Synapse SQL havuzunda çoğaltılmış tabloları kullanmaya yönelik tasarım kılavuzu
Bu makale, Synapse SQL havuzu şemanızda çoğaltılmış tablolar tasarlamaya yönelik öneriler sağlar. Veri taşımayı ve sorgu karmaşıklığını azaltarak sorgu performansını geliştirmek için bu önerileri kullanın.
Önkoşullar
Bu makalede, SQL havuzundaki veri dağıtımı ve veri taşıma kavramları hakkında bilgi sahibi olduğunuz varsayılır. Daha fazla bilgi için mimari makalesine bakın.
Tablo tasarımının bir parçası olarak verileriniz ve verilerin nasıl sorgulandığı hakkında olabildiğince fazla bilgi edinin. Örneğin, şu soruları göz önünde bulundurun:
- Tablo ne kadar büyük?
- Tablo ne sıklıkta yenilenir?
- SQL havuzunda olgu ve boyut tablolarım var mı?
Çoğaltılan tablo nedir?
Çoğaltılan tablo, her İşlem düğümünde erişilebilen tablonun tam kopyasına sahiptir. Tablo çoğaltıldığında bir birleştirme veya toplama öncesinde İşlem düğümleri arasında verileri aktarma gereksinimi ortadan kalkar. Tablonun birden çok kopyası olduğundan, tablo boyutu 2 GB'tan küçük olduğunda çoğaltılan tablolar en iyi şekilde çalışır. 2 GB sabit bir sınır değildir. Veriler statikse ve değişmezse, daha büyük tabloları çoğaltabilirsiniz.
Aşağıdaki diyagramda, her İşlem düğümünde erişilebilen çoğaltılmış bir tablo gösterilmektedir. SQL havuzunda, çoğaltılan tablo her işlem düğümündeki bir dağıtım veritabanına tamamen kopyalanır.

Çoğaltılan tablolar, yıldız şemasındaki boyut tabloları için iyi çalışır. Boyut tabloları genellikle boyut tablosundan farklı şekilde dağıtılan olgu tablolarına katılır. Boyutlar genellikle birden çok kopyayı depolamayı ve korumayı mümkün kılan bir boyuttadır. Boyutlar, müşteri adı ve adresi ve ürün ayrıntıları gibi yavaş değişen açıklayıcı verileri depolar. Verilerin yavaş değişen yapısı, çoğaltılan tablonun daha az bakımına yol açar.
Aşağıdaki durumlarda çoğaltılmış tablo kullanmayı göz önünde bulundurun:
- Disk üzerindeki tablo boyutu, satır sayısından bağımsız olarak 2 GB'tan küçüktür. Tablonun boyutunu bulmak için DBCC PDW_SHOWSPACEUSED komutunu kullanabilirsiniz:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Tablo, veri taşıma gerektirmeyen birleşimlerde kullanılır. Karma olarak dağıtılmış tablo gibi aynı sütunda dağıtılmayan tabloları hepsini bir kez deneme tablosuna eklerken, sorguyu tamamlamak için veri taşıma gerekir. Tablolardan biri küçükse, çoğaltılmış bir tablo düşünün. Çoğu durumda hepsini bir kez deneme tabloları yerine çoğaltılmış tablolar kullanmanızı öneririz. Sorgu planlarındaki veri taşıma işlemlerini görüntülemek için sys.dm_pdw_request_steps kullanın. BroadcastMoveOperation, çoğaltılmış bir tablo kullanılarak ortadan kaldırılabilir tipik veri taşıma işlemidir.
Çoğaltılan tablolar aşağıdaki durumlarda en iyi sorgu performansını vermeyebilir:
- Tabloda sık sık ekleme, güncelleştirme ve silme işlemleri vardır. Veri işleme dili (DML) işlemleri çoğaltılan tablonun yeniden oluşturulmasını gerektirir. Sık sık yeniden derlemek performansın yavaşlamasına neden olabilir.
