TDSP, tahmine dayalı analiz çözümlerini ve yapay zeka uygulamalarını verimli bir şekilde sunmak için kullanabileceğiniz çevik ve yinelemeli bir veri bilimi metodolojisidir. TDSP, ekip rollerinin birlikte çalışması için en uygun yolları önererek ekip işbirliğini ve öğrenmeyi geliştirir. TDSP, ekibinizin veri bilimi girişimlerini etkili bir şekilde uygulamasına yardımcı olmak için Microsoft'un ve diğer sektör liderlerinin en iyi uygulamalarını ve çerçevelerini içerir. TDSP, analiz programınızın avantajlarını tam olarak gerçekleştirmenizi sağlar.
Bu makalede, TDSP'ye ve ana bileşenlerine genel bir bakış sağlanır. Microsoft araçlarını ve altyapısını kullanarak TDSP'yi uygulama hakkında rehberlik sunar. Makale boyunca daha ayrıntılı kaynaklar bulabilirsiniz.
TDSP'nin önemli bileşenleri
TDSP aşağıdaki temel bileşenlere sahiptir:
- Veri bilimi yaşam döngüsü tanımı
- Standartlaştırılmış proje yapısı
- Veri bilimi projeleri için ideal altyapı ve kaynaklar
- Sorumlu yapay zeka: ve etik ilkelerle desteklenen yapay zekanın ilerlemesine yönelik bir taahhüt
Veri bilimi yaşam döngüsü
TDSP, veri bilimi projelerinizin geliştirilmesini yapılandırmak için kullanabileceğiniz bir yaşam döngüsü sağlar. Yaşam döngüsü, başarılı projelerin izlediği tüm adımları özetler.
Görev tabanlı TDSP'yi veri madenciliği için endüstriler arası standart süreç (CRISP-DM), veritabanlarında bilgi bulma (KDD) işlemi veya başka bir özel işlem gibi diğer veri bilimi yaşam döngüleriyle birleştirebilirsiniz. Yüksek düzeyde, bu farklı metodolojilerin çok ortak bir yanı vardır.
Akıllı bir uygulamanın parçası olan bir veri bilimi projeniz varsa bu yaşam döngüsünü kullanın. Akıllı uygulamalar, tahmine dayalı analiz için makine öğrenmesi veya yapay zeka modelleri dağıtır. Bu süreci keşif veri bilimi projeleri ve doğaçlama analiz projeleri için de kullanabilirsiniz.
TDSP yaşam döngüsü, ekibinizin yinelemeli olarak gerçekleştirdiği beş ana aşamadan oluşur. Bu aşamalar şunlardır:
TDSP yaşam döngüsünün görsel bir gösterimi aşağıdadır:
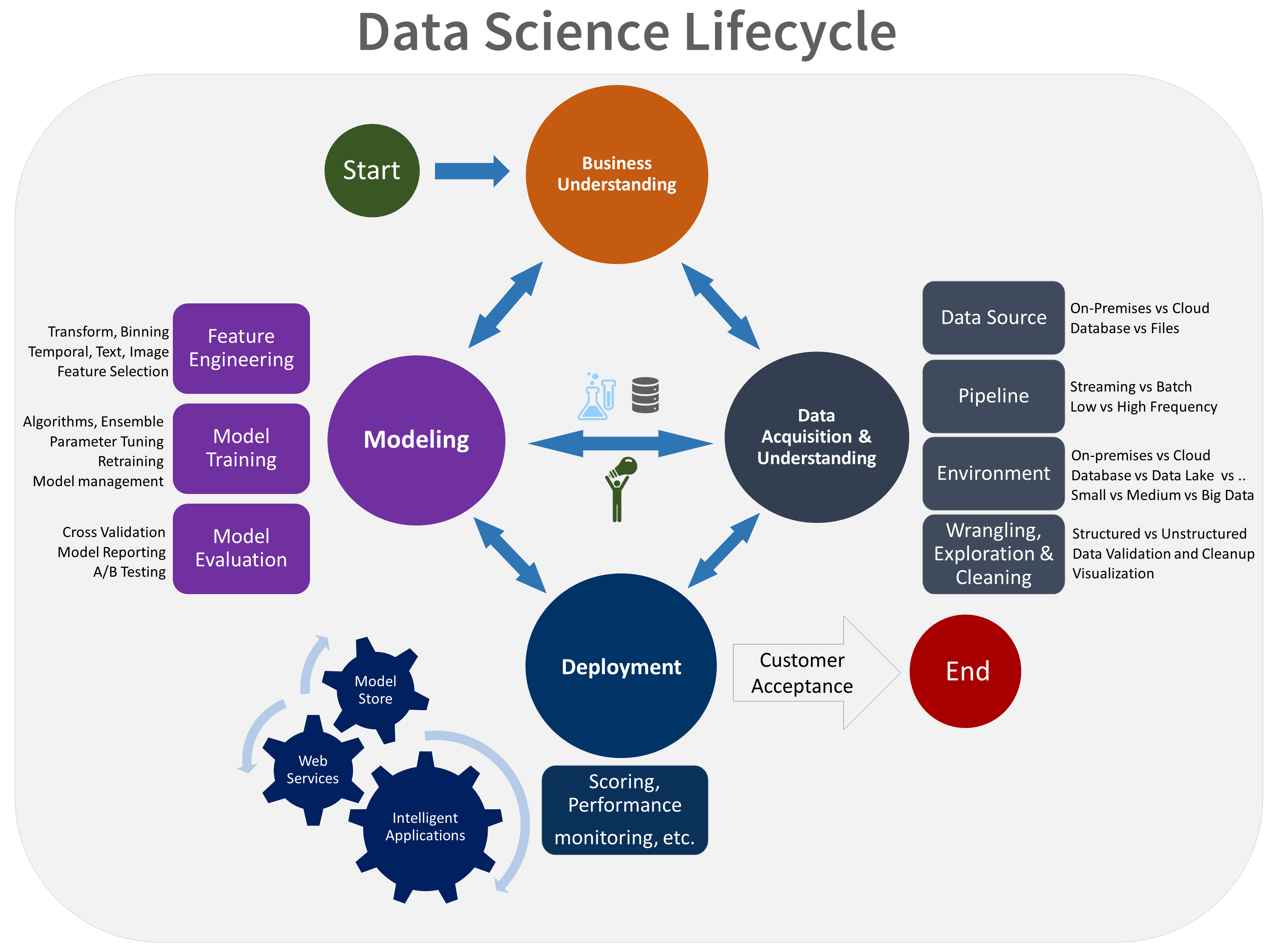
Her aşamanın hedefleri, görevleri ve belge yapıtları hakkında daha fazla bilgi için bkz . TDSP yaşam döngüsü.
Bu görevler ve yapıtlar aşağıdakiler gibi proje rolleriyle hizalanır:
- Çözüm mimarı
- Proje yöneticisi
- Veri mühendisi
