Otomatik makine öğrenmesi denemesi sonuçlarını değerlendirme
Bu makalede, otomatik makine öğrenmesi (otomatik ML) denemeniz tarafından eğitilen modelleri değerlendirmeyi ve karşılaştırmayı öğrenin. Otomatik ml denemesi boyunca birçok iş oluşturulur ve her iş bir model oluşturur. Otomatik ML her model için, modelin performansını ölçmenize yardımcı olan değerlendirme ölçümleri ve grafikleri oluşturur. Varsayılan olarak önerilen en iyi modelin bütünsel değerlendirmesini ve hata ayıklamasını yapmak için sorumlu bir yapay zeka panosu oluşturabilirsiniz. Buna model açıklamaları, eşitlik ve performans gezgini, veri gezgini, model hata analizi gibi içgörüler dahildir. Sorumlu yapay zeka panosu oluşturma hakkında daha fazla bilgi edinin.
Örneğin, otomatik ML deneme türüne göre aşağıdaki grafikleri oluşturur.
Önemli
Bu makalede işaretlenen (önizleme) öğeler şu anda genel önizleme aşamasındadır. Önizleme sürümü bir hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için önerilmez. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Önkoşullar
- Azure aboneliği. (Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun)
- Aşağıdakilerden biriyle oluşturulmuş bir Azure Machine Learning denemesi:
İş sonuçlarını görüntüleme
Otomatik ML denemeniz tamamlandıktan sonra işlerin geçmişine şu aracılığıyla ulaşabilirsiniz:
- Azure Machine Learning stüdyosu içeren bir tarayıcı
- JobDetails Jupyter pencere öğesini kullanan bir Jupyter not defteri
Aşağıdaki adımlar ve videoda, çalışma geçmişini ve model değerlendirme ölçümlerini ve grafiklerini stüdyoda nasıl görüntüleyebileceğiniz gösterilmektedir:
- Stüdyoda oturum açın ve çalışma alanınıza gidin.
- Soldaki menüde İşler'i seçin.
- Deneme listesinden denemenizi seçin.
- Sayfanın en altındaki tabloda otomatik bir ML işi seçin.
- Modeller sekmesinde, değerlendirmek istediğiniz modelin Algoritma adını seçin.
- Ölçümler sekmesinde, soldaki onay kutularını kullanarak ölçümleri ve grafikleri görüntüleyin.
Sınıflandırma ölçümleri
Otomatik ML, denemeniz için oluşturulan her sınıflandırma modeli için performans ölçümlerini hesaplar. Bu ölçümler scikit learn uygulamasını temel alır.
İki sınıf üzerinde ikili sınıflandırma için birçok sınıflandırma ölçümü tanımlanır ve çok sınıflı sınıflandırma için bir puan oluşturmak için sınıflar üzerinde ortalama gerektirir. Scikit-learn, üç otomatik ML'nin kullanıma sunduğu çeşitli ortalama yöntemleri sağlar: makro, mikro ve ağırlıklı.
- Makro - Her sınıf için ölçümü hesaplama ve ağırlıksız ortalamayı alma
- Mikro - Toplam gerçek pozitifleri, hatalı negatifleri ve hatalı pozitifleri (sınıflardan bağımsız) sayarak ölçümü genel olarak hesaplayın.
- Ağırlıklı - Her sınıf için ölçümü hesaplayın ve sınıf başına örnek sayısına göre ağırlıklı ortalamayı alın.
Her ortalama yönteminin avantajları olsa da, uygun yöntem seçilirken dikkat edilmesi gerekenlerden biri sınıf dengesizliğidir. Sınıfların farklı sayıda örneği varsa, azınlık sınıflarına çoğunluk sınıflarına eşit ağırlık verilen bir makro ortalaması kullanmak daha bilgilendirici olabilir. Otomatik ML'de ikili ve çok sınıflı ölçümler hakkında daha fazla bilgi edinin.
Aşağıdaki tabloda, denemeniz için oluşturulan her sınıflandırma modeli için otomatik ML'nin hesap yaptığı model performans ölçümleri özetlemektedir. Daha fazla ayrıntı için her ölçümün Hesaplama alanında bağlantılı scikit-learn belgelerine bakın.
Not
Görüntü sınıflandırma modellerine yönelik ölçümlerle ilgili ek ayrıntılar için görüntü ölçümleri bölümüne bakın.
| Metrik Sistem | Açıklama | Hesaplama |
|---|---|---|
| AUC | AUC, Alıcı çalışma özelliği eğrisinin altındaki alandır. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] Desteklenen ölçüm adları şunlardır: AUC_macro, her sınıf için AUC'nin aritmetik ortalaması.AUC_micro, toplam gerçek pozitifleri, hatalı negatifleri ve hatalı pozitifleri sayarak hesaplanır. AUC_weighted, her sınıf için puanın aritmetik ortalaması, her sınıftaki doğru örneklerin sayısına göre ağırlıklıdır. AUC_binary, belirli bir sınıfı sınıf olarak ele alarak ve diğer tüm sınıfları sınıf olarak true false birleştirerek AUC değeri. |
Hesaplama |
| accuracy | Doğruluk, gerçek sınıf etiketleriyle tam olarak eşleşen tahminlerin oranıdır. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] |
Hesaplama |
| average_precision | Ortalama duyarlık, her eşikte elde edilen duyarlıkların ağırlıklı ortalaması olarak bir duyarlık-geri çağırma eğrisini özetler ve ağırlık olarak kullanılan önceki eşikten geri çekme artışı elde eder. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] Desteklenen ölçüm adları şunlardır: average_precision_score_macro, her sınıfın ortalama duyarlık puanının aritmetik ortalaması.average_precision_score_micro, toplam gerçek pozitifleri, hatalı negatifleri ve hatalı pozitifleri sayarak hesaplanır.average_precision_score_weighted, her sınıf için ortalama duyarlık puanının aritmetik ortalaması, her sınıftaki gerçek örneklerin sayısına göre ağırlıklıdır. average_precision_score_binary, belirli bir sınıfı sınıf olarak değerlendirerek ve diğer tüm sınıfları sınıf olarak true false birleştirerek ortalama duyarlık değeri. |
Hesaplama |
| balanced_accuracy | Dengeli doğruluk, her sınıf için aritmetik geri çağırma ortalamasıdır. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] |
Hesaplama |
| f1_score | F1 puanı, duyarlık ve yakalamanın harmonik ortalamasıdır. Hem hatalı pozitif hem de hatalı negatiflerin dengeli bir ölçüsüdür. Ancak gerçek negatifleri hesaba katmıyor. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] Desteklenen ölçüm adları şunlardır: f1_score_macro: Her sınıf için F1 puanının aritmetik ortalaması. f1_score_micro: toplam gerçek pozitifleri, hatalı negatifleri ve hatalı pozitifleri sayarak hesaplanır. f1_score_weighted: Her sınıf için F1 puanının sınıf sıklığına göre ağırlıklı ortalama. f1_score_binary, belirli bir sınıfı sınıf olarak değerlendirerek ve diğer tüm sınıfları sınıf olarak true false birleştirerek f1 değerini verir. |
