训练和评估时序预测模型
在此笔记本中,我们构建一个程序来预测具有季节性周期的时序数据。 我们使用由纽约财政部在纽约市开放数据门户上发布的从 2003 年到 2015 年的纽约房地产销售数据集。
先决条件
获取 Microsoft Fabric 订阅。 或者注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左侧的体验切换器切换到 Synapse 数据科学体验。
- 熟悉 Microsoft Fabric 笔记本。
- 用于存储此示例数据的湖屋。 有关更多信息,请参阅将湖屋添加到笔记本。
请按照笔记本进行操作
可以遵循以下两种方式之一在笔记本中执行操作:
- 在 Synapse 数据科学体验中打开并运行内置笔记本。
- 将笔记本从 GitHub 上传到 Synapse 数据科学体验。
打开内置笔记本
示例时序笔记本是本教程随附的笔记本。
若要在 Synapse 数据科学体验中打开教程的内置示例笔记本,请执行以下操作:
转到 Synapse 数据科学主页。
选择“使用示例”。
选择相应的示例:
- 来自默认的“端到端工作流 (Python)”选项卡(如果示例适用于 Python 教程)。
- 来自“端到端工作流 (R)“选项卡(如果示例适用于 R 教程)。
- 从“快速教程”选项卡选择(如果示例适用于快速教程)。
从 GitHub 导入笔记本
AIsample - 时序 Forecasting.ipynb 是本教程随附的笔记本。
若要打开本教程随附的笔记本,请按照让系统为数据科学做好准备教程中的说明操作,将该笔记本导入到工作区。
或者,如果要从此页面复制并粘贴代码,则可以创建新的笔记本。
在开始运行代码之前,请务必将湖屋连接到笔记本。
步骤 1:安装自定义库
开发机器学习模型或处理临时数据分析时,可能需要为 Apache Spark 会话快速安装自定义库(例如,本笔记本中的 prophet)。 若要实现此目标,有两个选择。
- 可以使用内联安装功能(例如,
%pip、%conda等等)快速开始使用新库。 这只会在当前笔记本(而不是工作区)中安装自定义库。
# Use pip to install libraries
%pip install <library name>
# Use conda to install libraries
%conda install <library name>
- 也可以创建 Fabric 环境,安装来自公共来源的安装库或将自定义库上传到该环境,然后工作区管理员可以将环境附加为工作区的默认值。 然后,环境中的所有库都将可用于工作区中的任何笔记本和 Spark 作业定义。 有关环境的详细信息,请参阅在 Microsoft Fabric 中创建、配置和使用环境。
对于此笔记本,使用 %pip install 安装 prophet 库。 PySpark 内核将在 %pip install 之后重启。 这意味着必须安装该库,然后才能运行任何其他单元。
# Use pip to install Prophet
%pip install prophet
步骤 2:加载数据
数据集
此笔记本使用 NYC 属性销售数据数据集。 它涵盖了纽约市财政部 2003 年至 2015 年在纽约市开放数据门户上发布的数据。
该数据集包含 13 年内纽约市房地产市场每栋建筑物销售的记录。 有关数据集中列的定义,请参阅地产销售文件术语表。
| 行政区 | 居住区 | 建筑类别 | 税收类别 | block | 地块 | eastment | 目前建筑类别 | address | 公寓号 | 邮编 | 住宅单元数 | 商业单元数 | 总单元数 | 土地平方尺 | 总平方尺 | 建造年份 | tax_class_at_time_of_sale | 销售时建筑类别 | 售价 | 销售日期 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 曼哈顿 | 字母城 | 07 出租 - 无电梯公寓 | 0.0 | 384.0 | 17.0 | C4 | 225 EAST 2ND STREET | 10009.0 | 10.0 | 0.0 | 10.0 | 2145.0 | 6670.0 | 1900.0 | 2.0 | C4 | 275000.0 | 2007-06-19 | ||
