创建 AI 代理及其工具
重要
此功能目前以公共预览版提供。
本文介绍了如何使用 Mosaic AI 代理框架创建 AI 代理和工具。
了解如何使用 AI 操场快速制作工具调用代理的原型,并将其导出到 Mosaic AI 代理框架。
要求
- 了解什么是复合 AI 系统和 AI 代理?中所述的 AI 代理和工具的概念
- Databricks 建议在开发代理时安装最新版本的 MLflow Python 客户端。 有关
mlflow版本要求的信息,请参阅相关资源的身份验证。
创建 AI 代理工具
AI 代理使用工具来执行语言生成以外的操作,例如检索结构化或非结构化数据、执行代码或与远程服务对话(例如发送电子邮件或 Slack 消息)。
若要使用 Mosaic AI 代理框架向代理提供工具,可以使用以下方法的任意组合:
- 创建或使用现有的 Unity Catalog 函数作为工具,从而轻松发现、治理和共享工具。
- 在本地将工具定义为代理代码中的 Python 函数。
无论代理是用自定义 Python 代码编写的还是使用 LangGraph 等代理创作库,这两种方法都起作用。
定义工具时,请确保工具、其参数及其返回值都有详细的文档记录,以便代理 LLM 能够了解何时以及如何使用该工具。
使用 Unity Catalog 函数创建代理工具
这些示例使用在笔记本环境或 SQL 编辑器中编写的 Unity Catalog 函数创建 AI 代理工具。
在笔记本单元格中运行以下代码。 它使用 %sql 笔记本 magic 创建一个名为 python_exec 的 Unity Catalog 函数。
LLM 可以使用此工具执行用户提供的 Python 代码。
%sql
CREATE OR REPLACE FUNCTION
main.default.python_exec (
code STRING COMMENT 'Python code to execute. Remember to print the final result to stdout.'
)
RETURNS STRING
LANGUAGE PYTHON
DETERMINISTIC
COMMENT 'Executes Python code in the sandboxed environment and returns its stdout. The runtime is stateless and you can not read output of the previous tool executions. i.e. No such variables "rows", "observation" defined. Calling another tool inside a Python code is NOT allowed. Use standard python libraries only.'
