AI/ML Sistemlerinde Tehdit Modelleme ve Bağımlılıklar
Andrew Marshall, Jugal Parikh, Emre Kiciman ve Ram Shankar Siva Kumar
Raul Rojas ve AETHER Security Engineering Workstream'e Teşekkürler
2019 Kasım
Bu belge AI için AETHER Engineering Practices Çalışma Grubu'nun bir çalışmasıdır ve AI ile Makine Öğrenmesi alanına özgü tehdit sıralama ve risk azaltma konusunda yeni yönergeler sağladığından mevcut SDL tehdit modelleme uygulamalarını tamamlar niteliktedir. Aşağıdakilerin güvenlik tasarımı incelemeleri sırasında başvuru olarak kullanılması amaçlanmıştır:
AI/ML tabanlı hizmetlerle etkileşim kuran veya onlardan bağımlılıklarını alan ürünler/hizmetler
Temelinde AI/ML ile oluşturulan ürünler/hizmetler
Geleneksel güvenlik tehdidi azaltma işlemleri hiç olmadığı kadar önemlidir. Güvenlik Geliştirme Yaşam Döngüsü tarafından belirlenen gereksinimler, bu kılavuzun dayandığı ürün güvenliği temelini kurma açısından çok önemlidir. Geleneksel güvenlik tehditleriyle başa çıkılamaması, hem yazılım ortamında hem de fiziksel ortamda bu belgenin kapsamına alınan AI/ML'ye özgü saldırıların yapılmasına yardımcı olur, ayrıca yazılım yığınının alt katmanlarına indikçe tavizleri gereksiz hale getirir. Bu alandaki yeni güvenlik tehditlerine giriş bilgileri için bkz. Microsoft'ta AI ve ML'nin Geleceğini Güvence Altına Alma.
Güvenlik mühendisleriyle veri bilimcilerinin beceri kümeleri genellikle kesişmez. Bu kılavuzda, güvenlik mühendislerinin veri bilimcisi veya veri bilimcilerinin güvenlik mühendisi olması gerekmeden bu iki disiplinin bu yeni tehditler/tehditleri azaltmaları konusunda yapılandırılmış konuşmalar yapabilmesi sağlanır.
Bu belge iki bölüme ayrılmıştır:
- “Tehdit Modellemesiyle İlgili Önemli Yeni Düşünceler” AI/ML sistemlerinde tehdit modellemesi yaparken yeni düşünme yöntemlerine ve sorulacak yeni sorulara odaklanır. Hem veri bilimcileri hem de güvenlik mühendisleri bunu gözden geçirmelidir çünkü tehdit modellemesi tartışmalarında ve tehdit azaltma önceliklendirmesinde bu onların playbook'u olacaktır.
- “AI/ML'ye Özgü Tehditler ve Bu Tehditleri Azaltma”, belirli saldırıların ayrıntılarını ve Microsoft ürünleriyle hizmetlerini bu tehditlere karşı korumak için bugün kullanımda olan belirli azaltma adımlarını sağlar. Bu bölümde öncelikli olarak tehdit modelleme/güvenlik incelemesi işleminin sonucu olarak belirli tehdit azaltmalarını uygulaması gereken veri bilimcileri hedeflenir.
Bu kılavuz Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen ve Jeffrey Snover tarafından oluşturulan "Machine Learning'de Hata Modları" adlı Saldırgan Makine Öğrenmesi Tehdit Taksonomisi etrafında düzenlenmiştir. Bu belgede ayrıntılı olarak açıklanan güvenlik tehditlerini önceliklendirmeye yönelik olay yönetimi kılavuzu için AI/ML Tehditleri için SDL Hata Çubuğu'na bakın. Bunların hepsi, zaman içinde tehdit manzarasıyla birlikte gelişecek canlı belgelerdir.
Tehdit Modellemede Önemli Yeni Önemli Noktalar: Güven Sınırlarını görüntüleme şeklinizi değiştirme
Eğitirken kullandığınız verilerin ve veri sağlayıcısının bozulduğunu/zehirlendiğini varsayın. Anormal ve kötü amaçlı vergi girdilerini algılamayı, ayrıca aralarında ayrım yapmaya ve bunlardan kurtulmayı öğrenin
Özet
Veri depolarını ve onları barındıran sistemleri eğitme, Tehdit Modelleme kapsamınızın bir parçasıdır. Bugün makine öğrenmesinde en büyük güvenlik tehdidi veri zehirlenmesidir. Bunun nedeni bu alanda standart algılamaların ve tehdit azaltmalarının olmamasıdır ve buna eğitim verisi kaynakları olarak güvenilmeyen/seçilmemiş genel veri kümelerine bağımlılık da eklenir. Verilerinizin güvenilirliğinden emin olmak ve “çöp girer, çöp çıkar” eğitim döngüsünden kaçınmak için bu verilerin kaynağını ve kökenini izlemek çok önemlidir.
Güvenlik İncelemesinde Sorulacak Sorular
Verileriniz zehirlendiyse veya verilerinizin üzerinde oynandıysa bunu nasıl anlayabilirsiniz?
-Eğitim verilerinizin kalitesindeki bir sapmayı algılamak için hangi telemetriye sahipsiniz?
Kullanıcı tarafından sağlanan girişlerle mi eğitiyorsunuz?
-Bu içerik üzerinde ne tür bir giriş doğrulaması/temizlemesi yapıyorsunuz?
-Bu verilerin yapısı Veri Kümeleri için Veri Sayfaları benzeri bir şekilde belgelendi mi?
Çevrimiçi veri depolarına göre eğitiyorsanız, modelinizle veriler arasındaki bağlantının güvenliğini sağlamak için hangi önlemleri alıyorsunuz?
-Akışlarının tüketicilerine bozulmayı bildirmek için bir yolları var mı?
-Bunu yapma becerisine sahipler mi?
Eğitirken kullandığınız veriler ne kadar hassas?
-Bunları kataloğa alıyor musunuz veya veri girdilerini ekleme/güncelleştirme/silme işlemlerini denetliyor musunuz?
Modeliniz hassas veri çıkışı verebiliyor mu?
-Bu veriler kaynaktan izin alınarak mı elde edildi?
Model yalnızca hedefine ulaşmak için gereken sonuçların mı çıkışını yapıyor?
Modeliniz kaydedilebilen ve çoğaltılabilen ham güvenilirlik puanları veya başka herhangi bir doğrudan çıkış döndürüyor mu?