- Veri bilimcisi
- Uygulama geliştirici
- Proje lideri
Aşağıdaki diyagramda, yatay eksende ve dikey eksende gösterilen roller için yaşam döngüsünün her aşamasına karşılık gelen görevler (mavi) ve yapıtlar (yeşil) gösterilmektedir.

Standartlaştırılmış proje yapısı
Ekibiniz veri bilimi varlıklarınızı düzenlemek için Azure altyapısını kullanabilir.
Azure Machine Learning açık kaynak MLflow'unu destekler. Veri bilimi ve yapay zeka proje yönetimi için MLflow kullanmanızı öneririz. MLflow, makine öğrenmesi yaşam döngüsünün tamamını yönetmek için tasarlanmıştır. Modelleri farklı platformlarda eğitip sunar, böylece denemelerinizin nerede çalıştığına bakılmaksızın tutarlı bir araç kümesi kullanabilirsiniz. MLflow'ı bilgisayarınızda, uzak işlem hedefinde, sanal makinede veya makine öğrenmesi işlem örneğinde yerel olarak kullanabilirsiniz.
MLflow birkaç temel işlevden oluşur:
Denemeleri izleme: Parametreler, kod sürümleri, ölçümler ve çıkış dosyaları dahil olmak üzere denemeleri izlemek için MLflow kullanabilirsiniz. Bu özellik farklı çalıştırmaları karşılaştırmanıza ve deneme sürecini verimli bir şekilde yönetmenize yardımcı olur.
Paket kodu: Bağımlılıkları ve yapılandırmaları içeren makine öğrenmesi kodunu paketlemek için standartlaştırılmış bir biçim sağlar. Bu paketleme, çalıştırmaları yeniden üretmeyi ve kodu başkalarıyla paylaşmayı kolaylaştırır.
Modelleri yönetme: MLflow, modelleri yönetmek ve sürüme almak için işlevler sağlar. Modelleri depolayabileceğiniz, sürümleyebileceğiniz ve sunabileceğiniz çeşitli makine öğrenmesi çerçevelerini destekler.
Modelleri sunma ve dağıtma: MLflow, modelleri farklı ortamlarda kolayca dağıtabilmeniz için model sunma ve dağıtım özelliklerini tümleştirir.
Modelleri kaydetme: Bir modelin sürüm oluşturma, aşama geçişleri ve ek açıklamaları içeren yaşam döngüsünü yönetebilirsiniz. MLflow'u kullanarak işbirliğine dayalı bir ortamda merkezi bir model deposu tutabilirsiniz.
API ve kullanıcı arabirimi kullanma: Azure'da MLflow, Makine Öğrenmesi API'sinin 2. sürümünde paketlenmiştir, böylece sistemle program aracılığıyla etkileşim kurabilirsiniz. Bir kullanıcı arabirimiyle etkileşime geçmek için Azure portalını kullanabilirsiniz.
MLflow, denemeden dağıtıma kadar makine öğrenmesi geliştirme sürecini basitleştirir ve standartlaştırır.