Hesaplama |
| log_loss | Bu, (çok terimli) lojistik regresyonda ve sinir ağları gibi uzantılarında kullanılan kayıp işlevidir ve olasılığa dayalı sınıflandırıcının tahminleri göz önüne alındığında gerçek etiketlerin negatif günlük olasılığı olarak tanımlanır. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) |
Hesaplama |
| norm_macro_recall | Normalleştirilmiş makro geri çağırma makro ortalaması alınır ve normalleştirilir, böylece rastgele performansın puanı 0, mükemmel performansın puanı 1 olur. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] |
(recall_score_macro - R) / (1 - R) where, R rastgele tahminler için beklenen değeridir recall_score_macro .R = 0.5 ikili sınıflandırma için. R = (1 / C) C sınıfı sınıflandırma sorunları için. |
| matthews_correlation | Matthews korelasyon katsayısı, bir sınıfta diğerinden çok daha fazla örnek olsa bile kullanılabilen dengeli bir doğruluk ölçüsüdür. 1 katsayısı mükemmel tahmini, 0 rastgele tahmini ve -1 ters tahmini gösterir. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [-1, 1] |
Hesaplama |
| duyarlık | Duyarlık, bir modelin negatif örneklerin pozitif olarak etiketlenmesinden kaçınma özelliğidir. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] Desteklenen ölçüm adları şunlardır: precision_score_macro, her sınıf için aritmetik duyarlık ortalaması. precision_score_micro, toplam gerçek pozitifleri ve hatalı pozitifleri sayarak genel olarak hesaplanır. precision_score_weighted, her sınıf için aritmetik duyarlık ortalaması, her sınıftaki doğru örneklerin sayısına göre ağırlıklıdır. precision_score_binary, belirli bir sınıfı sınıf olarak değerlendirerek ve diğer tüm sınıfları sınıf olarak true false birleştirerek duyarlık değeri. |
Hesaplama |
| yakalama | Hatırlayın, bir modelin tüm pozitif örnekleri algılama özelliğidir. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] Desteklenen ölçüm adları şunlardır: recall_score_macro: her sınıf için aritmetik geri çağırma ortalaması. recall_score_micro: toplam gerçek pozitifler, hatalı negatifler ve hatalı pozitifler sayılarak genel olarak hesaplanır.recall_score_weighted: Her sınıf için aritmetik geri çağırma ortalaması, her sınıftaki gerçek örneklerin sayısına göre ağırlıklıdır. recall_score_binary, belirli bir sınıfı sınıf olarak değerlendirip diğer tüm sınıfları sınıf olarak true false birleştirerek geri çağırmanın değeridir. |
Hesaplama |
| weighted_accuracy | Ağırlıklı doğruluk, her örneğin aynı sınıfa ait toplam örnek sayısına göre ağırlıklandırıldığı doğruluktır. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [0, 1] |
Hesaplama |
İkili ve çok sınıflı sınıflandırma ölçümleri karşılaştırması
Otomatik ML, verilerin ikili olup olmadığını otomatik olarak algılar ve ayrıca bir true sınıf belirterek verilerin çok sınıflı olmasına rağmen kullanıcıların ikili sınıflandırma ölçümlerini etkinleştirmesine olanak tanır. Bir veri kümesinin iki veya daha fazla sınıfı varsa çok sınıflı sınıflandırma ölçümleri bildirilir. İkili sınıflandırma ölçümleri yalnızca veriler ikili olduğunda bildirilir.
Çok sınıflı sınıflandırma ölçümlerinin çok sınıflı sınıflandırma için tasarlandığına dikkat edin. İkili veri kümesine uygulandığında, bu ölçümler herhangi bir sınıfı beklediğiniz gibi sınıf olarak true işlemez. Çok sınıflı ölçümler için açıkça belirtilmiş olan ölçümler , macroveya weightedile microson eklenmiştir. Örnek olarak average_precision_score, f1_score, precision_score, recall_scoreve verilebilir AUC. Örneğin, geri çağırmayı olarak tp / (tp + fn)hesaplamak yerine, çok sınıflı ortalamalı geri çağırma (micro, macroveya weighted) ikili sınıflandırma veri kümesinin her iki sınıfının ortalamasını alır. Bu, sınıfın ve sınıfın geri çağırmasını true ayrı ayrı hesaplamaya false ve ardından ikisinin ortalamasını almaya eşdeğerdir.
Ayrıca, ikili sınıflandırmanın otomatik olarak algılanması desteklense de, ikili sınıflandırma ölçümlerinin doğru sınıf için hesaplandığından true emin olmak için sınıfı her zaman el ile belirtmeniz önerilir.
Veri kümesi çok sınıflı olduğunda ikili sınıflandırma veri kümelerinin ölçümlerini etkinleştirmek için kullanıcıların yalnızca sınıf olarak true kabul edilecek sınıfı belirtmesi gerekir ve bu ölçümler hesaplanır.
Karışıklık matrisi
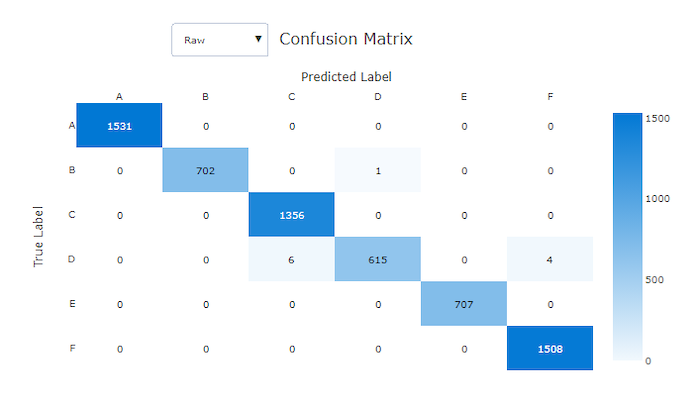
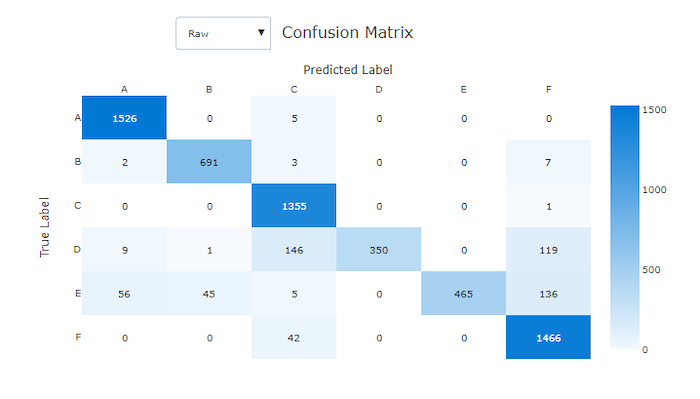
Karışıklık matrisleri, makine öğrenmesi modelinin sınıflandırma modellerine yönelik tahminlerinde nasıl sistematik hatalar yaptığını gösteren bir görsel sağlar. Addaki "karışıklık" sözcüğü, "kafa karıştırıcı" veya yanlış etiketlenmiş bir modelden gelir. Karışıklık matrisindeki satır i ve sütundaki j hücre, değerlendirme veri kümesinde sınıfına ait olan ve model tarafından sınıf C_i C_jolarak sınıflandırılan örnek sayısını içerir.
Stüdyoda, daha koyu bir hücre daha fazla örnek sayısını gösterir. Açılan listede Normalleştirilmiş görünümün seçilmesi, her matris satırına göre normalleştirilerek sınıfın C_i sınıfı olacağı C_jtahmin edilen yüzdesini gösterir. Varsayılan Ham görünümün avantajı, gerçek sınıfların dağılımındaki dengesizliklerin modelin azınlık sınıfından örnekleri yanlış sınıflandırmasına neden olup olmadığını görebilmenizdir. Bu, dengesiz veri kümelerinde sık karşılaşılan bir sorundur.
İyi bir modelin karışıklık matrisinde çapraz boyunca çoğu örnek bulunur.
İyi bir model için karışıklık matrisi
Hatalı bir model için karışıklık matrisi
ROC eğrisi
Alıcı çalışma özelliği (ROC) eğrisi, karar eşiği değiştikçe gerçek pozitif oran (TPR) ile hatalı pozitif oran (FPR) arasındaki ilişkiyi çizer. ROC eğrisi, yüksek sınıf dengesizliği olan veri kümeleri üzerinde modelleri eğitirken daha az bilgilendirici olabilir, çoğunluk sınıfı azınlık sınıflarının katkılarını boğabilir.