Eğitim verilerinin modelinize yapılan saldırıdan/modelinizin ters çevrilmesinden kurtarılmasının etkisi ne olur?
Model çıkışınızın güvenilirlik düzeyleri aniden düşerse, bunun nasıl/neden olduğunu ve ayrıca buna yol açan verileri bulabilir misiniz?
Modeliniz için iyi biçimlendirilmiş bir girişi nasıl tanımladınız? Girişlerin bu biçime uyması için ne yapıyorsunuz ve bu biçime uymazsa ne yapıyorsunuz?
Çıkışlarınız yanlışsa ama bildirilecek hatalara neden olmuyorsa, bunu nasıl anlarsınız?
Eğitim algoritmalarınızın matematiksel düzeyde saldırgan girişlere dayanıklı olup olmadığını biliyor musunuz?
Eğitim verilerinizin saldırgan kirlenmesinden nasıl kurtulursunuz?
-Saldırgan içeriği yalıtabilir/karantinaya alabilir ve etkilenen modelleri yeniden eğitebilir misiniz?
-Yeniden eğitmek üzere modelin önceki bir sürümüne dönebilir/kurtarabilir misiniz?
Seçilip düzenlenmemiş genel içerik üzerinde Pekiştirmeye Dayalı Öğrenme kullanıyor musunuz?
Verilerinizin kökenini düşünmeye başlayın; bir sorun buldunuz mu, bu verileri veri kümesine giriş noktalarına kadar izleyebildiniz mi? Yapamadıysanız, bu sorun yaratıyor mu?
Eğitim verilerinizin nereden geldiğini bilin ve anormalliklerin neye benzediğini anlamaya başlamak için istatistiksel normları belirleyin
-Eğitim verilerinizin hangi öğeleri dış etkiye açıktır?
-Eğitimde kullandığınız veri kümelerine kimler katkıda bulunabilir?
-Bir rakibe zarar vermek için eğitim verilerinizin kaynaklarına siz nasıl saldırabilirsiniz?
Bu Belgedeki İlgili Tehditler ve Tehdit Azaltmaları
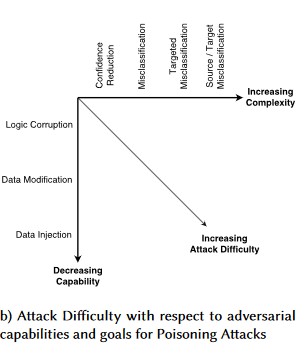
Saldırgan Pertürbasyon (tüm çeşitler)
Veri Zehirleme (tüm çeşitler)
Örnek Saldırılar
Zararsız e-postaları istenmeyen posta olarak sınıflandırmaya zorlama veya kötü amaçlı bir örneğin algılanmadan geçmesine neden olma
Özellikle yüksek sonuçlu senaryolarda saldırgan tarafından hazırlanan ve doğru sınıflandırmanın güvenilirlik düzeyini düşüren girişler
Saldırgan gelecekte kullanılacak olan doğru sınıflandırma olasılığını düşürmek için sınıflandırılmakta olan kaynak verilere rastgele kirlilik ekleyerek modelin düzeyini etkili bir şekilde düşürür
Belirli veri noktalarını yanlış sınıflandırılmaya zorlamak için eğitim verilerini kirletme ve bunun sonucunda sistem tarafından belirli eylemlerin yapılması veya atlanmasına yol açma
Modellerinizin veya ürününüzün/hizmetinizin gerçekleştirebileceği ve müşteriye çevrimiçi veya fiziksel ortamda zarar verebilecek eylemleri belirleme
Özet
AI/ML sistemlerine yönelik saldırılar azaltılmadan bırakıldığında, fiziksel dünyaya geçecek bir yol bulabilir. Kullanıcılara psikolojik veya fiziksel zarar vermek için çarpıtılabilecek her senaryo ürününüz/hizmetiniz için çok yıkıcı bir risktir. Bu eğitim ve tasarım seçimleri için kullanılan ve bu özel veri noktalarını sızdırabilecek müşterileriniz hakkındaki tüm hassas verileri kapsar.
Güvenlik İncelemesinde Sorulacak Sorular
Saldırgan örneklerle eğitiyor musunuz? Fiziksel ortamda bunlar modelinizin çıkışını nasıl etkiliyor?
Ürününüzde/hizmetinizde trolleme neye benziyor? Bunu nasıl algılayabilir ve yanıtlayabilirsiniz?
Modelinizde, hizmetinizi kandırıp geçerli kullanıcıların erişimini reddetmesini sağlayacak bir sonuç döndürmek için ne yapılabilir?
Modelinizin kopyalanmasının/çalınmasının nasıl bir etkisi olur?
Modeliniz kullanılarak belirli bir gruptaki bir bireyin üyeliği belirlenebilir mi yoksa modeliniz yalnızca eğitim verilerinde mi kullanılabilir?
Bir saldırgan ürününüzü belirli eylemleri gerçekleştirmeye zorlayarak ürünün saygınlığına zarar verebilir veya halkla ilişkilerde olumsuz tepkiye neden olabilir mi?
Trollerden gelen veriler gibi düzgün biçimlendirilmiş ama açıkça taraflı verileri nasıl işlersiniz?
Modelinizle etkileşim kurmanın veya modelinizi sorgulamanın açığa çıkan her yöntemi için, söz konusu yöntem eğitim verilerini veya model işlevselliğini açığa çıkarmak üzere sorgulanabilir mi?
Bu Belgedeki İlgili Tehditler ve Tehdit Azaltmaları
Üyelik Çıkarımı
Modeli Ters Çevirme
Model Hırsızlığı
Örnek Saldırılar
En yüksek güvenilirlik sonuçları için modeli tekrar tekrar sorgulayarak eğitim verilerini yeniden oluşturma ve ayıklama
Kapsamlı sorgu/yanıt eşleştirmesiyle modelin kendisini çoğaltma
Belirli bir gizli veri öğesinin eğitim kümesine dahil edildiğini ortaya çıkaracak şekilde modeli sorgulama
Kendi kendine giden bir arabayı dur işaretlerini/trafik ışıklarını yoksayması için kandırma
Konuşma botlarını zararsız kullanıcıları trollemek için yönlendirme
Veri/model tedarik zincirinizde AI/ML bağımlılıklarının tüm kaynaklarını ve ayrıca ön uç sunum katmanlarını belirleme
Özet
AI ve Makine Öğrenmesinde saldırıların birçoğu, modele sorgu erişimi sağlamak için yüzeye çıkarılan API'lere geçerli erişimle başlar. Burada mevcut olan zengin veri kaynaklarından ve zengin kullanıcı deneyimlerinden dolayı, modellerinize kimliği doğrulanmış ama “uygunsuz” (burada gri bir alan söz konusudur) üçüncütaraf erişimi bir risk oluşturur çünkü Microsoft tarafından sağlanan hizmetin üzerinde bir sunum katmanı işlevi görebilir.