| 曼哈顿 | 字母城 | 07 出租 - 无电梯公寓 | 2.0 | 405.0 | 12.0 | C7 | 508 EAST 12TH STREET | 10009.0 | 28.0 | 2.0 | 30.0 | 3872.0 | 15428.0 | 1930.0 | 2.0 | C7 | 7794005.0 | 2007-05-21 |
目标是建立一个根据历史数据预测每月总销售额的模型。 为此,可以使用 Prophet,这是 Facebook 开发的开源预测库。 Prophet 基于加法模型,其中非线性趋势与每日、每周和每年的季节性以及假期影响相匹配。 Prophet 最适合用于具有强烈季节性影响的时间序列数据集以及多个季节的历史数据。 此外,Prophet 还可以稳健地处理缺失数据和数据异常值。
Prophet 使用可分解的时序模型,该模型包括三个组件:
- 趋势:Prophet 假设分段恒定增长率,并自动选择变化点
- 季节性:默认情况下,Prophet 使用傅立叶级数来拟合每周和每年的季节性
- 假日:Prophet 需要了解过去和将来的所有假日。。 如果假日将来不重复,则 Prophet 不会将其包含在预测中。
该笔记本按月聚合数据,因此会忽略假日。
阅读官方论文,了解有关 Prophet 建模技术的详细信息。
下载数据集并上传到湖屋
数据源包含 15 个 .csv 文件。 这些文件包含纽约五个行政区 2003 年至 2015 年间的房地产销售记录。 为方便起见,nyc_property_sales.tar 文件会保存所有这些 .csv 文件,将它们压缩为一个文件。 公开可用的 Blob 存储将托管此 .tar 文件。
提示
使用此代码单元中显示的参数,可以轻松地将此笔记本应用于不同的数据集。
URL = "https://synapseaisolutionsa.blob.core.windows.net/public/NYC_Property_Sales_Dataset/"
TAR_FILE_NAME = "nyc_property_sales.tar"
DATA_FOLDER = "Files/NYC_Property_Sales_Dataset"
TAR_FILE_PATH = f"/lakehouse/default/{DATA_FOLDER}/tar/"
CSV_FILE_PATH = f"/lakehouse/default/{DATA_FOLDER}/csv/"
EXPERIMENT_NAME = "aisample-timeseries" # MLflow experiment name
以下代码将下载数据集的公开可用版本,然后将该数据集存储在 Fabric 湖屋中。
重要
确保在运行笔记本之前向笔记本中添加湖屋。 否则可能会导致出错。
import os
if not os.path.exists("/lakehouse/default"):
# Add a lakehouse if the notebook has no default lakehouse
# A new notebook will not link to any lakehouse by default
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse for the notebook."
)
else:
# Verify whether or not the required files are already in the lakehouse, and if not, download and unzip
if not os.path.exists(f"{TAR_FILE_PATH}{TAR_FILE_NAME}"):
os.makedirs(TAR_FILE_PATH, exist_ok=True)
os.system(f"wget {URL}{TAR_FILE_NAME} -O {TAR_FILE_PATH}{TAR_FILE_NAME}")
os.makedirs(CSV_FILE_PATH, exist_ok=True)