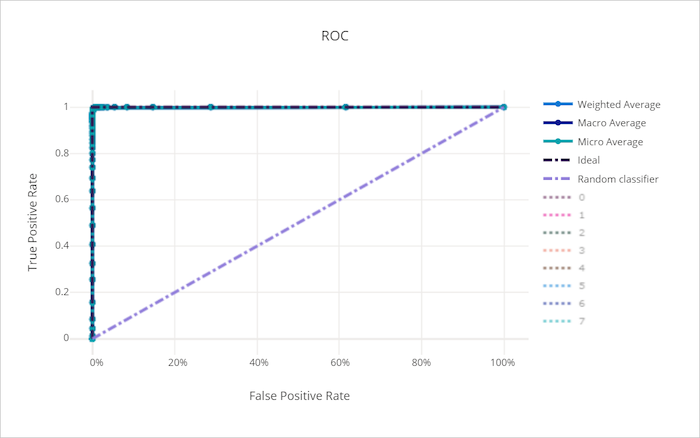
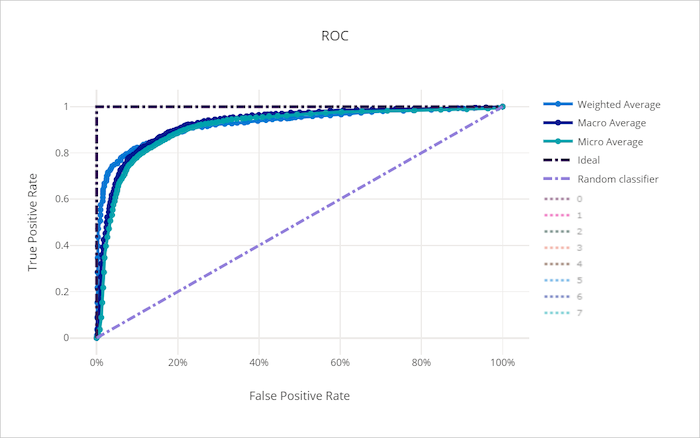
Eğrinin altındaki alan (AUC), doğru sınıflandırılmış örneklerin oranı olarak yorumlanabilir. Daha kesin olarak, AUC, sınıflandırıcının rastgele seçilen pozitif bir örneği rastgele seçilen negatif örnekten daha yüksek dereceleme olasılığıdır. Eğrinin şekli, sınıflandırma eşiğinin veya karar sınırının bir işlevi olarak TPR ile FPR arasındaki ilişki için bir sezgi verir.
Grafiğin sol üst köşesine yaklaşan bir eğri, mümkün olan en iyi model olan %100 TPR ve %0 FPR'ye yaklaşıyor. Rastgele bir model, sol alt köşeden sağ üst köşeye y = x doğru çizgi boyunca bir ROC eğrisi üretir. Rastgele modellerden daha kötü bir model, çizginin altına inen bir ROC eğrisine y = x sahip olabilir.
İpucu
Sınıflandırma denemeleri için, otomatik ML modelleri için üretilen çizgi grafiklerin her biri, modeli sınıf başına değerlendirmek veya tüm sınıflara göre ortalamasını almak için kullanılabilir. Grafiğin sağındaki göstergede sınıf etiketlerine tıklayarak bu farklı görünümler arasında geçiş yapabilirsiniz.
İyi bir model için ROC eğrisi
Kötü bir model için ROC eğrisi
Duyarlık-geri çağırma eğrisi
Duyarlık-geri çağırma eğrisi, karar eşiği değiştikçe duyarlık ve geri çağırma arasındaki ilişkiyi çizer. Hatırlayacağınız üzere modelin tüm pozitif örnekleri algılama özelliği ve duyarlık, modelin negatif örnekleri pozitif olarak etiketlemekten kaçınma özelliğidir. Bazı iş sorunları, hatalı negatiflerden ve hatalı pozitiflerden kaçınmanın göreli önemine bağlı olarak daha yüksek geri çağırma ve biraz daha yüksek hassasiyet gerektirebilir.
İpucu
Sınıflandırma denemeleri için, otomatik ML modelleri için üretilen çizgi grafiklerin her biri, modeli sınıf başına değerlendirmek veya tüm sınıflara göre ortalamasını almak için kullanılabilir. Grafiğin sağındaki göstergede sınıf etiketlerine tıklayarak bu farklı görünümler arasında geçiş yapabilirsiniz.
İyi bir model için duyarlık-geri çağırma eğrisi
Hatalı bir model için duyarlık yakalama eğrisi
Kümülatif kazanımlar eğrisi
Kümülatif kazançlar eğrisi, örnekleri tahmin edilen olasılık sırasına göre dikkate aldığımız örnek yüzdesinin işlevi olarak doğru sınıflandırılan pozitif örneklerin yüzdesini çizer.
Kazancı hesaplamak için öncelikle model tarafından tahmin edilen en yüksekten en düşük olasılığa kadar tüm örnekleri sıralayın. Ardından en yüksek güvenilirlik tahminlerini alın x% . Bu değerde x% algılanan pozitif örneklerin sayısını, kazancı elde etmek için toplam pozitif örnek sayısına bölün. Kümülatif kazanç, pozitif sınıfa ait olma olasılığı en yüksek olan verilerin yüzde bir kısmını değerlendirirken algıladığımız pozitif örneklerin yüzdesidir.
Mükemmel bir model, tüm pozitif örnekleri tüm negatif örneklerin üzerinde sıralar ve iki düz segmentten oluşan bir kümülatif kazanç eğrisi verir. birincisi, pozitif sınıfa (x, 1) x ait örneklerin kesirini (1 / num_classessınıflar dengeliyse) olan eğimli 1 / x (0, 0) bir çizgidir. İkincisi, ile olan (x, 1) (1, 1)yatay çizgidir. İlk segmentte, tüm pozitif örnekler doğru sınıflandırılır ve kümülatif kazanç, değerlendirilen örneklerin ilki x% içinde yer alır100%.
Taban çizgisi rastgele modeli, yalnızca toplam pozitif örnekler hakkında x% değerlendirilen örneklerin algılandığı bir x% kümülatif kazanç eğrisine y = x sahiptir. Dengeli bir veri kümesi için mükemmel bir model, bir mikro ortalama eğrisine ve kümülatif kazanç %100'e kadar eğime num_classes sahip bir makro ortalama çizgisine ve veri yüzdesi 100'e gelene kadar yatay değere sahiptir.
İpucu
Sınıflandırma denemeleri için, otomatik ML modelleri için üretilen çizgi grafiklerin her biri, modeli sınıf başına değerlendirmek veya tüm sınıflara göre ortalamasını almak için kullanılabilir. Grafiğin sağındaki göstergede sınıf etiketlerine tıklayarak bu farklı görünümler arasında geçiş yapabilirsiniz.
İyi bir model için kümülatif kazanç eğrisi
Kötü bir model için kümülatif kazanç eğrisi
Yükseltme eğrisi
Kaldırma eğrisi, bir modelin rastgele modele kıyasla kaç kat daha iyi performans gösterdiğini gösterir. Lift, kümülatif kazancın rastgele bir modelin kümülatif kazancına oranı olarak tanımlanır (her zaman olmalıdır 1).
Bu göreli performans, sınıf sayısını artırdıkça sınıflandırmanın daha zor hale geldiğini dikkate alır. (Rastgele model, iki sınıflı bir veri kümesine kıyasla 10 sınıflı bir veri kümesinden alınan örneklerin daha yüksek bir bölümünü yanlış tahmin eder)
Taban çizgisi kaldırma eğrisi, y = 1 model performansının rastgele bir modelle tutarlı olduğu çizgidir. Genel olarak, iyi bir modelin lift eğrisi bu grafikte daha yüksektir ve x ekseninden daha uzaktır ve modelin tahminlerine en çok güvendiği zaman rastgele tahminden çok daha iyi performans gösterdiğini gösterir.
İpucu
Sınıflandırma denemeleri için, otomatik ML modelleri için üretilen çizgi grafiklerin her biri, modeli sınıf başına değerlendirmek veya tüm sınıflara göre ortalamasını almak için kullanılabilir. Grafiğin sağındaki göstergede sınıf etiketlerine tıklayarak bu farklı görünümler arasında geçiş yapabilirsiniz.