AS $$
import sys
from io import StringIO
sys_stdout = sys.stdout
redirected_output = StringIO()
sys.stdout = redirected_output
exec(code)
sys.stdout = sys_stdout
return redirected_output.getvalue()
$$
在 SQL 编辑器中运行以下代码。
它创建一个名为 lookup_customer_info 的 Unity Catalog 函数,LLM 可以使用它来从假设 customer_data 表中检索结构化数据:
CREATE OR REPLACE FUNCTION main.default.lookup_customer_info(
customer_name STRING COMMENT 'Name of the customer whose info to look up'
)
RETURNS STRING
COMMENT 'Returns metadata about a particular customer given the customer name, including the customer email and ID. The
customer ID can be used for other queries.'
RETURN SELECT CONCAT(
'Customer ID: ', customer_id, ', ',
'Customer Email: ', customer_email
)
FROM main.default.customer_data
WHERE customer_name = customer_name
LIMIT 1;
在 AI 操场中制作工具调用代理的原型
创建 Unity Catalog 函数后,可以使用 AI 操场将其提供给 LLM 并测试代理。 AI 操场提供了一个沙盒用于制作工具调用代理的原型。
对 AI 代理感到满意后,可以将其导出以在 Python 中进一步开发它,或者按原样将其作为模型服务端点部署。
注意
Unity Catalog、无服务器计算、Mosaic AI 代理框架以及按令牌付费的基础模型或外部模型必须在当前工作区中可用,才能在 AI 操场中制作代理的原型。
制作工具调用终结点的原型。
在操场中,选择具有“函数调用”标签的模型。
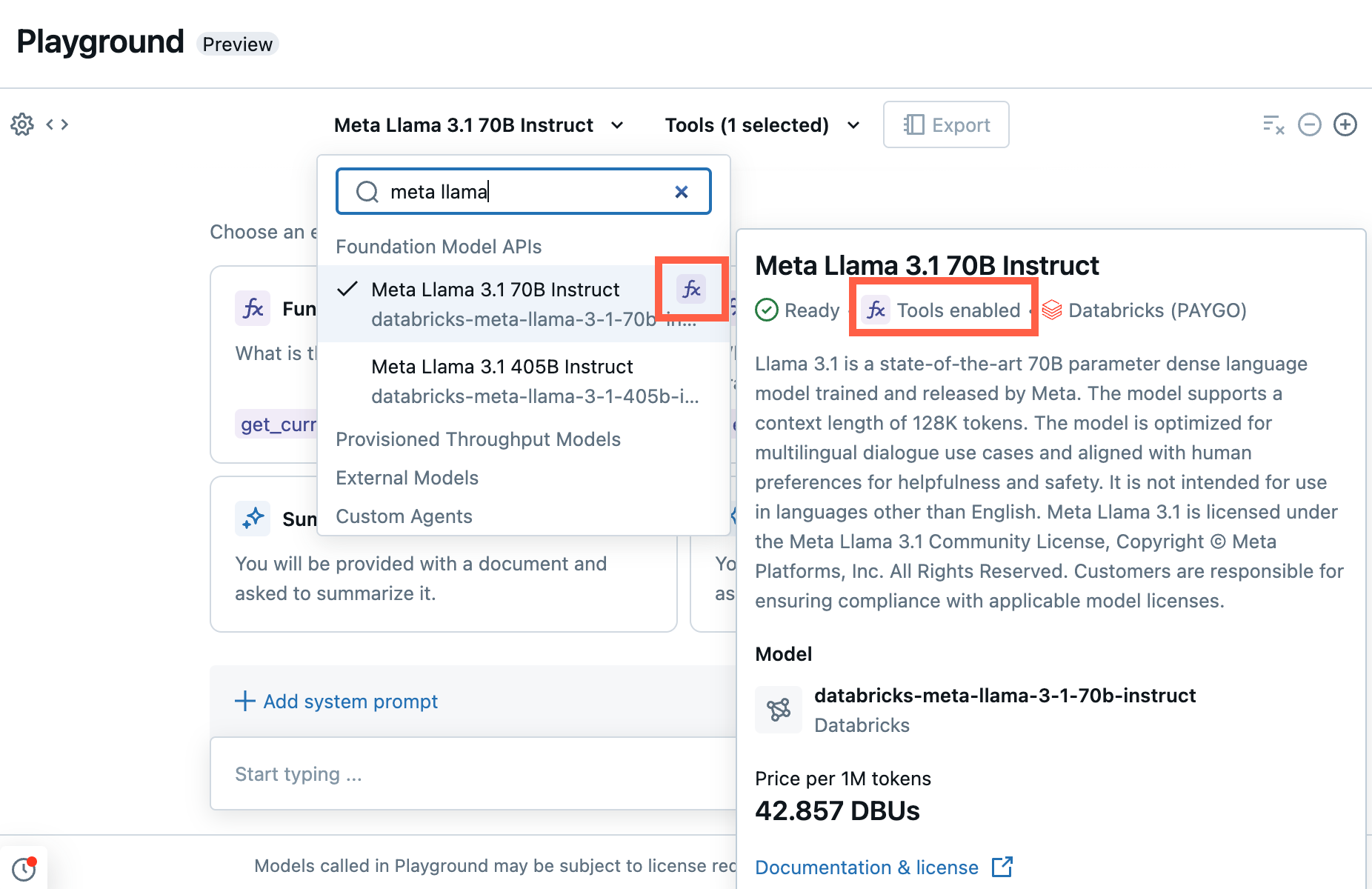