os.system(f"tar -zxvf {TAR_FILE_PATH}{TAR_FILE_NAME} -C {CSV_FILE_PATH}")
开始记录此笔记本的运行时间。
# Record the notebook running time
import time
ts = time.time()
设置 MLflow 试验跟踪
为了扩展 MLflow 日志记录功能,自动日志记录会在训练期间自动捕获机器学习模型的输入参数和输出指标的值。 然后,此信息会记录到工作区,MLflow API 或工作区中的相应试验可以访问并可视化该信息。 有关自动记录的详细信息,请访问此资源。
# Set up the MLflow experiment
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
注意
若要在笔记本会话中禁用 Microsoft Fabric 自动日志记录,请调用 mlflow.autolog() 并设置 disable=True。
从湖屋中读取原始日期数据
df = (
spark.read.format("csv")
.option("header", "true")
.load("Files/NYC_Property_Sales_Dataset/csv")
)
步骤 3:开始探索性数据分析
若要查看数据集,可以手动检查数据子集以更好地理解数据。 可以使用 display 函数来打印 DataFrame。 还可以显示图表视图以轻松可视化数据集的子集。
display(df)
手动审查数据集可以得出一些早期观察结果:
$0.00 销售价格的实例。 根据术语表,这意味着在没有现金对价的情况下转让所有权。 换句话说,交易中没有现金流。 应从数据集中删除
sales_price值为 $0.00 的销售额。数据集涵盖不同的构建类。 然而,本笔记本将重点关注根据术语表标记为“A”类型的住宅建筑。 应筛选数据集以仅包含住宅建筑。 为此,请包括
building_class_at_time_of_sale列或building_class_at_present列。 只能包含building_class_at_time_of_sale数据。数据集包括
total_units值等于 0 或gross_square_feet值等于 0 的实例。 应删除total_units或gross_square_units值等于 0 的所有实例。某些列(例如,
apartment_number、tax_class、build_class_at_present等)具有缺失值或 NULL 值。 假设缺失的数据涉及笔误,或者数据不存在。 分析不依赖于这些缺失值,因此可以忽略它们。sale_price列存储为字符串,并带有前缀“$”字符。 若要继续分析,请将此列表示为数字。 应将sale_price列强制转换为整数。
类型转换和筛选
若要解决某些已识别的问题,请导入所需的库。
# Import libraries
import pyspark.sql.functions as F
from pyspark.sql.types import *
将销售数据从字符串转换为整数
使用正则表达式将字符串的数字部分与美元符号分开(例如,在字符串“$300,000”中,拆分“$”和“300,000”),然后将数字部分转换为整数。
接下来,筛选数据以仅包含满足所有这些条件的实例:
sales_price大于 0total_units大于 0gross_square_feet大于 0building_class_at_time_of_sale为类型 A
df = df.withColumn(
"sale_price", F.regexp_replace("sale_price", "[$,]", "").cast(IntegerType())
)
df = df.select("*").where(
'sale_price > 0 and total_units > 0 and gross_square_feet > 0 and building_class_at_time_of_sale like "A%"'
)
按月聚合
数据资源每天跟踪房地产销售情况,但这种方法对于此笔记本来说过于细化。 相反,它按月聚合数据。