Güvenlik İncelemesinde Sorulacak Sorular
Hangi müşterilerin/iş ortaklarının modelinize veya hizmet API'lerinize erişim için kimliği doğrulanmıştır?
-Bunlar hizmetinizin üzerinde bir sunum katmanı işlevi görebilir mi?
-Güvenliğin aşılması durumunda erişimlerini hemen iptal edebilir misiniz?
-Hizmetinizin veya bağımlılıklarınızın kötü amaçlı kullanımı durumunda kurtarma stratejiniz nedir?
Bir üçüncütaraf modelinizin amacını yeniden belirlemek ve Microsoft'a veya müşterilerine zarar vermek için model çevresinde bir maskeleme oluşturabilir mi?
Müşteriler size doğrudan eğitim verileri sağlıyor mu?
-Bu verilerin güvenliğini nasıl sağlıyorsunuz?
-Bu veriler kötü amaçlıysa ve hizmetinizi hedefliyorsa ne yapılabilir?
Burada hatalı pozitif neye benzer? Hatalı negatifin etkisi nedir?
Birden çok model arasında Gerçek Pozitif ile Hatalı Pozitif oranlarının sapmasını izleyebiliyor ve ölçebiliyor musunuz?
Müşterilerinize model çıkışınızın güvenilirliğini kanıtlamak için ne tür bir telemetriye ihtiyacınız var?
ML/Eğitim verileri tedarik zincirinizdeki tüm üçüncü taraf bağımlılıklarını belirleyin (yalnızca açık kaynak yazılımlarını değil veri sağlayıcılarını da)
-Bunları neden kullanıyorsunuz ve güvenilirliklerini nasıl doğruluyorsunuz?
Üçüncütarafların önceden oluşturulmuş modellerini kullanıyor veya üçüncü taraf MLaaS sağlayıcılarına eğitim verileri gönderiyor musunuz?
Benzer ürünler/hizmetlerde görülen hatalar hakkındaki haberlerin envanterini çıkarın. Birçok AI/ML tehdidinin model türleri arasında aktarıldığını bildiğinize göre, bu saldırılar sizin kendi ürünlerinizi nasıl etkiler?
Bu Belgedeki İlgili Tehditler ve Tehdit Azaltmaları
Sinir Ağı Yeniden Programlama
Fiziksel ortamdaki saldırgan örnekler
Eğitim Verilerini Kurtaran Kötü Amaçlı ML Sağlayıcıları
ML Tedarik Zincirine Saldırma
Arka Kapı Modeli
Güvenliği aşılan ML'ye özgü bağımlılıklar
Örnek Saldırılar
Kötü amaçlı MLaaS sağlayıcısı belirli bir atlamayla modelinize truva atları ekliyor
Saldırgan müşteri kullandığınız ortak OSS bağımlılığında güvenlik açığı buluyor, hizmetinizin güvenliğini aşmak için hazırlanmış eğitim verileri yükünü karşıya yüklüyor
Ahlaksız iş ortağı yüz tanıma API'lerini kullanıyor ve Derin Sahtelik üretmek için hizmetinizin üzerinde bir sunum katmanı oluşturuyor.
AI/ML'ye Özgü Tehditler ve Tehditlerin Azaltmaları
#1: Saldırgan Pertürbasyon
Açıklama
Pertürbasyon stili saldırılarda, saldırgan üretime dağıtılmış bir modelden istediği yanıtı almak için sorguyu gizlice değiştirir[1]. Bu, sonucun her zaman erişim ihlali veya EOP olmayabildiği ama bunun yerine modelin sınıflandırma performansının bozulduğu fuzzing stili saldırılara yol açan bir model giriş bütünlüğü ihlalidir. Ayrıca belirli hedef sözcükleri AI'nin yasaklamasına yol açacak şekilde kullanan, bu yolla adı "yasaklanmış" sözcükle eşlenen geçerli kullanıcılara hizmet reddine neden olan troller tarafından da bildirilebilir.
 [24]
[24]
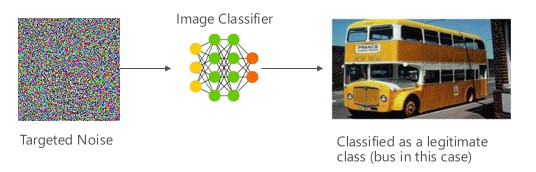
Değişken #1a: Hedeflenen yanlış sınıflandırma
Bu örnekte saldırganlar hedef sınıflandırıcının giriş sınıfında yer almayan ama model tarafından bu giriş sınıfında olacak şekilde sınıflandırılan bir örnek üretir. Saldırgan örnek insanlara rastgele bir kirlilik olarak görünebilir ama saldırganların hedef makine öğrenmesi sistemi konusunda biraz bilgileri vardır ve aslında rastgele olmayan, bunun yerine hedef modelin belirli yönlerini kötüye kullanan bir beyaz kirlilik oluşturabilirler. Saldırgan meşru bir örnek olmayan bir giriş örneği verir ama hedef sistem bunu meşru bir sınıf olarak sınıflandırır.
Örnekler
 [6]
[6]
Risk Azaltıcı Etkenler
Saldırgan Eğitim tarafından oluşturulan Model Güvenilirliğini Kullanarak Saldırgan Sağlamlığı Pekiştirme [19]: Yazarlar, temel modelin saldırgan sağlamlığını pekiştirmek için güvenilirlik bilgilerini ve en yakın komşu aramasını birleştiren bir çerçeve olan Son Derece Güvenilir Yakın Komşu (HCNN) önerisinde bulunur. Bu, temel eğitim dağıtımından alınan bir örnek noktanın yakınlarındaki doğru ve yanlış model tahminlerini ayırt etmeye yardımcı olabilir.
