Toplu iş uç noktalarındaki puanlama modellerini dağıtma
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Batch uç noktaları, büyük hacimli veriler üzerinde çıkarım çalıştıran modelleri dağıtmak için kullanışlı bir yol sağlar. Bu uç noktalar, modellerinizi toplu puanlama için barındırma sürecini basitleştirerek altyapı yerine makine öğrenmesine odaklanmanızı sağlar.
Aşağıdaki durumlarda model dağıtımı için toplu iş uç noktalarını kullanın:
- Çıkarım çalıştırmak için daha uzun süre gerektiren pahalı modelleriniz var.
- Birden çok dosyaya dağıtılan büyük miktarda veriden çıkarım yapmanız gerekir.
- Düşük gecikme süresi gereksinimleriniz yoktur.
- Paralelleştirmeden yararlanabilirsiniz.
Bu makalede, klasik MNIST (Değiştirilmiş Ulusal Standartlar ve Teknoloji Enstitüsü) basamak tanıma sorununu çözen bir makine öğrenmesi modeli dağıtmak için toplu iş uç noktası kullanacaksınız. Dağıtılan modeliniz daha sonra büyük miktarlardaki veriler (bu örnekte görüntü dosyaları) üzerinden toplu çıkarım gerçekleştirir. İlk olarak Torch kullanılarak oluşturulmuş bir modelin toplu dağıtımını oluşturursunuz. Bu dağıtım, uç noktada varsayılan dağıtım olur. Daha sonra, TensorFlow (Keras) ile oluşturulan bir modun ikinci dağıtımını oluşturur, ikinci dağıtımı test eder ve ardından uç noktanın varsayılan dağıtımı olarak ayarlarsınız.
Bu makaledeki komutları yerel olarak çalıştırmak için gereken kod örnekleri ve dosyaları takip etmek için Örnekleri kopyalama deposu bölümüne bakın. Kod örnekleri ve dosyaları azureml-examples deposunda bulunur.
Önkoşullar
Bu makaledeki adımları izlemeden önce aşağıdaki önkoşullara sahip olduğunuzdan emin olun:
Azure aboneliği. Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü deneyin.
Azure Machine Learning çalışma alanı. Yoksa, oluşturmak için Çalışma alanlarını yönetme makalesindeki adımları kullanın.
Aşağıdaki görevleri gerçekleştirmek için çalışma alanında bu izinlere sahip olduğunuzdan emin olun:
Toplu iş uç noktalarını ve dağıtımlarını oluşturmak/yönetmek için: Sahip rolünü, katkıda bulunan rolünü veya izin veren
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*özel bir rolü kullanın.Çalışma alanı kaynak grubunda ARM dağıtımları oluşturmak için: Çalışma alanının dağıtıldığı kaynak grubunda izin veren
Microsoft.Resources/deployments/writesahip rolü, katkıda bulunan rolü veya özel bir rol kullanın.
Azure Machine Learning ile çalışmak için aşağıdaki yazılımı yüklemeniz gerekir:
ŞUNLAR IÇIN GEÇERLIDIR:
Azure CLI ml uzantısı v2 (geçerli)Azure CLI ve
mlAzure Machine Learning uzantısı.az extension add -n ml
Örnek deposunu kopyalama
Bu makaledeki örnek, azureml-examples deposunda yer alan kod örneklerini temel alır. YAML ve diğer dosyaları kopyalamak/yapıştırmak zorunda kalmadan komutları yerel olarak çalıştırmak için önce depoyu kopyalayın ve ardından dizinleri klasöre değiştirin:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Sisteminizi hazırlama
Çalışma alanınıza bağlanma
İlk olarak, çalışacağınız Azure Machine Learning çalışma alanına bağlanın.
Azure CLI için varsayılan ayarları henüz ayarlamadıysanız varsayılan ayarlarınızı kaydedin. Aboneliğinizin, çalışma alanınızın, kaynak grubunuzun ve konumunuzun değerlerini birden çok kez geçirmemek için şu kodu çalıştırın:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
İşlem oluşturma
Batch uç noktaları işlem kümelerinde çalışır ve hem Azure Machine Learning işlem kümelerini (AmlCompute) hem de Kubernetes kümelerini destekler. Kümeler paylaşılan bir kaynaktır, bu nedenle bir küme bir veya birden çok toplu dağıtım barındırabilir (isterseniz diğer iş yükleriyle birlikte).