首先,更改日期值以仅显示月份和年份数据。 日期值仍将包含年份数据。 你仍然可以区分 2005 年 12 月和 2006 年 12 月。
此外,仅保留与分析相关的列。 其中包括 sales_price、total_units、gross_square_feet 和 sales_date。 还必须将 sales_date 重命名为 month。
monthly_sale_df = df.select(
"sale_price",
"total_units",
"gross_square_feet",
F.date_format("sale_date", "yyyy-MM").alias("month"),
)
display(monthly_sale_df)
按月聚合 sale_price、total_units 和 gross_square_feet 值。 然后,按 month 分组数据,并为每个组中的所有值求和。
summary_df = (
monthly_sale_df.groupBy("month")
.agg(
F.sum("sale_price").alias("total_sales"),
F.sum("total_units").alias("units"),
F.sum("gross_square_feet").alias("square_feet"),
)
.orderBy("month")
)
display(summary_df)
Pyspark 到 Pandas 的转换
Pyspark DataFrame 可以很好地处理大型数据集。 但是,由于数据聚合,DataFrame 的大小会更小。 这标识你现在可以使用 pandas DataFrames。
此代码会将数据集从 pyspark DataFrame 转换为 pandas DataFrame。
import pandas as pd
df_pandas = summary_df.toPandas()
display(df_pandas)
可视化效果
可以查看纽约市的房地产交易趋势,以更好地理解数据。 这有助于深入了解潜在模式和季节性趋势。 在此资源中了解有关 Microsoft Fabric 数据可视化的详细信息。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
f, (ax1, ax2) = plt.subplots(2, 1, figsize=(35, 10))
plt.sca(ax1)
plt.xticks(np.arange(0, 15 * 12, step=12))
plt.ticklabel_format(style="plain", axis="y")
sns.lineplot(x="month", y="total_sales", data=df_pandas)
plt.ylabel("Total Sales")
plt.xlabel("Time")
plt.title("Total Property Sales by Month")
plt.sca(ax2)
plt.xticks(np.arange(0, 15 * 12, step=12))
plt.ticklabel_format(style="plain", axis="y")
sns.lineplot(x="month", y="square_feet", data=df_pandas)
plt.ylabel("Total Square Feet")
plt.xlabel("Time")
plt.title("Total Property Square Feet Sold by Month")
plt.show()
探索性数据分析中的观察结果摘要
- 数据显示出每年明显的重复模式;这意味着数据具有每年的季节性
- 与冬季相比,夏季月份的销量似乎更高
- 在高销售额年份和低销售额年份的比较中,高销售额年份的高销售额月份和低销售额月份之间的收入差异(从绝对值来看)超过了低销售额年份的高销售额月份和低销售额月份之间的收入差异。
例如,2004年,最高销售月与最低销售月的收入差异约为:
$900,000,000 - $500,000,000 = $400,000,000
2011 年,收入差异计算约为:
$400,000,000 - $300,000,000 = $100,000,000
在你稍后必须在乘性季节性效应和加性季节性效应之间做出选择时,这一点会变得很重要。
步骤 4:模型训练和跟踪
模型拟合
Prophet 输入始终是两列 DataFrame。 一个输入列是名为 ds 的时间列,一个输入列是名为 y 的值列。 时间列应具有日期、时间或日期时间数据格式(例如,YYYY_MM)。 此处的数据集满足这个条件。 值列必须是数字数据格式。
对于模型拟合,必须仅将时间列重命名为 ds,将值列重命名为 y,并将数据传递给 Prophet。 有关详细信息,请参阅 Prophet Python API 文档。
df_pandas["ds"] = pd.to_datetime(df_pandas["month"])
df_pandas["y"] = df_pandas["total_sales"]
Prophet 遵循 scikit-learn 约定。 首先,创建 Prophet 的新实例,设置某些参数(例如 seasonality_mode),然后将该实例适合数据集。
尽管恒定加性因子是 Prophet 的默认季节性效应,但你应该使用“乘性”季节性作为季节性效应参数。 上一节的分析表明,由于季节性幅度的变化,简单的加性季节性根本无法很好地拟合数据。
将 weekly_seasonality 参数设置为 off,因为数据是按月聚合的。 因此,每周数据不可用。
使用马尔可夫链蒙特卡罗 (MCMC) 方法捕获季节性不确定性估计。 默认情况下,Prophet 可以提供趋势和观测噪声的不确定性估计,但不能提供季节性的不确定性估计。 MCMC 需要更多的处理时间,但它们允许算法提供季节性、趋势和观测噪声的不确定性估计。 有关详细信息,请参阅 Prophet 不确定性间隔文档。
通过 changepoint_prior_scale 参数调整自动变化点检测灵敏度。 Prophet 算法会自动尝试在数据中查找轨迹突然变化的实例。 可能会很难找到正确的值。 若要解决此问题,可以尝试不同的值,然后选择性能最佳的模型。 有关详细信息,请参阅 Prophet 趋势变更点文档。
from prophet import Prophet
def fit_model(dataframe, seasonality_mode, weekly_seasonality, chpt_prior, mcmc_samples):
m = Prophet(
seasonality_mode=seasonality_mode,
weekly_seasonality=weekly_seasonality,
changepoint_prior_scale=chpt_prior,
mcmc_samples=mcmc_samples,
)
m.fit(dataframe)
return m
交叉验证
Prophet 有一个内置的交叉验证工具。 该工具可以估计预测误差,并找到性能最佳的模型。
交叉验证技术可以验证模型的效率。 该技术在数据集的子集上训练模型,并在数据集的以前未见过的子集上运行测试。 该技术可以检查统计模型推广到独立数据集的程度。
对于交叉验证,请保留数据集的特定样本,该样本不属于训练数据集。 然后,在部署之前,在该样本上测试经过训练的模型。 然而,这种方法不适用于时间序列数据,因为如果模型已经看到了 2005 年 1 月和 2005 年 3 月的数据,并且你尝试对 2005 年 2 月进行预测,那么该模型实际上可以作弊,因为它可以看到数据趋势的走向。 在实际应用中,目标是预测未来,即不可见的区域。
若要处理这个问题并使测试可靠,请根据日期分割数据集。 使用特定日期之前的数据集(例如前 11 年的数据)进行训练,然后使用其余不可见的数据进行预测。
在此场景中,从 11 年的训练数据开始,然后使用一年时间期进行每月预测。 具体来说,训练数据包含从 2003 年到 2013 年的所有数据。 然后,第一次运行处理 2014 年 1 月到 2015 年 1 月的预测。 下一次运行处理 2014 年 2 月到 2015 年 2 月的预测,依此类推。
对三个经过训练的模型中的每一个重复此过程,看看哪个模型性能最佳。 然后,将这些预测与实际值进行比较,以确定最佳模型的预测质量。
