Microsoft Fabric'te not defteri görselleştirmesi
Microsoft Fabric, veri ambarları ve büyük veri analizi sistemleri arasında içgörü elde etme süresini hızlandıran tümleşik bir analiz hizmetidir. Not defterlerindeki veri görselleştirme, verileriniz hakkında içgörü elde etmenizi sağlayan önemli bir bileşendir. Büyük ve küçük verilerin insanların anlamasını kolaylaştırmaya yardımcı olur. Ayrıca veri gruplarındaki desenleri, eğilimleri ve aykırı değerleri algılamayı kolaylaştırır.
Apache Spark'ı Doku'da kullandığınızda, Doku not defteri grafik seçenekleri ve popüler açık kaynak kitaplıklarına erişim dahil olmak üzere verilerinizi görselleştirmenize yardımcı olacak çeşitli yerleşik seçenekler vardır.
Doku not defteri kullanırken, grafik seçeneklerini kullanarak tablosal sonuçlar görünümünüzü özelleştirilmiş bir grafiğe dönüştürebilirsiniz. Burada, herhangi bir kod yazmak zorunda kalmadan verilerinizi görselleştirebilirsiniz.
Yerleşik görselleştirme komutu - display() işlevi
Fabric yerleşik görselleştirme işlevi, Apache Spark DataFrames, Pandas DataFrames ve SQL sorgu sonuçlarını zengin biçimli veri görselleştirmelerine dönüştürmenizi sağlar.
Zengin veri çerçevesi tablo görünümünü ve grafik görünümünü oluşturmak için Spark DataFrames veya Dayanıklı Dağıtılmış Veri Kümeleri (RDD) işlevlerinde PySpark ve Scala'da oluşturulan veri çerçevelerinde görüntüleme işlevini kullanabilirsiniz.
İşlenen veri çerçevesinin satır sayısını belirtebilirsiniz. Varsayılan değer 1000değeridir. Not defteri görüntüleme çıkış pencere öğesi, bir veri çerçevesinin en fazla 10000 satırını görüntülemeyi ve profillemeyi destekler.

Özelleştirilmiş kuralınızla eşlenen verileri verimli bir şekilde filtrelemek için genel araç çubuğundaki filtre işlevini kullanabilirsiniz, koşul belirtilen sütuna uygulanır ve filtre sonucu hem tablo görünümüne hem de grafik görünümüne yansıtılır.

