı, PyTorch ile eğitme, hiper parametre ayarlama ve dağıtma örnek not defterinden alınmıştır. Bu örnekte learning_rate ve momentum parametreleri ayarlanacaktır. Çalıştırmaların erken durdurulması, birincil ölçümü dışında kalan bir çalıştırmayı durduran bir tarafından BanditPolicybelirlenir (bkz. BanditPolicy sınıf başvurusu).slack_factor
Örnekteki aşağıdaki kod, ayarlı değerlerin nasıl alındığını, ayrıştırıldığını ve eğitim betiğinin fine_tune_model işlevine nasıl geçirildiğini gösterir:
# from pytorch_train.py
def main():
print("Torch version:", torch.__version__)
# get command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument('--num_epochs', type=int, default=25,
help='number of epochs to train')
parser.add_argument('--output_dir', type=str, help='output directory')
parser.add_argument('--learning_rate', type=float,
default=0.001, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='momentum')
args = parser.parse_args()
data_dir = download_data()
print("data directory is: " + data_dir)
model = fine_tune_model(args.num_epochs, data_dir,
args.learning_rate, args.momentum)
os.makedirs(args.output_dir, exist_ok=True)
torch.save(model, os.path.join(args.output_dir, 'model.pt'))
Önemli
Her hiper parametre çalıştırması, modeli ve tüm veri yükleyicilerini yeniden oluşturma dahil olmak üzere eğitimi sıfırdan yeniden başlatır. Eğitim çalıştırmalarınızdan önce mümkün olduğunca çok veri hazırlama işlemi yapmak için Azure Machine Learning işlem hattı veya el ile işlem kullanarak bu maliyeti en aza indirebilirsiniz.
Hiper parametre ayarlama denemesi gönderme
Hiper parametre ayarlama yapılandırmanızı tanımladıktan sonra denemeyi gönderin:
from azureml.core.experiment import Experiment
experiment = Experiment(workspace, experiment_name)
hyperdrive_run = experiment.submit(hd_config)
Sıcak başlangıç hiper parametre ayarı (isteğe bağlı)
Modeliniz için en iyi hiper parametre değerlerini bulmak yinelemeli bir işlem olabilir. Hiper parametre ayarlamasını hızlandırmak için önceki beş çalıştırmadaki bilgileri yeniden kullanabilirsiniz.
Sıcak başlangıç, örnekleme yöntemine bağlı olarak farklı şekilde işlenir:
- Bayes örneklemesi: Önceki çalıştırmadaki denemeler, yeni örnekler seçmek ve birincil ölçümü geliştirmek için önceden bilgi olarak kullanılır.
- Rastgele örnekleme veya kılavuz örnekleme: Erken sonlandırma, düşük performanslı çalıştırmaları belirlemek için önceki çalıştırmalardan gelen bilgileri kullanır.
Sıcak başlangıç yapmak istediğiniz üst çalıştırmaların listesini belirtin.
from azureml.train.hyperdrive import HyperDriveRun
warmstart_parent_1 = HyperDriveRun(experiment, "warmstart_parent_run_ID_1")
warmstart_parent_2 = HyperDriveRun(experiment, "warmstart_parent_run_ID_2")
warmstart_parents_to_resume_from = [warmstart_parent_1, warmstart_parent_2]
Hiper parametre ayarlama denemesi iptal edilirse, eğitim çalıştırmalarını son denetim noktasından sürdürebilirsiniz. Ancak, eğitim betiğinizin denetim noktası mantığını işlemesi gerekir.
