湖屋端到端方案:概述和体系结构
Microsoft Fabric 是面向企业的一体化分析解决方案,涵盖从数据移动到数据科学、实时分析和商业智能的所有内容。 它提供一套全面的服务,包括数据湖、数据工程和数据集成,全部放在一个位置。 有关详细信息,请参阅什么是 Microsoft Fabric?
本教程将引导你完成从数据获取到使用数据的端到端方案。 它可以帮助你建立对 Fabric 的基本了解,包括不同的体验及其集成方式,以及在该平台上工作所带来的专业和平民开发者体验。 本教程不是参考体系结构、特性和功能的详尽列表或具体最佳做法的建议。
湖屋端到端方案
过去,组织一直在构建新式数据仓库,以满足其事务和结构化数据分析需求。 此外,组织还构建数据湖屋(半结构化/非结构化)来满足大数据数据分析需求。 这两个系统并行运行,造成了孤岛和数据重复并增加了总拥有成本。
Fabric 在 Delta Lake 格式上统一了数据存储和标准化,可消除孤岛、去除重复数据并大幅降低总拥有成本。
借助 Fabric 提供的灵活性,可以实施湖屋或数据仓库体系结构,或者将它们组合在一起,通过简单的实施来充分利用这两者。 在本教程中,你将以零售组织为例,完成其湖屋构建的整个过程。 它使用奖牌体系结构,其中青铜层具有原始数据,银层具有经过验证和重复数据删除的数据,黄金层具有高度精细的数据。 可以采用相同的方法为任何行业的任何组织实施湖屋。
本教程介绍来自零售领域的虚构 Wide World Importers 公司的开发人员如何完成以下步骤:
登录到 Power BI 帐户并注册免费的 Microsoft Fabric 试用版。 如果没有 Power BI 许可证,请注册 Power BI 免费许可证,然后可以启动 Fabric 试用版。
为组织构建并实施端到端湖屋:
- 创建 Fabric 工作区。
- 创建湖屋。
- 引入数据、转换数据并将其加载到湖屋中。 还可以跨湖屋模式和 SQL 分析终结点模式浏览数据的 OneLake、OneCopy。
- 使用 SQL 分析终结点连接到湖屋,然后使用 DirectLake 创建 Power BI 报表,以跨不同维度分析销售数据。
- (可选)可以使用管道来协调和计划数据引入和转换流。
通过删除工作区和其他项来清理资源。
体系结构
下图显示了湖屋端到端体系结构。 以下列表中描述了所涉及的组件。
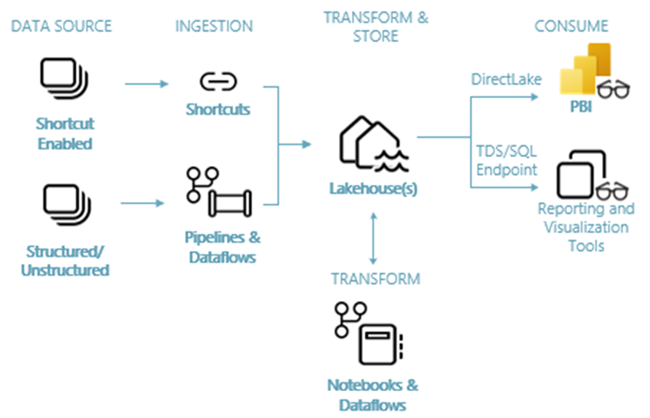
数据源:使用 Fabric 可以快速轻松地连接到 Azure 数据服务以及其他基于云的平台和本地数据源,从而简化数据引入。
引入:可以使用 200 多个本机连接器快速为组织生成见解。 这些连接器集成到 Fabric 管道中,并通过数据流利用用户友好的拖放数据转换。 此外,借助 Fabric 中的快捷方式功能,可以连接到现有数据,而无需复制或移动数据。
转换和存储:Fabric 对 Delta Lake 格式实施标准化。 这意味着所有 Fabric 引擎都可以访问和操作 OneLake 中存储的相同数据集,而无需复制数据。 此存储系统可以根据组织要求,使用奖牌体系结构或数据网格灵活构建湖屋。 可以使用管道/数据流或笔记本/Spark 实现代码优先体验,在低代码或无代码数据转换体验之间进行选择。