İyi bir model için lift curve
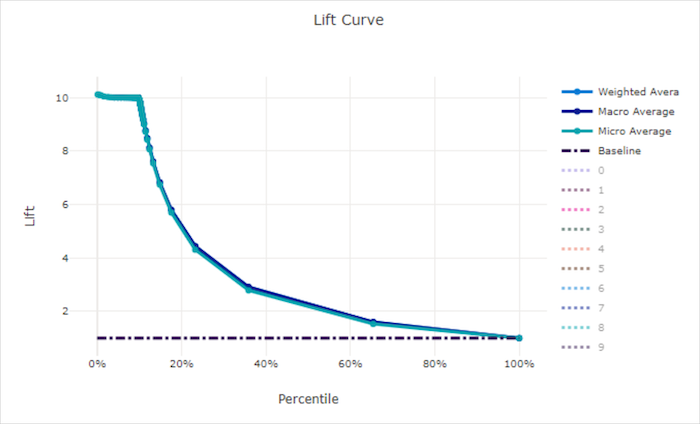
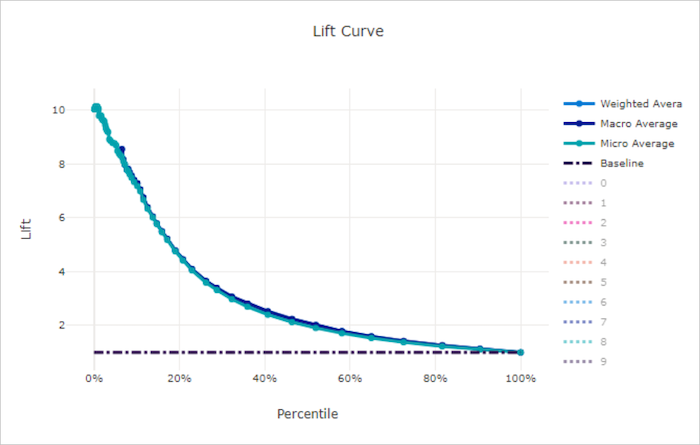
Kötü bir model için eğriyi kaldırma
Kalibrasyon eğrisi
Kalibrasyon eğrisi, modelin tahminlerine olan güvenini her güvenilirlik düzeyindeki pozitif örneklerin oranına göre çizer. İyi kalibre edilmiş bir model, %100 güvenilirlik atadığı tahminlerin %100'ünün, %50 güvenilirlik atadığı tahminlerin %50'sinin, %20 güvenilirlik atadığı tahminlerin %20'sinin vb. doğru bir şekilde sınıflandıracaktır. Mükemmel şekilde kalibre edilmiş bir model, modelin y = x her sınıfa ait olma olasılığını mükemmel bir şekilde tahmin ettiği çizgiyi izleyen bir kalibrasyon eğrisine sahiptir.
Aşırı güvenilir bir model sıfıra ve bire yakın olasılıkları tahmin eder, nadiren her bir örneğin sınıfı hakkında belirsizdir ve kalibrasyon eğrisi geriye dönük "S" ile benzer görünür. Kendinden emin olmayan bir model, tahminde bulunan sınıfa ortalama olarak daha düşük bir olasılık atar ve ilişkili kalibrasyon eğrisi bir "S" ile benzer görünür. Kalibrasyon eğrisi, modelin doğru sınıflandırma yeteneğini değil, tahminlerine doğru güvenilirlik atama becerisini gösterir. Model doğru şekilde düşük güvenilirlik ve yüksek belirsizlik atadıysa kötü bir model iyi bir kalibrasyon eğrisine sahip olabilir.
Not
Kalibrasyon eğrisi örnek sayısına duyarlıdır, bu nedenle küçük bir doğrulama kümesi yorumlanması zor olabilecek gürültülü sonuçlar üretebilir. Bu, modelin iyi kalibre edilmediği anlamına gelmez.
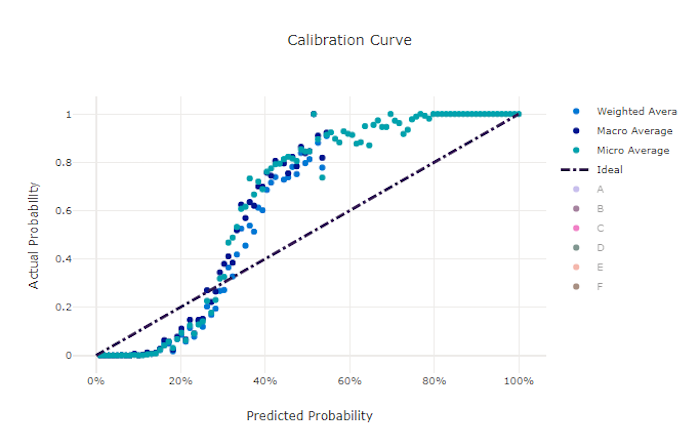
İyi bir model için kalibrasyon eğrisi
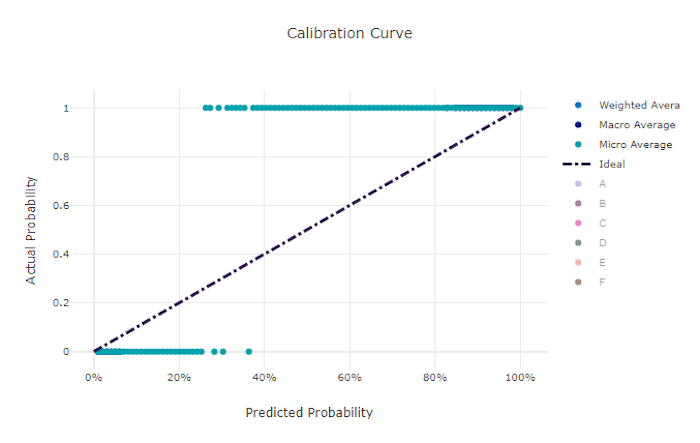
Hatalı bir model için kalibrasyon eğrisi
Regresyon/tahmin ölçümleri
Otomatik ML, bir regresyon veya tahmin denemesi olup olmadığına bakılmaksızın oluşturulan her model için aynı performans ölçümlerini hesaplar. Bu ölçümler, farklı aralıklara sahip veriler üzerinde eğitilen modeller arasında karşılaştırma yapmak için de normalleştirmeden geçer. Daha fazla bilgi edinmek için bkz . ölçüm normalleştirme.
Aşağıdaki tabloda regresyon ve tahmin denemeleri için oluşturulan model performans ölçümleri özetlenmiştir. Sınıflandırma ölçümleri gibi bu ölçümler de scikit learn uygulamalarını temel alır. Hesaplama alanında uygun scikit learn belgeleri buna uygun şekilde bağlanır.