Machine Learning Git depolarıyla tümleştirilir; böylece GitHub, GitLab, Bitbucket, Azure DevOps veya başka bir Git uyumlu hizmet gibi Git uyumlu hizmetleri kullanabilirsiniz. Machine Learning'de zaten izlenen varlıklara ek olarak, ekibiniz git uyumlu hizmetlerinde kendi taksonomilerini geliştirerek aşağıdakiler gibi diğer proje verilerini depolayabilir:
- Belge
- Proje verileri: örneğin, son proje raporu
- Veri raporu: örneğin, veri sözlüğü veya veri kalitesi raporları
- Model: örneğin, model raporları
- Kod
- Veri hazırlama
- Model geliştirme
- Güvenlik ve uyumluluk içeren kullanıma hazır hale getirme
Altyapı ve kaynaklar
TDSP, aşağıdaki kategorilerde paylaşılan analiz ve depolama altyapısının nasıl yönetileceğini gösteren öneriler sağlar:
- Veri kümelerini depolamak için bulut dosya sistemleri
- Bulut veritabanları
- SQL veya Spark kullanan büyük veri kümeleri
- Yapay zeka ve makine öğrenmesi hizmetleri
Veri kümelerini depolamak için bulut dosya sistemleri
Bulut dosya sistemleri çeşitli nedenlerle TDSP için çok önemlidir:
Merkezi veri depolama: Bulut dosya sistemleri veri kümelerini depolamak için merkezi bir konum sağlar. Bu, veri bilimi ekibi üyeleri arasında işbirliği yapmak için gereklidir. Merkezileştirme, tüm ekip üyelerinin en güncel verilere erişebilmesini sağlar ve güncel olmayan veya tutarsız veri kümeleriyle çalışma riskini azaltır.
Ölçeklenebilirlik: Bulut dosya sistemleri, veri bilimi projelerinde yaygın olarak kullanılan büyük hacimli verileri işleyebilir. Dosya sistemleri, projenin ihtiyaçlarıyla birlikte büyüyen ölçeklenebilir depolama çözümleri sağlar. Ekiplerin donanım sınırlamaları konusunda endişelenmeden büyük veri kümelerini depolamasına ve işlemesine olanak tanır.
Erişilebilirlik: Bulut dosya sistemleriyle verilere İnternet bağlantısıyla her yerden erişebilirsiniz. Bu erişim, dağıtılmış ekipler veya ekip üyelerinin uzaktan çalışması gerektiğinde önemlidir. Bulut dosya sistemleri sorunsuz işbirliğini kolaylaştırır ve verilerin her zaman erişilebilir olmasını sağlar.
Güvenlik ve uyumluluk: Bulut sağlayıcıları genellikle şifreleme, erişim denetimleri ve endüstri standartları ve düzenlemeleri ile uyumluluğu içeren güçlü güvenlik önlemleri uygular. Güçlü güvenlik önlemleri hassas verileri koruyabilir ve ekibinizin yasal ve mevzuat gereksinimlerini karşılamaya yardımcı olabilir.
Sürüm denetimi: Bulut dosya sistemleri genellikle ekiplerin zaman içinde veri kümelerindeki değişiklikleri izlemek için kullanabileceği sürüm denetimi özelliklerini içerir. Sürüm denetimi, verilerin bütünlüğünü korumak ve sonuçları veri bilimi projelerinde yeniden oluşturmak için çok önemlidir. Ayrıca, ortaya çıkan sorunları denetlemenize ve gidermenize de yardımcı olur.
Araçlarla tümleştirme: Bulut dosya sistemleri, çeşitli veri bilimi araçları ve platformlarıyla sorunsuz bir şekilde tümleştirebilir. Araç tümleştirmesi daha kolay veri alımını, veri işlemeyi ve veri analizini destekler. Örneğin, Azure Depolama Machine Learning, Azure Databricks ve diğer veri bilimi araçlarıyla iyi tümleştirilir.
İşbirliği ve paylaşım: Bulut dosya sistemleri, veri kümelerini diğer ekip üyeleri veya paydaşlarla paylaşmayı kolaylaştırır. Bu sistemler paylaşılan klasörler ve izin yönetimi gibi işbirliğine dayalı özellikleri destekler. İşbirliği özellikleri ekip çalışmasını kolaylaştırır ve doğru kişilerin ihtiyaç duydukları verilere erişmesini sağlar.
Maliyet verimliliği: Bulut dosya sistemleri, şirket içi depolama çözümlerini korumaktan daha uygun maliyetli olabilir. Bulut sağlayıcıları, veri bilimi projenizin gerçek kullanım ve depolama gereksinimlerine göre maliyetleri yönetmeye yardımcı olabilecek kullandıkça öde seçeneklerini içeren esnek fiyatlandırma modellerine sahiptir.
Olağanüstü durum kurtarma: Bulut dosya sistemleri genellikle veri yedekleme ve olağanüstü durum kurtarma özellikleri içerir. Bu özellikler donanım hatalarına, yanlışlıkla silmelere ve diğer olağanüstü durumlara karşı verilerin korunmasına yardımcı olur. İç rahatlığı sağlar ve veri bilimi operasyonlarında sürekliliği destekler.
