数据统一最佳做法
当您设置规则以将数据统一到客户配置文件中时,请考虑以下最佳实践:
平衡统一与完全匹配的时间。 尝试捕获每个可能的匹配会导致许多规则和统一需要很长时间。
逐步添加规则并跟踪结果。 移除不会改善匹配结果的规则。
对每个表 进行重复数据删除,以便每个客户都显示在一行中。
使用 规范化 来标准化数据输入方式的变化 ,例如 Street vs. St vs. St. vs. st.
策略性地使用 模糊匹配 来纠正拼写错误和错误 ,例如 bob@contoso.com and bob@contoso.cm。与精确匹配相比,模糊匹配需要更长的运行时间。 始终进行测试,看看在模糊匹配上花费的额外时间是否值得额外的匹配率。
使用 完全匹配来缩小匹配范围。 确保具有模糊条件的每个规则都至少有一个完全匹配条件。
不要匹配包含大量重复数据的列。 确保模糊匹配列的值不会频繁重复,例如表单的默认值“Firstname”。
统一性能
每个规则都需要一些时间才能运行。 将每个表与每个其他表进行比较或尝试捕获每个可能的记录匹配项等模式可能会导致较长的统一处理时间。 它还会在将每个表与基表进行比较的计划上返回很少的匹配项(如果有的话)。
最好的方法是从您知道需要的一组基本规则开始,例如将每个表与主表进行比较。 您的主表应该是包含最完整、最准确数据的表。 此表应按顺序排列在“匹配规则统一”步骤的顶部。
逐步添加几条规则,并查看更改需要多长时间才能运行,以及结果是否有所改善。 转到“ 设置>系统>状态 ”,然后选择 “匹配 ”以查看每次统一运行重复数据删除和匹配所花费的时间。
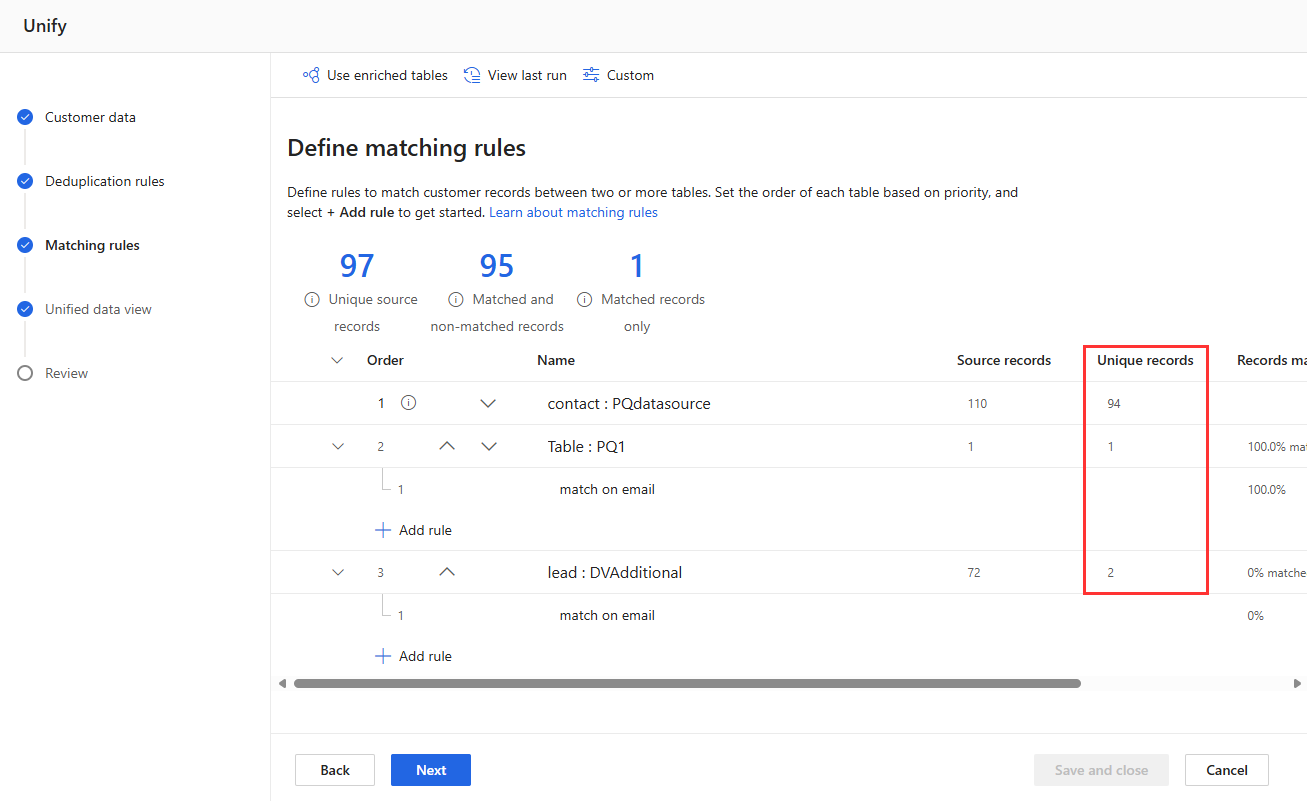
在“重复数据删除规则” 和 “匹配规则 ”页面上查看规则统计信息,以查看唯一记录 的数量 是否发生变化。 如果新规则与某些记录匹配,并且唯一记录计数没有更改,则以前的规则将标识这些匹配项。
重复数据删除
使用重复数据删除规则删除表中的重复客户记录,以便每个表中的一行代表每个客户。 好的规则可识别唯一客户。
在这个简单示例中,记录 1、2 和 3 共享电子邮件或电话号码,并代表同一个人。
| ID | 客户 | 手机 | |
|---|---|---|---|
| 1 | 人员 1 | (425) 555-1111 | AAA@A.com |
| 2 | 人员 1 | (425) 555-1111 | BBB@B.com |
| 3 | 人员 1 | (425) 555-2222 | BBB@B.com |
| 4 | 人员 2 | (206) 555-9999 | Person2@contoso.com |
我们不想只在姓名上匹配,因为这会将不同的人与同一个姓名匹配。
使用“名称”和“电话”创建规则 1,该规则与记录 1 和 2 匹配。
使用“名称”和“电子邮件”创建规则 2,该规则与记录 2 和 3 匹配。