| Metrik Sistem | Açıklama | Hesaplama |
|---|---|---|
| explained_variance | Açıklanan varyans, modelin hedef değişkendeki varyasyonu ne ölçüde hesapladığına ilişkin ölçüler. Bu, özgün verilerin varyansında hataların varyansına yüzde azalmadır. Hataların ortalaması 0 olduğunda, belirleme katsayısına eşittir (aşağıdaki grafikte r2_score bakın). Amaç: 1'e daha yakınsa o kadar iyi Aralık: (-inf, 1] |
Hesaplama |
| mean_absolute_error | Ortalama mutlak hata, hedefle tahmin arasındaki mutlak fark değerinin beklenen değeridir. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) Tür: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error veri aralığına bölünür. |
Hesaplama |
| mean_absolute_percentage_error | Ortalama mutlak yüzde hatası (MAPE), tahmin edilen değerle gerçek değer arasındaki ortalama farkın ölçüsüdür. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) |
|
| median_absolute_error | Ortanca mutlak hata, hedef ve tahmin arasındaki tüm mutlak farklılıkların ortanca değeridir. Bu kayıp aykırı değerler için güçlüdür. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) Tür: median_absolute_errornormalized_median_absolute_error: median_absolute_error veri aralığına bölünür. |
Hesaplama |
| r2_score | R2 (belirleme katsayısı), gözlemlenen verilerin toplam varyansına göre ortalama kare hatasının (MSE) orantılı azalmasını ölçer. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [-1, 1] Not: R2 genellikle (-inf, 1] aralığına sahiptir. MSE gözlemlenen varyanstan daha büyük olabilir, bu nedenle R2 , verilere ve model tahminlerine bağlı olarak rastgele olarak büyük negatif değerlere sahip olabilir. Otomatik ML klipleri R2 puanlarını -1 olarak bildirdiği için R2 için -1 değeri büyük olasılıkla gerçek R2 puanının -1'den küçük olduğu anlamına gelir. Negatif R2 puanını yorumlarken diğer ölçüm değerlerini ve verilerin özelliklerini göz önünde bulundurun. |
Hesaplama |
| root_mean_squared_error | Kök ortalama kare hatası (RMSE), hedefle tahmin arasındaki beklenen karekök farkının karekökünü oluşturur. Taraflı olmayan bir tahmin aracı için RMSE, standart sapmaya eşittir. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) Tür: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error veri aralığına bölünür. |
Hesaplama |
| root_mean_squared_log_error | Kök ortalama kare günlük hatası, beklenen kare logaritmik hatanın karekökünü oluşturur. Amaç: 0'a ne kadar yakınsa o kadar iyi Aralık: [0, inf) Tür: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error veri aralığına bölünür. |
Hesaplama |
| spearman_correlation | Spearman bağıntısı, iki veri kümesi arasındaki ilişkinin monotonluğuna ilişkin birparametrik olmayan ölçüdür. Pearson bağıntısının aksine Spearman bağıntısı her iki veri kümesinin de normal olarak dağıtıldığını varsaymaz. Diğer korelasyon katsayıları gibi Spearman da -1 ile 1 arasında değişir ve 0 bağıntı olmadığını gösterir. -1 veya 1 bağıntıları tam bir monoton ilişki anlamına geliyor. Spearman, tahmin edilen veya gerçek değerlere yapılan değişikliklerin, tahmin edilen veya gerçek değerlerin sıralama sırasını değiştirmemesi durumunda Spearman sonucunu değiştirmeyeceği anlamına gelen derece sırası bağıntı ölçümüdür. Amaç: 1'e daha yakınsa o kadar iyi Aralık: [-1, 1] |
Hesaplama |
Ölçüm normalleştirmesi
Otomatik ML, regresyon ve tahmin ölçümlerini normalleştirerek farklı aralıklara sahip veriler üzerinde eğitilen modeller arasında karşılaştırma sağlar. Daha geniş bir aralığı olan bir veri üzerinde eğitilen model, hata normalleştirilmediği sürece daha küçük bir aralıkta eğitilen aynı modelden daha yüksek hataya sahiptir.
Hata ölçümlerini normalleştirmenin standart bir yöntemi olmasa da otomatik ML, hatayı veri aralığına bölmek için yaygın bir yaklaşım benimser: normalized_error = error / (y_max - y_min)
Not
Veri aralığı modelle birlikte kaydedilmez. Bir bekleme testi kümesinde y_min aynı modelle çıkarım yaparsanız ve y_max test verilerine göre değişebilirseniz ve normalleştirilmiş ölçümler modelin eğitim ve test kümelerindeki performansını karşılaştırmak için doğrudan kullanılamayabilir. Karşılaştırmayı adil hale getirmek için eğitim kümenizden ve y_max değerini y_min geçirebilirsiniz.
Tahmin ölçümleri: normalleştirme ve toplama
Tahmin modeli değerlendirmesi için ölçümlerin hesaplanması, veriler birden çok zaman serisi içerdiğinde dikkat edilmesi gereken bazı özel noktalar gerektirir. Ölçümleri birden çok seri üzerinden toplamaya yönelik iki doğal seçenek vardır:
- Her serideki değerlendirme ölçümlerine eşit ağırlık verildiği makro ortalaması,
- Her tahmin için değerlendirme ölçümlerinin eşit ağırlığa sahip olduğu mikro ortalama .
Bu durumlar, çok sınıflı sınıflandırmada makroya ve mikro ortalamaya doğrudan benzetmelere sahiptir.
Model seçimi için birincil ölçüm seçilirken makro ile mikro ortalama arasındaki ayrım önemli olabilir. Örneğin, çeşitli tüketici ürünlerine yönelik talebi tahmin etmek istediğiniz perakende senaryolarını göz önünde bulundurun. Bazı ürünler diğerlerinden daha yüksek hacimlerde satmaktadır. Birincil ölçüm olarak mikro ortalamalı bir RMSE seçerseniz, yüksek hacimli öğeler modelleme hatasının büyük bir bölümüne katkıda bulunur ve dolayısıyla ölçüme hakim olabilir. Model seçim algoritması, yüksek hacimli öğelerde düşük hacimli öğelere göre daha yüksek doğruluk oranına sahip modelleri tercih edebilir. Buna karşılık, makro ortalaması alınmış, normalleştirilmiş BIR RMSE, düşük hacimli öğelere yüksek hacimli öğelere yaklaşık olarak eşit ağırlık verir.
Aşağıdaki tabloda AutoML'nin tahmin ölçümlerinden hangilerinin makro veya mikro ortalama kullandığını listelemektedir:
| Makro ortalaması | Mikro ortalama |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, , root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Makro ortalaması ölçümlerinin her seriyi ayrı ayrı normalleştirdiğini unutmayın. Ardından, son sonucu vermek için her seriden normalleştirilmiş ölçümlerin ortalaması alınır. Makro ile mikro arasında doğru seçim iş senaryosuna bağlıdır, ancak genellikle kullanmanızı normalized_root_mean_squared_erroröneririz.
Fazlalıklar
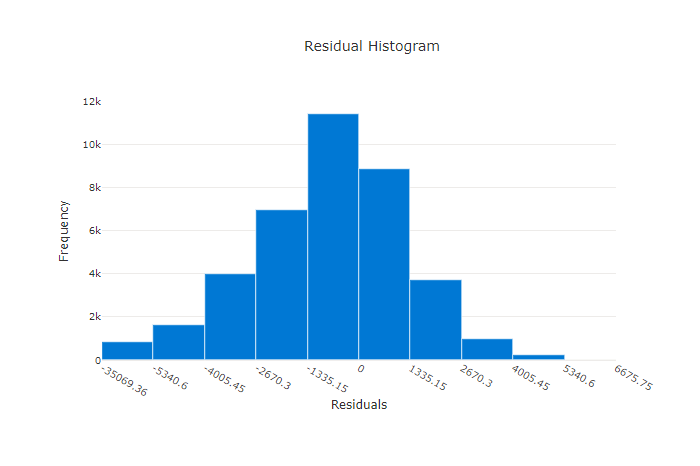
Artıklar grafiği, regresyon ve tahmin denemeleri için oluşturulan tahmin hatalarının (artıklar) histogramıdır. Artıklar tüm örnekler için hesaplanır y_predicted - y_true ve ardından model sapmasını göstermek için histogram olarak görüntülenir.
Bu örnekte, her iki model de gerçek değerden daha düşük tahminde bulunur. Bu, gerçek hedeflerin çarpık dağılımına sahip bir veri kümesi için yaygın değildir, ancak model performansının daha kötü olduğunu gösterir. İyi bir model, uç noktalarda az sayıda artık ile sıfırda zirveye inen artık dağılımına sahiptir. Daha kötü bir modelde, sıfır civarında daha az örnek içeren artık dağılımı yayılır.