Otomasyon ve iş akışı tümleştirmesi: Bulut depolama sistemleri, veri bilimi sürecinin farklı aşamaları arasında sorunsuz veri aktarımı sağlayan otomatik iş akışlarıyla tümleştirilebilir. Otomasyon verimliliği artırmaya ve verileri yönetmek için gereken el ile çabayı azaltmaya yardımcı olabilir.
Bulut dosya sistemleri için önerilen Azure kaynakları
- Azure Blob Depolama - Yapılandırılmamış veriler için ölçeklenebilir bir nesne depolama hizmeti olan Azure Blob Depolama hakkında kapsamlı belgeler.
- Azure Data Lake Storage - büyük veri analizi için tasarlanmış ve büyük ölçekli veri kümelerini destekleyen Azure Data Lake Storage 2. Nesil hakkında bilgi.
- Azure Dosyalar - Bulutta tam olarak yönetilen dosya paylaşımları sağlayan Azure Dosyalar ayrıntıları.
Özetle, bulut dosya sistemleri tüm veri yaşam döngüsünü destekleyen ölçeklenebilir, güvenli ve erişilebilir depolama çözümleri sağladığından TDSP için çok önemlidir. Bulut dosya sistemleri, kapsamlı veri alımını ve anlaşılmasını destekleyen çeşitli kaynaklardan sorunsuz veri tümleştirmesi sağlar. Veri bilimcileri, büyük veri kümelerini verimli bir şekilde depolamak, yönetmek ve erişmek için bulut dosya sistemlerini kullanabilir. Bu işlevsellik, makine öğrenmesi modellerini eğitip dağıtmak için gereklidir. Bu sistemler, ekip üyelerinin birleşik bir ortamda verileri aynı anda paylaşmasına ve üzerinde çalışmasına olanak tanıyarak işbirliğini de geliştirir. Bulut dosya sistemleri, verilerin korunmasına yardımcı olan ve veri bütünlüğünü ve güvenini korumak için çok önemli olan mevzuat gereksinimleriyle uyumlu hale getirmeye yardımcı olan güçlü güvenlik özellikleri sağlar.
Bulut veritabanları
Bulut veritabanları çeşitli nedenlerle TDSP'de kritik bir rol oynar:
Ölçeklenebilirlik: Bulut veritabanları, bir projenin artan veri gereksinimlerini karşılamak için kolayca büyüyebilen ölçeklenebilir çözümler sağlar. Ölçeklenebilirlik, büyük ve karmaşık veri kümelerini sık sık işleyen veri bilimi projeleri için çok önemlidir. Bulut veritabanları, el ile müdahaleye veya donanım yükseltmelerine gerek kalmadan değişen iş yüklerini işleyebilir.
Performans iyileştirme: Geliştiriciler otomatik dizin oluşturma, sorgu iyileştirme ve yük dengeleme gibi özellikleri kullanarak bulut veritabanlarını performans için en iyi duruma getirmektedir. Bu özellikler, veri alma ve işlemenin hızlı ve verimli olmasını sağlamaya yardımcı olur. Bu, gerçek zamanlı veya neredeyse gerçek zamanlı veri erişimi gerektiren veri bilimi görevleri için çok önemlidir.
Erişilebilirlik ve işbirliği: Teams, bulut veritabanlarındaki depolanan verilere herhangi bir konumdan erişebilir. Bu erişilebilirlik, coğrafi olarak dağılmış olabilecek ekip üyeleri arasında işbirliğini teşvik eder. Erişilebilirlik ve işbirliği, dağıtılmış ekipler veya uzaktan çalışan kişiler için önemlidir. Bulut veritabanları, eşzamanlı erişim ve işbirliği sağlayan çok kullanıcılı ortamları destekler.
Veri bilimi araçlarıyla tümleştirme: Bulut veritabanları, çeşitli veri bilimi araçları ve platformlarıyla sorunsuz bir şekilde tümleştirilir. Örneğin, Azure bulut veritabanları Machine Learning, Power BI ve diğer veri analizi araçlarıyla iyi tümleştirilir. Bu tümleştirme, veri alımı ve depolamadan analiz ve görselleştirmeye kadar veri işlem hattını kolaylaştırır.
Güvenlik ve uyumluluk: Bulut sağlayıcıları veri şifreleme, erişim denetimleri ve endüstri standartları ve düzenlemeleri ile uyumluluğu içeren güçlü güvenlik önlemleri uygular. Güvenlik önlemleri hassas verileri korur ve ekibinizin yasal ve mevzuat gereksinimlerini karşılamaya yardımcı olur. Güvenlik özellikleri, veri bütünlüğünü ve gizliliğini korumak için çok önemlidir.
Maliyet verimliliği: Bulut veritabanları genellikle kullandıkça öde modeliyle çalışır ve bu da şirket içi veritabanı sistemlerini korumaktan daha uygun maliyetli olabilir. Bu fiyatlandırma esnekliği, kuruluşların bütçelerini etkili bir şekilde yönetmesine ve yalnızca kullandıkları depolama ve işlem kaynakları için ödeme yapmaya olanak tanır.