Aşağıdaki kodda gösterildiği gibi adlı batch-clusterbir işlem oluşturun. gerektiği gibi ayarlayabilir ve kullanarak azureml:<your-compute-name>işlemlerinize başvurabilirsiniz.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Not
Bir toplu iş uç noktası çağrılana ve toplu puanlama işi gönderilene kadar küme 0 düğümde kaldığından bu noktada işlem için ücret alınmaz. İşlem maliyetleri hakkında daha fazla bilgi için bkz . AmlCompute maliyetini yönetme ve iyileştirme.
Toplu iş uç noktası oluşturma
Toplu iş uç noktası, istemcilerin toplu puanlama işini tetiklemesi için çağırabileceği bir HTTPS uç noktasıdır. Toplu puanlama işi , birden çok girişi puanlayan bir iştir. Toplu dağıtım , gerçek toplu puanlama (veya toplu çıkarım) yapan modeli barındıran işlem kaynakları kümesidir. Bir toplu iş uç noktasının birden çok toplu dağıtımları olabilir. Toplu iş uç noktaları hakkında daha fazla bilgi için bkz . Toplu iş uç noktaları nedir?.
İpucu
Toplu dağıtımlardan biri, uç nokta için varsayılan dağıtım görevi görür. Uç nokta çağrıldığında, varsayılan dağıtım gerçek toplu puanlama işlemini yapar. Toplu iş uç noktaları ve dağıtımları hakkında daha fazla bilgi için bkz . toplu iş uç noktaları ve toplu dağıtım.
Uç noktayı adlandırın. Uç noktanın adı, uç noktanın URI'sine eklendiğinden azure bölgesinde benzersiz olmalıdır. Örneğin, içinde
westus2adımybatchendpointolan tek bir toplu iş uç noktası olabilir.Toplu iş uç noktasını yapılandırma
Aşağıdaki YAML dosyası bir toplu iş uç noktasını tanımlar. Bu dosyayı batch uç noktası oluşturmak için CLI komutuyla kullanabilirsiniz.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningAşağıdaki tabloda uç noktanın temel özellikleri açıklanmaktadır. Tam toplu iş uç noktası YAML şeması için bkz . CLI (v2) toplu uç noktası YAML şeması.
Tuş Açıklama nameToplu iş uç noktasının adı. Azure bölge düzeyinde benzersiz olması gerekir. descriptionToplu iş uç noktasının açıklaması. Bu özellik isteğe bağlıdır. tagsUç noktaya eklenecek etiketler. Bu özellik isteğe bağlıdır. Uç noktayı oluşturun:
Toplu dağıtım oluşturma
Model dağıtımı, gerçek çıkarım yapan modeli barındırmak için gereken bir kaynak kümesidir. Toplu iş modeli dağıtımı oluşturmak için aşağıdaki öğelere ihtiyacınız vardır:
- Çalışma alanında kayıtlı bir model
- Modeli puanlayanın kodu
- Modelin bağımlılıklarının yüklü olduğu bir ortam
- Önceden oluşturulmuş işlem ve kaynak ayarları
Dağıtılacak modeli kaydederek başlayın. Popüler rakam tanıma sorunu (MNIST) için bir Torch modeli. Batch Dağıtımları yalnızca çalışma alanına kayıtlı modelleri dağıtabilir. Dağıtmak istediğiniz model zaten kayıtlıysa bu adımı atlayabilirsiniz.
İpucu
Modeller, uç nokta yerine dağıtımla ilişkilendirilir. Bu, farklı modellerin (veya model sürümlerinin) farklı dağıtımlarda dağıtılma şartıyla, tek bir uç noktanın aynı uç nokta altında farklı modellere (veya model sürümlerine) hizmet verebileceği anlamına gelir.