İyi bir model için artıklar grafiği
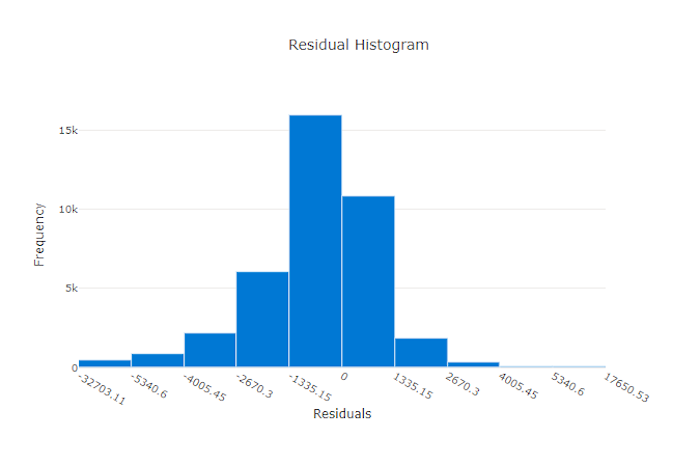
Hatalı bir model için artıklar grafiği
Tahmin edilen ve gerçek
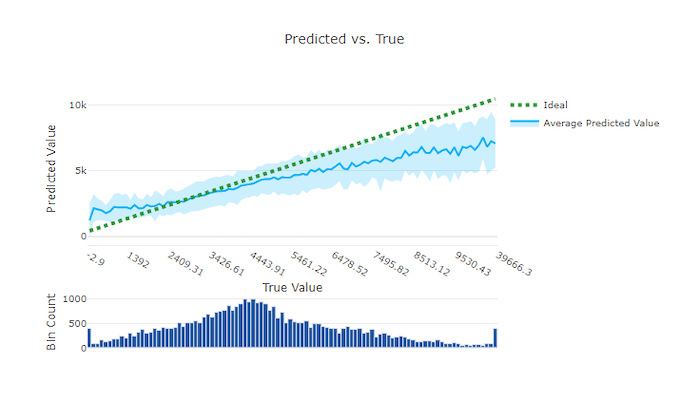
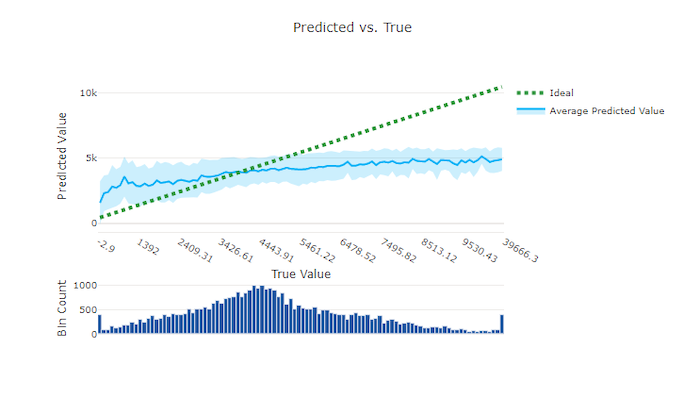
Regresyon ve tahmin denemesi için tahmin edilen ve doğru olan grafik, hedef özellik (doğru/gerçek değerler) ile modelin tahminleri arasındaki ilişkiyi çizer. Gerçek değerler x ekseni boyunca gruplandırılır ve her bölme için ortalama tahmin edilen değer hata çubuklarıyla çizilir. Bu, modelin belirli değerleri tahmin etme konusunda taraflı olup olmadığını görmenizi sağlar. Çizgi, ortalama tahmini görüntüler ve gölgeli alan bu ortalamanın etrafındaki tahminlerin varyansını gösterir.
Genellikle en yaygın gerçek değer, en düşük varyansa sahip en doğru tahminlere sahiptir. Eğilim çizgisinin, çok az gerçek değerin bulunduğu ideal y = x çizgiden uzaklığı, aykırı değerler üzerinde model performansının iyi bir ölçüsüdür. Gerçek veri dağılımını belirlemek için grafiğin altındaki histogramı kullanabilirsiniz. Dağıtımın seyrek olduğu daha fazla veri örneği dahil olmak, görünmeyen verilerde model performansını artırabilir.
Bu örnekte, daha iyi modelin ideal y = x çizgiye daha yakın bir tahmin edilen ve gerçek çizgiye sahip olduğunu unutmayın.
İyi bir model için tahmin edilen ve gerçek grafik karşılaştırması
Kötü bir model için tahmin edilen ve gerçek grafik karşılaştırması
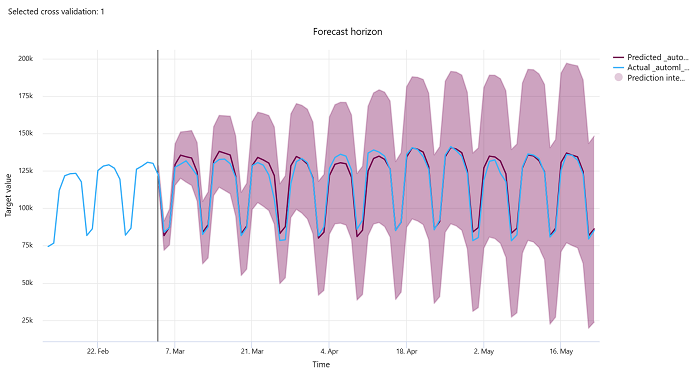
Tahmin ufku
Tahmin denemeleri için tahmin ufku grafiği, tahmin edilen değer ile çapraz doğrulama katlama başına zaman içinde eşlenen gerçek değerler arasındaki ilişkiyi en fazla beş kat çizer. X ekseni, eğitim kurulumu sırasında sağladığınız sıklık temelinde zamanı eşler. Grafikteki dikey çizgi, tahminleri oluşturmaya başlamak istediğiniz zaman aralığı olan ufuk çizgisi olarak da adlandırılan tahmin ufuk noktasını işaretler. Tahmin ufuk çizgisinin solunda geçmiş eğilimleri daha iyi görselleştirmek için geçmiş eğitim verilerini görüntüleyebilirsiniz. Tahmin ufkunun sağındaki tahminleri (mor çizgi) farklı çapraz doğrulama katları ve zaman serisi tanımlayıcıları için gerçek değerlere (mavi çizgi) göre görselleştirebilirsiniz. Gölgeli mor alan, bu ortalamanın etrafındaki tahminlerin olasılık aralıklarını veya varyansını gösterir.
Grafiğin sağ üst köşesindeki düzenlenmiş kalem simgesine tıklayarak hangi çapraz doğrulama katlama ve zaman serisi tanımlayıcı birleşimlerinin görüntüleneceğini seçebilirsiniz. Çeşitli zaman serilerinizin grafiğini görselleştirmek için ilk beş çapraz doğrulama katlama ve 20'ye kadar farklı zaman serisi tanımlayıcısı arasından seçim yapın.
Önemli
Bu grafik hem eğitim ve doğrulama verilerinden oluşturulan modeller için eğitim çalıştırmasında hem de eğitim verilerine ve test verilerine dayalı test çalıştırmasında kullanılabilir. Tahmin kaynağından önce en fazla 20 veri noktasına ve tahmin kaynağından sonra en fazla 80 veri noktasına izin veririz. DNN modellerinde, eğitim çalıştırmasında yer alan bu grafik, modelin tamamen eğitildikten sonra son dönem verilerini gösterir. Eğitim çalıştırması sırasında doğrulama verileri açıkça sağlanmışsa test çalıştırmasında bu grafik ufuk çizgisinin önünde boşluk olabilir. Bunun nedeni, test çalıştırmasında eğitim verileri ve test verilerinin kullanılması ve doğrulama verilerinin boşluğa neden olmasıdır.
Görüntü modelleri için ölçümler (önizleme)
Otomatik ML, modelin performansını değerlendirmek için doğrulama veri kümesindeki görüntüleri kullanır. Eğitimin nasıl ilerlettiğini anlamak için modelin performansı dönem düzeyinde ölçülür. Bir veri kümesinin tamamı sinir ağı üzerinden tam olarak bir kez ileri ve geri geçirildiğinde bir dönem geçer.
Görüntü sınıflandırma ölçümleri
Değerlendirme için birincil ölçüm, ikili ve çok sınıflı sınıflandırma modellerinin doğruluğu ve çok etiketli sınıflandırma modelleri için IoU (Birleşim üzerinde Kesişim) ölçümüdür. Görüntü sınıflandırma modellerinin sınıflandırma ölçümleri, sınıflandırma ölçümleri bölümünde tanımlanan ölçümlerle aynıdır. Bir dönemle ilişkili kayıp değerleri de günlüğe kaydedilir ve bu da eğitimin nasıl ilerlediğini izlemeye ve modelin aşırı uygun mu yoksa yetersiz mi olduğunu belirlemeye yardımcı olabilir.