- SQL havuzu sık sık ölçeklendirilir. SQL havuzunu ölçeklendirmek, çoğaltılan tablonun yeniden oluşturulmasına neden olan İşlem düğümlerinin sayısını değiştirir.
- Tabloda çok sayıda sütun vardır, ancak veri işlemleri genellikle yalnızca az sayıda sütuna erişer. Bu senaryoda, tablonun tamamını çoğaltmak yerine, tabloyu dağıtmak ve ardından sık erişilen sütunlarda bir dizin oluşturmak daha etkili olabilir. Bir sorgu veri taşıma gerektirdiğinde, SQL havuzu yalnızca istenen sütunlar için verileri taşır.
İpucu
Dizin oluşturma ve çoğaltılan tablolar hakkında daha fazla kılavuz için bkz . Azure Synapse Analytics'te ayrılmış SQL havuzu (eski adı SQL DW) için başvuru sayfası.
Çoğaltılmış tabloları basit sorgu önkoşullarıyla kullanma
Tabloyu dağıtmayı veya çoğaltmayı seçmeden önce, tabloda çalıştırmayı planladığınız sorgu türlerini düşünün. Mümkün olduğu
- Eşitlik veya eşitsizlik gibi basit sorgu koşullarını içeren sorgular için çoğaltılan tabloları kullanın.
- LIKE veya NOT LIKE gibi karmaşık sorgu koşullarını içeren sorgular için dağıtılmış tabloları kullanın.
Yoğun CPU kullanan sorgular, iş tüm İşlem düğümlerine dağıtıldığında en iyi performansı gösterir. Örneğin, bir tablonun her satırında hesaplamalar çalıştıran sorgular, dağıtılmış tablolarda çoğaltılan tablolardan daha iyi performans gösterir. Çoğaltılan bir tablo her İşlem düğümünde tam olarak depolandığından, çoğaltılan bir tabloya yönelik CPU yoğunluklu bir sorgu her İşlem düğümündeki tablonun tamamına karşı çalıştırılır. Ek hesaplama sorgu performansını yavaşlatabilir.
Örneğin, bu sorgu karmaşık bir koşula sahiptir. Veriler çoğaltılmış tablo yerine dağıtılmış bir tabloda olduğunda daha hızlı çalışır. Bu örnekte veriler hepsini bir kez deneme olarak dağıtılabilir.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Var olan hepsini bir kez deneme tablolarını çoğaltılmış tablolara dönüştürme
Hepsini bir kez deneme tablolarınız zaten varsa, bu makalede özetlenen ölçütleri karşılıyorsa bunları çoğaltılmış tablolara dönüştürmenizi öneririz. Çoğaltılan tablolar, veri taşıma gereksinimini ortadan kaldırdığından hepsini bir kez deneme tablolarının performansını artırır. Hepsini bir kez deneme tablosu her zaman birleşimler için veri taşıma gerektirir.
Bu örnekte, tabloyu çoğaltılmış tablo olarak değiştirmek DimSalesTerritory için CTAS kullanılır. Bu örnek karma dağıtılmış mı yoksa hepsini bir kez deneme mi olduğuna DimSalesTerritory bakılmaksızın çalışır.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Hepsini bir kez deneme ve çoğaltılmış için sorgu performansı örneği
Çoğaltılan tablo, birleştirmeler için veri taşıma gerektirmez çünkü tablonun tamamı her İşlem düğümünde zaten mevcuttur. Boyut tabloları hepsini bir kez deneme dağıtılmışsa, birleştirme boyut tablosunu tam olarak her İşlem düğümüne kopyalar. Verileri taşımak için sorgu planı BroadcastMoveOperation adlı bir işlem içerir. Bu tür veri taşıma işlemi sorgu performansını yavaşlatıyor ve çoğaltılan tablolar kullanılarak ortadan kaldırılıyor. Sorgu planı adımlarını görüntülemek için sys.dm_pdw_request_steps sistem kataloğu görünümünü kullanın.
