你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure AI 搜索中的语义排名
在 Azure AI 搜索中,“语义排序器”功能通过使用 Microsoft 语言理解模型对搜索结果重新排名来显著提高搜索相关性。 本文是一个大致简介,帮助你了解语义排序器的行为和优势。
语义排序器是一项高级功能,按使用情况计费。 建议阅读本文以了解背景信息,但如果希望立即开始使用,请按照这些步骤操作。
注意
语义排序器不使用生成式 AI 或矢量。 如果要查找矢量支持和相似性搜索,请参阅 Azure AI 搜索中的矢量搜索了解详细信息。
什么是语义排名?
语义排序器是一组查询侧功能,可提高基于文本的查询、矢量查询和混合查询的初始 BM25 排序或 RRF 排序搜索结果的质量。 针对搜索服务启用它时,语义排名通过两种方式来扩展查询执行管道:
首先,它在使用 BM25 或倒数排序融合 (RRF) 评分的初始结果集的基础上添加了二次排名。 此二次排名使用改写自 Microsoft 必应的多语言深度学习模型来提升在语义上最相关的结果的排名。
其次,它会提取并返回响应中的描述和答案,你可以在搜索页面上呈现它们以改进用户的搜索体验。
下面是语义重新排序器的功能:
| 功能 | 说明 |
|---|---|
| L2 排名 | 使用查询的上下文或语义含义基于预排名的结果计算新的相关性分数。 |
| 语义标题和重点 | 从字段中提取最能总结内容的逐字句子和短语,并突出显示关键段落,以便于扫描。 当单个内容字段对“搜索结果”页来说过于密集时,用于总结结果的标题就非常有用了。 突出显示的文本会提升最相关的术语和短语,这样用户就能够快速确定匹配被视为相关的原因。 |
| 语义答案 | 从语义查询返回的可选附加子结构。 它直接回答了类似问题的查询。 它要求文档包含带有答案特征的文本。 |
语义排序器的工作原理
语义排序器将查询和结果馈送给 Microsoft 托管的语言理解模型,并扫描以获取更好的匹配项。
下图说明了这一概念。 请考虑“capital”一词。 它具有不同的含义,具体取决于上下文是财务、法律、地理还是语法。 通过语言理解,语义排名程序可以检测上下文并提升符合查询意向的结果。
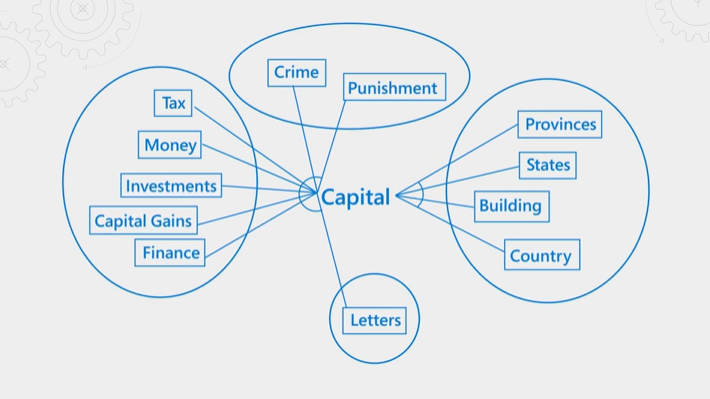
语义排名既耗费资源又耗费时间。 为了在查询操作的预期延迟内完成处理,向语义排名程序提供的输入将被整合并减少,以便可以尽快完成重新排名步骤。
语义排名有三个步骤:
- 收集和汇总输入
- 使用语义排序器对结果评分
- 输出重新评分的结果、标题和答案
如何收集和总结输入
在语义排名中,查询子系统将搜索结果作为摘要和排名模型的输入传递。 由于排名模型具有输入大小约束并且是处理密集型的,因此必须将搜索结果进行结构化(总结)并调整其大小以便高效处理。
语义排序器从文本查询的 BM25 排名结果或矢量/混合查询的 RRF 排名结果开始。 重新排名练习中仅使用文本字段,并且只有前 50 个结果才会进入语义排名,即使结果包含 50 个以上的结果也是如此。 通常,语义排名中使用的字段是信息性和描述性的。
对于搜索结果中的每个文档,摘要模型最多接受 2000 个标记,其中一个标记大约为 10 个字符。 输入由语义配置中列出的“标题”、“关键字”和“内容”字段组合而成。
过长的字符串会被剪裁,以确保总长度满足摘要步骤的输入要求。 此剪裁练习演示了为什么必须按优先级顺序向语义配置添加字段。 如果你的文档非常大,其中的字段包含大量文本,则会忽略超过最大限制的任何内容。
语义字段 标记限制 "title" 128 个标记 "关键字 128 个标记 "内容" 剩余标记 摘要输出是每个文档的摘要字符串,由每个字段中最相关的信息组成。 摘要字符串将发送到排名程序进行评分,并发送到计算机阅读理解模型以获取标题和答案。