Sınıflandırma modelindeki her tahmin, tahminin yapıldığı güvenilirlik düzeyini gösteren bir güvenilirlik puanıyla ilişkilendirilir. Çok etiketli görüntü sınıflandırma modelleri varsayılan olarak 0,5 puan eşiğiyle değerlendirilir, yani yalnızca bu güven düzeyine sahip tahminler ilişkili sınıf için pozitif bir tahmin olarak kabul edilir. Çok sınıflı sınıflandırma puan eşiği kullanmaz, ancak bunun yerine en yüksek güvenilirlik puanına sahip sınıf tahmin olarak kabul edilir.
Görüntü sınıflandırması için dönem düzeyinde ölçümler
Tablosal veri kümelerinin sınıflandırma ölçümlerinden farklı olarak, görüntü sınıflandırma modelleri tüm sınıflandırma ölçümlerini aşağıda gösterildiği gibi bir dönem düzeyinde günlüğe kaydeder.

Görüntü sınıflandırma için özet ölçümler
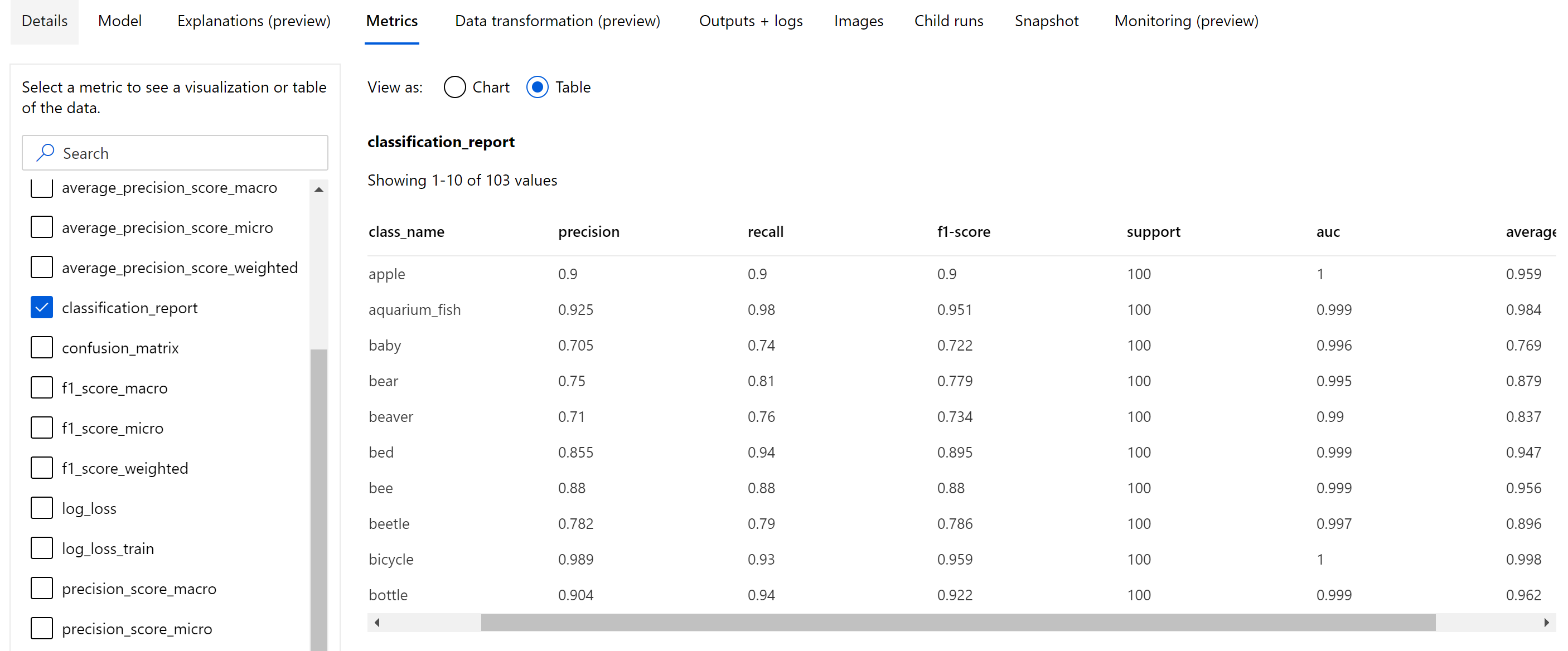
Görüntü sınıflandırma modeli, dönem düzeyinde günlüğe kaydedilen skaler ölçümlerin dışında karışıklık matrisi, ROC eğrisi dahil sınıflandırma grafikleri, duyarlık-geri çağırma eğrisi ve en yüksek birincil ölçüm (doğruluk) puanını aldığımız en iyi dönem için model için sınıflandırma raporu gibi özet ölçümleri de günlüğe kaydeder.
Sınıflandırma raporu aşağıda gösterildiği gibi duyarlık, yakalama, f1 puanı, destek, auc ve average_precision gibi çeşitli ortalama düzeyine (mikro, makro ve ağırlıklı) sahip ölçümler için sınıf düzeyinde değerler sağlar. Sınıflandırma ölçümleri bölümündeki ölçüm tanımlarına bakın.
Nesne algılama ve örnek segmentasyonu ölçümleri
Bir görüntü nesnesi algılama veya örnek segmentasyonu modelinden gelen her tahmin bir güvenilirlik puanıyla ilişkilendirilir.
Puan eşiğinden daha yüksek güvenilirlik puanına sahip tahminler tahmin olarak çıkar ve varsayılan değeri modele özgü olan ve hiper parametre ayarlama sayfasından (box_score_threshold hiper parametre) başvurulabilen ölçüm hesaplamasında kullanılır.
Görüntü nesnesi algılama ve örnek segmentasyonu modelinin ölçüm hesaplaması, yer gerçeği ile tahminler arasındaki çakışma alanını yer gerçeği ile tahminler arasındaki birleşim alanı ile tahminler arasında bölerek hesaplanan IoU (Birleşim Üzerinde Kesişim) adlı ölçüm tarafından tanımlanan bir çakışma ölçümünü temel alır. Her tahminden hesaplanan IoU, bir tahminin pozitif tahmin olarak kabul edilmesi için kullanıcı açıklamalı bir temel gerçekle ne kadar çakışması gerektiğini belirleyen IoU eşiği adı verilen bir çakışma eşiğiyle karşılaştırılır. Tahminden hesaplanan IoU çakışma eşiğinden küçükse, tahmin ilişkili sınıf için pozitif bir tahmin olarak kabul edilmez.
Görüntü nesnesi algılama ve örnek segmentasyon modellerinin değerlendirilmesi için birincil ölçüm ortalama ortalama duyarlıktır (mAP). mAP, tüm sınıflarda ortalama duyarlık (AP) ortalama değeridir. Otomatik ML nesne algılama modelleri, aşağıdaki iki popüler yöntemi kullanarak mAP hesaplamasını destekler.
Pascal VOC ölçümleri:
Pascal VOC mAP, nesne algılama/örnek segmentasyonu modelleri için mAP hesaplamasının varsayılan yoludur. Pascal VOC stili mAP yöntemi, precision-recall eğrisinin bir sürümünün altındaki alanı hesaplar. İlk p(ri), geri çağırma sırasında duyarlık olan tüm benzersiz geri çağırma değerleri için hesaplanır. p(ri) daha sonra herhangi bir geri çağırma r' >= ri için elde edilen maksimum duyarlık ile değiştirilir. Eğrinin bu sürümünde duyarlık değeri monoton olarak azalıyor. Pascal VOC mAP ölçümü varsayılan olarak 0,5 IoU eşiğiyle değerlendirilir. Bu kavramın ayrıntılı bir açıklaması bu blogda bulunabilir.