使用:Power BI 可以使用湖屋中的数据进行报告和可视化。 每个湖屋都有一个内置的 TDS 终结点(称为 SQL 分析终结点),以便从其他报告工具轻松连接和查询湖屋表中的数据。 SQL 分析终结点为用户提供 SQL 连接功能。
示例数据集
本教程使用 Wide World Importers (WWI) 示例数据库,在下一教程中,该数据库将导入湖屋。 对于湖屋端到端方案,我们已生成足够的数据来探索 Fabric 平台的规模和性能功能。
Wide World Importers (WWI) 是一家在旧金山湾区运营的批发新奇商品进口商和分销商。 作为一家批发商,WWI 的客户大多是向个人转售产品的公司。 WWI 向美国各地的零售客户销售产品,包括专卖店、超市、计算商店、旅游景区商店和某些人。 WWI 还通过代理网络向其他批发商销售产品,这些代理代表 WWI 推销他们的产品。 若要了解有关其公司配置文件和运营的详细信息,请参阅适用于 Microsoft SQL 的 Wide World Importers 示例数据库。
通常,数据从事务系统或业务线应用程序引入湖屋。 但是,为简单起见,在本教程中,我们使用 WWI 提供的维度模型作为初始数据源。 我们使用它作为源,将数据引入湖屋,并通过奖牌体系结构的不同阶段(铜牌、银牌和金牌)对其进行转换。
数据模型
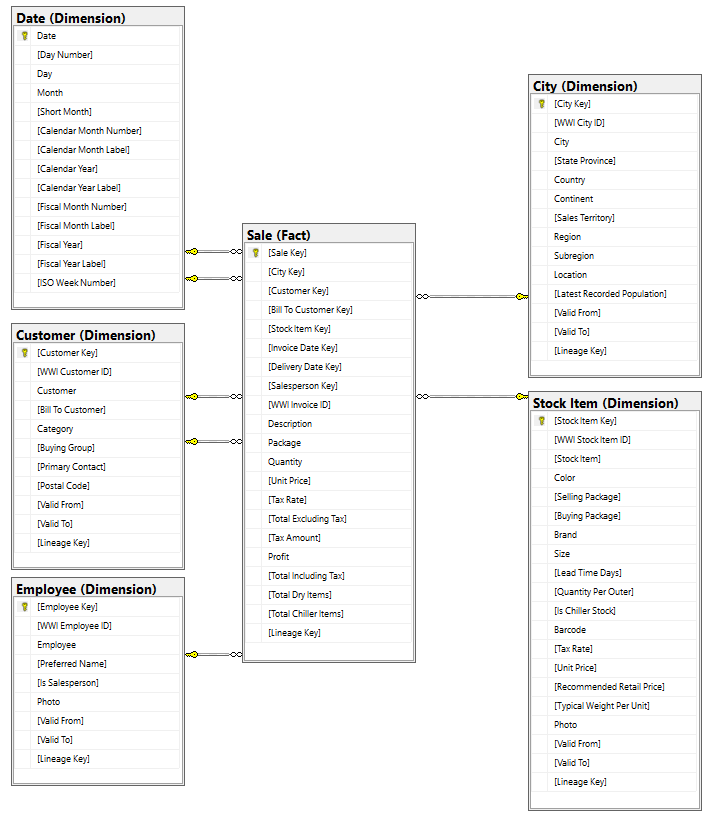
虽然 WWI 维度模型包含许多事实数据表,但对于本教程,我们使用销售事实数据表及其相关维度。 下面的示例对 WWI 数据模型进行了说明:
数据和转换流
如前所述,我们将使用来自 Wide World Importers (WWI) 示例数据的示例数据来构建此端到端湖屋。 在此实施中,示例数据存储在所有表的 Parquet 文件格式的 Azure 数据存储帐户中。 但是,在实际场景中,数据通常源自各种源和不同的格式。
下图显示了源、目标和数据转换:
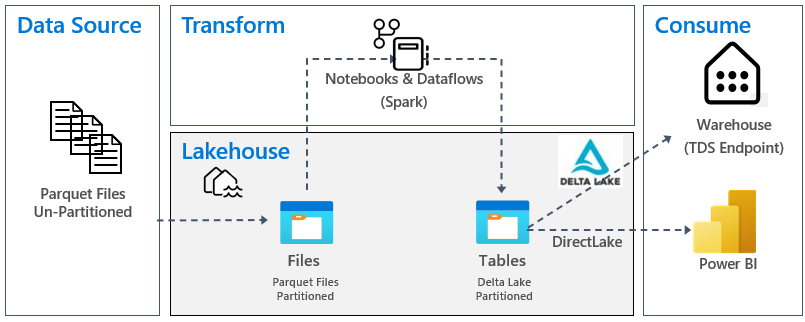
数据源:源数据采用 Parquet 文件格式和未分区的结构。 它存储在每个表的文件夹中。 在本教程中,我们设置了一个管道,用于将完整的历史数据或一次性数据引入湖屋。
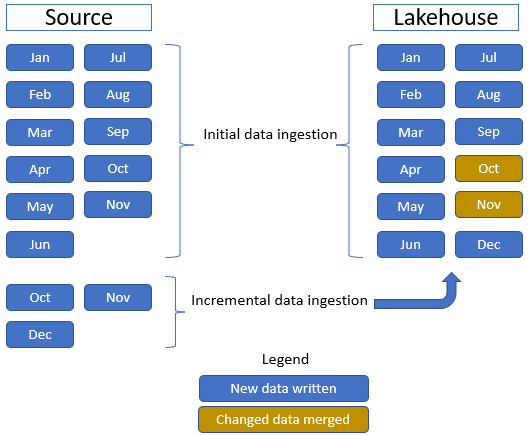
在本教程中,我们使用了销售事实数据表,一个父文件夹包含 11 个月的历史数据(每个月一个子文件夹),另一个文件夹包含三个月的增量数据(每个月一个子文件夹)。 在初始数据引入期间,11 个月的数据将引入湖屋表。 但是,当增量数据到达时,它将包括 10 月和 11 月的更新数据,以及 12 月和 11 月的新数据。10 月和 11 月数据将与现有数据合并,并将新的 12 月数据写入湖屋表,如下图所示:
湖屋:在本教程中,你将创建一个湖屋,将数据引入湖屋的文件部分,然后在湖屋的“表”部分创建 delta lake 表。
转换:对于数据准备和转换,可以看到两种不同的方法。 我们演示了如何为倾向于代码优先体验的用户使用 Notebooks/Spark,并为倾向于低代码或无代码体验的用户使用管道/数据流。
使用:为了演示数据使用,你将了解如何使用 Power BI 的 DirectLake 功能从湖屋创建报表、仪表板和直接查询数据。 此外,我们还演示了如何使用 TDS/SQL 分析终结点将数据提供给第三方报告工具。 此终结点允许连接到仓库并运行 SQL 查询进行分析。