检索增强生成 (RAG) 提供 LLM 知识
本文介绍了检索增强生成如何让 LLM 在无需训练的情况下将数据源视为知识。
LLM 通过培训拥有庞大的知识库。 对于大多数方案,你可以选择一个专为你的要求设计的 LLM,但这些 LLM 仍然需要额外的训练来了解你的特定数据。 你可以使用检索增强生成将数据提供给 LLM,而无需事先对其进行训练。
RAG 的工作原理
若要执行检索增强生成,请为数据创建嵌入内容,以及有关数据的常见问题。 你可以动态执行此操作,也可以使用矢量数据库解决方案创建和存储嵌入内容。
当用户提出问题时,LLM 会使用嵌入来比较用户的问题与数据,并查找最相关的上下文。 然后,此上下文和用户的问题在提示中转到 LLM,LLM 会根据你的数据提供响应。
基本 RAG 过程
若要执行 RAG,必须处理要用于检索的每个数据源。 基本流程如下所示:
- 将大型数据分块成可管理的部分。
- 将区块转换为可搜索格式。
- 将转换后的数据存储在允许高效访问的位置。 此外,当 LLM 提供响应时,存储引文或引用的相关元数据也很重要。
- 在提示中将转换后的数据馈送给 LLM。
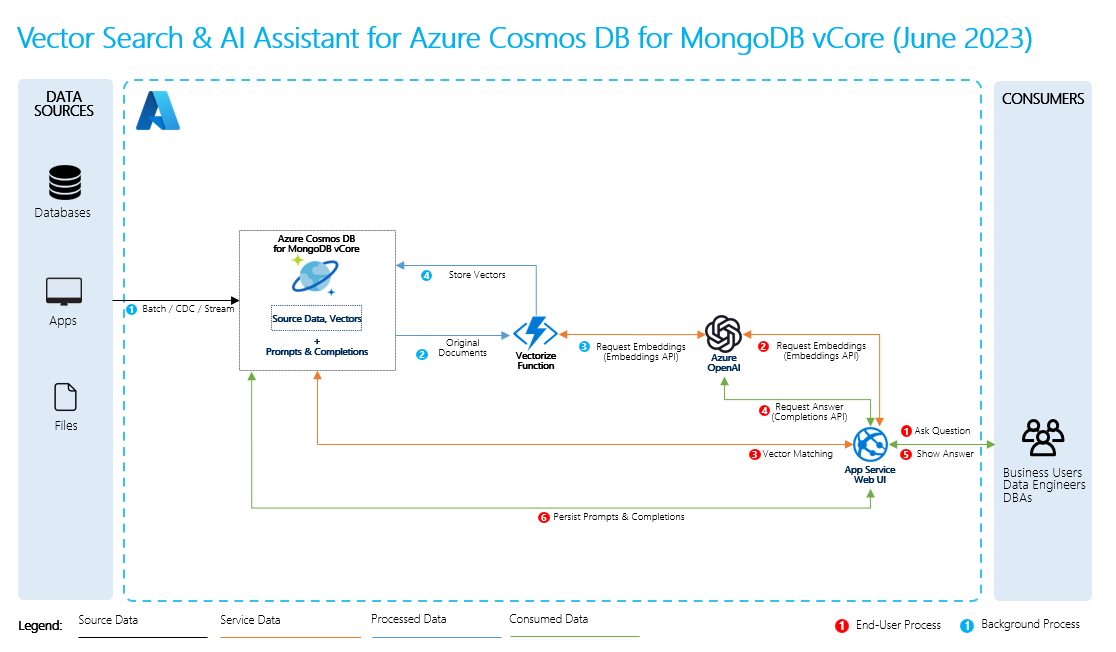
- 源数据:这是数据所在的位置。 它可以是计算机上的文件/文件夹、云存储中的文件、Azure 机器学习数据资产、Git 存储库或 SQL 数据库。
- 数据分块:源中的数据需要转换为纯文本。 例如,Word 文档或 PDF 需要破解并转换为文本。 然后,文本被分块成较小的部分。
- 将文本转换为矢量:这些是嵌入内容。 矢量是转换为数字序列的概念的数值表示形式,通过它,计算机可以轻松了解这些概念之间的关系。
- 源数据和嵌入之间的链接:此信息作为元数据存储在所创建的区块上,然后用于帮助 LLM 在生成响应时生成引文。