规则 1 和规则 2 的组合创建单个匹配组,因为它们共用记录 2。
您可以决定唯一标识客户的规则和条件的数量。 具体的规则取决于您可以匹配的数据、数据的质量以及您希望重复数据删除过程的详尽程度。
获胜者与备用记录
运行规则并识别出重复记录后,重复数据删除过程将选择“入选者行”。非入选行称为“Alternate行”。 Alternate行用于匹配规则统一步骤,用于将其他表中的记录与入选行匹配。 除了获胜者行之外,行还会与备用行中的数据进行匹配。
将规则添加到表后,您可以通过“合并”偏好设置 配置要选择哪一行作为入选行。 合并首选项按表设置。 无论选择哪种合并策略,如果获胜者行出现平局,则数据顺序中的第一行将用作决胜局。
标准化
使用归一化来标准化数据,以实现更好的匹配。 归一化在大型数据集上表现良好。
标准化数据仅用于比较目的,以更有效地匹配客户记录。 它不会更改最终统一客户配置文件输出中的数据。
| 标准化 | 示例 |
|---|---|
| 数字 | 将许多表示数字的 Unicode 符号转换为简单数字。 示例: ❽ 和 VIII. 都归一化为数字 8。 注意:符号必须以 Unicode 点格式编码。 |
| 代码 | 删除符号和特殊字符。 示例:!?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| 文本转小写 | 将大写字符转换为小写字符。 示例:“THIS Is aN EXamplE”转换为“THIS IS AN EXAMPLE” |
| 类型 – 电话 | 将各种格式的电话转换为数字,考虑国家/地区代码和分机号显示方式的变化。 示例:+01 425.555.1212 = 1 (425) 555-1212 |
| 类型 - 名称 | 转换 500 多种常见名称变体和标题。 示例:“debby”->“deborah”“prof”和“professor”->“Prof.” |
| 类型 - 地址 | 转换地址的通用部分 示例:“street”->“st”和“northwest”->“nw” |
| 类型 - 组织 | 删除了大约 50 个公司名称“干扰词”,例如“co”、“corp”、“corporation”和“ltd”。 |
| Unicode 转 ASCII | 将 Unicode 字符转换为同等 ASCII 字母 示例:字符“à”、“á”、“â”、“À”、“Á”、“”、“Ô、“Ä”、“Ⓐ”和“A”全部转换为“a”。 |
| 空白 | 删除所有空格 |
| 别名映射 | 允许您上载字符串对的自定义列表,然后可以使用该列表来指示应始终被视为完全匹配的字符串。 当您有您认为应该匹配的特定数据示例,但使用其他标准化模式之一无法匹配时,使用别名映射。 示例:Scott 和 Scooter,或 MSFT 和 Microsoft。 |