传递给语义排名程序的每个生成的摘要字符串的最大长度为 256 个标记。
如何对排名评分
评分是针对标题以及用于填充长度为 256 个标记的摘要字符串中的任何其他内容执行的。
根据所提供的查询,对标题的概念和语义相关性进行评估。
@search.rerankerScore 根据给定查询的文档的语义相关性分配给每个文档。 分数范围从 4 到 0(从高到低),分数越高表示相关性越高。
分数 含义 4.0 文档高度相关,并完全回答问题,但段落可能包含与问题无关的额外文本。 3.0 文档是相关的,但缺少使其完整的详细信息。 2.0 文档在某种程度上相关;它要么部分回答了问题,要么只回答了问题的某些方面。 1.0 文档与问题相关,它回答了问题的一小部分。 0.0 文档是不相关的。 匹配项按分数降序列出,并且包含在查询响应有效负载中。 有效负载包括答案、普通文本标题和突出显示的标题,以及标记为可检索的任何字段或在 select 子句中指定的任何字段。
注意
对于任何给定的查询,@search.rerankerScore 的分布可能会因基础结构级别的条件而略有不同。 排名模型更新也会影响分布。 出于这些原因,如果要为最小阈值编写自定义代码,或者要为向量和混合查询设置阈值属性,请不要使限制过于细化。
语义排序器的输出
从每个摘要字符串中,计算机阅读理解模型查找最有代表性的段落。
输出为:
文档的语义标题。 每个标题都有普通文本版本和突出显示版本,在每个文档中通常少于 200 字。
一个可选的语义答案,假设你指定了
answers参数,查询以问题的形式提出,并且在长字符串中找到了一个段落,该段落提供了此问题的可能答案。
标题和答案始终是索引中的逐字文本。 此工作流中没有可创建或撰写新内容的生成式 AI 模型。
语义功能和限制
语义排序器是一项较新的技术,因此,对它能够做什么和不能做什么设定期望非常重要。 它能够做什么:
提升在语义上更接近原始查询意向的匹配项。
查找要用作标题和答案的字符串。 标题和答案在响应中返回,并且可以在搜索结果页上呈现。
语义排序器不能做的是,在整个语料库上重新运行查询来查找语义上相关的结果。 语义排名会对现有结果集重新排名,该结果集由按默认排名算法评分的前 50 个结果组成。 另外,语义排序器无法创建新的信息或字符串。 标题和答案是从内容逐字提取的,因此,如果结果不包含与答案类似的文本,则语言模型不会生成它。
虽然语义排名并非在每种情况下都有益处,但某些内容可以显著受益于其功能。 语义排序器中的语言模型最适用于信息丰富并且为散文结构的可搜索内容。 知识库、联机文档或包含描述性内容的文档可从语义排序器功能获得最大收益。
基础技术来自必应和 Microsoft Research,并已作为附加产品功能集成到 Azure AI 搜索基础结构中。 有关用于支持语义排序器的研究和 AI 投入的详细信息,请参阅必应的 AI 功能如何为 Azure AI 搜索提供支持(Microsoft Research 博客)。
以下视频概要介绍功能。
可用性和定价
语义排序器适用于基本层和更高层的搜索服务(受区域可用性限制)。
启用语义排序器时,请选择该功能的定价计划:
- 在查询量较低的情况下(每月 1000 以下),语义排名是免费的。
- 在查询量较高的情况下,请选择标准定价计划。
Azure AI 搜索定价页显示适用于不同货币和间隔的计费费率。
如果查询请求包括 queryType=semantic 并且搜索字符串不为空(例如 search=pet friendly hotels in New York),则会对语义排序器收费。 如果搜索字符串为空 (search=*),即使 queryType 设置为 semantic,也不会收费。
如何开始使用语义排序器
登录到 Azure 门户以验证搜索服务是否为“基本”或更高。