from prophet.diagnostics import cross_validation
from prophet.diagnostics import performance_metrics
def evaluation(m):
df_cv = cross_validation(m, initial="4017 days", period="30 days", horizon="365 days")
df_p = performance_metrics(df_cv, monthly=True)
future = m.make_future_dataframe(periods=12, freq="M")
forecast = m.predict(future)
return df_p, future, forecast
使用 MLflow 记录模型
记录模型以跟踪其参数,并保存模型以供以后使用。 所有相关模型信息都记录在工作区中的实验名称下。 模型、参数和指标以及 MLflow 自动记录项保存在一次 MLflow 运行中。
# Setup MLflow
from mlflow.models.signature import infer_signature
进行试验
机器学习试验是组织和控制所有相关机器学习运行的主要单元。 一次运行对应于模型代码的单次执行。 机器学习试验跟踪是指对所有不同试验及其组件的管理。 这包括参数、指标、模型和其他工件,它有助于组织特定机器学习试验所需的组件。 机器学习试验跟踪还可以通过保存的试验轻松复制过去的结果。 详细了解 Microsoft Fabric 中的机器学习试验。 一旦确定要包含的步骤(例如,在此笔记本中拟合和评估 Prophet 模型),就可以运行试验。
model_name = f"{EXPERIMENT_NAME}-prophet"
models = []
df_metrics = []
forecasts = []
seasonality_mode = "multiplicative"
weekly_seasonality = False
changepoint_priors = [0.01, 0.05, 0.1]
mcmc_samples = 100
for chpt_prior in changepoint_priors:
with mlflow.start_run(run_name=f"prophet_changepoint_{chpt_prior}"):
# init model and fit
m = fit_model(df_pandas, seasonality_mode, weekly_seasonality, chpt_prior, mcmc_samples)
models.append(m)
# Validation
df_p, future, forecast = evaluation(m)
df_metrics.append(df_p)
forecasts.append(forecast)
# Log model and parameters with MLflow
mlflow.prophet.log_model(
m,
model_name,
registered_model_name=model_name,
signature=infer_signature(future, forecast),
)
mlflow.log_params(
{
"seasonality_mode": seasonality_mode,
"mcmc_samples": mcmc_samples,
"weekly_seasonality": weekly_seasonality,
"changepoint_prior": chpt_prior,
}
)
metrics = df_p.mean().to_dict()
metrics.pop("horizon")
mlflow.log_metrics(metrics)
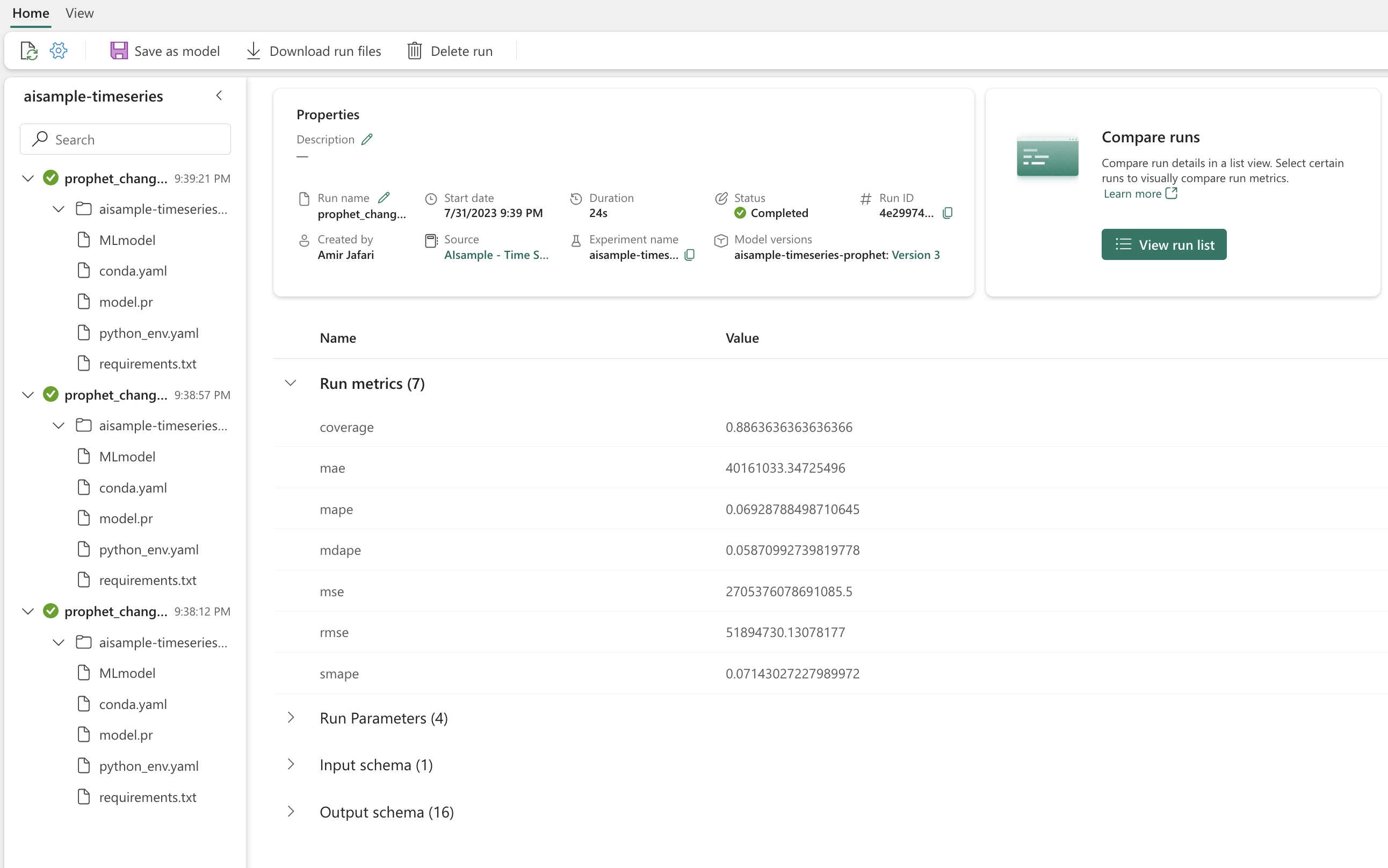
使用 Prophet 可视化模型
Prophet 具有内置的可视化功能,可以展示模型拟合结果。