Otomatik yedeklemeler ve olağanüstü durum kurtarma: Bulut veritabanları otomatik yedekleme ve olağanüstü durum kurtarma çözümleri sağlar. Bu çözümler donanım hataları, yanlışlıkla silmeler veya başka olağanüstü durumlar varsa veri kaybını önlemeye yardımcı olur. Güvenilirlik, veri bilimi projelerinde veri sürekliliğini ve bütünlüğünü korumak için çok önemlidir.
Gerçek zamanlı veri işleme: Birçok bulut veritabanı, en güncel bilgileri gerektiren veri bilimi görevleri için gerekli olan gerçek zamanlı veri işleme ve analizi destekler. Bu özellik, veri bilimcilerinin en son kullanılabilir verilere göre zamanında kararlar vermesine yardımcı olur.
Veri tümleştirmesi: Bulut veritabanları diğer veri kaynakları, veritabanları, veri gölleri ve dış veri akışlarıyla kolayca tümleştirebilir. Tümleştirme, veri bilimcilerinin birden çok kaynaktan verileri birleştirmelerine yardımcı olur ve kapsamlı bir görünüm ve daha gelişmiş analiz sağlar.
Esneklik ve çeşitlilik: Bulut veritabanları ilişkisel veritabanları, NoSQL veritabanları ve veri ambarları gibi çeşitli biçimlerde gelir. Bu çeşitlilik, veri bilimi ekiplerinin yapılandırılmış veri depolaması, yapılandırılmamış veri işleme veya büyük ölçekli veri analizine ihtiyaç duyması fark etmeksizin belirli gereksinimleri için en iyi veritabanı türünü seçmesine olanak tanır.
Gelişmiş analiz desteği: Bulut veritabanları genellikle gelişmiş analiz ve makine öğrenmesi için yerleşik destekle birlikte gelir. Örneğin, Azure SQL Veritabanı yerleşik makine öğrenmesi hizmetleri sağlar. Bu hizmetler, veri bilim adamlarının doğrudan veritabanı ortamında gelişmiş analizler gerçekleştirmesine yardımcı olur.
Bulut veritabanları için önerilen Azure kaynakları
- Azure SQL Veritabanı - Tam olarak yönetilen bir ilişkisel veritabanı hizmeti olan Azure SQL Veritabanı belgeleri.
- Azure Cosmos DB - Genel olarak dağıtılmış, çok modelli bir veritabanı hizmeti olan Azure Cosmos DB hakkında bilgiler.
- PostgreSQL için Azure Veritabanı - Uygulama geliştirme ve dağıtım için yönetilen bir veritabanı hizmeti olan PostgreSQL için Azure Veritabanı kılavuzu.
- MySQL için Azure Veritabanı - MySQL veritabanları için yönetilen bir hizmet olan MySQL için Azure Veritabanı ayrıntıları.
Özetle, veri temelli projeleri destekleyen ölçeklenebilir, güvenilir ve verimli veri depolama ve yönetim çözümleri sağladığından, bulut veritabanları TDSP için çok önemlidir. Bunlar, veri bilimcilerinin çeşitli kaynaklardan büyük veri kümelerini almalarına, ön işlemelerine ve analizlerine yardımcı olan sorunsuz veri tümleştirmesini kolaylaştırır. Bulut veritabanları, makine öğrenmesi modellerini geliştirmek, test etmek ve dağıtmak için gerekli olan hızlı sorgulama ve veri işlemeyi etkinleştirir. Ayrıca bulut veritabanları, ekip üyelerinin aynı anda verilere erişmesi ve verilerle çalışabilmesi için merkezi bir platform sağlayarak işbirliğini geliştirir. Son olarak bulut veritabanları, verileri koruma altına almak ve mevzuat standartlarıyla uyumlu tutmak için gelişmiş güvenlik özellikleri ve uyumluluk desteği sağlar. Bu, veri bütünlüğünü ve güvenini korumak için kritik önem taşır.
SQL veya Spark kullanan büyük veri kümeleri
SQL veya Spark kullananlar gibi büyük veri kümeleri çeşitli nedenlerle TDSP için temeldir:
Büyük hacimli verileri işleme: Büyük veri kümeleri, büyük hacimli verileri verimli bir şekilde işlemek için tasarlanmıştır. Veri bilimi projeleri genellikle geleneksel veritabanlarının kapasitesini aşan büyük veri kümelerini içerir. SQL tabanlı büyük veri kümeleri ve Spark bu verileri büyük ölçekte yönetebilir ve işleyebilir.
Dağıtılmış bilgi işlem: Büyük veri kümeleri, verileri ve hesaplama görevlerini birden çok düğüme yaymak için dağıtılmış bilgi işlem kullanır. Paralel işleme özelliği, veri bilimi projelerinde zamanında içgörüler elde etmek için gerekli olan veri işleme ve analiz görevlerini önemli ölçüde hızlandırır.