SQL deyiminin çıkışı, varsayılan olarak display() ile aynı çıkış pencere öğesini kullanır.
Zengin veri çerçevesi tablo görünümü
Tablo görünümünde ücretsiz seçim desteği
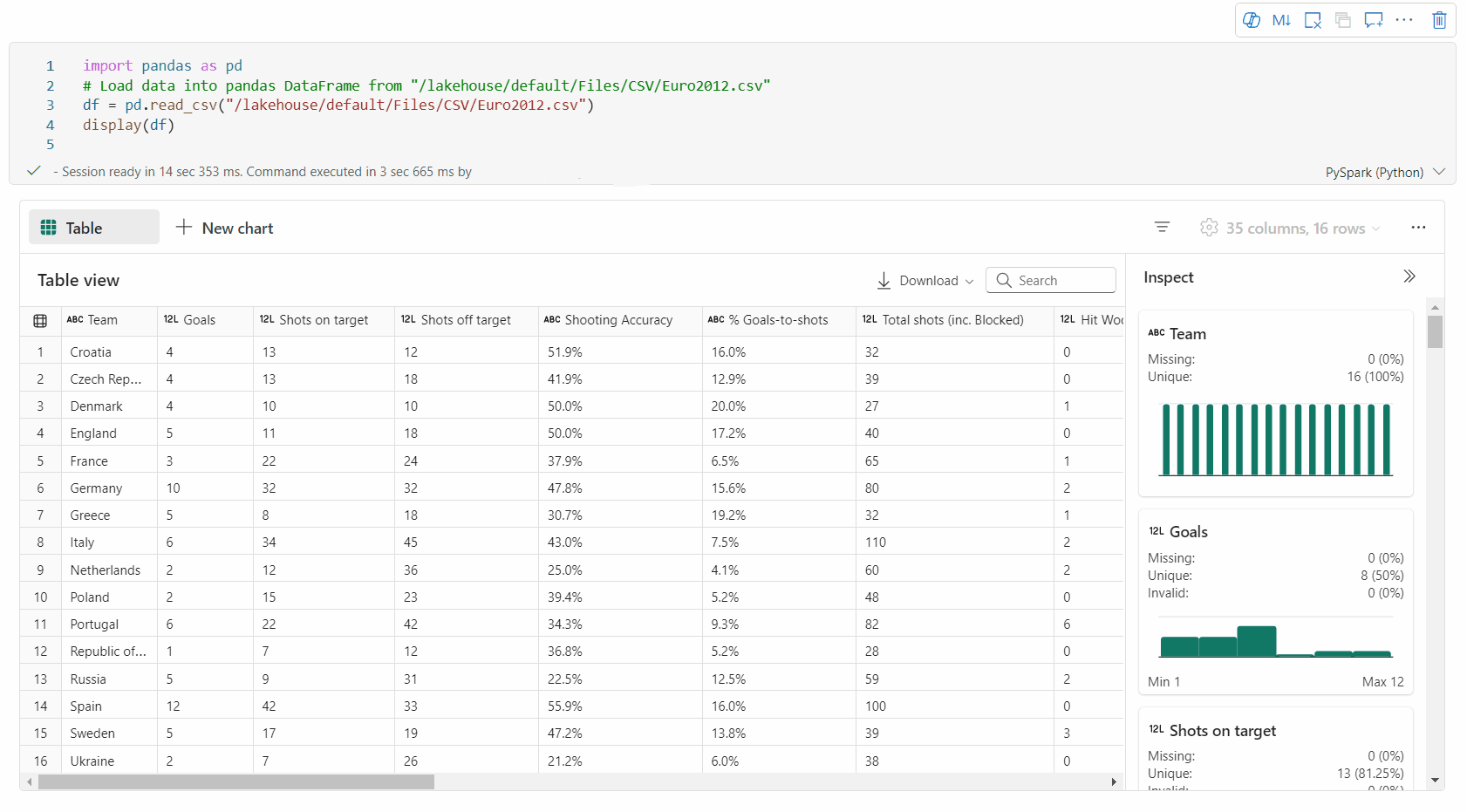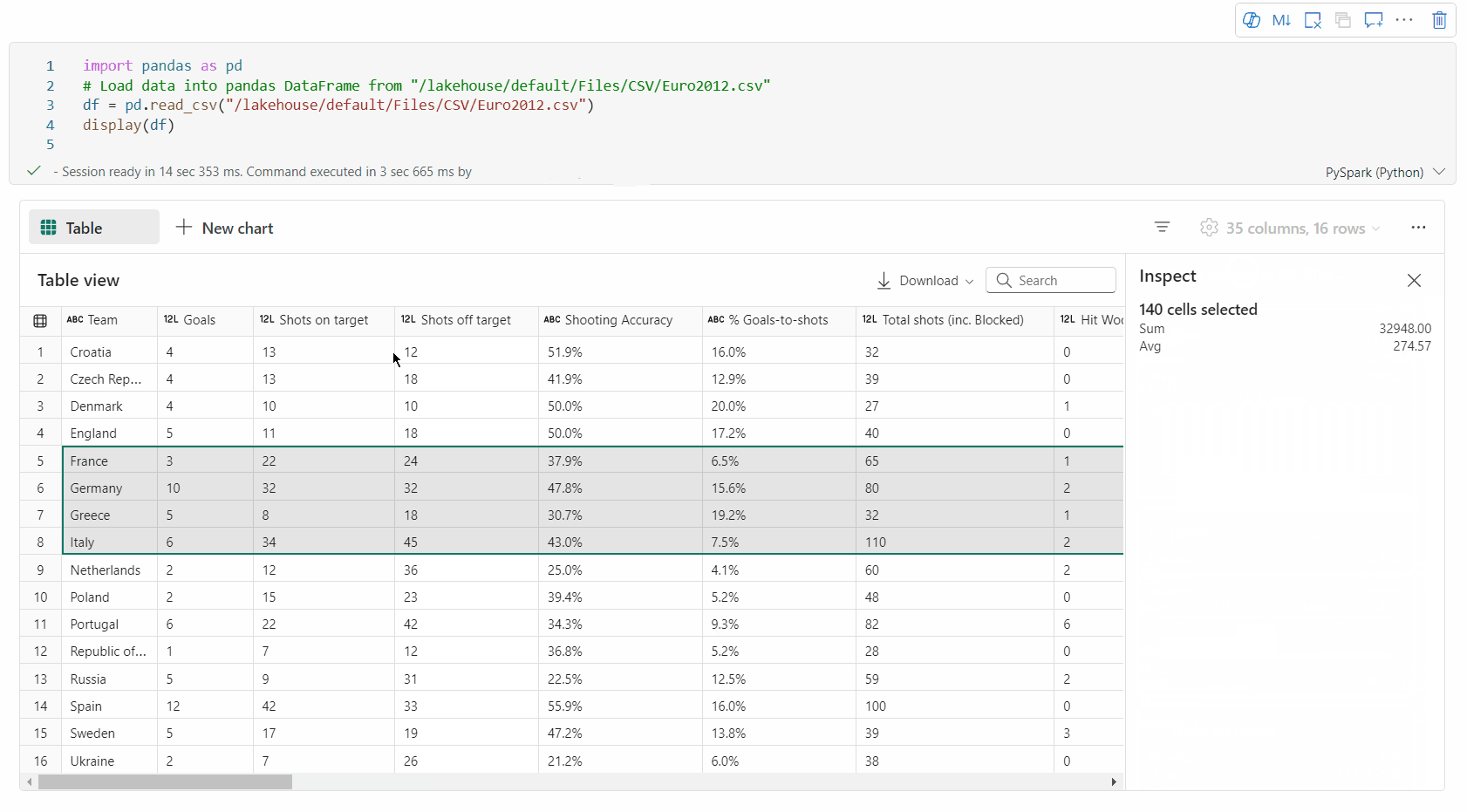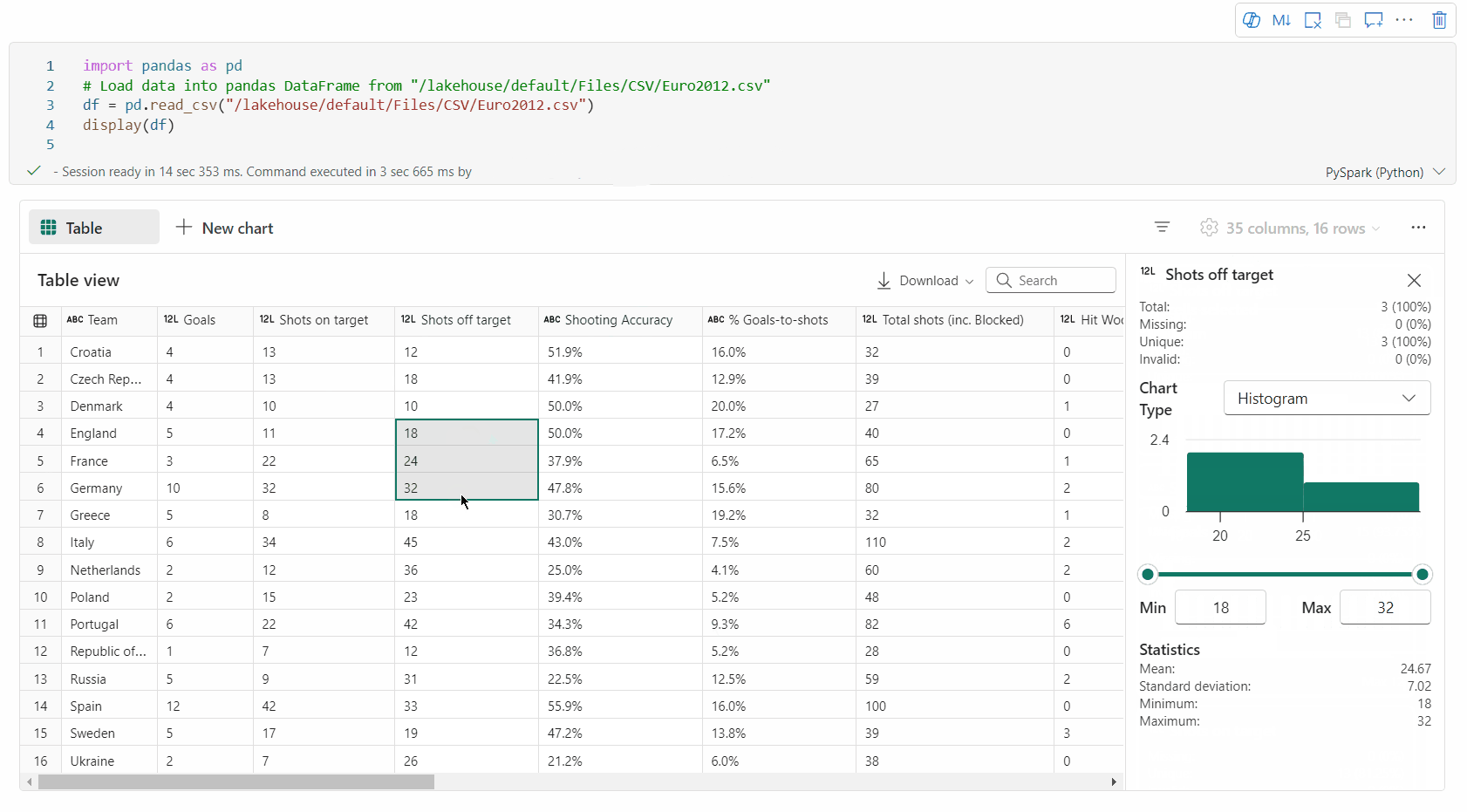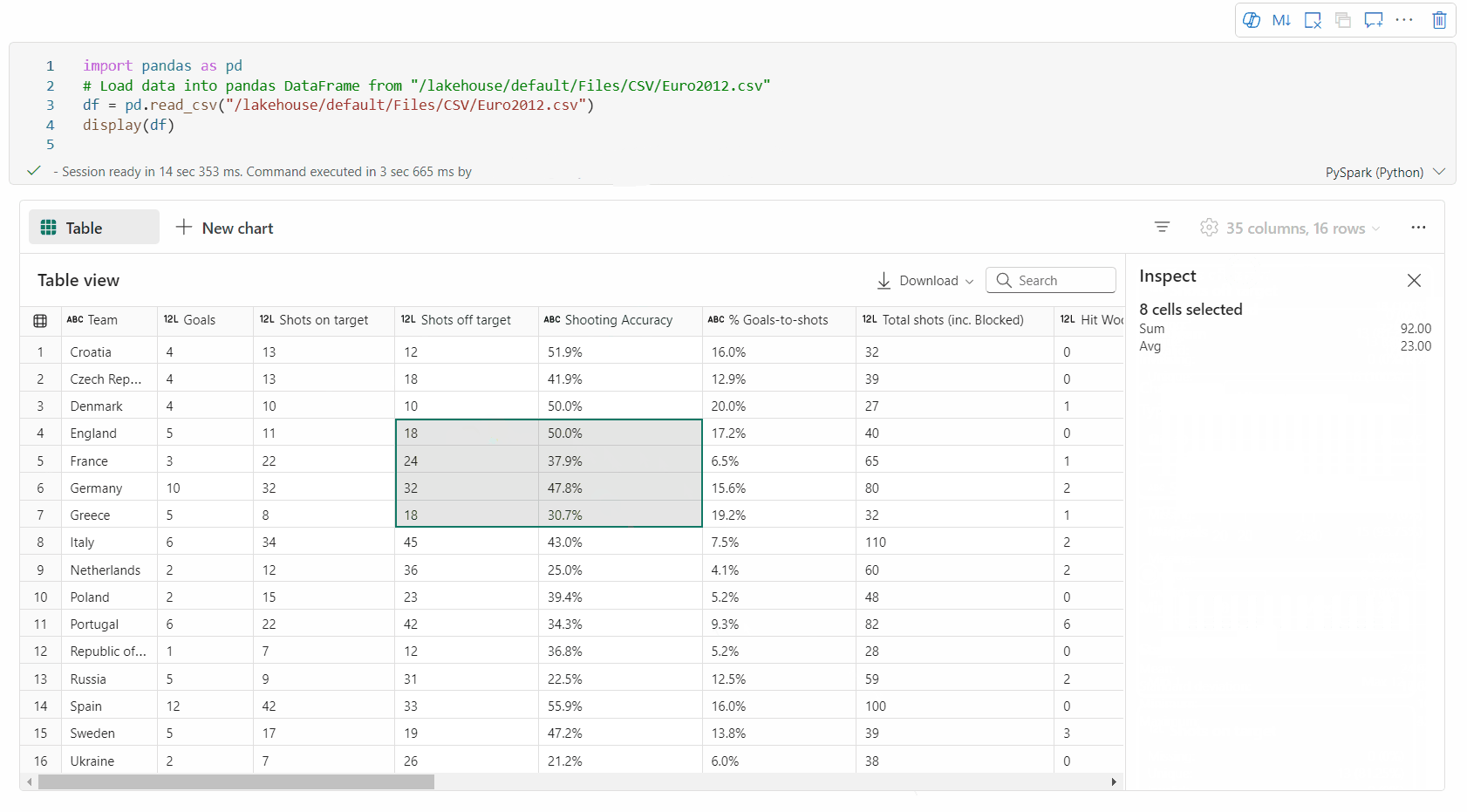
Tablo görünümü, display() komutu kullanılırken varsayılan olarak işlenir. Not defterindeki zengin veri çerçevesi önizlemesi, esnek ve sezgisel seçim özellikleriyle veri analizi deneyimini geliştirmek için tasarlanmış ücretsiz bir seçim işlevi sunar. Bu özellik kullanıcıların veri çerçeveleriyle daha verimli bir şekilde etkileşim kurmasını ve daha derin içgörüler elde etmesini sağlar.
Sütun seçimi
- Tek sütun: Sütunun tamamını seçmek için sütun başlığına tıklayın.
- Birden çok sütun: Tek bir sütun seçtikten sonra ,'Shift' tuşuna basılı tutun, sonra birden çok sütun seçmek için başka bir sütun üst bilgisine tıklayın.
Satır seçimi
- Tek satır: Satırın tamamını seçmek için bir satır üst bilgisine tıklayın.
- Birden çok satır: Tek bir satır seçtikten sonra , 'Shift' tuşuna basılı tutun ve birden çok satır seçmek için başka bir satır üst bilgisine tıklayın.
Hücre içeriği önizlemesi: Ek kod yazmaya gerek kalmadan verilere hızlı ve ayrıntılı bir bakış elde etmek için tek tek hücrelerin içeriğinin önizlemesini görüntüleyin.
Sütun özeti: Verilerin özelliklerini hızla anlamak için veri dağıtımı ve önemli istatistikler de dahil olmak üzere her sütunun özetini alın.
Boş alan seçimi: Seçili toplam hücreye ve seçili alandaki sayısal değerlere genel bir bakış elde etmek için tablonun herhangi bir sürekli kesimini seçin.
Seçili İçeriği Kopyalama: Tüm seçim durumlarında, 'Ctrl + C' kısayolunu kullanarak seçili içeriği hızla kopyalayabilirsiniz. Seçilen veriler CSV biçiminde kopyalanır ve bu da diğer uygulamalarda işlenmesini kolaylaştırır.