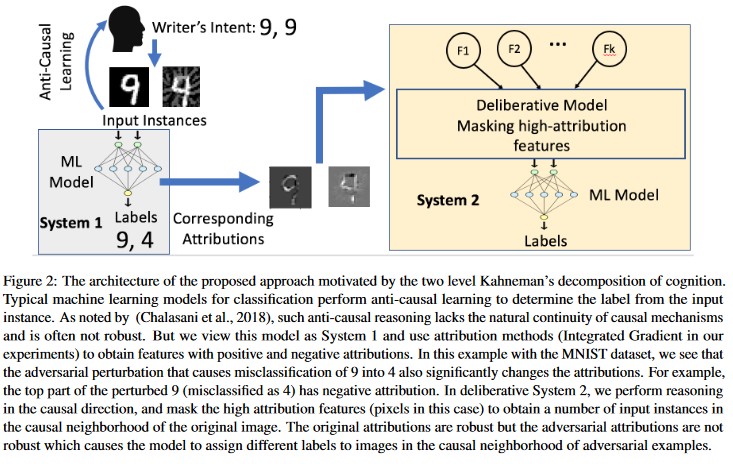
Atf temelli Nedensel Analiz [20]: Yazarlar saldırgan pertürbasyonlara dayanıklılık ile makine öğrenmesi modelleri tarafından oluşturulan bireysel kararların atıf tabanlı açıklaması arasındaki bağlantıyı inceler. Saldırgan girişlerin ilişkilendirme alanında güçlü olmadığını, saldırgan örneklerde yüksek ilişkilendirmeye sahip birkaç özelliğin maskelenmesinin makine öğrenmesi modelinde kararsızlığı değiştirmeye yol açtığını bildiriyorlar. Buna karşılık doğal girişler ilişkilendirme alanında güçlüler.
 [20]
[20]
Bu yaklaşımlar makine öğrenmesi modellerini saldırgan saldırılara karşı daha dayanıklı yapıyor çünkü bu iki katmanlı bilişsel sistemin kandırılması için özgün modele saldırmak yeterli olmuyor, ayrıca saldırgan örnek için oluşturulan ilişkilendirmenin de özgün örneklere benzer olması gerekiyor. Başarılı bir saldırgan saldırı için her iki sistemin güvenliğinin de eşzamanlı olarak aşılması gerekiyor.
Geleneksel Paralelleri
Artık modeliniz saldırganın denetiminde olduğundan Uzaktan Ayrıcalık Yükseltme
Önem
Kritik
Değişken #1b: Kaynak/Hedef yanlış sınıflandırması
Bunun özelliği, saldırgan tarafından modelin verili bir giriş için istediği etikete dönmesini sağlama girişimidir. Genellikle modeli bir yanlış pozitif veya yanlış negatif döndürmeye zorlar. Sonuçta modelin sınıflandırma doğruluğu ustalıklı bir şekilde ele geçirilmiş olur ve saldırgan istediği belirli atlamaları tetikleyebilir.
Bu saldırının sınıflandırma doğruluğu üzerinde önemli derecede zararlı bir etkisi olsa da, bir saldırganın yalnızca kaynak verileri artık doğru işaretlenmeyecek şekilde manipüle etmesi değil aynı zamanda istenen sahte etiketle özel olarak etiketlemesi de gerektiğinden, bunu yürütmek de daha fazla zaman gerektirebilir. Bu saldırılar genellikle yanlış sınıflandırmayı zorlamak için birden çok adım/girişim içerir [3]. Model hedefli yanlış sınıflandırmanın zorlandığı öğrenme aktarımı hatalarına yatkınsa, yoklama saldırıları çevrimdışı yapılabileceğinden fark edilebilir bir saldırgan trafiği ayak izi bulunmayabilir.
Örnekler
Zararsız e-postaları istenmeyen posta olarak sınıflandırmaya zorlama veya kötü amaçlı bir örneğin algılanmadan geçmesine neden olma. Bunlar model atlatma veya taklit saldırıları olarak da bilinir.
Risk Azaltıcı Etkenler
Tepkiye/Savunmaya Yönelik Algılama Eylemleri
- Sınıflandırma sonuçlarını sağlayan API'ye yönelik çağrılar arasında minimum bir süre eşiği uygulayın. Bu uygulama başarılı bir pertürbasyon bulmak için gereken toplam süreyi artırarak çok adımlı saldırı testini yavaşlatır.
Proaktif/Korumaya Yönelik Eylemler
Saldırgan Sağlamlığı Geliştirmek için Özellik Gösterimi [22]: Yazarlar, özellik gösterimini gerçekleştirerek saldırgan sağlamlığı artıran yeni bir ağ mimarisi geliştirmektedir. Özel olarak ağlar yerel olmayan yollar veya başka filtreler kullanarak özelliklerin kirliliğini gideren bloklar içeriyor; ağın tamamı uçtan uca eğitiliyor. Saldırgan eğitimle birleştirildiğinde, özellik kirliliğini giderme ağları hem beyaz kutu hem de kara kutu saldırı ayarlarında son derece gelişmiş saldırgan sağlamlığı ciddi ölçüde geliştiriyor.
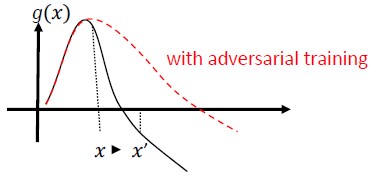
Saldırgan Eğitim ve Düzenlileştirme: Kötü amaçlı girişlere karşı dayanıklılık ve sağlamlık oluşturmak için bilinen saldırgan örneklerle eğitin. Bu, aşamalı giriş değişimleri normunu cezalandıran ve sınıflandırıcının tahmin işlevini daha düzenli hale getiren (giriş marjını yükselterek) bir regülasyon biçimi olarak da görülebilir. Düşük güvenilirlik oranlarıyla doğru sınıflandırmalar içeriyor.
Monoton özelliklerin seçilmesiyle monoton bir sınıflandırma geliştirmeye yatırım yapın. Bu sayede saldırgan yalnızca negatif sınıftan özellikleri doldurarak sınıflandırıcıyı atlatamayacaktır [13].
Özellik sıkıştırma [18], saldırgan örnekleri algılayarak DNN modellerini sağlamlaştırmak için kullanılabilir. Özgün alandaki birçok farklı özellik vektörüne karşılık gelen örnekleri tek örnekte birleştirerek saldırganın kullanabildiği arama alanını küçültür. Özellik sıkıştırma DNN modelinin özgün giriş üzerindeki tahminini sıkıştırılmış giriş tahminiyle karşılaştırarak, saldırgan örnekleri algılamaya yardımcı olabilir. Özgün ve sıkıştırılan örnekler modelden önemli ölçüde farklı çıkışlar üretirse, giriş büyük olasılıkla saldırgan olacaktır. Tahminler arasındaki anlaşmazlığı ölçerek ve bir eşik değeri seçerek, sistem meşru örnekler için doğru tahmini çıkarabilir ve saldırgan girişleri reddedebilir.