Ölçeklenebilirlik: Büyük veri kümeleri, hem daha fazla düğüm ekleyerek hem de mevcut düğümlerin gücünü artırarak dikey olarak yüksek ölçeklenebilirlik sağlar. Ölçeklenebilirlik, artan veri boyutlarını ve karmaşıklığı işleyerek veri altyapısının projenin gereksinimleriyle birlikte büyümesine yardımcı olur.
Veri bilimi araçlarıyla tümleştirme: Büyük veri kümeleri, çeşitli veri bilimi araçları ve platformlarıyla iyi bir şekilde tümleştirilir. Örneğin Spark, Hadoop ile sorunsuz bir şekilde tümleştirilir ve SQL kümeleri çeşitli veri çözümleme araçlarıyla çalışır. Tümleştirme, veri alımından analiz ve görselleştirmeye kadar sorunsuz bir iş akışı sağlar.
Gelişmiş analiz: Büyük veri kümeleri gelişmiş analizleri ve makine öğrenmesini destekler. Örneğin Spark aşağıdaki yerleşik kitaplıkları sağlar:
- Makine öğrenmesi, MLlib
- Graf işleme, GraphX
- Akış işleme, Spark Akışı
Bu özellikler, veri bilim adamlarının doğrudan küme içinde karmaşık analizler gerçekleştirmesine yardımcı olur.
Gerçek zamanlı veri işleme: Özellikle Spark kullanan büyük veri kümeleri gerçek zamanlı veri işlemeyi destekler. Bu özellik, en güncel veri analizi ve karar alma gerektiren projeler için çok önemlidir. Gerçek zamanlı işleme sahtekarlık algılama, gerçek zamanlı öneriler ve dinamik fiyatlandırma gibi senaryolarda yardımcı olur.
Veri dönüştürme ve ayıklama, dönüştürme, yükleme (ETL):Büyük veri kümeleri veri dönüştürme ve ETL işlemleri için idealdir. Karmaşık veri dönüştürmeleri, temizleme ve toplama görevlerini verimli bir şekilde işleyebilirler. Bu görevler genellikle verilerin çözümlenebilmesi için gereklidir.
Maliyet verimliliği: Özellikle Azure Databricks ve diğer bulut hizmetleri gibi bulut tabanlı çözümleri kullandığınızda büyük veri kümeleri uygun maliyetli olabilir. Bu hizmetler, kullandıkça öde dahil olmak üzere şirket içi büyük veri altyapısını korumaktan daha ekonomik olabilecek esnek fiyatlandırma modelleri sağlar.
Hataya dayanıklılık: Büyük veri kümeleri hataya dayanıklılık göz önünde bulundurularak tasarlanmıştır. Bazı düğümler başarısız olsa bile sistemin çalışır durumda kalmasını sağlamaya yardımcı olmak için verileri düğümler arasında çoğaltır. Bu güvenilirlik, veri bilimi projelerinde veri bütünlüğünü ve kullanılabilirliğini korumak için kritik öneme sahiptir.
Veri gölü tümleştirmesi: Büyük veri kümeleri genellikle veri gölleriyle sorunsuz bir şekilde tümleştirilir ve bu sayede veri bilimciler farklı veri kaynaklarına birleşik bir şekilde erişip analiz eder. Tümleştirme, yapılandırılmış ve yapılandırılmamış verilerin birleşimini destekleyerek daha kapsamlı analizler sağlar.
SQL tabanlı işleme: SQL hakkında bilgi sahibi olan veri bilimciler için Spark SQL veya Hadoop üzerinde SQL gibi SQL sorguları ile çalışan büyük veri kümeleri, büyük verileri sorgulamak ve analiz etmek için tanıdık bir arabirim sağlar. Bu kullanım kolaylığı analiz sürecini hızlandırabilir ve daha geniş bir kullanıcı aralığı için daha erişilebilir hale getirir.
İşbirliği ve paylaşım: Büyük veri kümeleri, birden çok veri bilimcisinin ve analistin aynı veri kümeleri üzerinde birlikte çalışabileceği işbirliğine dayalı ortamları destekler. Ekip çalışmasını ve bilgi paylaşımını teşvik eden kod, not defterleri ve sonuçları paylaşmaya yönelik özellikler sağlar.
Güvenlik ve uyumluluk: Büyük veri kümeleri veri şifreleme, erişim denetimleri ve endüstri standartlarıyla uyumluluk gibi güçlü güvenlik özellikleri sağlar. Güvenlik özellikleri hassas verileri korur ve ekibinizin mevzuat gereksinimlerini karşılamasını sağlar.
Büyük veri kümeleri için önerilen Azure kaynakları
- Machine Learning'de Apache Spark: Azure Synapse Analytics ile Machine Learning tümleştirmesi, Apache Spark çerçevesi aracılığıyla dağıtılmış hesaplama kaynaklarına kolay erişim sağlar.
- Azure Synapse Analytics: Azure Synapse Analytics için büyük verileri ve veri ambarını tümleştirmeye yönelik kapsamlı belgeler.