Eğitim çalıştırması aynı hiper parametre yapılandırmasını kullanmalıdır ve çıkışlar klasörlerini bağlamalıdır. Eğitim betiği, eğitim çalıştırmasının resume-from sürdürülmesi için denetim noktası veya model dosyalarını içeren bağımsız değişkeni kabul etmelidir. Aşağıdaki kod parçacığını kullanarak tek tek eğitim çalıştırmalarını sürdürebilirsiniz:
from azureml.core.run import Run
resume_child_run_1 = Run(experiment, "resume_child_run_ID_1")
resume_child_run_2 = Run(experiment, "resume_child_run_ID_2")
child_runs_to_resume = [resume_child_run_1, resume_child_run_2]
Hiper parametre ayarlama denemenizi, isteğe bağlı parametreleri kullanarak ve resume_child_runs yapılandırmada önceki denemeden sıcak bir başlangıç yapmak veya tek tek eğitim çalıştırmalarını resume_from sürdürmek için yapılandırabilirsiniz:
from azureml.train.hyperdrive import HyperDriveConfig
hd_config = HyperDriveConfig(run_config=script_run_config,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
resume_from=warmstart_parents_to_resume_from,
resume_child_runs=child_runs_to_resume,
primary_metric_name="accuracy",
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=100,
max_concurrent_runs=4)
Hiper parametre ayarlama çalıştırmalarını görselleştirme
hiper parametre ayarlama çalıştırmalarınızı Azure Machine Learning stüdyosu görselleştirebilir veya bir not defteri pencere öğesi kullanabilirsiniz.