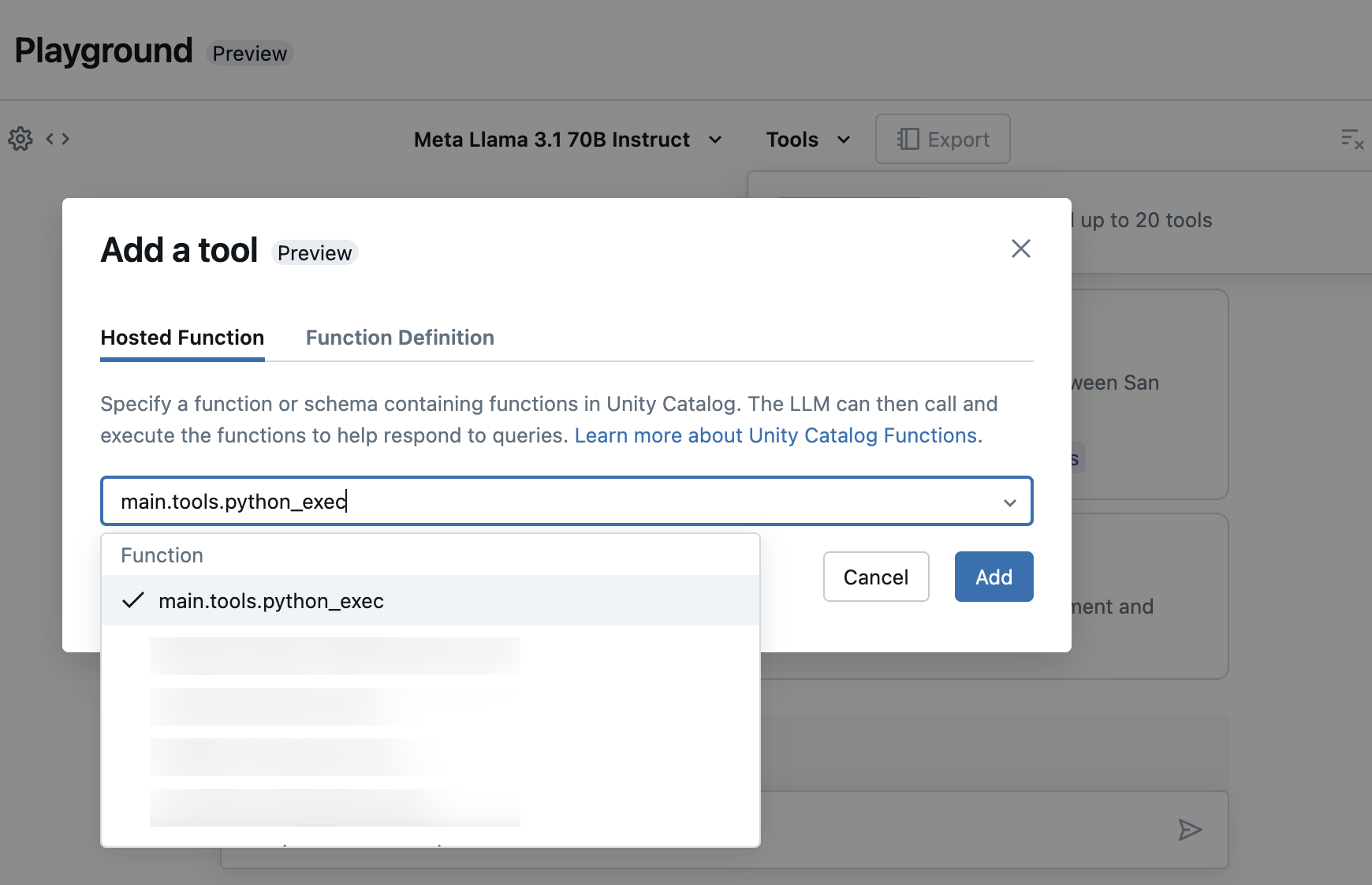
选择“工具”,并在下拉列表中指定 Unity Catalog 函数名称:
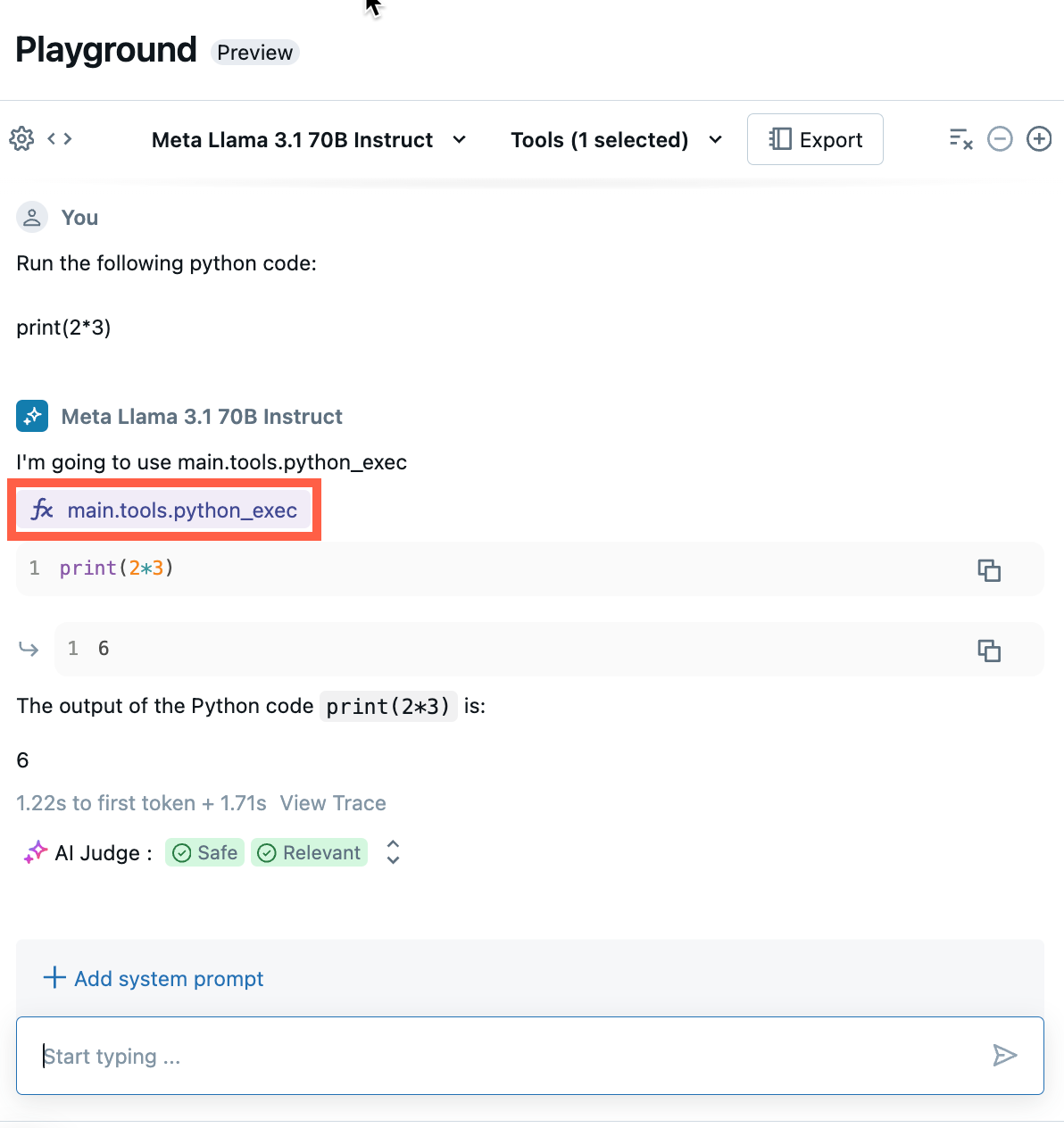
通过聊天测试当前的 LLM、工具和系统提示的组合,并尝试变体。
导出和部署 AI 操场代理
添加工具和测试代理后,将操场代理导出到 Python 笔记本:
单击“导出代理代码”以生成 Python 笔记本笔记本,以帮助开发和部署 AI 代理。
导出代理代码后,会看到三个文件保存到工作区:
agent笔记本:包含使用 LangChain 定义代理的 Python 代码。driver笔记本:包含使用 Mosaic AI 代理框架记录、跟踪、注册和部署 AI 代理的 Python 代码。config.yml:包含有关代理的配置信息,包括工具定义。
打开
agent笔记本以查看定义代理的 LangChain 代码,使用此笔记本以编程方式测试和循环访问代理,例如定义更多工具或调整代理的参数。注意
导出的代码可能与 AI 操场会话具有不同的行为。 Databricks 建议运行导出的笔记本,以便进一步进行迭代和调试,评估代理质量,然后部署代理以与他人共享。
对代理的输出感到满意后,就可以运行
driver笔记本来记录代理并将其部署到模型服务终结点。
在代码中定义代理
除了从 AI 操场生成代理代码之外,还可以使用 LangChain 或 Python 代码等框架自行在代码中定义代理。 若要使用代理框架部署代理,其输入必须符合支持的输入和输出格式之一。
使用参数来配置代理
在代理框架中,可以使用参数来控制代理的执行方式。 这样,就可以通过代理的不同特征进行快速迭代,而无需更改代码。 参数是在 Python 字典或 .yaml 文件中定义的键值对。
若要配置代码,请创建一个 ModelConfig,即一组键值参数。 ModelConfig 是 Python 字典或 .yaml 文件。 例如,可以在开发期间使用字典,然后将其转换为 .yaml 文件以用于生产部署和 CI/CD。 有关 ModelConfig 的详细信息,请参阅 MLflow 文档。
下面显示了一个示例 ModelConfig。
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
若要从代码调用配置,请使用以下操作之一:
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
支持的输入格式
下面是代理支持的输入格式。
(建议)使用 OpenAI 聊天完成架构进行查询。 它应有一个对象数组作为
