教程:将笔记本与 Apache Spark 配合使用来查询 KQL 数据库
笔记本既是包含数据分析说明和结果的可读文档,又是可用于执行数据分析的可执行文档。 本文介绍如何使用 Microsoft Fabric 笔记本通过 Apache Spark 从 KQL 数据库读取数据和向其写入数据。 本教程在 Microsoft Fabric 的 Real-Time Intelligence 和数据工程环境中使用预先创建的数据集和笔记本。 有关笔记本的详细信息,请参阅如何使用 Microsoft Fabric 笔记本。
具体来说,你将学习如何:
- 创建 KQL 数据库
- 导入笔记本
- 使用 Apache Spark 将数据写入 KQL 数据库
- 从 KQL 数据库查询数据
先决条件
1- 创建 KQL 数据库
打开导航窗格底部的体验开关,然后选择“Real-Time Intelligence”。
选择“KQL 数据库”磁贴。
在“KQL 数据库名称”字段中,输入 nycGreenTaxi,然后选择“创建”。
现已在所选工作区的上下文中创建了 KQL 数据库。
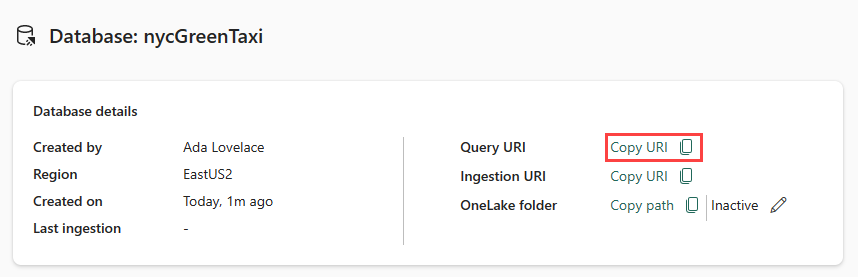
复制数据库仪表板中数据库详细信息卡的查询 URI,并将其粘贴到某个位置,如记事本,以用于后续步骤。
2- 下载 NYC GreenTaxi 笔记本
我们创建了一个示例笔记本,用于指导你完成使用 Spark 连接器将数据加载到数据库中的所有必要步骤。
打开 GitHub 上的 Fabric 示例存储库,以下载 NYC GreenTaxi KQL 笔记本。
将笔记本保存到设备本地。
注意
笔记本必须以
.ipynb文件格式保存。

3- 导入笔记本
此工作流的其余部分在产品的数据工程部分进行,并使用 Spark 笔记本在 KQL 数据库中加载和查询数据。
打开导航窗格底部的体验切换器,然后选择“数据工程”。
选择导入笔记本。
在“导入状态”窗口中选择“上传”。
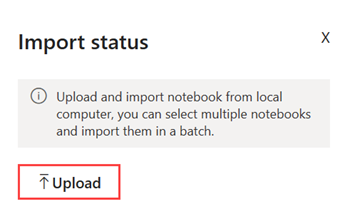
选择在上一步中下载的 NYC GreenTaxi 笔记本。
导入完成后,返回到工作区以打开此笔记本。
4 - 获取数据
若要使用 Spark 连接器查询数据库,需要授予对 NYC GreenTaxi Blob 容器的读取和写入访问权限。
选择“播放”按钮运行以下单元格,或选择单元格并按 Shift+ Enter。 对每个代码单元格重复此步骤。
注意
等待完成检查标记出现,然后运行下一个单元格。
运行以下单元格以启用对 NYC GreenTaxi Blob 容器的访问。
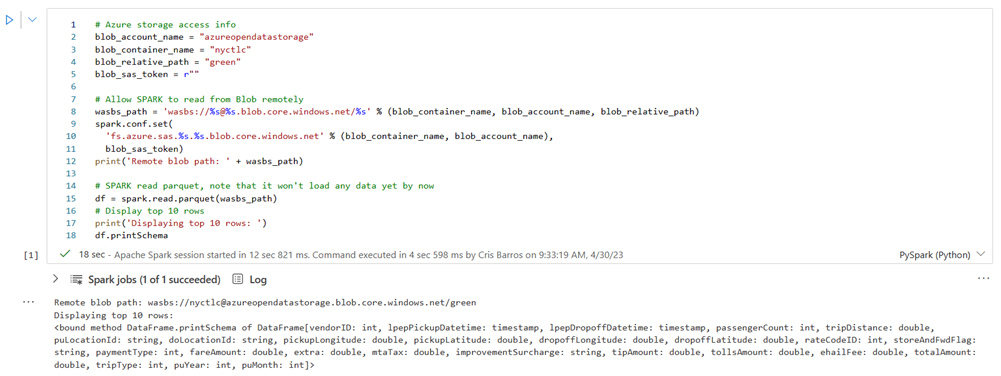
在 KustoURI 中,粘贴之前复制的查询 URI,而不是占位符文本。
将占位符数据库名称更改为 nycGreenTaxi。
将占位符表名称更改为 GreenTaxiData。

运行该单元。
运行下一个单元格,将数据写入数据库。 可能需要几分钟时间才能完成此步骤。




数据库现在已将数据加载到名为 GreenTaxiData 的表中。
5- 运行笔记本
按顺序运行剩余的两个单元格,以查询表中的数据。 结果显示按年份记录的前 20 个最高及最低出租车费和距离。

6- 清理资源
通过导航到在其中创建项的工作区来清理创建的项。
在工作区中,将鼠标悬停在要删除的笔记本上,选择“更多”菜单 [...] >“删除”。
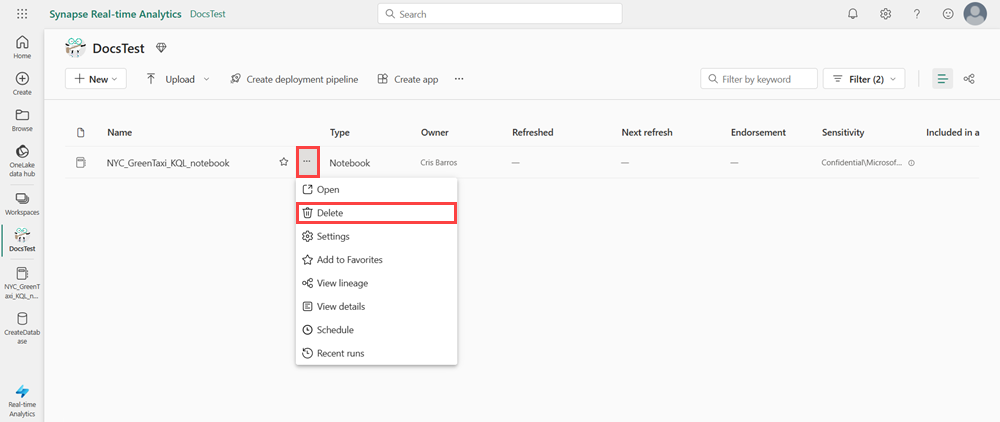
选择“删除” 。 笔记本在删除后无法恢复。