Ücretsiz seçim desteğinin Animasyonlu GIF'ini
İnceleme bölmesi aracılığıyla veri profili oluşturma desteği
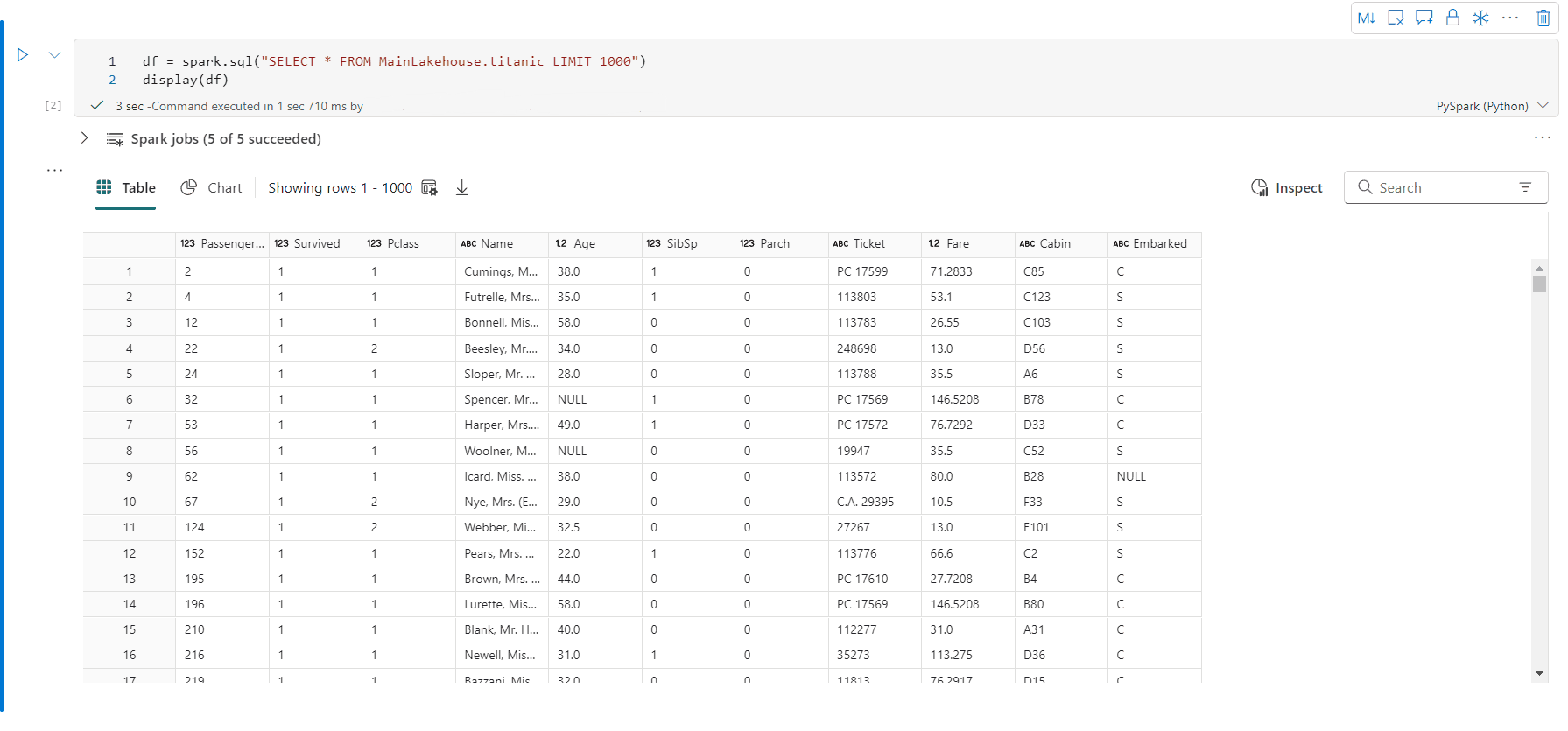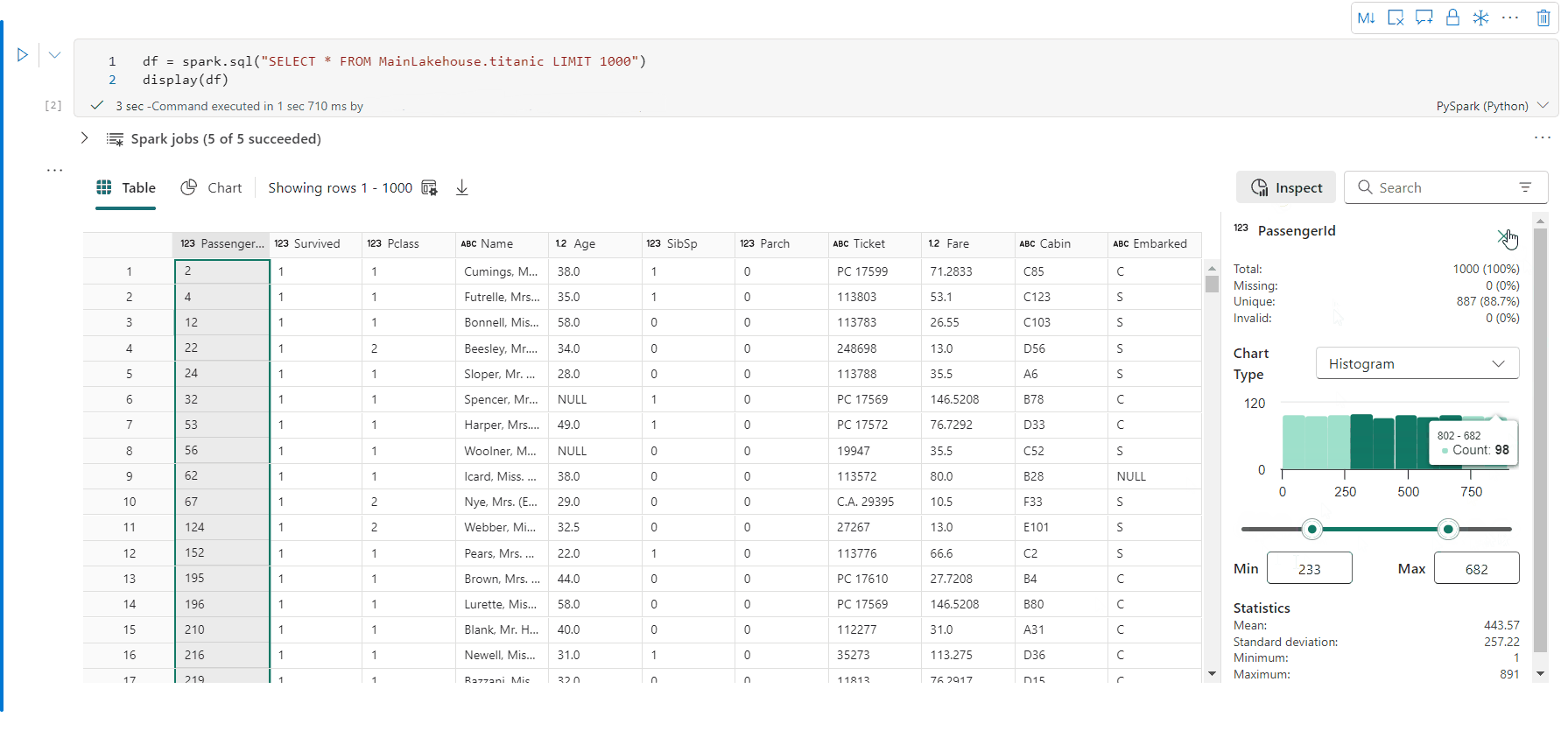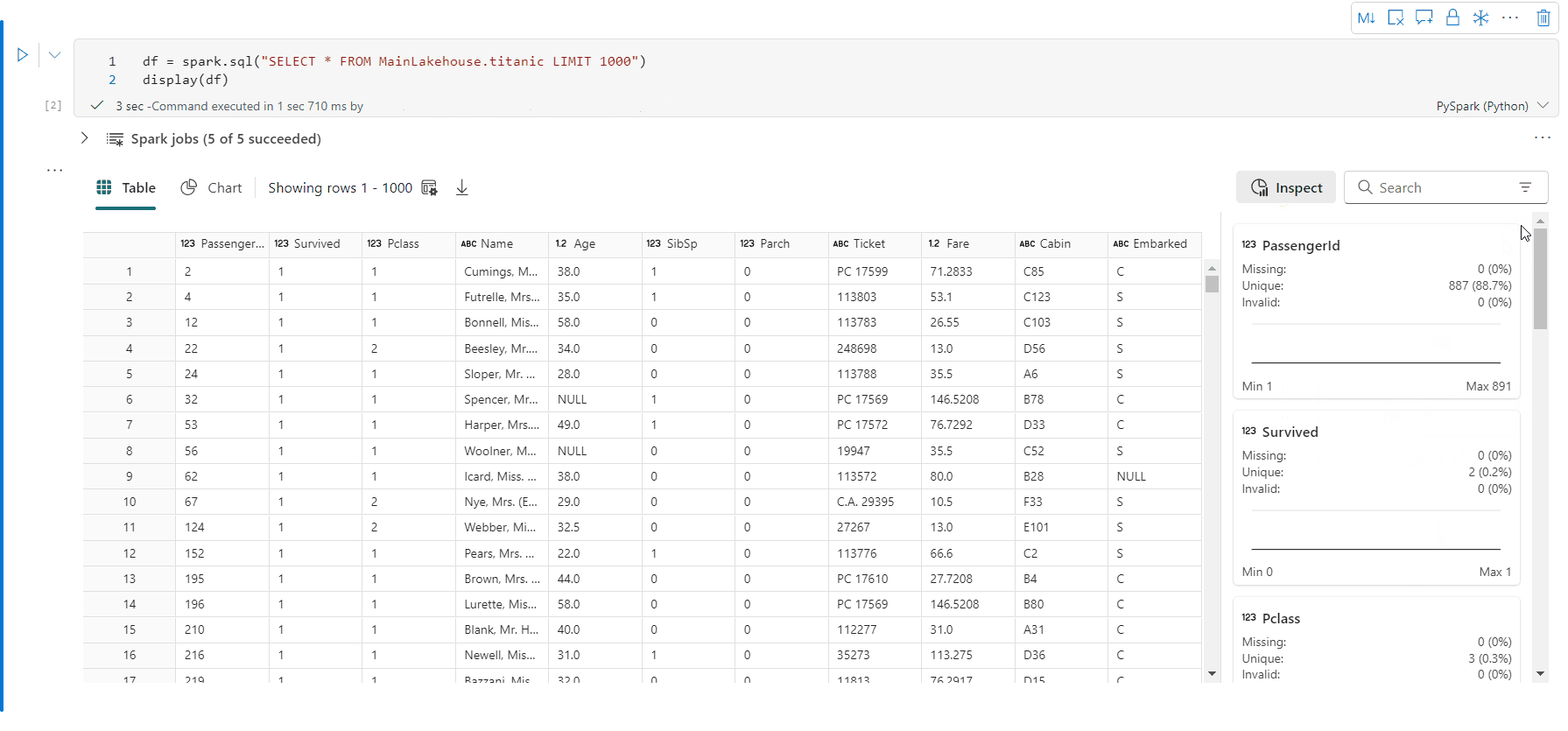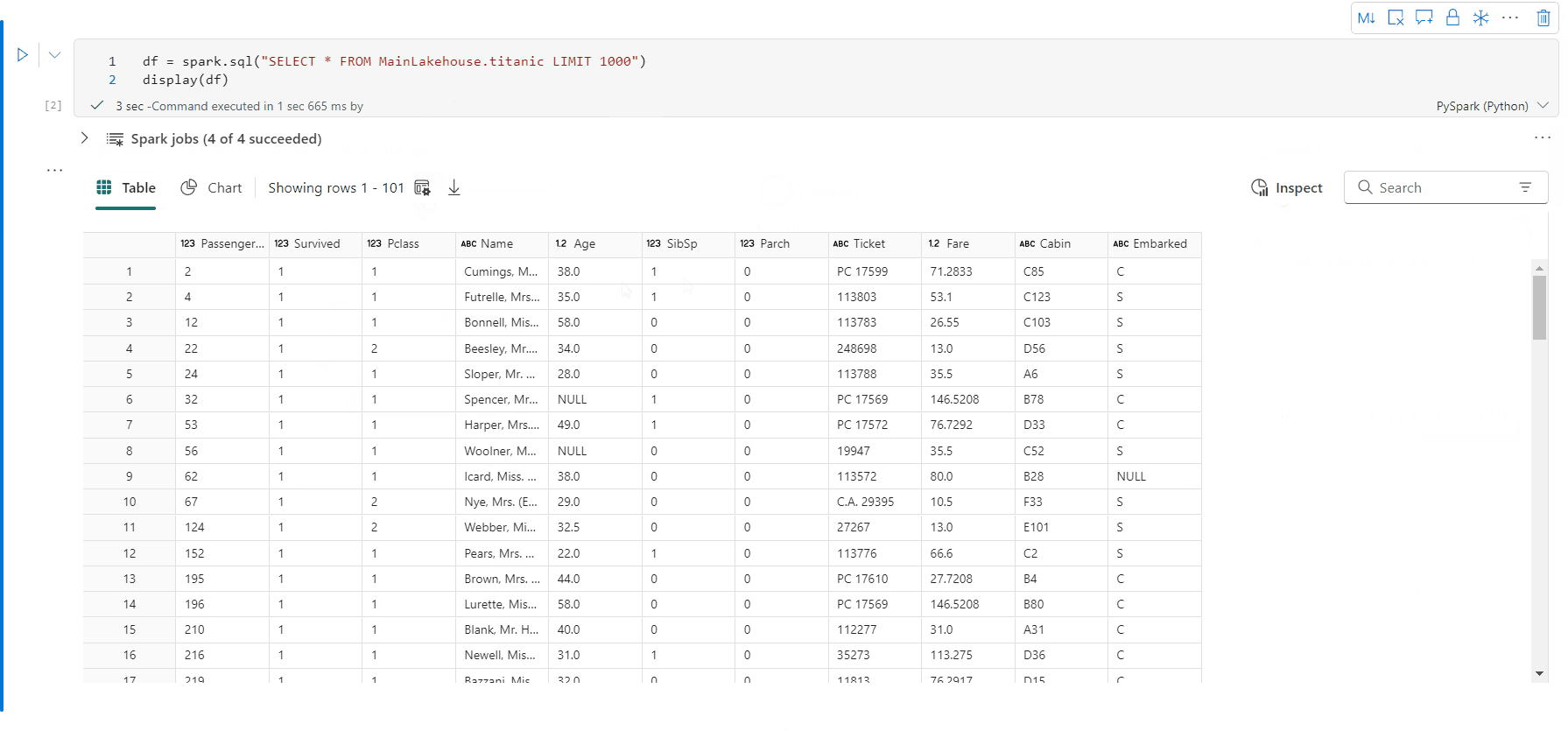
İncele düğmesine tıklayarak veri çerçevenizin profilini oluşturabilirsiniz. Özetlenmiş veri dağılımını sağlar ve her sütunun istatistiklerini gösterir.