messages参数。 此格式最适合 RAG 应用程序。question = { "messages": [ { "role": "user", "content": "What is Retrieval-Augmented Generation?", }, { "role": "assistant", "content": "RAG, or Retrieval Augmented Generation, is a generative AI design pattern that combines a large language model (LLM) with external knowledge retrieval. This approach allows for real-time data connection to generative AI applications, improving their accuracy and quality by providing context from your data to the LLM during inference. Databricks offers integrated tools that support various RAG scenarios, such as unstructured data, structured data, tools & function calling, and agents.", }, { "role": "user", "content": "How to build RAG for unstructured data", }, ] }SplitChatMessagesRequest。 建议用于多轮次聊天应用程序,特别是当你想要分开管理当前查询和历史记录时。question = { "query": "What is MLflow", "history": [ { "role": "user", "content": "What is Retrieval-augmented Generation?" }, { "role": "assistant", "content": "RAG is" } ] }
对于 LangChain,Databricks 建议使用 LangChain 表达式语言来编写链。 在链定义代码中,可以使用 itemgetter 来获取消息、query 或 history 对象,具体取决于使用的输入格式。
支持的输出格式
代理必须具有以下支持的输出格式之一:
- (建议)ChatCompletionResponse。 建议支持 OpenAI 响应格式互操作性的客户采用此格式。
- StringObjectResponse。 此格式最容易解释,也最简单。