Şimdi bir puanlama betiği oluşturmanın zamanı geldi. Toplu dağıtımlar, belirli bir modelin nasıl yürütülmesi gerektiğini ve giriş verilerinin nasıl işlenmesi gerektiğini gösteren bir puanlama betiği gerektirir. Batch uç noktaları Python'da oluşturulan betikleri destekler. Bu durumda, basamakları temsil eden görüntü dosyalarını okuyan ve karşılık gelen rakamı veren bir model dağıtırsınız. Puanlama betiği aşağıdaki gibidir:
Not
MLflow modellerinde Azure Machine Learning puanlama betiğini otomatik olarak oluşturur, bu nedenle bir betik sağlamanız gerekmez. Modeliniz bir MLflow modeliyse bu adımı atlayabilirsiniz. Toplu iş uç noktalarının MLflow modelleriyle nasıl çalıştığı hakkında daha fazla bilgi için Toplu dağıtımlarda MLflow modellerini kullanma makalesine bakın.
Uyarı
Toplu iş uç noktası altında Otomatik makine öğrenmesi (AutoML) modeli dağıtıyorsanız, AutoML'nin sağladığı puanlama betiğinin yalnızca çevrimiçi uç noktalar için çalıştığını ve toplu yürütme için tasarlanmadığını unutmayın. Toplu dağıtımınız için puanlama betiği oluşturma hakkında bilgi için bkz . Toplu dağıtımlar için puanlama betikleri yazma.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Toplu dağıtımınızın çalıştırılacağı bir ortam oluşturun. Ortamın toplu iş uç noktaları için gerekli olan paketleri
azureml-coreveazureml-dataset-runtime[fuse]değerlerinin yanı sıra kodunuzun çalıştırılması için gereken tüm bağımlılıkları içermesi gerekir. Bu durumda bağımlılıklar birconda.yamldosyada yakalanmıştır:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Önemli
ve
azureml-dataset-runtime[fuse]paketleriazureml-coretoplu dağıtımlar için gereklidir ve ortam bağımlılıklarına dahil edilmelidir.Ortamı aşağıdaki gibi belirtin:
Ortam tanımı, dağıtım tanımının kendisine anonim bir ortam olarak eklenir. Dağıtımda aşağıdaki satırlarda görürsünüz:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlUyarı
Toplu dağıtımlarda seçilmiş ortamlar desteklenmez. Kendi ortamınızı belirtmeniz gerekir. süreci basitleştirmek için her zaman sizin seçtiğiniz ortamın temel görüntüsünü kullanabilirsiniz.
Dağıtım tanımı oluşturma
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoAşağıdaki tabloda toplu dağıtımın temel özellikleri açıklanmaktadır. Tam toplu dağıtım YAML şeması için bkz . CLI (v2) toplu dağıtım YAML şeması.
Tuş Açıklama nameDağıtımın adı. endpoint_nameAltında dağıtımın oluşturulacağı uç noktanın adı. modelToplu puanlama için kullanılacak model. Örnek, kullanarak pathbir modeli satır içi olarak tanımlar. Bu tanım, model dosyalarının otomatik olarak karşıya yüklenmesini ve otomatik olarak oluşturulan bir ad ve sürümle kaydedilmesini sağlar. Daha fazla seçenek için Bkz. Model şeması. Üretim senaryoları için en iyi uygulama olarak modeli ayrı ayrı oluşturup burada başvurmanız gerekir. Var olan bir modele başvurmak için söz diziminiazureml:<model-name>:<model-version>kullanın.code_configuration.codeModeli puanlayan tüm Python kaynak kodunu içeren yerel dizin. code_configuration.scoring_scriptDizindeki code_configuration.codePython dosyası. Bu dosyanın birinit()işlevi ve birrun()işlevi olmalıdır.init()Yüksek maliyetli veya yaygın hazırlıklar için işlevini kullanın (örneğin, modeli belleğe