"İncele" yan bölmesindeki her kart, veri çerçevesinin bir sütununa eşlenir; karta tıklayarak veya tabloda bir sütun seçerek daha fazla ayrıntı görüntüleyebilirsiniz.
Tablonun hücresine tıklayarak hücre ayrıntılarını görüntüleyebilirsiniz. Bu özellik, veri çerçevesi uzun dize türü içeriği içerdiğinde kullanışlıdır.
Yeni zengin veri çerçevesi grafik görünümü
Not
Şu anda özellik önizleme aşamasındadır.
Geliştirilmiş grafik görünümü display() komutunda kullanılabilir. display() komutunu kullanarak verilerinizi görselleştirmek için daha sezgisel ve güçlü bir deneyim sağlar.
Artık Yeni grafik'e tıklayarak tek bir display() çıkış pencere öğesinde en fazla 5 grafik ekleyebilir, böylece farklı sütunlara dayalı birden çok grafik oluşturabilir ve grafikleri kolayca karşılaştırabilirsiniz.
Yeni grafikler oluştururken hedef veri çerçevesini temel alan grafik önerilerinin listesini alabilirsiniz. Önerilen bir grafiği düzenlemeyi veya sıfırdan kendi grafiğinizi oluşturmayı seçebilirsiniz.
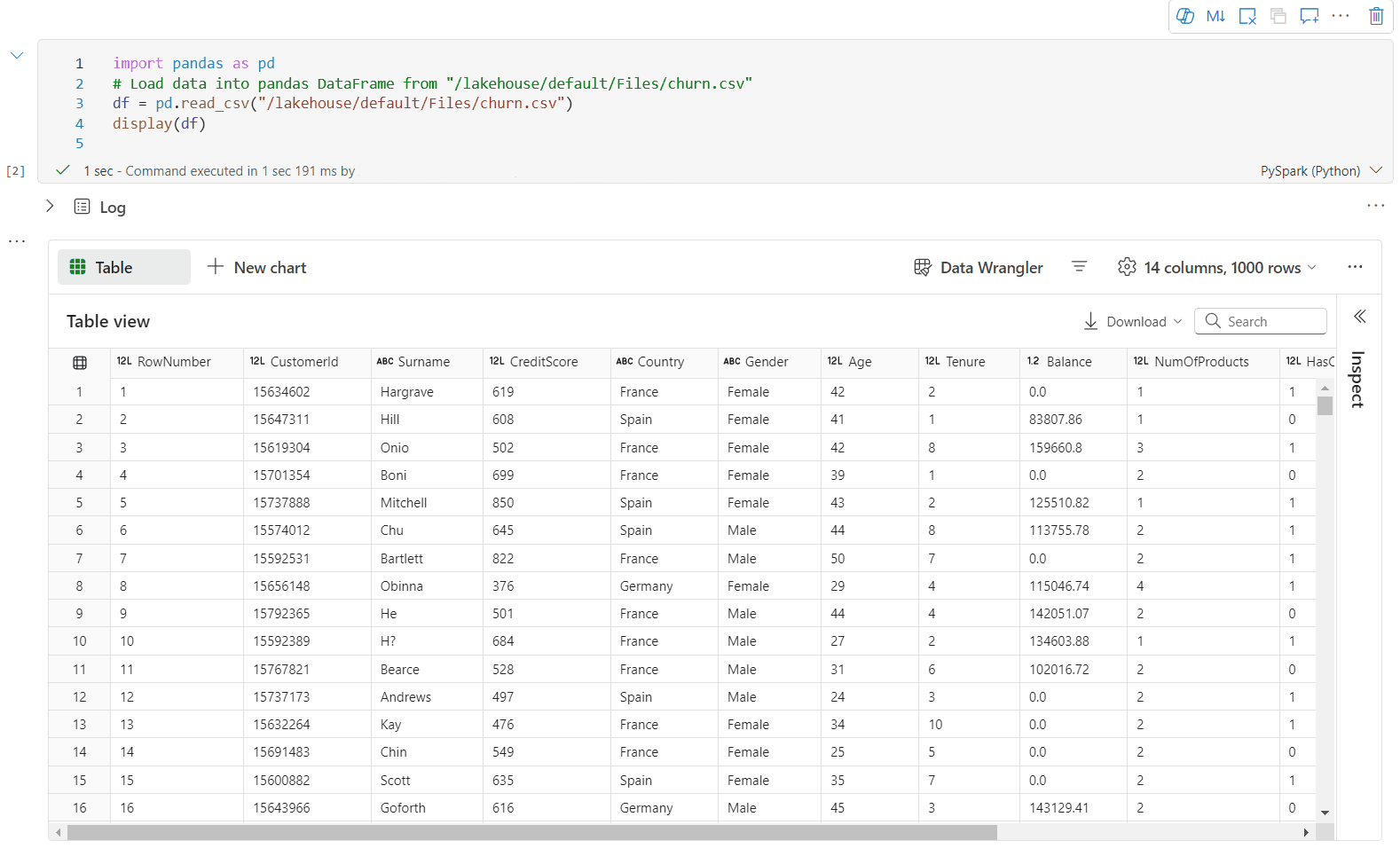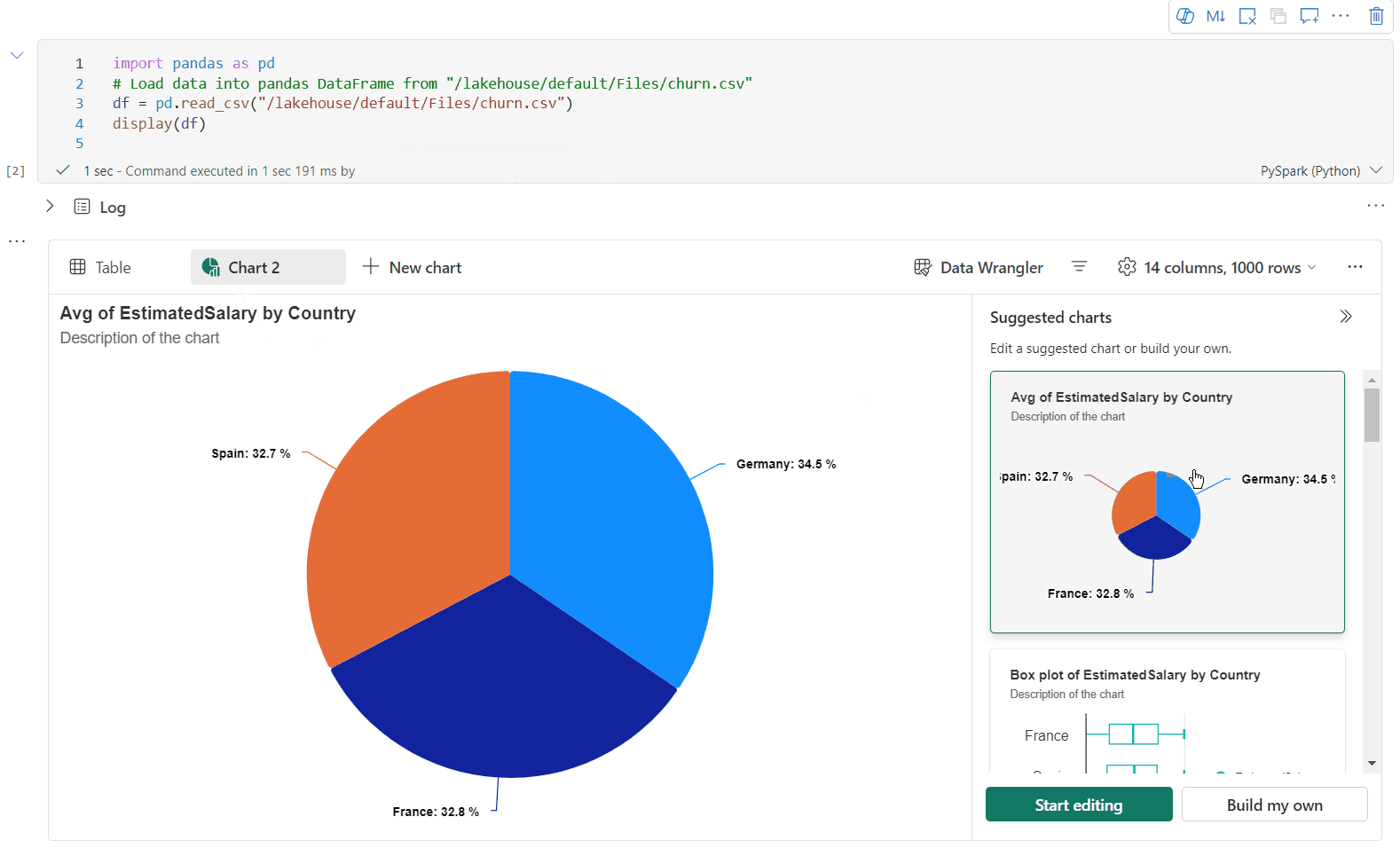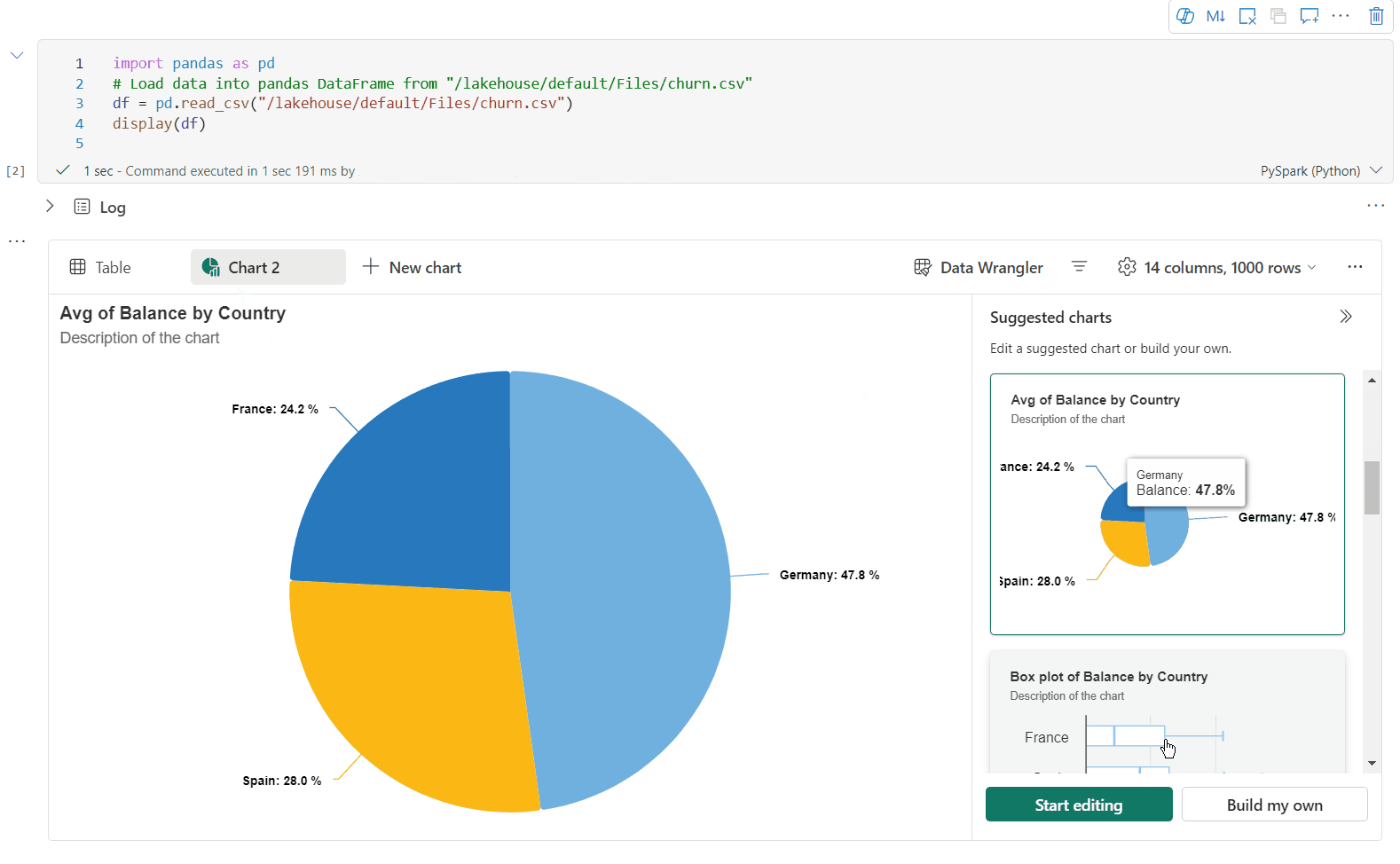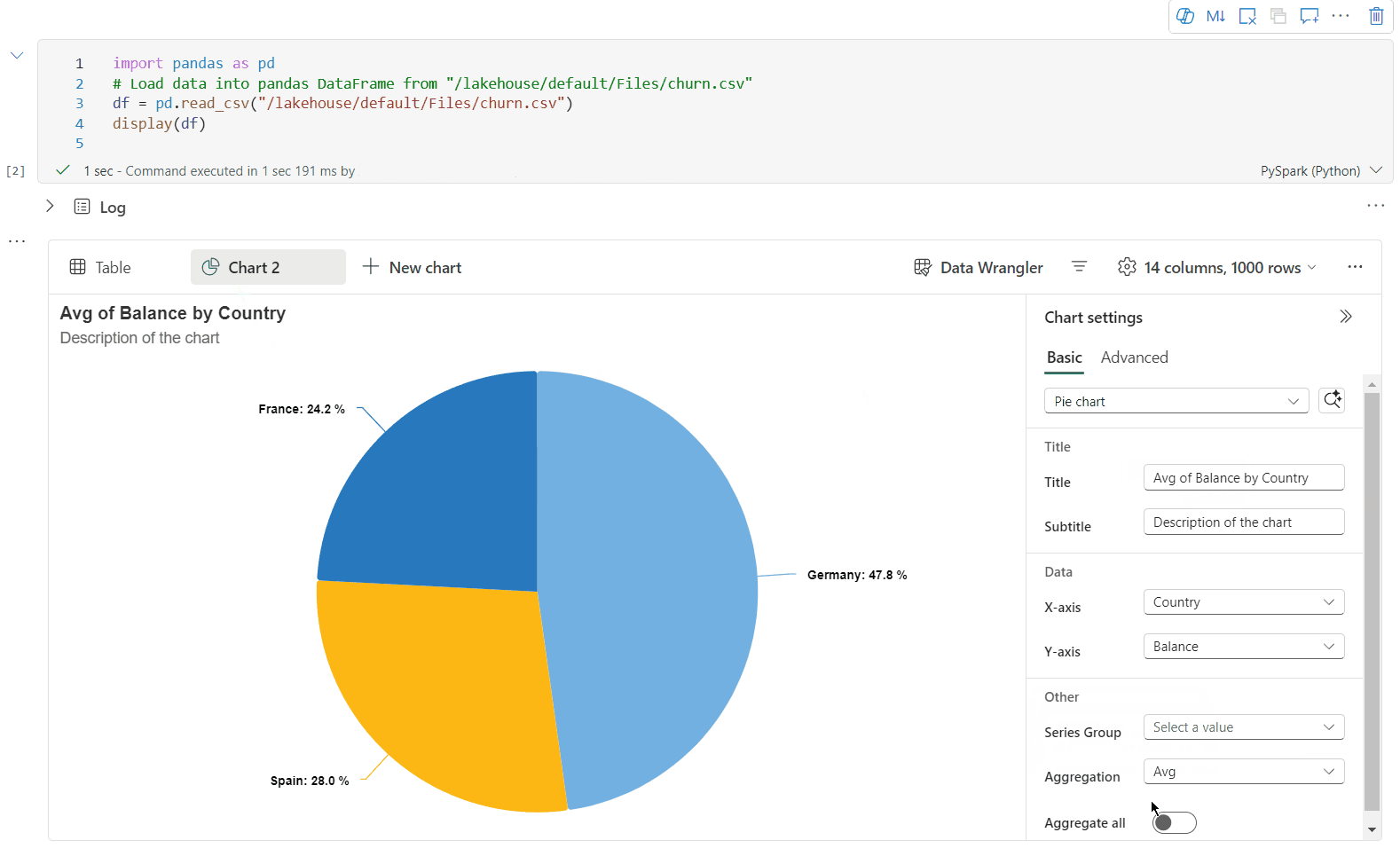
Artık aşağıdaki ayarları belirterek görselleştirmenizi özelleştirebilirsiniz. Ayar seçenekleri seçili grafik türüne göre değişebilir:
Kategori Temel ayarlar Açıklama Grafik türü Görüntüleme işlevi çubuk grafikler, dağılım grafikleri, çizgi grafikler, özet tablo ve daha fazlası dahil olmak üzere çok çeşitli grafik türlerini destekler. Başlık Başlık Grafiğin başlığı. Başlık Alt yazı Daha fazla açıklama içeren grafiğin alt başlığı. Veri X-ekseni Grafiğin anahtarını belirtin. Veri Y ekseni Grafiğin değerlerini belirtin. Gösterge Göstergeyi Göster