Studio
Azure Machine Learning stüdyosu tüm hiper parametre ayarlama çalıştırmalarınızı görselleştirebilirsiniz. Portalda bir denemeyi görüntüleme hakkında daha fazla bilgi için bkz . Stüdyoda çalıştırma kayıtlarını görüntüleme.
Ölçüm grafiği: Bu görselleştirme, hiper parametre ayarlama süresi boyunca her hiper sürücü alt çalıştırması için günlüğe kaydedilen ölçümleri izler. Her satır bir alt çalıştırmayı temsil eder ve her nokta bu çalışma zamanı yinelemesinde birincil ölçüm değerini ölçer.

Paralel Koordinatlar Grafiği: Bu görselleştirme, birincil ölçüm performansı ile tek tek hiper parametre değerleri arasındaki bağıntıyı gösterir. Grafik, eksenlerin hareketi (eksen etiketine göre seçip sürükleme) ve değerleri tek bir eksende vurgulayarak etkileşimlidir (istenen değer aralığını vurgulamak için tek bir eksen boyunca dikey olarak seçip sürükleyin). Paralel koordinatlar grafiği, grafiğin en sağdaki bölümünde, söz konusu çalıştırma örneği için ayarlanan hiper parametrelere karşılık gelen en iyi ölçüm değerini çizen bir eksen içerir. Bu eksen, grafik gradyan göstergesini verilere daha okunabilir bir şekilde yansıtmak için sağlanır.
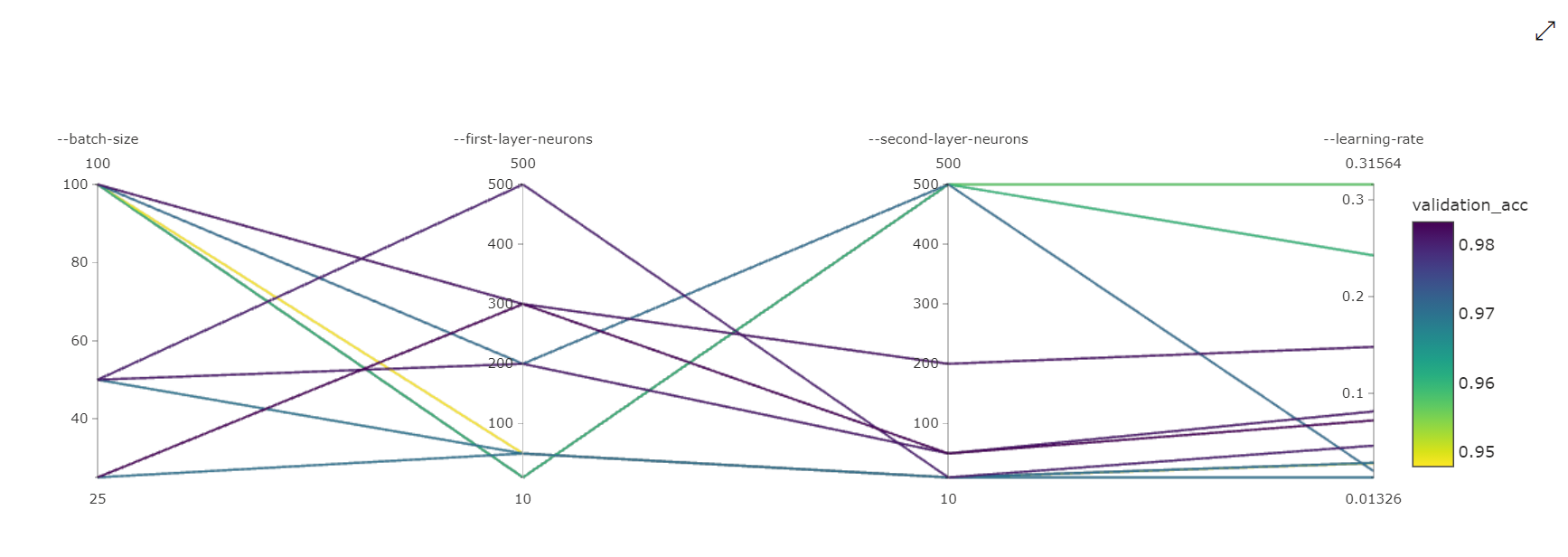
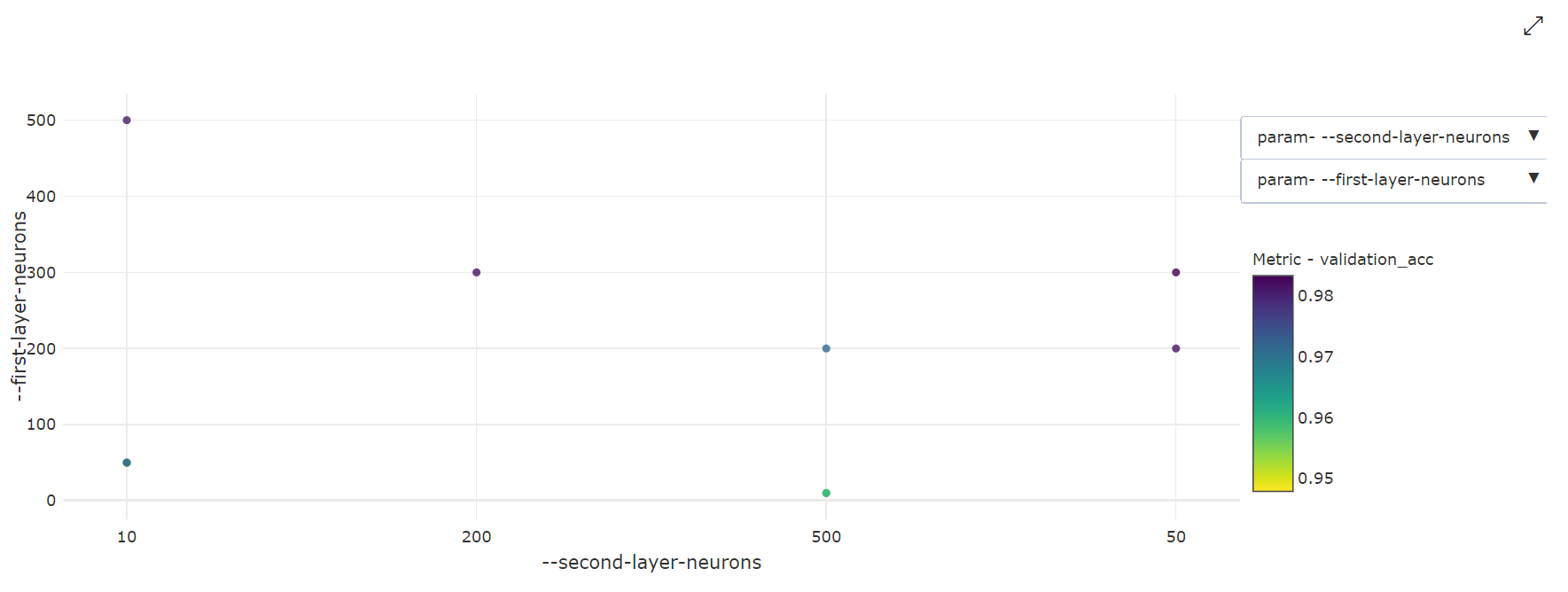
2 Boyutlu Dağılım Grafiği: Bu görselleştirme, ilişkili birincil ölçüm değeriyle birlikte her iki hiper parametre arasındaki bağıntıyı gösterir.