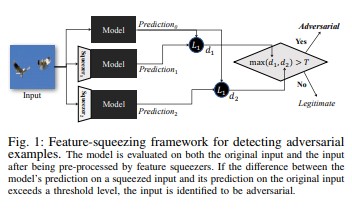 [18]
[18]Saldırgan Örneklere Karşı Sertifikalı Savunmalar [22]: Yazarlar, belirli bir ağ ve test girişi için hiçbir saldırının hatayı belirli bir değeri aşmaya zorlayabileceği bir sertifika veren yarı kesin gevşemeyi temel alan bir yöntem önerir. İkincisi, bu sertifika farklılaştırılabildiğinden yazarlar bunu ağ parametreleriyle birlikte iyileştirebiliyor ve bu yolla tüm saldırılara karşı uyarlamalı bir düzenleyici sağlanıyor.
Yanıt Eylemleri
- Özellikle tek bir kullanıcıdan veya küçük bir kullanıcı grubundan geliyorsa, sınıflandırıcılar arasında yüksek farkın söz konusu olduğu sınıflandırma sonuçlarında uyarı gönderme.
Geleneksel Paralelleri
Uzaktan Ayrıcalık Yükseltme
Önem
Kritik
Değişken #1c: Rastgele yanlış sınıflandırma
Bu saldırganın hedef sınıflandırmasının geçerli kaynak sınıflandırması dışında herhangi bir şey olabildiği, özel bir çeşitlemedir. Saldırı genellikle gelecekte doğru sınıflandırma kullanılabilmesi olasılığını düşürmek için sınıflandırılmakta olan kaynak verilere rastgele kirlilik eklemeyi içerir [3].
Örnekler
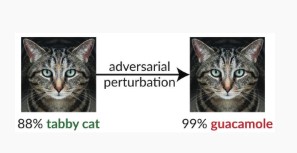
Risk Azaltıcı Etkenler
Çeşitleme 1a ile aynı.
Geleneksel Paralelleri
Kalıcı olmayan hizmet reddi
Önem
Önemli
Değişken #1d: Güvenilirlik Azaltma
Özellikle yüksek sonuçlu senaryolarda saldırgan doğru sınıflandırmanın güvenilirlik düzeyini düşüren girişler hazırlayabilir. Bu, yöneticileri veya izleme sistemlerini geçerli uyarılardan ayırt edilemeyen sahte uyarılarla bunaltmayı amaçlayan çok büyük sayılarda hatalı pozitif biçimini de alabilir [3].
Örnekler

Risk Azaltıcı Etkenler
- Variant #1a kapsamındaki eylemlere ek olarak, tek bir kaynaktan gelen uyarı hacmini azaltmak için olay azaltma kullanılabilir.
Geleneksel Paralelleri
Kalıcı olmayan hizmet reddi
Önem
Önemli
hedeflenen veri zehirleme #2a
Açıklama
Saldırganın hedefi, eğitim aşamasında oluşturulan makine modeline virüs bulaştırmaktır, böylece yeni verilerle ilgili tahminler test aşamasında değiştirilmiş olur[1]. Hedefli zehirleme saldırılarında, saldırgan belirli eylemlerin yapılmasına veya atlanmasına neden olacak belirli örnekleri yanlış sınıflandırmak ister.
Örnekler
Hedeflenen AV yazılımının hatalı biçimde kötü amaçlı olarak sınıflandırılmasını sağlamak ve istemci sistemlerinde kullanımını engellemek için AV yazılımını kötü amaçlı yazılım olarak gönderme.
Risk Azaltıcı Etkenler
Gündelik veri dağılımına bakmak ve çeşitlemelerde uyarı vermek için anomali algılayıcıları tanımlama
-Eğitim verileri değişikliklerini gündelik olarak ölçme, eğiklik/kayma telemetrisi
Giriş doğrulaması, hem temizleme hem de bütünlük denetimi
Zehirleme temel eğitim örnekleri ekler. Bu tehdide karşılık vermek için iki ana strateji:
-Veri temizleme/doğrulama: zehirleme örneklerini eğitim verilerinden kaldırma -Zehirleme saldırılarına karşı mücadele etmek için paketleme [14]
-Olumsuz Etki Durumunda Reddetme (RONI) savunması [15]
-Sağlam Öğrenme: Zehirlenme örnekleri varlığında sağlam olan öğrenme algoritmalarını seçin.
-Yazarların veri zehirlenmesi sorununu iki adımda ele aldığı [21] yaklaşımı anlatılmaktadır: 1) gerçek alt alanı kurtarmak için yeni bir sağlam matris faktörizasyon yöntemi tanıtmak ve 2) adımda kurtarılan temele dayalı saldırgan örnekleri ayıklamak için yeni sağlam ilke bileşen regresyonu (1). Bunlar gerçek alt alanı kurtarmak için gerekli ve yeterli koşulları temsil eder ve kesin referansla karşılaştırıldığında beklenen tahmin kaybına bağlılık gösterir.
Geleneksel Paralelleri
Saldırganın ağda kalıcı hale geldiği truva atı eklenmiş konak. Eğitim ve yapılandırma verilerinin güvenliğinin aşılması ve model oluşturma için alınıyor/güveniliyor olması.
Önem
Kritik
#2b Ayrımcı Veri Zehirleme
Açıklama
Amaç saldırılan veri kümesinin kalitesini/bütünlüğünü bozmaktır. Birçok veri kümesi genel/güvenilmez/seçilmemiş olma özelliğine sahiptir, dolayısıyla öncelikle bu tür veri bütünlüğü ihlallerini belirleme becerisi çerçevesinde ek sorunlar getirir. Güvenliğinin aşıldığı bilinmeyen verilerle eğitim vermek, bir çöp girer/çöp çıkar durumudur. Algılandıktan sonra, önceliklendirmeyle ihlal edilen verilerin kapsamının saptanması ve bunların karantinaya alınması/yeniden eğitilmesi gerekir.
Örnekler
Bir şirket, modellerini eğiteceği geleceğe dair petrol verileri için tanınmış ve güvenilir bir web sitesini kazıyor. Veri sağlayıcısının web sitesinin güvenliği daha sonra SQL Ekleme saldırısı yoluyla tehlikeye girmiş oluyor. Saldırgan istediğinde veri kümesini zehirleyebilir ve eğitilen modelin verilerin bozulmuş olduğu hakkında hiçbir fikri olmaz.