Göstergeyi etkinleştirin/devre dışı bırakın. Gösterge Position Göstergenin konumunu özelleştirin. Diğer Seri grubu Toplama gruplarını belirlemek için bu yapılandırmayı kullanın. Diğer Toplama Görselleştirmenizdeki verileri toplamak için bu yöntemi kullanın. Diğer Yığılmış Sonucun görüntüleme stilini yapılandırın. Not
Varsayılan olarak display(df) işlevi, grafikleri işlemek için verilerin yalnızca ilk 1.000 satırını alır. Tüm sonuçlarda Toplama'yı seçin ve ardından tüm veri çerçevesinden grafik oluşturmayı uygulamak için Uygula'yı seçin. Grafik ayarı değiştiğinde bir Spark işi tetikleniyor. Hesaplamanın tamamlanması ve grafiğin işlenmesi birkaç dakika sürebilir.
Kategori Gelişmiş ayarlar Açıklama Color Tema Grafiğin tema renk kümesini tanımlayın. X-ekseni Etiket X eksenine bir etiket belirtin. X-ekseni Ölçek X ekseninin ölçek işlevini belirtin. X-ekseni Aralık X ekseni değer aralığını belirtin. Y ekseni Etiket Y eksenine bir etiket belirtin. Y ekseni Ölçek Y ekseninin ölçek işlevini belirtin. Y ekseni Aralık Y ekseni değer aralığını belirtin. Görüntüle Etiketleri göster Grafikte sonuç etiketlerini gösterin/gizleyin. Yapılandırma değişiklikleri hemen geçerli olur ve tüm yapılandırmalar not defteri içeriğinde otomatik olarak kaydedilir.

Grafik sekmesi menüsünde grafikleri kolayca yeniden adlandırabilir, çoğaltabilir veya silebilirsiniz .

Kullanıcı bir grafiğin üzerine geldiğinde yeni grafik deneyiminde etkileşimli bir araç çubuğu kullanılabilir. Yakınlaştırma, uzaklaştırma, yakınlaştırmak, sıfırlamak, kaydırmak vb. gibi işlemleri destekler.




Eski grafik görünümü
Not
Eski grafik görünümü, yeni grafik görünümü önizlemeyi tamamladıktan sonra kullanımdan kaldırılacaktır.