黑点表示用于训练模型的数据点。 蓝线是预测值,浅蓝色区域显示不确定性间隔。 你已经构建了三个具有不同 changepoint_prior_scale 值的模型。 这三个模型的预测值显示在此代码块的结果中。
for idx, pack in enumerate(zip(models, forecasts)):
m, forecast = pack
fig = m.plot(forecast)
fig.suptitle(f"changepoint = {changepoint_priors[idx]}")
第一个图形中的最小的 changepoint_prior_scale 值导致趋势变化的欠拟合。 第三个图形中最大的 changepoint_prior_scale 可能会导致过度拟合。 因此,第二个图形似乎是最佳选择。 这意味着第二个模型最适合。
使用 Prophet 可视化趋势和季节性
Prophet 还可以轻松可视化潜在趋势和季节性。 第二个模型的可视化效果显示在此代码块的结果中。
BEST_MODEL_INDEX = 1 # Set the best model index according to the previous results
fig2 = models[BEST_MODEL_INDEX].plot_components(forecast)
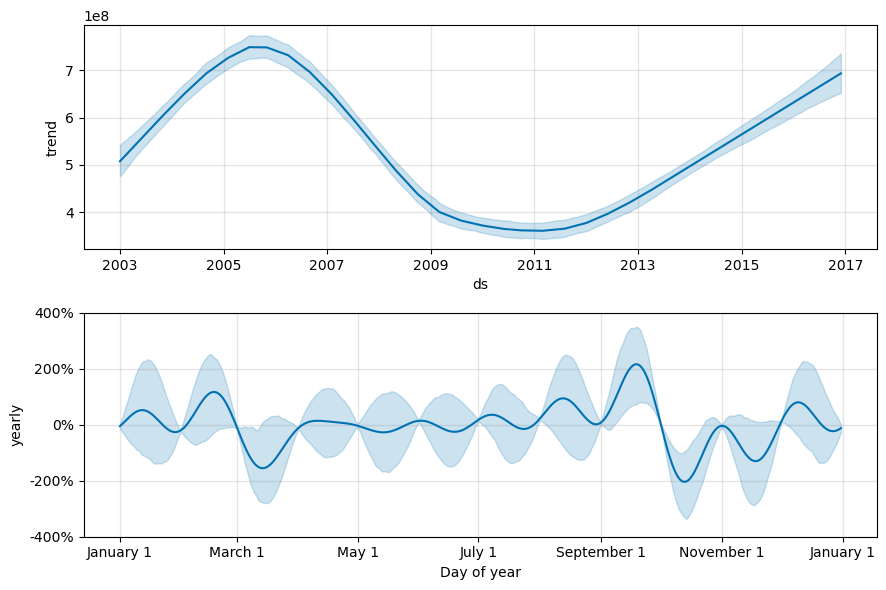
在这些图形中,浅蓝色阴影反映了不确定性。 顶部图表明强劲的长期振荡趋势。 几年来,销量有起有落。 底部图表明销售额往往在二月和九月达到峰值,在这几个月达到当年的最高值。 在那几个月之后不久,即三月和十月,它们跌至当年的最低值。
使用各种指标评估模型的性能,例如:
- 均方误差 (MSE)
- 均方根误差 (RMSE)
- 平均绝对误差 (MAE)
- 平均绝对百分比误差 (MAPE)
- 中值绝对百分比误差 (MDAPE)
- 对称平均绝对百分比误差 (SMAPE)
使用 yhat_lower 和 yhat_upper 估计评估覆盖率。 请注意对未来一年进行预测的不同时间范围,共 12 次。
display(df_metrics[BEST_MODEL_INDEX])
对于该预测模型,使用 MAPE 指标时,对未来一个月的预测通常会产生大约 8% 的误差。 但是,对于未来一年的预测,误差将增加到大约 10%。
步骤 5:对模型进行评分并保存预测结果
现在对模型进行评分,并保存预测结果。
使用 Predict Transformer 进行预测
现在,可以加载模型并使用它进行预测。 用户可以使用 PREDICT 来操作机器学习模型,PREDICT 是一种可扩展的 Microsoft Fabric 功能,支持在任何计算引擎中进行批量评分。 通过此资源了解有关 PREDICT 以及如何在 Microsoft Fabric 中使用它的更多信息。
from synapse.ml.predict import MLFlowTransformer
spark.conf.set("spark.synapse.ml.predict.enabled", "true")
model = MLFlowTransformer(
inputCols=future.columns.values,
outputCol="prediction",
modelName=f"{EXPERIMENT_NAME}-prophet",
modelVersion=BEST_MODEL_INDEX,
)
test_spark = spark.createDataFrame(data=future, schema=future.columns.to_list())
batch_predictions = model.transform(test_spark)
display(batch_predictions)
# Code for saving predictions into lakehouse
batch_predictions.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/batch_predictions"
)
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")