Risk Azaltıcı Etkenler
Çeşitleme 2a ile aynı.
Geleneksel Paralelleri
Yüksek değerli bir varlığa karşı kimliği doğrulanmış Hizmet reddi
Önem
Önemli
#3 Model Ters Çevirme Saldırıları
Açıklama
Makine öğrenmesi modellerinde kullanılan özel özellikler kurtarılabilir [1]. Saldırganın erişimi olmadığı özel eğitim verilerini yeniden oluşturma buna dahildir. Biyometri topluluğunda tepe tırmanma saldırıları olarak da bilinir [16, 17] Bu, döndürülen güven düzeyini en üst düzeye çıkaran, hedefle eşleşen sınıflandırmaya tabi olan girişin bulunmasıyla mümkündür [4].
Örnekler
 [4]
[4]
Risk Azaltıcı Etkenler
Hassas verilerden eğitilen modellere arabirimi oluşturmak için güçlü bir erişim denetimi gerekir.
Model tarafından izin verilen sorgulara hız sınırı getirme
Önerilen tüm sorgularda giriş doğrulaması yaparak, modelin giriş doğruluğu tanımına uymayan her şeyi reddederek ve yararlı olması için gereken en az miktarda bilgiyi döndürerek, kullanıcılarla/çağrıyı yapanlarla gerçek model arasında geçitler uygulayın.
Geleneksel Paralelleri
Hedefli, dönüştürülmüş Bilgilerin Açığa Çıkması
Önem
Standart SDL hata çubuğuna göre varsayılan olarak önemli düzeyini alır ama ayıklanan hassas veya kişisel veriler bunu kritik düzeye çıkarabilir.
#4 Üyelik Çıkarımı Saldırısı
Açıklama
Saldırgan belirli bir veri kaydının modelin eğitim veri kümesinin bir parçası olup olmadığını saptayabilir[1]. Araştırmacılar, özniteliklere (yaş, cinsiyet, hastane gibi) göre bir hastanın ana prosedürünü (örneğin: Hastanın geçtiği ameliyat) tahmin edebildi [1].
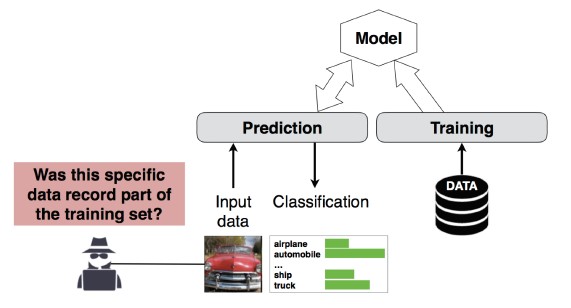 [12]
[12]
Risk Azaltıcı Etkenler
Bu saldırının yapılabilirliğini ortaya koyan araştırma raporları Değişiklik Gizliliğinin [4, 9] etkili bir tehdit azaltma yöntemi olabileceğini gösteriyor. Bu hala Microsoft'ta olgunlaşmamış bir alan ve AETHER Security Engineering bu alanda araştırmaya yatırım yaparak uzmanlık oluşturmayı öneriyor. Bu araştırma Değişiklik Gizliliği özelliklerinin listelenmesini ve pratikte tehdit azaltma açısından ne kadar etkili olduklarının değerlendirilmesini gerektirebilir. Bunun ardından bu savunmalara yönelik tasarım yolları, Visual Studio'da kod derlediğinizde size varsayılan güvenlik korumaları (geliştirici ve kullanıcılara saydam) sağlanmasına benzer biçimde çevrimiçi hizmet platformlarımızda saydam olarak devralınabilir.
Nöron bırakma ve model yığınlama kullanmak bir ölçüde etkili tehdit azaltma yöntemleri olabilir. Nöron bırakmanın kullanılması sinir ağının bu saldırıya dayanıklılığını artırmakla kalmaz, model performansını da artırır [4].
Geleneksel Paralelleri
Veri Gizliliği. Veri noktasının eğitim kümesine dahil olup olmadığı hakkında çıkarımlar yapılıyor ama asıl eğitim verileri açıklanmıyor
Önem
Bu bir güvenlik sorunu değil gizlilik sorunudur. Tehdit modelleme kılavuzunda buna değinilmesinin nedeni etki alanlarının çakışmasıdır ama burada verilecek her yanıtın Güvenlik değil Gizlilik tarafından yönlendirilmesi gerekir.
#5 Model Çalma
Açıklama
Saldırganlar temel alınan modeli meşru bir şekilde sorgulayarak bu modeli yeniden oluşturur. Yeni modelin işlevselliği, temel alınan modeldeki ile aynıdır[1]. Model yeniden oluşturulduktan sonra, özellik bilgilerini ele geçirmek veya eğitim verileri ile ilgili çıkarımlar yapmak üzere ters çevrilebilir.
Denklem çözme - API çıkışı aracılığıyla sınıf olasılıkları döndüren bir model için saldırgan, modeldeki bilinmeyen değişkenleri belirlemek üzere sorgular oluşturabilir.
Yol Bulma – Bir girişi sınıflandırırken ağaç tarafından alınan 'kararları' ayıklamak için API özelliklerinin açıklarından yararlanan bir saldırı [7].
Aktarılabilirlik saldırısı - Bir saldırgan, muhtemelen hedeflenen modele tahmin sorguları vererek, yerel bir modeli eğitebilir ve bunu kullanarak hedef modele aktarım yapan saldırı örnekleri oluşturabilir [8]. Modelinizin ayıklanması ve bir saldırı girişi türüne karşı savunmasız olduğunun keşfedilmesi durumunda, üretim ortamına dağıtılan modelinize yönelik yeni saldırılar, modelinizin bir kopyasını ayıklayan saldırgan tarafından tamamen çevrimdışı olarak geliştirilebilir.
Örnekler
Model ayıklama, bir ML modelinin istenmeyen posta, kötü amaçlı yazılım sınıflandırması ve ağ anomalisi algılama gibi saldırı davranışlarını algılamaya hizmet ettiği ayarlarda kurtulma saldırılarını kolaylaştırabilir [7].
Risk Azaltıcı Etkenler
Proaktif/Korumaya Yönelik Eylemler
Tahmin API'lerinde döndürülen ayrıntıları en aza indirirken veya örterken bir yandan da bunların "dürüst" uygulamalara yaralı olmaya devam etmesini sağlayın [7].