| 自定义绕过 | 允许您上载字符串的自定义列表,然后可以使用该列表来指示永远不应匹配的字符串。 当您的数据具有应忽略的常见值(例如虚拟电话号码或虚拟电子邮件)时,自定义绕过非常有用。 示例:永远不要匹配手机 555-1212,或者 test@contoso.com |
完全匹配
使用精度来确定两个字符串的关闭程度应被视为匹配项。 默认精度设置需要完全匹配。 任何其他值都启用该条件的模糊匹配。
精度可以设置为低(30% 匹配)、中(60% 匹配)和高(80% 匹配)。 或者,您可以以 1% 的增量自定义和设置精度。
完全匹配条件
首先运行精确匹配条件,以获得用于模糊匹配的缩小值集。 要达到预期结果,精确匹配条件应该具有合理程度的唯一性。 例如,如果所有客户都位于同一国家/地区,则在该国家/地区上完全匹配无助于缩小范围。
全名、电子邮件、电话或地址字段等列具有很好的唯一性,是用作完全匹配的绝佳列。
确保用于完全匹配条件的列没有任何经常重复的值,例如表单捕获的默认值“Firstname”。 客户见解可以分析数据列,以提供对排名靠前的重复值的见解。 可以在 Azure Data Lake(使用 Common Data Model 或 Delta 格式)、连接和 Synapse 上启用数据分析。 数据配置文件在下次刷新数据源时运行。 有关更多信息,请 转到数据分析。
模糊匹配
使用模糊匹配来匹配已关闭但由于拼写错误或其他小变化而不精确的字符串。 有策略地使用模糊匹配,因为它比精确匹配慢。 确保在任何具有模糊条件的规则中至少有一个完全匹配条件。
模糊匹配不适用于捕获 Suzzie 和 Suzanne 等名称变体。 使用“规范化模式 类型:名称 ”或自定义 别名匹配 可以更好地捕获这些变体,客户可以在其中输入他们想要视为匹配项的名称变体列表。
您可以向规则添加条件,如匹配 FirstName 和 Phone。 给定规则内的条件是“AND”条件。 每个条件都必须匹配,行才能匹配。 单独的规则是“OR”条件。 如果规则 1 与行不匹配,则将这些行与规则 2 进行比较。
备注
只有字符串数据类型列可以使用模糊匹配。 对于具有其他数据类型(如整数、双精度或日期时间)的列,精度字段是只读的,并设置为完全匹配。
模糊匹配计算
模糊匹配是通过计算两个字符串之间的编辑距离分数来确定的。 如果分数达到或超过精度阈值,则字符串被视为匹配项。
编辑距离是通过添加、删除或更改字符将一个字符串转换为另一个字符串所需的编辑次数。
例如,当我们删除 q、u、e、i 和 e 字符并插入 y 字符时,字符串 “Jacqueline” 和 “Jaclyne” 的编辑距离为 5。
要计算编辑距离分数,请使用以下公式:(基本字符串长度 - 编辑距离)/基本字符串长度。
| 基本字符串 | 比较字符串 | 分数 |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0.857 |
| franklin | frank | (8-3) / 8 = 0.625 |