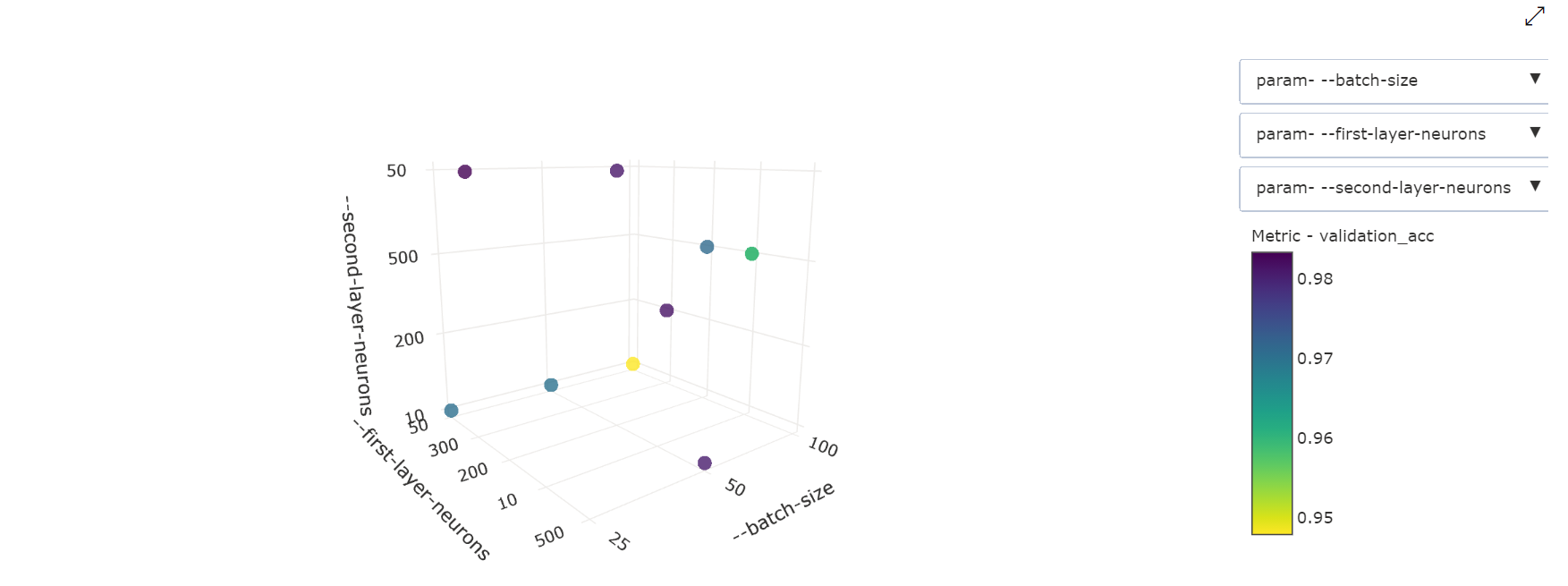
3 Boyutlu Dağılım Grafiği: Bu görselleştirme 2B ile aynıdır, ancak birincil ölçüm değeriyle bağıntının üç hiper parametre boyutuna izin verir. 3B alanda farklı bağıntıları görüntülemek üzere grafiği yeniden ayarlamak için de seçip sürükleyebilirsiniz.
Not defteri pencere öğesi
Eğitim çalıştırmalarınızın ilerleme durumunu görselleştirmek için Not Defteri pencere öğesini kullanın. Aşağıdaki kod parçacığı, jupyter not defterinde tüm hiper parametre ayarlama çalıştırmalarınızı tek bir yerde görselleştirir:
from azureml.widgets import RunDetails
RunDetails(hyperdrive_run).show()
Bu kod, hiper parametre yapılandırmalarının her biri için eğitim çalıştırmalarıyla ilgili ayrıntıları içeren bir tablo görüntüler.