yüklemek için).init(), işlemin başlangıcında yalnızca bir kez çağrılır. Her girdiyi puanlarken kullanınrun(mini_batch); değerimini_batchdosya yollarının listesidir. İşlev birrun()pandas DataFrame veya dizi döndürmelidir. Döndürülen her öğe, içindeki giriş öğesinin başarılı bir çalıştırmasınımini_batchgösterir. Puanlama betiği yazma hakkında daha fazla bilgi için bkz . Puanlama betiğini anlama.environmentModelin puanını almak için ortam. Örnek, ve imagekullanarak bir ortamı satır içi olarakconda_filetanımlar.conda_fileBağımlılıklar öğesininimageüzerine yüklenir. Ortam otomatik olarak oluşturulan bir ad ve sürümle kaydedilir. Daha fazla seçenek için Ortam şemasına bakın. Üretim senaryoları için en iyi uygulama olarak, ortamı ayrı ayrı oluşturup buraya başvurmanız gerekir. Var olan bir ortama başvurmak için söz diziminiazureml:<environment-name>:<environment-version>kullanın.computeToplu puanlama çalıştırılacak işlem. Örnek, başlangıçta oluşturulan öğesini batch-clusterkullanır ve söz diziminiazureml:<compute-name>kullanarak buna başvurur.resources.instance_countHer toplu puanlama işi için kullanılacak örnek sayısı. settings.max_concurrency_per_instanceÖrnek başına en fazla paralel scoring_scriptçalıştırma sayısı.settings.mini_batch_sizeBir çağrıda run()işleyebileceği dosyascoring_scriptsayısı.settings.output_actionÇıkışın çıkış dosyasında nasıl düzenlenmesi gerektiği. append_rowdöndürülen tümrun()çıkış sonuçlarını adlıoutput_file_nametek bir dosyada birleştirir.summary_onlyçıkış sonuçlarını birleştirmez ve yalnızca öğesini hesaplarerror_threshold.settings.output_file_nameiçin append_rowoutput_actiontoplu puanlama çıkış dosyasının adı.settings.retry_settings.max_retriesBaşarısız scoring_scriptrun()olan için en fazla deneme sayısı.settings.retry_settings.timeoutMini toplu iş puanlama için scoring_scriptrun()saniye cinsinden zaman aşımı.settings.error_thresholdYoksayılması gereken giriş dosyası puanlama hatalarının sayısı. Girişin tamamı için hata sayısı bu değerin üzerine çıkarsa toplu puanlama işi sonlandırılır. Örnek, -1toplu puanlama işini sonlandırmadan herhangi bir sayıda hataya izin verildiğini gösteren kullanır.settings.logging_levelGünlük ayrıntı düzeyi. Ayrıntı düzeyini artırma değerleri şunlardır: UYARI, BİlGİ ve HATA AYıKLAMA. settings.environment_variablesHer toplu puanlama işi için ayarlanacağı ortam değişkeni ad-değer çiftlerinin sözlüğü. Dağıtımı oluşturun:
Toplu iş uç noktası altında bir toplu dağıtım oluşturmak ve bunu varsayılan dağıtım olarak ayarlamak için aşağıdaki kodu çalıştırın.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultİpucu
parametresi,
--set-defaultyeni oluşturulan dağıtımı uç noktanın varsayılan dağıtımı olarak ayarlar. Bu, özellikle ilk dağıtım oluşturma işleminde uç noktanın yeni bir varsayılan dağıtımını oluşturmanın kullanışlı bir yoludur. Üretim senaryoları için en iyi yöntem olarak, varsayılan olarak ayarlamadan yeni bir dağıtım oluşturmak isteyebilirsiniz. Dağıtımın beklediğiniz gibi çalıştığını doğrulayın ve ardından varsayılan dağıtımı daha sonra güncelleştirin. Bu işlemi uygulama hakkında daha fazla bilgi için Yeni model dağıtma bölümüne bakın.Toplu iş uç noktasını ve dağıtım ayrıntılarını denetleyin.