Örneğin, şemaya karşı AdventureWorks aşağıdaki sorguda FactInternetSales tablo karma olarak dağıtılmıştır. DimDate ve DimSalesTerritory tabloları daha küçük boyutlu tablolardır. Bu sorgu, 2004 mali yılı için Kuzey Amerika toplam satışları döndürür:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Ve'i hepsini bir kez deneme tabloları olarak yeniden oluşturduk DimDate DimSalesTerritory . Sonuç olarak sorgu, birden çok yayın taşıma işlemine sahip olan aşağıdaki sorgu planını göstermiştir:
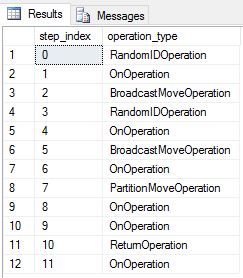
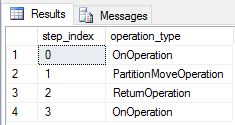
Çoğaltılmış tablolar olarak yeniden oluşturup DimDate DimSalesTerritory sorguyu yeniden çalıştırdık. Sonuçta elde edilen sorgu planı çok daha kısadır ve herhangi bir yayın taşıması yoktur.
Çoğaltılan tabloları değiştirmek için performansla ilgili dikkat edilmesi gerekenler
SQL havuzu, tablonun ana sürümünü koruyarak çoğaltılmış bir tablo uygular. Ana sürümü her İşlem düğümündeki ilk dağıtım veritabanına kopyalar. Bir değişiklik olduğunda, önce ana sürüm güncelleştirilir, ardından her İşlem düğümündeki tablolar yeniden oluşturulur. Çoğaltılan bir tablonun yeniden oluşturulması, tabloyu her İşlem düğümüne kopyalamayı ve ardından dizinleri oluşturmayı içerir. Örneğin, DW2000c üzerindeki çoğaltılmış bir tabloda verilerin beş kopyası bulunur. Her İşlem düğümünde bir ana kopya ve tam kopya. Tüm veriler dağıtım veritabanlarında depolanır. SQL havuzu, daha hızlı veri değişikliği deyimlerini ve esnek ölçeklendirme işlemlerini desteklemek için bu modeli kullanır.
Zaman uyumsuz yeniden derlemeler, çoğaltılan tabloya karşı aşağıdakilerden sonraki ilk sorgu tarafından tetiklenir:
- Veriler yüklendi veya değiştirildi
- Synapse SQL örneği farklı bir düzeye ölçeklendirilir
- Tablo tanımı güncelleştirildi
Yeniden derlemeler şunlardan sonra gerekli değildir:
- Duraklatma işlemi
- İşlemi sürdür
Yeniden derleme, veriler değiştirildikten hemen sonra gerçekleşmez. Bunun yerine, bir sorgu tablodan ilk kez seçtiğinde yeniden oluşturma tetikler. Yeniden derlemeyi tetikleyen sorgu, veriler zaman uyumsuz olarak her İşlem düğümüne kopyalanırken tablonun ana sürümünden hemen okunur. Veri kopyalama işlemi tamamlanana kadar, izleyen sorgular tablonun ana sürümünü kullanmaya devam eder. Çoğaltılan tabloda başka bir yeniden derlemeyi zorlayan herhangi bir etkinlik gerçekleşirse, veri kopyalama geçersiz kılınır ve bir sonraki select deyimi verilerin yeniden kopyalanmasını tetikler.
Dizinleri konservatif olarak kullanma
Standart dizin oluşturma uygulamaları çoğaltılan tablolar için geçerlidir. SQL havuzu, yeniden oluşturma işleminin bir parçası olarak çoğaltılan her tablo dizinini yeniden oluşturur. Yalnızca performans artışı dizinleri yeniden oluşturma maliyetinden daha ağır bastığında dizinleri kullanın.