Model girişleriniz için doğru biçimlendirilmiş bir sorgu tanımlayın ve yalnızca tamamlanmış, doğru biçimlendirilmiş, bu biçimle eşleşen girişlere yanıt olarak sonuç döndürün.
Yuvarlanmış güvenirlik değerleri döndürün. Meşru çağrı sahiplerinin çoğuna birden çok ondalık konum duyarlığı gerekmez.
Geleneksel Paralelleri
Sistem verilerinde yapılan kimliği doğrulanmamış salt okunur değişiklikler, yüksek değerli bilgileri açığa çıkarmayı mı hedefliyor?
Önem
Güvenliğe duyarlı modellerde Önemli, diğer durumlarda Orta
#6 Sinir Ağı Yeniden Programlama
Açıklama
Bir saldırgan tarafından özel olarak hazırlanmış bir sorgu aracılığıyla Makine Öğrenmesi sistemleri, oluşturucunun asıl amacından sapan bir göreve yeniden programlanabilir [1].
Örnekler
Yüz tanıma API’si üzerinde, 3. tarafların deepfakes oluşturucu gibi Microsoft müşterilerine zarar vermek üzere tasarlanmış uygulamalara eklemesini sağlayan zayıf erişim denetimleri.
Risk Azaltıcı Etkenler
Güçlü istemci-sunucu<> karşılıklı kimlik doğrulaması ve model arabirimlerine erişim denetimi
Sorunlu hesapların kaldırılması.
API'leriniz için bir hizmet düzeyi anlaşmasını belirleme ve zorlama. Bildirilen sorun için kabul edilebilir düzeltme süresini saptama ve SLA süresi dolduktan sonra sorunun artık yeniden üretilmediğinden emin olma.
Geleneksel Paralelleri
Bu bir kötüye kullanma senaryosudur. Bu konuda bir güvenlik olayı açmaktansa doğrudan kötüye kullanan kişinin hesabını devre dışı bırakma olasılığınız daha yüksektir.
Önem
Önemli - Kritik
#7 Fiziksel etki alanındaki Saldırgan Örnek (bitler-atomlar>)
Açıklama
Saldırgan bir örnek, yalnızca makine öğrenmesi sistemini yanıltmak amacıyla gönderilen kötü amaçlı bir varlığın girişi/sorgusudur [1]
Örnekler
Dur işaretine belirli bir renkteki ışığın (saldırı girişi) yansıtılması ve görüntü tanıma sisteminin dur işaretini dur işareti olarak görmemeye zorlanması nedeniyle kendi kendine çalışan bir arabanın kandırılarak dur işaretini geçmesi gibi, bu örnekler fiziksel ortamda gerçekleşebilir.
Geleneksel Paralelleri
Ayrıcalık Yükselmesi, uzaktan kod yürütme
Risk Azaltıcı Etkenler
Bu saldırıların kendilerini göstermelerinin nedeni, makine öğrenmesi katmanında (AI yönlendirmeli karar alma katmanının altındaki veri ve algoritma katmanı) sorunların azaltılmamış olmasıdır. Diğer tüm yazılımlarda *veya* fiziksel sistemlerde olduğu gibi, hedefin altındaki katman her zaman geleneksel vektörler aracılığıyla saldırıya uğrayabilir. Bu nedenle geleneksel güvenlik uygulamaları, özellikle AI ile geleneksel yazılım arasında güvenlik açıkları azaltılmamış bir katman (veri/algoritma katmanı) kullanıldığından, her zamankinden daha önemlidir.
Önem
Kritik
#8 Eğitim verilerini kurtarabilen kötü amaçlı ML sağlayıcıları
Açıklama
Kötü amaçlı bir sağlayıcı, özel eğitim verilerinin kurtarıldığı arka kapılı bir algoritma sunar. Bunlar yalnızca modeli alarak yüzleri ve metinleri yeniden oluşturabiliyordu.
Geleneksel Paralelleri
Hedefli bilgilerin açığa çıkması
Risk Azaltıcı Etkenler
Bu saldırının yapılabilirliğini ortaya koyan araştırma raporları Benzer Yapılı Şifrelemenin etkili bir tehdit azaltma yöntemi olabileceğini gösteriyor. Bu şu anda çok az yatırım yapılan bir alan ve AETHER Security Engineering bu alanda araştırmaya yatırım yaparak uzmanlık oluşturmayı öneriyor. Bu araştırmanın Benzer Yapılı Şifreleme prensiplerini listelemesi ve kötü amaçlı Hizmet Olarak ML sağlayıcıları karşısında azaltıcı etken olarak pratik etkisini değerlendirmesi gerekebilir.
Önem
Kişisel bilgiler söz konusuysa Önemli, değilse Orta
#9 ML Tedarik Zincirine Saldırma
Açıklama
Algoritmaları eğitmek için gereken büyük kaynaklar (veri + hesaplama) nedeniyle, geçerli uygulama büyük şirketler tarafından eğitilen modelleri yeniden kullanmak ve eldeki görev için biraz değiştirmektir (örneğin: ResNet, Microsoft'un popüler bir görüntü tanıma modelidir). Bu modeller, Model Zoo’da seçki olarak sunulur (Caffe popüler görüntü tanıma modellerini barındırır). Bu saldırıda, saldırgan Caffe'de barındırılan modellere saldırır ve böylece veriler herkes için bozulur. [1]
Geleneksel Paralelleri
Güvenlik dışı üçüncü taraf bağımlılığı güvenliğinin aşılması
Uygulama mağazasının kötü amaçlı yazılım barındırdığının bilinmesi
Risk Azaltıcı Etkenler
Modeller ve veriler için mümkün olduğunca üçüncü taraf bağımlılıklarını en aza indirin.
Bu bağımlılıkları tehdit modelleme sürecinizle birleştirin.
Birinciveüçüncü taraf sistemleri arasında güçlü kimlik doğrulamasından, erişim denetiminden ve şifrelemeden yararlanın.
Önem
Kritik
#10 Arka Kapı Makine Öğrenmesi
Açıklama
Eğitim işleminde kötü amaçlı bir üçüncü taraf dış kaynak olarak kullanılır. Bu üçüncü taraf eğitim verilerinin üzerinde oynar ve hedeflenen yanlış sınıflandırmaları (belirli bir virüsü kötü amaçlı değil olarak sınıflandırma gibi) zorlayan bir truva atı modeli teslim eder[1]. Bu, Hizmet Olarak ML model oluşturma senaryolarının bir riskidir.