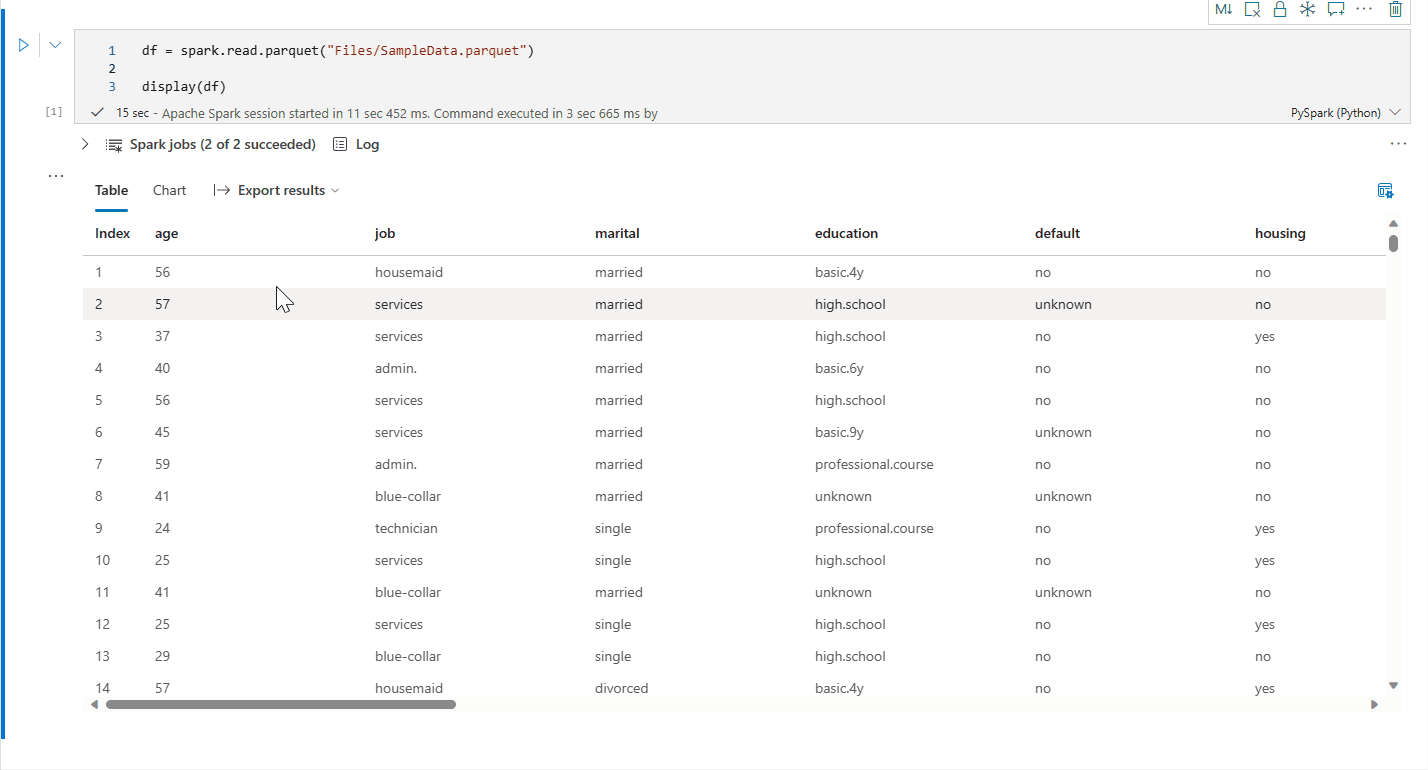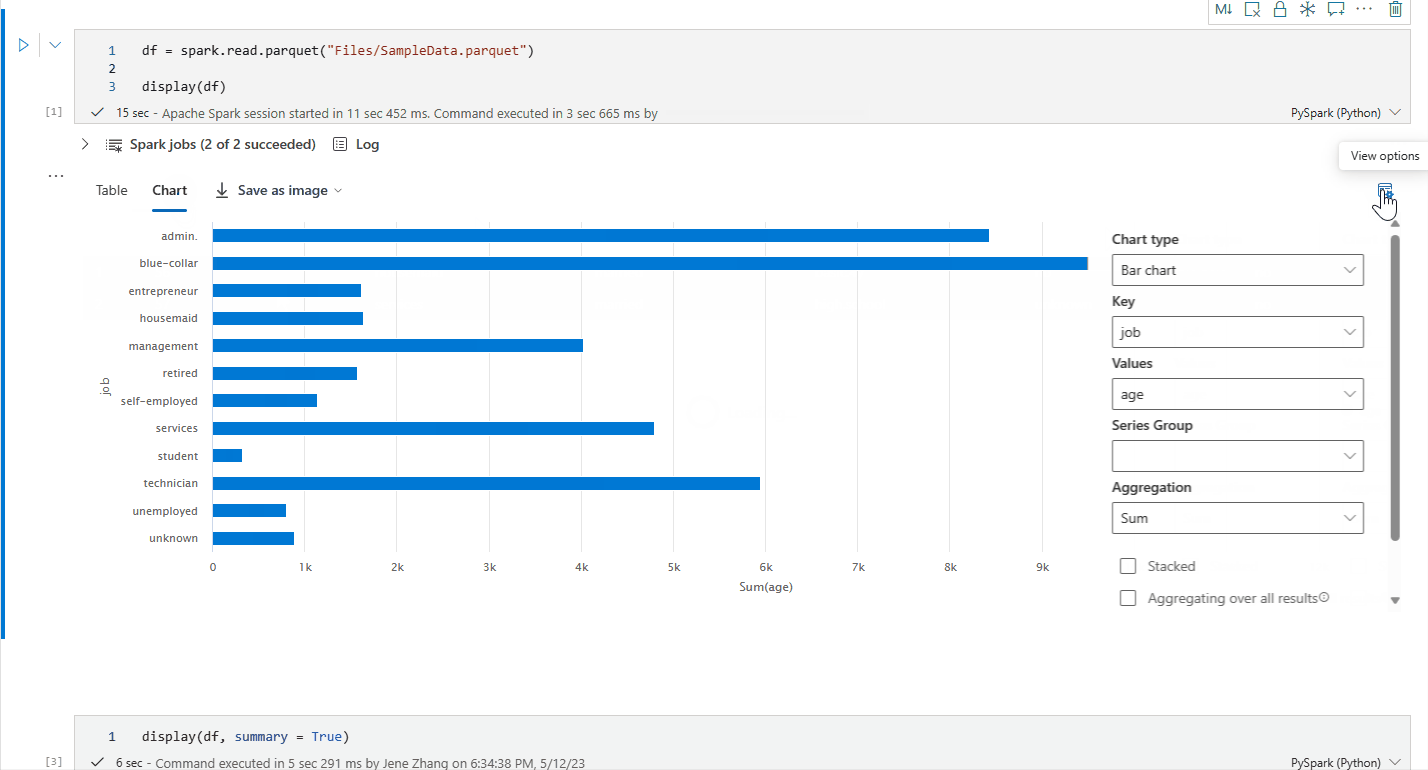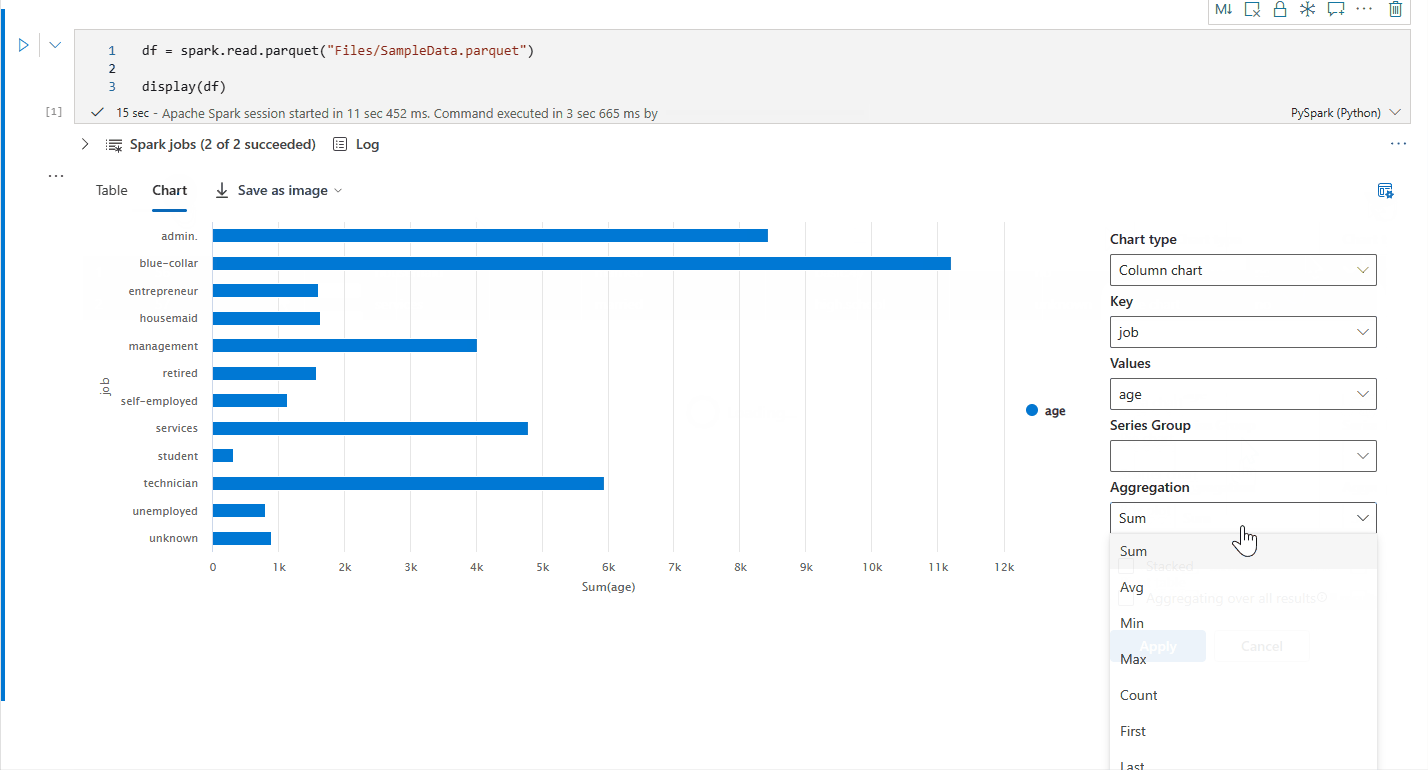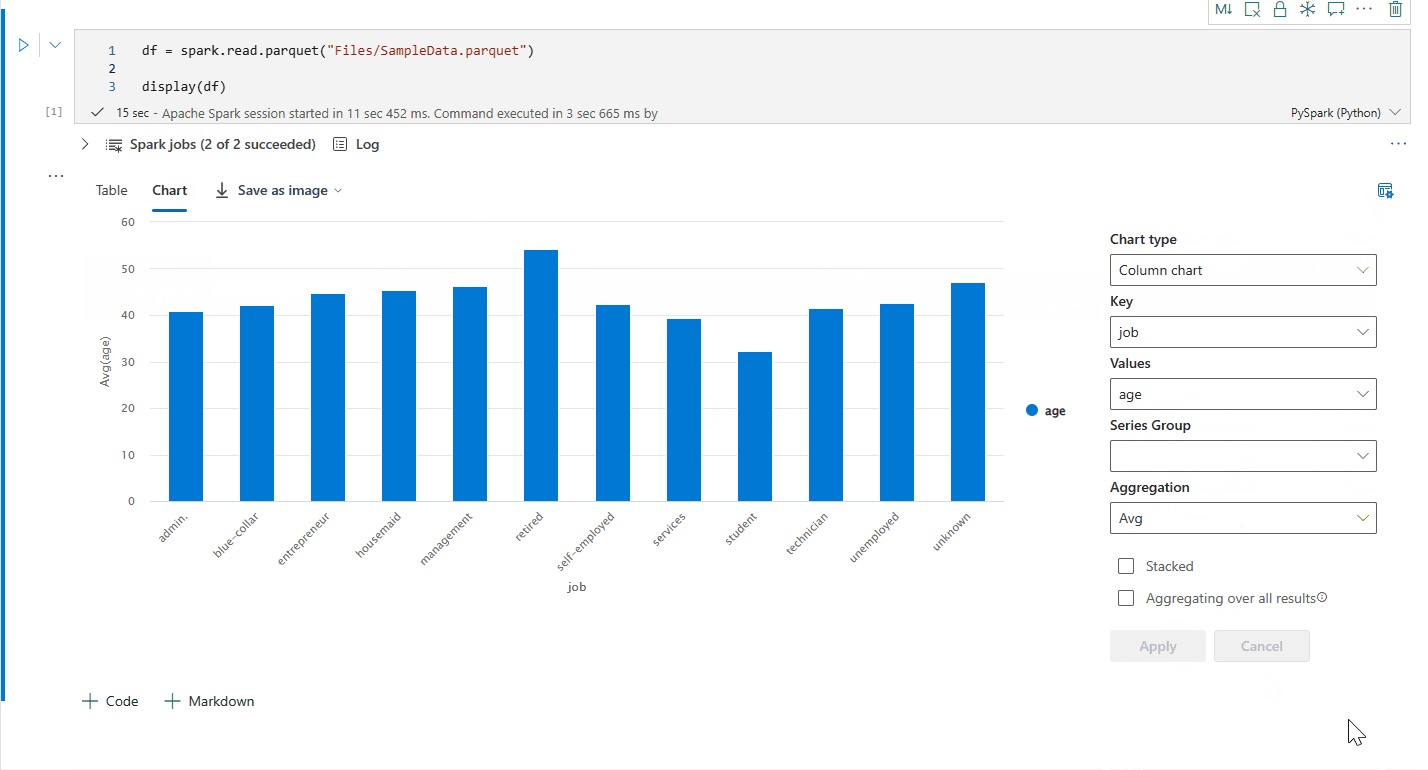
'Yeni görselleştirme'yi kapatarak eski grafik görünümüne geri dönebilirsiniz. Yeni deneyim varsayılan olarak etkindir.