Toplu veri yükü
Çoğaltılan tablolara veri yüklerken, yükleri birlikte toplu işleyerek yeniden derlemeleri en aza indirmeyi deneyin. Select deyimlerini çalıştırmadan önce tüm toplu yüklemeleri gerçekleştirin.
Örneğin, bu yük düzeni dört kaynaktan verileri yükler ve dört yeniden derleme çağırır.
- Kaynak 1'den yükleyin.
- Select deyimi tetikleyicileri yeniden derleme 1.
- Kaynak 2'den yükleyin.
- Select deyimi tetikleyicileri yeniden derleme 2.
- Kaynak 3'ten yükleyin.
- Select deyimi tetikleyicileri yeniden derleme 3.
- Kaynak 4'ten yükleyin.
- Select deyimi tetikleyicileri yeniden derleme 4.
Örneğin, bu yük düzeni dört kaynaktan verileri yükler, ancak yalnızca bir yeniden derleme çağırır.
- Kaynak 1'den yükleyin.
- Kaynak 2'den yükleyin.
- Kaynak 3'ten yükleyin.
- Kaynak 4'ten yükleyin.
- Deyimi tetikleyicileri yeniden derlemeyi seçin.
Toplu yüklemeden sonra çoğaltılmış tabloyu yeniden oluşturma
Tutarlı sorgu yürütme sürelerini sağlamak için, toplu yüklemeden sonra çoğaltılan tabloların derlemesini zorlamayı göz önünde bulundurun. Aksi takdirde, ilk sorgu sorguyu tamamlamak için veri taşımayı kullanmaya devam eder.
"Çoğaltılmış Tablo Önbelleği Oluşturma" işlemi aynı anda en fazla iki işlem yürütebilir. Örneğin, beş tablo için önbelleği yeniden oluşturmaya çalışırsanız, sistem aynı anda iki tablo oluşturmak için bir staticrc20 (değiştirilemez) kullanır. Dolayısıyla, 2 GB'ı aşan büyük çoğaltılmış tabloların kullanılmasından kaçınılması önerilir, çünkü bu, düğümler arasında önbellek yeniden oluşturma işlemini yavaşlatabilir ve genel süreyi artırabilir.
Bu sorgu, değiştirilmiş ancak yeniden derlenmemiş çoğaltılmış tabloları listelemek için sys.pdw_replicated_table_cache_state DMV kullanır.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Yeniden derlemeyi tetikleme için, önceki çıktıdaki her tabloda aşağıdaki deyimi çalıştırın.
SELECT TOP 1 * FROM [ReplicatedTable]
Not
Önbelleğe alınmamış çoğaltılmış tablonun istatistiklerini yeniden derlemeyi planlıyorsanız, önbelleği tetiklemeden önce istatistikleri güncelleştirdiğinizden emin olun. İstatistiklerin güncelleştirilmesi önbelleği geçersiz kılacağından sıra önemlidir.
Örnek: ile UPDATE STATISTICSbaşlayın, ardından önbelleğin yeniden oluşturulmasını tetikleyin. Aşağıdaki örneklerde doğru örnek istatistikleri güncelleştirir ve ardından önbelleğin yeniden oluşturulmasını tetikler.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Yeniden oluşturma işlemini izlemek için , 'BuildReplicatedTableCache' ile başlayacağı sys.dm_pdw_exec_requestscommand kullanabilirsiniz. Örneğin:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
İpucu
Tablo boyutu sorguları , çoğaltılmış dağıtım ilkesine sahip olan ve 2 GB'tan büyük olan tabloları doğrulamak için kullanılabilir.
Sonraki adımlar
Çoğaltılmış tablo oluşturmak için şu deyimlerden birini kullanın:
Dağıtılmış tablolara genel bakış için bkz . dağıtılmış tablolar.