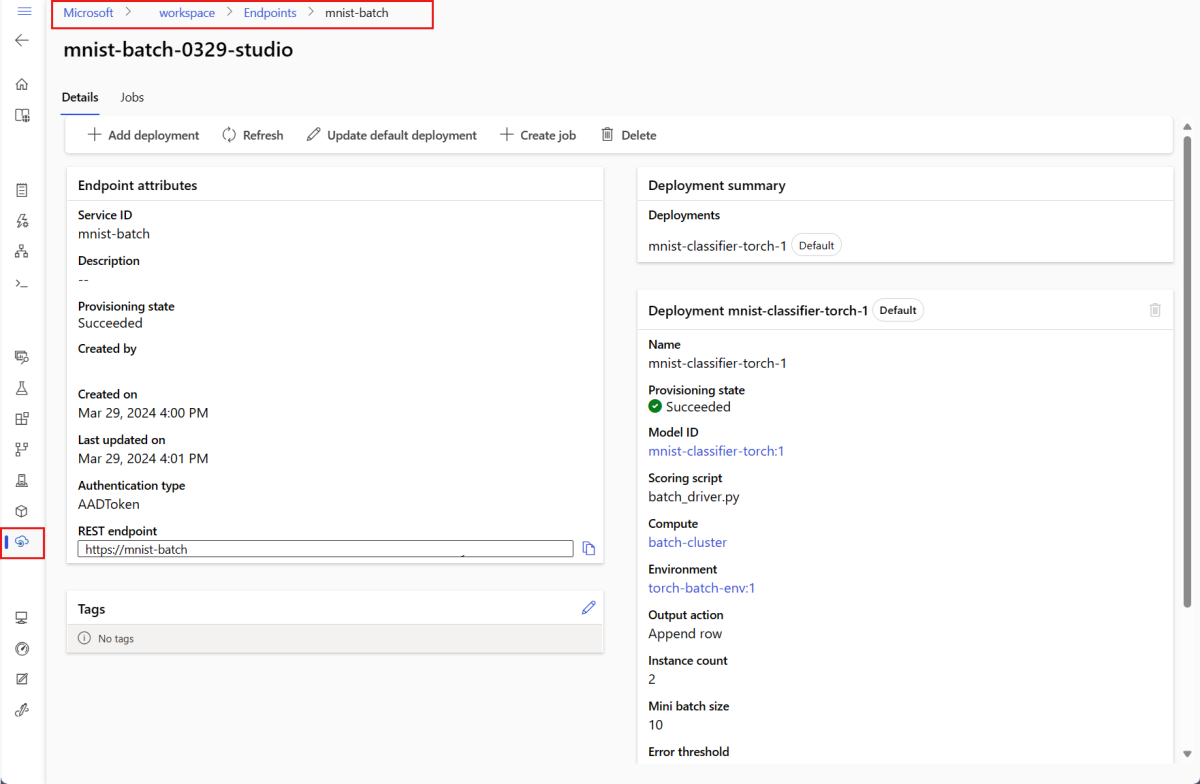
Toplu iş uç noktalarını çalıştırma ve sonuçlara erişme
Toplu iş uç noktasını çağırmak, toplu puanlama işini tetikler. İş name , çağırma yanıtından döndürülür ve toplu puanlama ilerleme durumunu izlemek için kullanılabilir. Toplu iş uç noktalarındaki puanlama modellerini çalıştırırken, uç noktaların puanlamak istediğiniz verileri bulabilmesi için giriş verilerinin yolunu belirtmeniz gerekir. Aşağıdaki örnekte, Azure Depolama Hesabında depolanan MNIST veri kümesinin örnek verileri üzerinden yeni bir iş başlatma işlemi gösterilmektedir.
Azure CLI, Azure Machine Learning SDK'sı veya REST uç noktalarını kullanarak toplu iş uç noktasını çalıştırabilir ve çağırabilirsiniz. Bu seçenekler hakkında daha fazla ayrıntı için bkz . Toplu iş uç noktaları için iş ve giriş verileri oluşturma.
Not
Paralelleştirme nasıl çalışır?
Toplu dağıtımlar, işi dosya düzeyinde dağıtır. Bu, 10 dosyadan oluşan mini toplu işlerle birlikte 100 dosya içeren bir klasörün her biri 10 dosyadan oluşan 10 toplu iş oluşturacağı anlamına gelir. Bu, söz konusu dosyaların boyutundan bağımsız olarak gerçekleşir. Dosyalarınız büyük mini toplu işlerde işlenemeyecek kadar büyükse, daha yüksek bir paralellik düzeyi elde etmek için dosyaları daha küçük dosyalara bölmenizi veya mini toplu iş başına dosya sayısını azaltmanızı öneririz. Şu anda toplu dağıtımlar, bir dosyanın boyut dağıtımındaki dengesizliklere hesaba katılamıyor.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Batch uç noktaları, farklı konumlarda bulunan dosyaların veya klasörlerin okunmasını destekler. Desteklenen türler ve bunların nasıl belirtilmesi hakkında daha fazla bilgi edinmek için bkz . Batch uç noktaları işlerinden verilere erişme.
Toplu iş yürütme ilerleme durumunu izleme
Toplu puanlama işlerinin giriş kümesinin tamamını işlemesi genellikle biraz zaman alır.