Özetle, SQL veya Spark gibi büyük veri kümeleri, çok büyük miktarda veriyi verimli bir şekilde işlemek için gereken hesaplama gücünü ve ölçeklenebilirliği sağladığından, TDSP için çok önemlidir. Büyük veri kümeleri, veri bilim insanlarının derin içgörüleri ve doğru model geliştirmeyi kolaylaştıran büyük veri kümelerinde karmaşık sorgular ve gelişmiş analizler gerçekleştirmesini sağlar. Dağıtılmış bilgi işlem kullandığınızda, bu kümeler hızlı veri işleme ve analiz olanağı sağlar ve bu da genel veri bilimi iş akışını hızlandırır. Büyük veri kümeleri ayrıca çeşitli veri kaynakları ve araçlarıyla sorunsuz tümleştirmeyi de destekler ve bu da birden çok ortamdan veri alma, işleme ve analiz etme özelliğini geliştirir. Büyük veri kümeleri ekiplerin kaynakları, iş akışlarını ve sonuçları etkili bir şekilde paylaşabileceği birleşik bir platform sağlayarak işbirliğini ve yeniden üretilebilirliği de teşvik eder.
Yapay zeka ve makine öğrenmesi hizmetleri
Yapay zeka ve makine öğrenmesi (ML) hizmetleri çeşitli nedenlerle TDSP'nin ayrılmaz bir parçasıdır:
Gelişmiş analiz: Yapay zeka ve ML hizmetleri gelişmiş analize olanak tanır. Veri bilimcileri karmaşık desenleri ortaya çıkarmak, tahminlerde bulunmak ve geleneksel analiz yöntemleriyle mümkün olmayan içgörüler oluşturmak için gelişmiş analiz kullanabilir. Bu gelişmiş özellikler, yüksek etkili veri bilimi çözümleri oluşturmak için çok önemlidir.
Yinelenen görevlerin otomasyonu: Yapay zeka ve ML hizmetleri, veri temizleme, özellik mühendisliği ve model eğitimi gibi yinelenen görevleri otomatikleştirebilir. Otomasyon zamandan tasarruf sağlar ve veri bilimcilerinin projenin daha stratejik yönlerine odaklanmalarına yardımcı olur ve bu da genel üretkenliği artırır.
Geliştirilmiş doğruluk ve performans: ML modelleri, verilerden öğrenerek tahminlerin ve analizlerin doğruluğunu ve performansını geliştirebilir. Bu modeller daha fazla veriye maruz kaldıkça sürekli olarak geliştirilebilir ve bu da daha iyi karar alma ve daha güvenilir sonuçlar elde etme olanağı sunar.
Ölçeklenebilirlik: Machine Learning gibi bulut platformları tarafından sağlanan yapay zeka ve ML hizmetleri yüksek oranda ölçeklenebilir. Bunlar, veri bilimi ekiplerinin temel altyapı sınırlamaları konusunda endişelenmeden artan talepleri karşılamak için çözümlerini ölçeklendirmesine yardımcı olan büyük hacimli verileri ve karmaşık hesaplamaları işleyebilir.
Diğer araçlarla tümleştirme: Yapay zeka ve ML hizmetleri Azure Data Lake, Azure Databricks ve Power BI gibi Microsoft ekosistemi içindeki diğer araçlar ve hizmetlerle sorunsuz bir şekilde tümleştirilir. Tümleştirme, veri alımı ve işlemeden model dağıtımına ve görselleştirmesine kadar kolaylaştırılmış bir iş akışını destekler.
Model dağıtımı ve yönetimi: Yapay zeka ve ML hizmetleri, üretimde makine öğrenmesi modellerini dağıtmak ve yönetmek için güçlü araçlar sağlar. Sürüm denetimi, izleme ve otomatik yeniden eğitme gibi özellikler, modellerin zaman içinde doğru ve etkili kalmasını sağlamaya yardımcı olur. Bu yaklaşım, ML çözümlerinin bakımını kolaylaştırır.
Gerçek zamanlı işleme: Yapay zeka ve ML hizmetleri gerçek zamanlı veri işlemeyi ve karar almayı destekler. Gerçek zamanlı işleme, sahtekarlık algılama, dinamik fiyatlandırma ve öneri sistemleri gibi anında içgörüler ve eylemler gerektiren uygulamalar için gereklidir.
Özelleştirilebilirlik ve esneklik: Yapay zeka ve ML hizmetleri, önceden oluşturulmuş modellerden VE API'lerden sıfırdan özel modeller oluşturmaya yönelik çerçevelere kadar çeşitli özelleştirilebilir seçenekler sunar. Bu esneklik, veri bilimi ekiplerinin çözümleri belirli iş ihtiyaçlarına ve kullanım örneklerine uyarlamasına yardımcı olur.
En son algoritmalara erişim: Yapay zeka ve ML hizmetleri, veri bilimcilerine önde gelen araştırmacılar tarafından geliştirilen en yeni algoritmalara ve teknolojilere erişim sağlar. Access, ekibin projeleri için yapay zeka ve ML'deki en son ilerlemeleri kullanabilmesini sağlar.