İşlenmiş bir tablo görünümünüz olduğunda Grafik görünümüne geçin.
Doku not defteri, grafiği veri içgörüleriyle anlamlı hale getirmek için hedef veri çerçevesine dayalı grafikleri otomatik olarak önerir.
Artık aşağıdaki değerleri belirterek görselleştirmenizi özelleştirebilirsiniz:
Yapılandırma Açıklama Grafik türü Görüntüleme işlevi çubuk grafikler, dağılım grafikleri, çizgi grafikler ve daha fazlası dahil olmak üzere çok çeşitli grafik türlerini destekler. Anahtar x ekseni için değer aralığını belirtin. Değer Y ekseni değerleri için değer aralığını belirtin. Seri grubu Toplama gruplarını belirlemek için bu yapılandırmayı kullanın. Toplama Görselleştirmenizdeki verileri toplamak için bu yöntemi kullanın. Yapılandırmalar Not Defteri çıkış içeriğinde otomatik olarak kaydedilir.
Not
Varsayılan olarak display(df) işlevi, grafikleri işlemek için verilerin yalnızca ilk 1.000 satırını alır. Tüm sonuçlarda Toplama'yı seçin ve ardından tüm veri çerçevesinden grafik oluşturmayı uygulamak için Uygula'yı seçin. Grafik ayarı değiştiğinde bir Spark işi tetikleniyor. Hesaplamanın tamamlanması ve grafiğin işlenmesi birkaç dakika sürebilir.
İş tamamlandığında, son görselleştirmenizi görüntüleyebilir ve bunlarla etkileşim kurabilirsiniz.

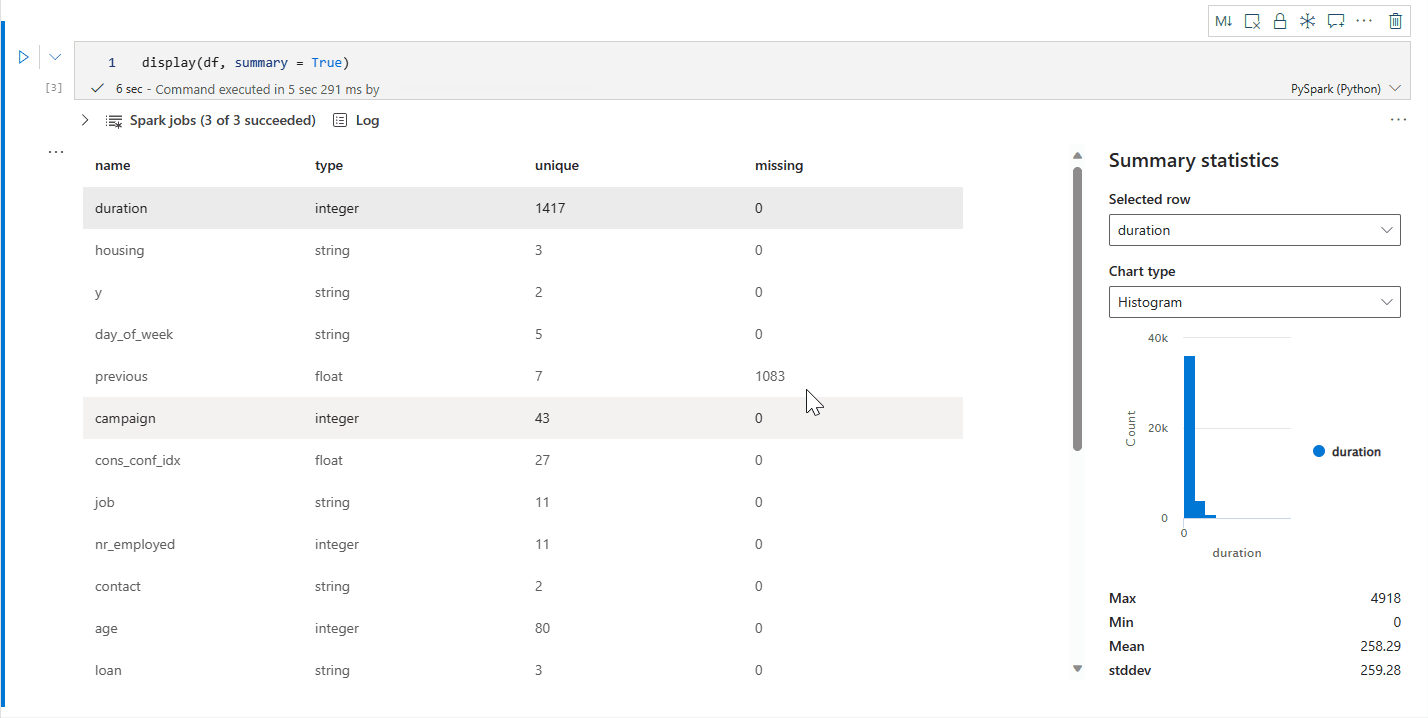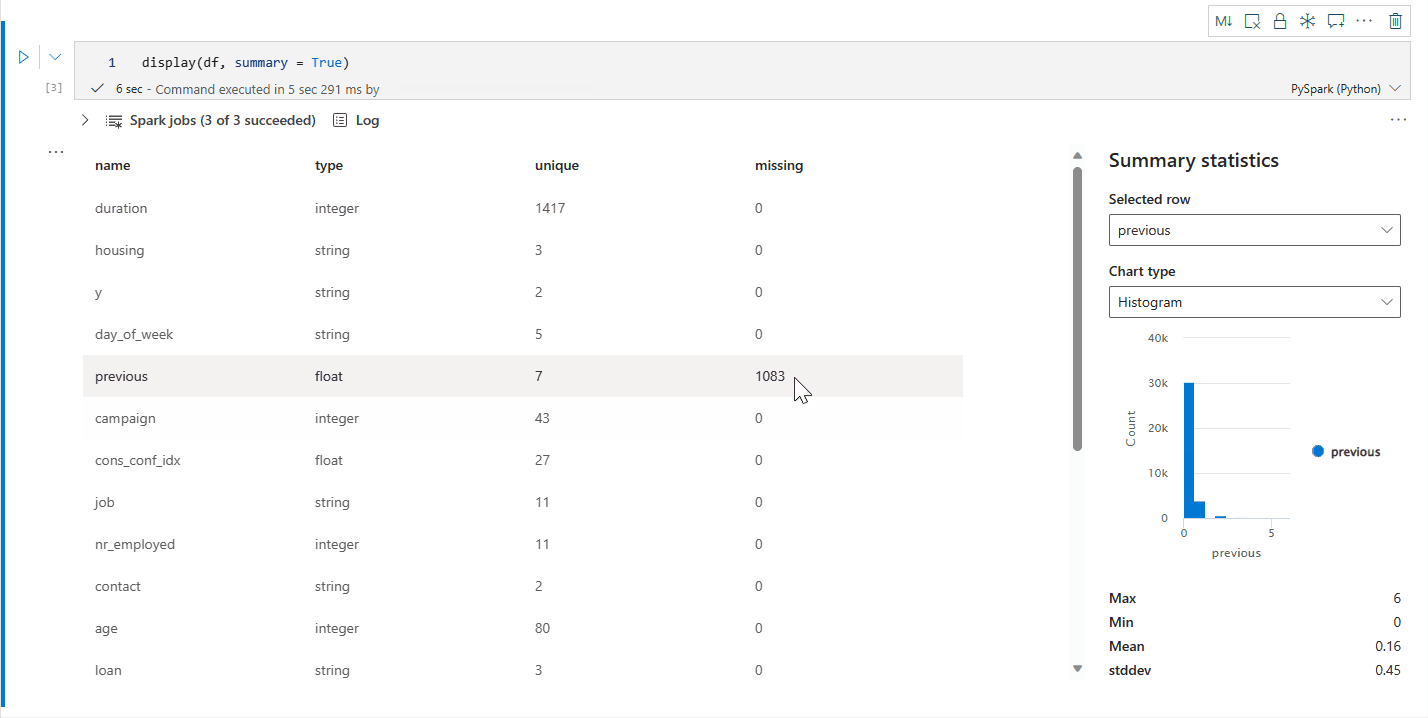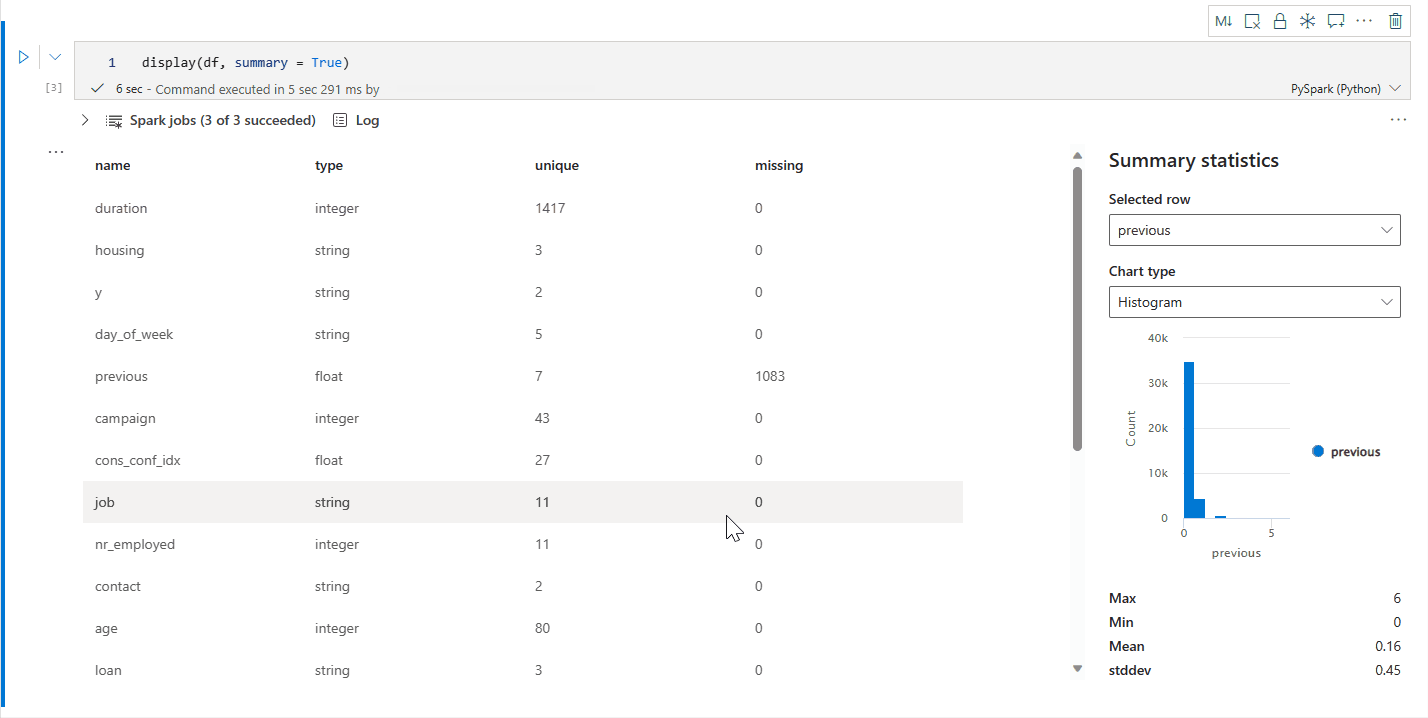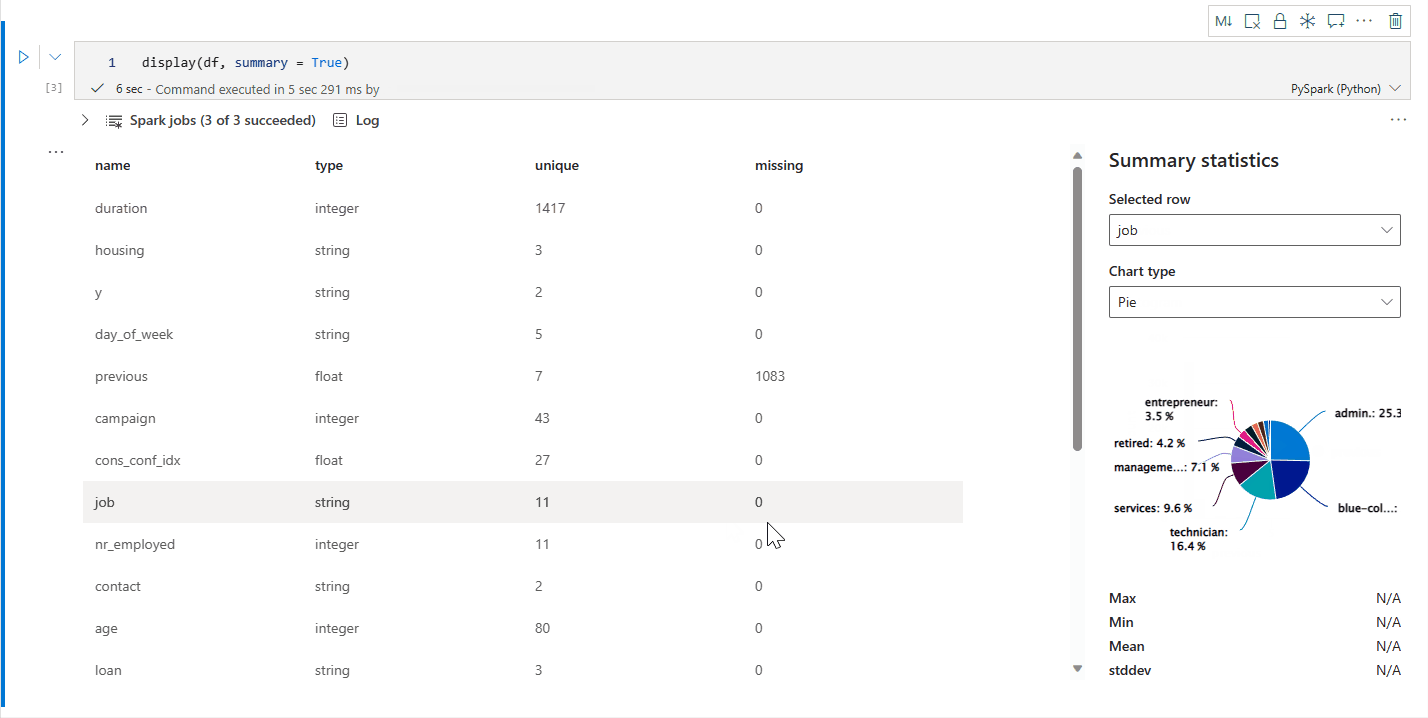
display() özet görünümü
Belirli bir Apache Spark DataFrame'in istatistik özetini denetlemek için display(df, summary = true) kullanın. Özet sütun adını, sütun türünü, benzersiz değerleri ve her sütun için eksik değerleri içerir. Ayrıca, en düşük değerini, maksimum değerini, ortalama değerini ve standart sapması görmek için belirli bir sütunu seçebilirsiniz.
displayHTML() seçeneği
Doku not defterleri, displayHTML işlevini kullanarak HTML grafiklerini destekler.
Aşağıdaki görüntü, D3.js kullanarak görselleştirme oluşturma örneğidir.

Bu görselleştirmeyi oluşturmak için aşağıdaki kodu çalıştırın.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Not defterine Power BI raporu ekleme
Önemli
Bu özellik şu anda ÖNİzLEME aşamasındadır. Bu bilgiler, Genel Kullanıma sunulmadan önce önemli ölçüde değiştirilebilecek yayın öncesi bir ürünle ilgilidir. Microsoft, burada sağlanan bilgilerle ilgili olarak açık veya zımni hiçbir garanti vermez.
Powerbiclient Python paketi artık Doku not defterlerinde yerel olarak desteklenmektedir. Doku not defteri Spark çalışma zamanı 3.4'te ek kurulum (kimlik doğrulama işlemi gibi) yapmanız gerekmez. İçeri aktarmanız powerbiclient ve keşfetmeye devam edin. powerbiclient paketini kullanma hakkında daha fazla bilgi edinmek için powerbiclient belgelerine bakın.