Aşağıdaki kod, iş durumunu denetler ve daha fazla ayrıntı için Azure Machine Learning stüdyosu bir bağlantı oluşturur.
az ml job show -n $JOB_NAME --web

Toplu puanlama sonuçlarını denetleme
İş çıkışları, çalışma alanının varsayılan blob depolama alanında veya belirttiğiniz depolama alanında depolanır. Varsayılanları değiştirmeyi öğrenmek için bkz . Çıkış konumunu yapılandırma. Aşağıdaki adımlar, iş tamamlandığında puanlama sonuçlarını Azure Depolama Gezgini görüntülemenizi sağlar:
Toplu puanlama işini Azure Machine Learning stüdyosu'da açmak için aşağıdaki kodu çalıştırın. job studio bağlantısı, değeri
interactionEndpoints.Studio.endpointolarak yanıtınainvokeda eklenir.az ml job show -n $JOB_NAME --webİşin grafiğinde adımı seçin
batchscoring.Çıkışlar + günlükler sekmesini ve ardından Veri çıkışlarını göster'i seçin.
Veri çıkışları'ndan simgeyi seçerek Depolama Gezgini açın.

Depolama Gezgini puanlama sonuçları aşağıdaki örnek sayfaya benzer:



Çıkış konumunu yapılandırma
Varsayılan olarak, toplu puanlama sonuçları çalışma alanının varsayılan blob deposunda iş adıyla (sistem tarafından oluşturulan GUID) adlı bir klasörde depolanır. Toplu iş uç noktasını çağırdığınızda puanlama çıkışlarının depolandığı yeri yapılandırabilirsiniz.
Azure Machine Learning kayıtlı veri deposundaki herhangi bir klasörü yapılandırmak için kullanın output-path . için söz dizimi--output-path, bir klasör azureml://datastores/<datastore-name>/paths/<path-on-datastore>/belirttiğinizde olduğu gibi --input aynıdır. Yeni bir çıkış dosyası adı yapılandırmak için kullanın --set output_file_name=<your-file-name> .
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Uyarı
Benzersiz bir çıkış konumu kullanmanız gerekir. Çıkış dosyası varsa, toplu puanlama işi başarısız olur.
Önemli
Girişlerden farklı olarak çıkışlar yalnızca blob depolama hesaplarında çalışan Azure Machine Learning veri depolarında depolanabilir.
Her iş için dağıtım yapılandırmasının üzerine yaz
Toplu iş uç noktasını çağırdığınızda, işlem kaynaklarından en iyi şekilde yararlanmak ve performansı geliştirmek için bazı ayarların üzerine yazılabilir. Aşağıdaki ayarlar iş başına yapılandırılabilir:
- Örnek sayısı: İşlem kümesinden istenecek örnek sayısının üzerine yazmak için bu ayarı kullanın. Örneğin, daha büyük hacimli veri girişleri için uçtan uca toplu puanlama işlemini hızlandırmak için daha fazla örnek kullanmak isteyebilirsiniz.
- Mini toplu iş boyutu: Her mini toplu işleme eklenecek dosya sayısının üzerine yazmak için bu ayarı kullanın. Mini toplu iş sayısı, toplam giriş dosyası sayılarına ve mini toplu iş boyutuna göre belirlenir. Daha küçük bir mini toplu iş boyutu daha fazla mini toplu iş oluşturur. Mini toplu işlemler paralel olarak çalıştırılabilir, ancak ek zamanlama ve çağırma ek yükü olabilir.
- En fazla yeniden deneme, zaman aşımı ve hata eşiği gibi diğer ayarların üzerine yazılabilir. Bu ayarlar, farklı iş yükleri için uçtan uca toplu puanlama süresini etkileyebilir.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Uç noktaya dağıtım ekleme
Dağıtımı olan bir toplu iş uç noktanız olduğunda modelinizi iyileştirmeye ve yeni dağıtımlar eklemeye devam edebilirsiniz. Siz aynı uç nokta altında yeni modeller geliştirip dağıtırken Batch uç noktaları varsayılan dağıtıma hizmet almaya devam eder. Dağıtımlar birbirinizi etkilemez.
Bu örnekte, aynı MNIST sorununu çözmek için Keras ve TensorFlow ile oluşturulmuş bir modeli kullanan ikinci bir dağıtım eklersiniz.