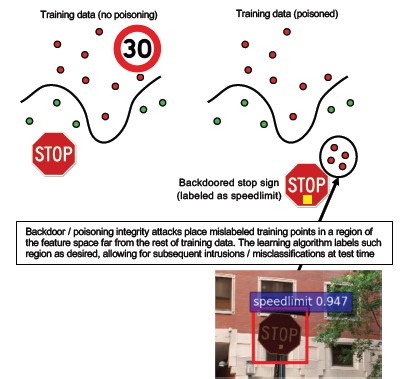 [12]
[12]
Geleneksel Paralelleri
Güvenlikle ilgili üçüncü taraf bağımlılığı güvenliğinin aşılması
Güvenliği Aşılmış Yazılım Güncelleştirme mekanizması
Sertifika Yetkilisinin güvenliğini aşma
Risk Azaltıcı Etkenler
Tepkiye/Savunmaya Yönelik Algılama Eylemleri
- Bu tehdit keşfedildiğinde zaten iş işten geçmiştir, dolayısıyla kötü amaçlı sağlayıcı tarafından sunulan modele ve eğitim verilerine güvenilemez.
Proaktif/Korumaya Yönelik Eylemler
Tüm hassas modelleri şirket içinde eğitme
Eğitim verilerini kataloglayarak bunların güçlü güvenlik uygulamalarına sahip güvenilen bir üçüncü taraftan geldiğinden emin olma
MLaaS sağlayıcısı ile kendi sistemleriniz arasındaki etkileşimde tehdidi modelleme
Yanıt Eylemleri
- Dış bağımlılığın güvenliğinin aşılmasıyla aynı
Önem
Kritik
#11 ML sisteminin yazılım bağımlılıklarından yararlanma
Açıklama
Bu saldırıda saldırgan algoritmaları manipüle ETMEZ. Bunun yerine arabellek taşmaları veya siteler arası betik gibi yazılımdaki güvenlik açıklarından yararlanır[1]. AI/ML'nin altındaki yazılım katmanlarının güvenliğini aşmak, hala doğrudan öğrenme katmanına saldırmaktan daha kolaydır, bu nedenle Güvenlik Geliştirme Yaşam Döngüsü altında ayrıntıları verilen geleneksel güvenlik tehdidi azaltma uygulamaları çok önemlidir.
Geleneksel Paralelleri
Güvenliği Aşılmış Açık Kaynak Yazılım Bağımlılığı
Web sunucusu güvenlik açığı (XSS, CSRF, API girişi doğrulama hatası)
Risk Azaltıcı Etkenler
Uygun Güvenlik Geliştirme Yaşam Döngüsü/Operasyonel Güvenlik Güvencesi en iyi yöntemlerini izlemek için güvenlik ekibinizle birlikte çalışın.
Önem
Değişken; Geleneksel yazılım güvenlik açığının türüne bağlı olarak Kritik düzeye kadar çıkabilir.
Kaynakça
[1] Makine Öğrenmesinde Hata Modları, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen ve Jeffrey Snover, https://video2.skills-academy.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Derin Öğrenmede Saldırgan Örnekler: Karakterizasyon ve Ayrışma, Wei, ve diğerleri, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Makine Öğrenmesi Modellerinde Model ve VeriDen Bağımsız Üyelik Çıkarımı Saldırıları ve Savunmaları, Salem, vb. https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha ve T. Ristenpart, “Güvenilirlik Bilgilerini Kötüye Kullanan Model Tersine Çevirme Saldırıları ve Temel Önlemler,” 2015 ACM SIGSAC Bilgisayar ve İletişim Güvenliği (CCS) Konferansı Toplantı Tutanakları.
[6] Nicolas Papernot ve Patrick McDaniel- Makine Öğrenmesinde Saldırgan Örnekler AIWTB 2017
[7] Tahmin API'leri Aracılığıyla Makine Öğrenmesi Modellerini Çalma, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell Üniversitesi; Ari Juels, Cornell Tech; Michael K. Reiter, North Carolina Chapel Hill Üniversitesi; Thomas Ristenpart, Cornell Tech
[8] Aktarılabilir Saldırgan Örnekler Alanı, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh ve Patrick McDaniel
[9] İyi Oluşturulmuş Öğrenme Modellerinde Üyelik Çıkarımlarını Anlama Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 ve Kai Chen3,4
[10] Simon-Gabriel ve diğer yazarlar, Sinir ağlarının saldırgan güvenlik açığı giriş boyutuyla birlikte artıyor, ArXiv 2018;
[11] Lyu ve diğer yazarlar, Saldırgan örnekler için birleşik aşamalı regülasyon ailesi, ICDM 2015
[12] Vahşi Desenler: Saldırgan Makine Öğrenmesinin Yükselişinin Ardından On Yıl - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Monoton Sınıflandırma Kullanılarak Saldırgan Olarak Sağlam Kötü Amaçlı Yazılım Algılama Inigo Incer ve diğer yazarlar
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto ve Fabio Roli. Saldırgan Sınıflandırma Görevlerinde Zehirleme Saldırılarına Karşı Mücadele Etmek için Sınıflandırıcıları Paketleme
[15] Olumsuz Etki Savunması Hongjiang Li ve Patrick P.K. Chan'da Geliştirilmiş Reddetme
[16] Adler. Biyometrik şifreleme sistemlerinin güvenlik açıkları. 5. Uluslararası Konferans AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Tepe tırmanma saldırılarında yüz doğrulama sistemlerinin güvenlik açığı üzerine. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Özellik Sıkıştırma: Derin Sinir Ağlarında Saldırgan Örnekleri Algılama. 2018 Ağ ve Dağıtılmış Sistem Güvenliği Sempozyumu. 18-21 Şubat.
[19] Saldırgan Eğitim Tarafından Tetiklenen Model Güvenilirliğini Kullanarak Saldırgan Sağlamlığı Pekiştirme - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Saldırgan Örneklerin Saptanması için İlişkilendirme ile Yönlendirilen Nedensel Analiz, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Eğitim Verileri Zehirlenmesine Karşı Sağlam Lineer Regresyon – Chang Liu ve diğer yazarlar
[22] Saldırgan Sağlamlığı Geliştirmek için Özellik Kirliliğini Giderme, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Saldırgan Örneklere Karşı Onaylı Savunmalar - Aditi Raghunathan, Jacob Steinhardt, Percy Liang