İşbirliği ve paylaşım: Yapay zeka ve ML platformları, birden çok ekip üyesinin aynı proje üzerinde birlikte çalışabileceği, kod paylaşabileceği ve denemeleri yeniden üretebildiği işbirliğine dayalı geliştirme ortamlarını destekler. İşbirliği, ekip çalışmasını geliştirir ve model geliştirmede tutarlılık sağlamaya yardımcı olur.
Maliyet verimliliği: Bulut üzerindeki yapay zeka ve ML hizmetleri, şirket içi çözümler oluşturmak ve korumaktan daha uygun maliyetli olabilir. Bulut sağlayıcıları, maliyetleri düşürebilen ve kaynak kullanımını iyileştirebilen kullandıkça öde seçeneklerini içeren esnek fiyatlandırma modellerine sahiptir.
Gelişmiş güvenlik ve uyumluluk: Yapay zeka ve ML hizmetleri, veri şifreleme, güvenli erişim denetimleri ve endüstri standartları ve düzenlemeleri ile uyumluluk gibi güçlü güvenlik özellikleriyle birlikte gelir. Bu özellikler verilerinizin ve modellerinizin korunmasına ve yasal ve mevzuat gereksinimlerini karşılamaya yardımcı olur.
Önceden oluşturulmuş modeller ve API'ler: Birçok yapay zeka ve ML hizmeti doğal dil işleme, görüntü tanıma ve anomali algılama gibi yaygın görevler için önceden oluşturulmuş modeller ve API'ler sağlar. Önceden oluşturulmuş çözümler geliştirme ve dağıtımı hızlandırabilir ve ekiplerin yapay zeka özelliklerini uygulamalarıyla hızla tümleştirmesine yardımcı olabilir.
Deneme ve prototip oluşturma: Yapay zeka ve ML platformları, hızlı deneme ve prototip oluşturma ortamları sağlar. Veri bilimciler, en iyi çözümü bulmak için farklı algoritmaları, parametreleri ve veri kümelerini hızla test edebilir. Deneme ve prototip oluşturma, model geliştirmeye yönelik yinelemeli bir yaklaşımı destekler.
Yapay zeka ve ML hizmetleri için önerilen Azure kaynakları
Machine Learning, veri bilimi uygulaması ve TDSP için önerdiğimiz ana kaynaktır. Ayrıca Azure, belirli uygulamalar için kullanıma hazır yapay zeka modellerine sahip yapay zeka hizmetleri sağlar.
- Machine Learning: Makine Öğrenmesi'nin kurulum, model eğitimi, dağıtım vb. bilgilerini kapsayan ana belge sayfası.
- Azure AI hizmetleri: Görme, konuşma, dil ve karar alma görevleri için önceden oluşturulmuş yapay zeka modelleri sağlayan yapay zeka hizmetleri hakkında bilgi.
Özetle yapay zeka ve ML hizmetleri, makine öğrenmesi modellerinin geliştirme, eğitim ve dağıtımını kolaylaştıran güçlü araçlar ve çerçeveler sağladığından TDSP için çok önemlidir. Bu hizmetler, model geliştirme sürecini büyük ölçüde hızlandıran algoritma seçimi ve hiper parametre ayarlama gibi karmaşık görevleri otomatikleştirir. Bu hizmetler ayrıca veri bilim adamlarının büyük veri kümelerini ve yoğun işlem gücü gerektiren görevleri verimli bir şekilde işlemelerine yardımcı olan ölçeklenebilir altyapı sağlar. Yapay zeka ve ML araçları diğer Azure hizmetleriyle sorunsuz bir şekilde tümleştirilir ve veri alımı, ön işleme ve model dağıtımlarını geliştirir. Tümleştirme sorunsuz bir uçtan uca iş akışı sağlamaya yardımcı olur. Ayrıca bu hizmetler işbirliğini ve yeniden üretilebilirliği teşvik eder. Ekipler yüksek güvenlik ve uyumluluk standartlarını korurken içgörüleri paylaşabilir ve sonuçlar ve modellerle etkili bir şekilde denemeler yapabilir.
Sorumlu AI
Microsoft, yapay zeka veya ML çözümleriyle yapay zeka ve ML çözümleri içinde sorumlu yapay zeka araçlarını tanıtmaktadır. Bu araçlar Microsoft Sorumlu Yapay Zeka Standardını destekler. İş yükünüz yine de yapay zekayla ilgili zararları tek tek ele almalıdır.
Eşler tarafından gözden geçirilmiş alıntılar
TDSP, ekiplerin Microsoft görevlendirmelerinde kullandığı iyi oluşturulmuş bir metodolojidir. TDSP, hakemli literatürde belgelenmiştir ve incelenmiştir. Alıntılar, TDSP özelliklerini ve uygulamalarını araştırma fırsatı sağlar. Daha fazla bilgi ve alıntı listesi için bkz . TDSP yaşam döngüsü.