İkinci dağıtım ekleme
Toplu dağıtımınızın çalıştırılacağı bir ortam oluşturun. Kodunuzun çalışması için gereken tüm bağımlılıkları ortama ekleyin. Toplu dağıtımların çalışması için gerekli olduğundan kitaplığını
azureml-coreda eklemeniz gerekir. Aşağıdaki ortam tanımı, TensorFlow ile bir modeli çalıştırmak için gerekli kitaplıklara sahiptir.Ortam tanımı, dağıtım tanımının kendisine anonim bir ortam olarak eklenir.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlKullanılan conda dosyası aşağıdaki gibi görünür:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Model için bir puanlama betiği oluşturun:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Dağıtım tanımı oluşturma
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvDağıtımı oluşturun:
Toplu iş uç noktası altında bir toplu dağıtım oluşturmak ve bunu varsayılan dağıtım olarak ayarlamak için aşağıdaki kodu çalıştırın.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEİpucu
--set-defaultBu durumda parametresi eksik. Üretim senaryoları için en iyi yöntem olarak, varsayılan olarak ayarlamadan yeni bir dağıtım oluşturun. Ardından doğrulayın ve varsayılan dağıtımı daha sonra güncelleştirin.
Varsayılan olmayan toplu dağıtımı test edin
Yeni varsayılan olmayan dağıtımı test etmek için çalıştırmak istediğiniz dağıtımın adını bilmeniz gerekir.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Uyarı --deployment-name , yürütülecek dağıtımı belirtmek için kullanılır. Bu parametre, toplu iş uç noktasının invoke varsayılan dağıtımını güncelleştirmeden varsayılan olmayan bir dağıtım yapmanızı sağlar.
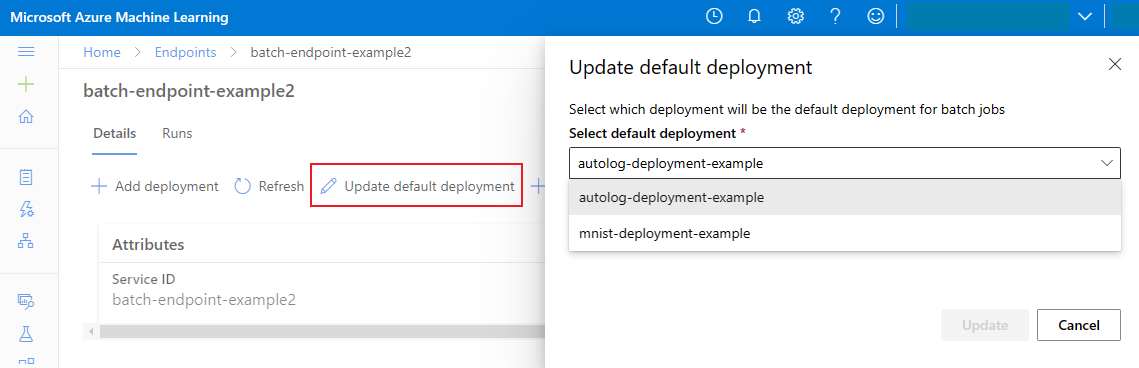
Varsayılan toplu dağıtımı güncelleştirme
Bir uç nokta içinde belirli bir dağıtımı çağırabilirsiniz ancak genellikle uç noktanın kendisini çağırmak ve hangi dağıtımın kullanılacağına (varsayılan dağıtım) uç noktanın karar vermesine izin vermek istersiniz. Kullanıcının uç noktayı çağırmasıyla yaptığınız sözleşmeyi değiştirmeden varsayılan dağıtımı değiştirebilir (ve sonuç olarak dağıtımı sunan modeli değiştirebilirsiniz). Varsayılan dağıtımı güncelleştirmek için aşağıdaki kodu kullanın:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Toplu iş uç noktasını ve dağıtımı silme
Eski toplu iş dağıtımını kullanmayacaksanız, aşağıdaki kodu çalıştırarak silin. --yes silme işlemini onaylamak için kullanılır.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Toplu iş uç noktasını ve temel alınan tüm dağıtımlarını silmek için aşağıdaki kodu çalıştırın. Toplu puanlama işleri silinmez.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
İlgili içerik
- Toplu uç nokta işlerinden verilere erişme.
- Toplu iş uç noktaları üzerinde kimlik doğrulaması.
- Toplu iş uç noktalarındaki ağ yalıtımı.
- Toplu iş uç noktalarının sorunlarını giderme.