Powerbiclient aşağıdaki temel özellikleri destekler.
Mevcut bir Power BI raporunu işleme
Power BI raporlarını not defterlerinize yalnızca birkaç satır kodla kolayca ekleyebilir ve bunlarla etkileşim kurabilirsiniz.
Aşağıdaki görüntü, mevcut Power BI raporunu işlemeye yönelik bir örnektir.

Mevcut bir Power BI raporunu işlemek için aşağıdaki kodu çalıştırın.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Spark DataFrame'den rapor görselleri oluşturma
Hızlı bir şekilde içgörülü görselleştirmeler oluşturmak için not defterinizde bir Spark DataFrame kullanabilirsiniz. Hedef çalışma alanında rapor öğesi oluşturmak için eklenmiş raporda Kaydet'i de seçebilirsiniz.
Aşağıdaki görüntü, Spark DataFrame'den QuickVisualize() alınan bir örnektir.

Spark DataFrame'den rapor işlemek için aşağıdaki kodu çalıştırın.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Pandas DataFrame'den rapor görselleri oluşturma
Not defterindeki pandas DataFrame'i temel alan raporlar da oluşturabilirsiniz.
Aşağıdaki görüntüde pandas DataFrame'den alınan bir QuickVisualize() örnek verilmiştir.

Spark DataFrame'den rapor işlemek için aşağıdaki kodu çalıştırın.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Popüler kitaplıklar
Veri görselleştirme söz konusu olduğunda, Python birçok farklı özellik içeren birden çok grafik kitaplığı sunar. Varsayılan olarak, Doku'daki her Apache Spark havuzu bir dizi seçilmiş ve popüler açık kaynak kitaplık içerir.
Matplotlib
Her kitaplık için yerleşik işleme işlevlerini kullanarak Matplotlib gibi standart çizim kitaplıklarını işleyebilirsiniz.
Aşağıdaki görüntüde Matplotlib kullanarak çubuk grafik oluşturma örneği verilmiştir.


Bu çubuk grafiği çizmek için aşağıdaki örnek kodu çalıştırın.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
displayHTML(df) kullanarak bokeh gibi HTML veya etkileşimli kitaplıkları işleyebilirsiniz.
Aşağıdaki görüntüde bokeh kullanarak harita üzerinde glif çizme örneği verilmiştir.

Bu görüntüyü çizmek için aşağıdaki örnek kodu çalıştırın.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
displayHTML() kullanarak Plotly gibi HTML veya etkileşimli kitaplıkları işleyebilirsiniz.
Bu görüntüyü çizmek için aşağıdaki örnek kodu çalıştırın.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandalar
Pandas DataFrames'in HTML çıkışını varsayılan çıkış olarak görüntüleyebilirsiniz. Doku not defterleri stillenmiş HTML içeriğini otomatik olarak gösterir.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df