COCO ölçümleri:
COCO değerlendirme yöntemi , AP hesaplaması için 101 noktalı ilişkilendirilmiş bir yöntem ve on üzerinde IoU eşiğinin ortalamasını kullanır. AP@[.5:.95] 0,5 ile 0,95 olan ve adım boyutu 0,05 olan ortalama IoU AP'sine karşılık gelir. Otomatik ML, AP ve AR (ortalama geri çağırma) dahil olmak üzere COCO yöntemi tarafından tanımlanan 12 ölçümün tümünü uygulama günlüklerindeki çeşitli ölçeklerde günlüğe kaydederken, ölçümler kullanıcı arabirimi 0,5 ioU eşiğinde yalnızca mAP'yi gösterir.
İpucu
Görüntü nesnesi algılama modeli değerlendirmesi, hiper parametrenin hiper parametre ayarlama bölümünde açıklandığı gibi 'coco' olarak ayarlanması durumunda validation_metric_type coco ölçümlerini kullanabilir.
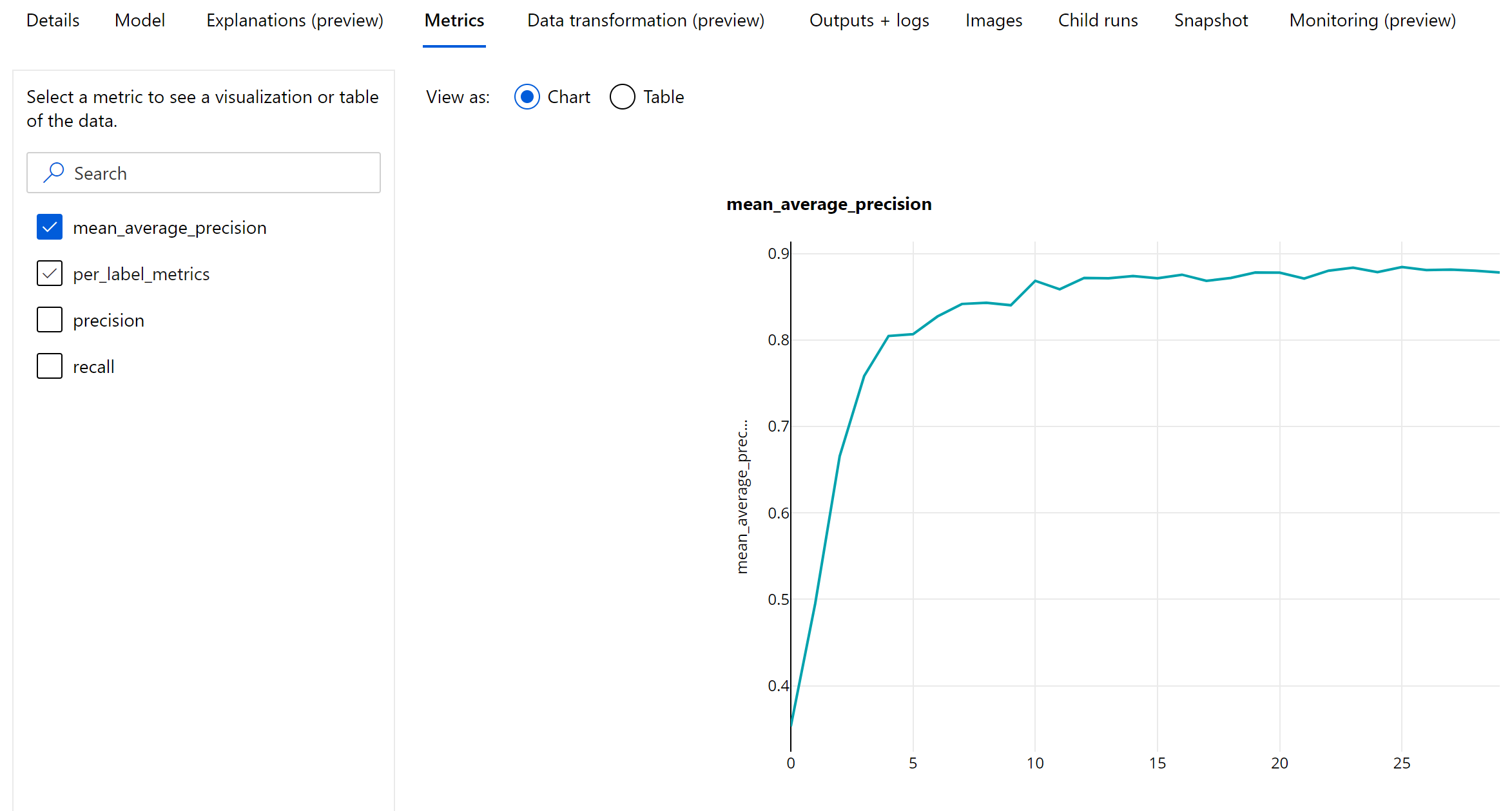
Nesne algılama ve örnek segmentasyonu için dönem düzeyinde ölçümler
mAP, duyarlık ve geri çağırma değerleri, görüntü nesnesi algılama/örnek segmentasyonu modelleri için bir dönem düzeyinde günlüğe kaydedilir. MAP, duyarlık ve geri çağırma ölçümleri de 'per_label_metrics' adıyla sınıf düzeyinde günlüğe kaydedilir. 'per_label_metrics' tablo olarak görüntülenmelidir.
Not
Duyarlık, geri çağırma ve per_label_metrics için dönem düzeyinde ölçümler 'coco' yöntemi kullanılırken kullanılamaz.
En iyi önerilen AutoML modeli için sorumlu yapay zeka panosu (önizleme)
Azure Machine Learning Sorumlu Yapay Zeka panosu, Sorumlu yapay zekayı uygulamada etkili ve verimli bir şekilde uygulamanıza yardımcı olacak tek bir arabirim sağlar. Sorumlu yapay zeka panosu yalnızca tablo verileri kullanılarak desteklenir ve yalnızca sınıflandırma ve regresyon modellerinde desteklenir. Aşağıdaki alanlarda çeşitli olgun Sorumlu Yapay Zeka araçlarını bir araya getirir:
- Model performansı ve eşitlik değerlendirmesi
- Veri keşfi
- Makine öğrenmesi yorumlanabilirliği
- Hata analizi
Model değerlendirme ölçümleri ve grafikleri bir modelin genel kalitesini ölçmek için iyi olsa da modelin eşitliğini inceleme, açıklamalarını görüntüleme (modelin tahminlerini yapmak için hangi veri kümesinin kullanıldığı olarak da bilinir), sorumlu yapay zekayı uygularken hatalarının ve olası kör noktaların incelenmesi temel önem taşır. Bu nedenle otomatik ML, modelinize yönelik çeşitli içgörüleri gözlemlemenize yardımcı olacak sorumlu bir yapay zeka panosu sağlar. Azure Machine Learning stüdyosu Sorumlu yapay zeka panosunu görüntülemeyi öğrenin.
Bu panoyu kullanıcı arabirimi veya SDK aracılığıyla nasıl oluşturabileceğinizi görün.
Model açıklamaları ve özellik önemleri
Model değerlendirme ölçümleri ve grafikleri modelin genel kalitesini ölçmek için iyi olsa da, sorumlu yapay zeka alıştırması yaparken modelin tahminde bulunmak için hangi veri kümesi özelliklerini kullandığını incelemek önemlidir. Bu nedenle otomatik ML, veri kümesi özelliklerinin göreli katkılarını ölçmek ve raporlamak için bir model açıklamaları panosu sağlar. Azure Machine Learning stüdyosu açıklamalar panosunu görüntülemeyi öğrenin.
Not
En iyi model açıklaması olan yorumlanabilirlik, aşağıdaki algoritmaları en iyi model veya topluluk olarak öneren otomatik ML tahmin denemeleri için kullanılamaz:
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Peygamber
- Ortalama
- Saf
- Mevsim Ortalaması
- Mevsim Naif
Sonraki adımlar
- Otomatik makine öğrenmesi modeli açıklaması örnek not defterlerini deneyin.
- Ml'ye özgü otomatik sorular için adresine askautomatedml@microsoft.comulaşın.