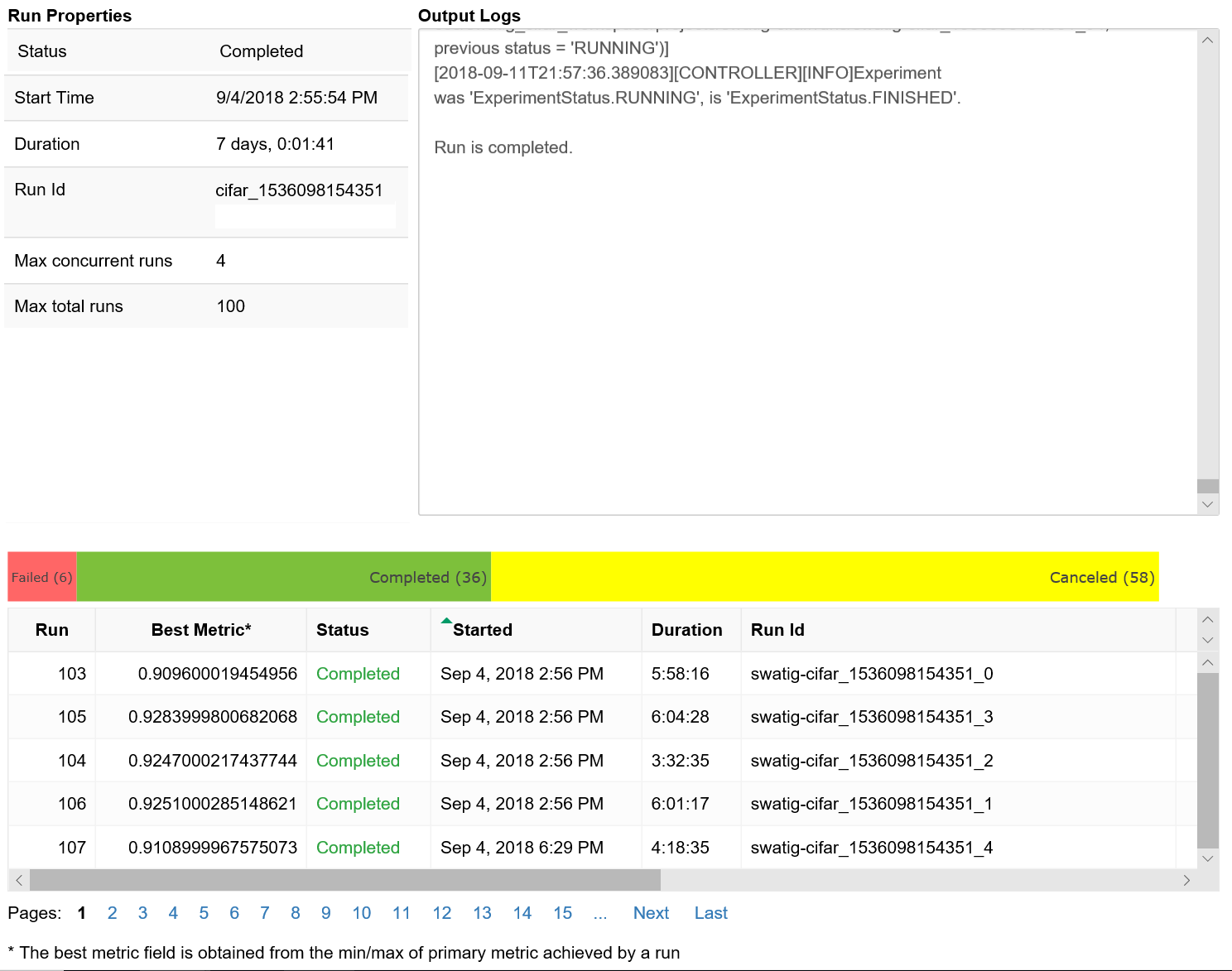
Ayrıca, eğitim ilerledikçe her çalıştırmanın performansını görselleştirebilirsiniz.
En iyi modeli bulma
Tüm hiper parametre ayarlama çalıştırmaları tamamlandıktan sonra en iyi performansa sahip yapılandırmayı ve hiper parametre değerlerini belirleyin:
best_run = hyperdrive_run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details()['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print('\n Accuracy:', best_run_metrics['accuracy'])
print('\n learning rate:',parameter_values[3])
print('\n keep probability:',parameter_values[5])
print('\n batch size:',parameter_values[7])
Örnek not defteri
Bu klasördeki train-hyperparameter-* not defterlerine bakın:
Not defterlerini çalıştırmayı öğrenmek için bkz. Hizmeti keşfetmek için Jupyter not defterlerini kullanma.