对于 LangChain,请使用 MLflow 中的 StringResponseOutputParser() 或 ChatCompletionsOutputParser() 作为最终链步骤。 这样做会将 LangChain AI 消息的格式设置为与代理兼容的格式。
from mlflow.langchain.output_parsers import StringResponseOutputParser, ChatCompletionsOutputParser
chain = (
{
"user_query": itemgetter("messages")
| RunnableLambda(extract_user_query_string),
"chat_history": itemgetter("messages") | RunnableLambda(extract_chat_history),
}
| RunnableLambda(fake_model)
| StringResponseOutputParser() # use this for StringObjectResponse
# ChatCompletionsOutputParser() # or use this for ChatCompletionResponse
)
如果你使用 PyFunc,Databricks 建议使用类型提示来批注 predict() 函数,其中输入和输出数据类是 mlflow.models.rag_signatures 中定义的类的子类。
可以从 predict() 内的数据类构造一个输出对象,以确保遵循格式。 返回的对象必须转换成字典表示形式,以确保可以序列化。
from mlflow.models.rag_signatures import ChatCompletionRequest, ChatCompletionResponse, ChainCompletionChoice, Message
class RAGModel(PythonModel):
...
def predict(self, context, model_input: ChatCompletionRequest) -> ChatCompletionResponse:
...
return asdict(ChatCompletionResponse(
choices=[ChainCompletionChoice(message=Message(content=text))]
))
示例笔记本
这些笔记本创建一个简单的“Hello,world”链,以演示如何在 Databricks 中创建链应用程序。 第一个示例创建简单的链。 第二个示例笔记本演示如何使用参数来最大程度地减少开发过程中的代码更改。