将 Dataverse 数据复制到 Azure SQL
使用 Azure Synapse Link 将 Microsoft Dataverse 数据连接到 Azure Synapse Analytics,以探索数据并加快获得见解的速度。 本文介绍如何运行 Azure Synapse 管道或 Azure 数据工厂,将数据从 Azure Data Lake Storage Gen2 复制到 Azure SQL 数据库,并在 Azure Synapse Link 中启用增量更新功能。
备注
Azure Synapse Link for Microsoft Dataverse 以前称为“导出到 Data Lake”。 此服务已更名,从 2021 年 5 月起生效,它会继续将数据导出到 Azure Data Lake 以及 Azure Synapse Analytics。 此模板是一个代码示例。 我们鼓励您使用此模板作为指导,以测试使用提供的管道将数据从 Azure Data Lake Storage Gen2 检索到 Azure SQL 数据库的功能。
先决条件
- Azure Synapse Link for Dataverse。 本指南假定您已经满足创建 Azure Data Lake 的 Azure Synapse Link 的先决条件。 更多信息:Azure Data Lake 的 Azure Synapse Link for Dataverse 的先决条件
- 在与 Power Apps 租户相同的 Microsoft Entra 租户下创建 Azure Synapse Workspace 或 Azure 数据工厂。
- 创建 Azure Synapse Link for Dataverse 并启用增量文件夹更新以设置时间间隔。 详细信息:查询和分析增量更新
- 需要为触发器注册 Microsoft.EventGrid 提供程序。 详细信息:Azure 门户。 注意:如果您在 Azure Synapse Analytics 中使用此功能,请确保您的订阅也在数据工厂资源提供程序中注册,否则您将收到错误,指示创建“事件订阅”失败。
- 创建 Azure SQL 数据库并启用允许 Azure 服务和资源访问此服务器属性。 详细信息:设置 Azure SQL 数据库 (PaaS) 时我应该知道什么?
- 创建和配置 Azure Integration Runtime。 详细信息:创建 Azure Integration Runtime - Azure 数据工厂和 Azure Synapse
重要
使用此模板可能会额外增加成本。 这些成本与 Azure 数据工厂或 Synapse 工作区管道的使用有关,并按月计费。 使用管道的成本主要取决于增量更新的时间间隔和数据量。 若要计划和管理使用此功能的成本,请转到:通过成本分析在管道级别监控成本
在决定使用此模板时,请务必考虑这些额外成本,因为它们不是可选成本,必须支付才能继续使用此功能。
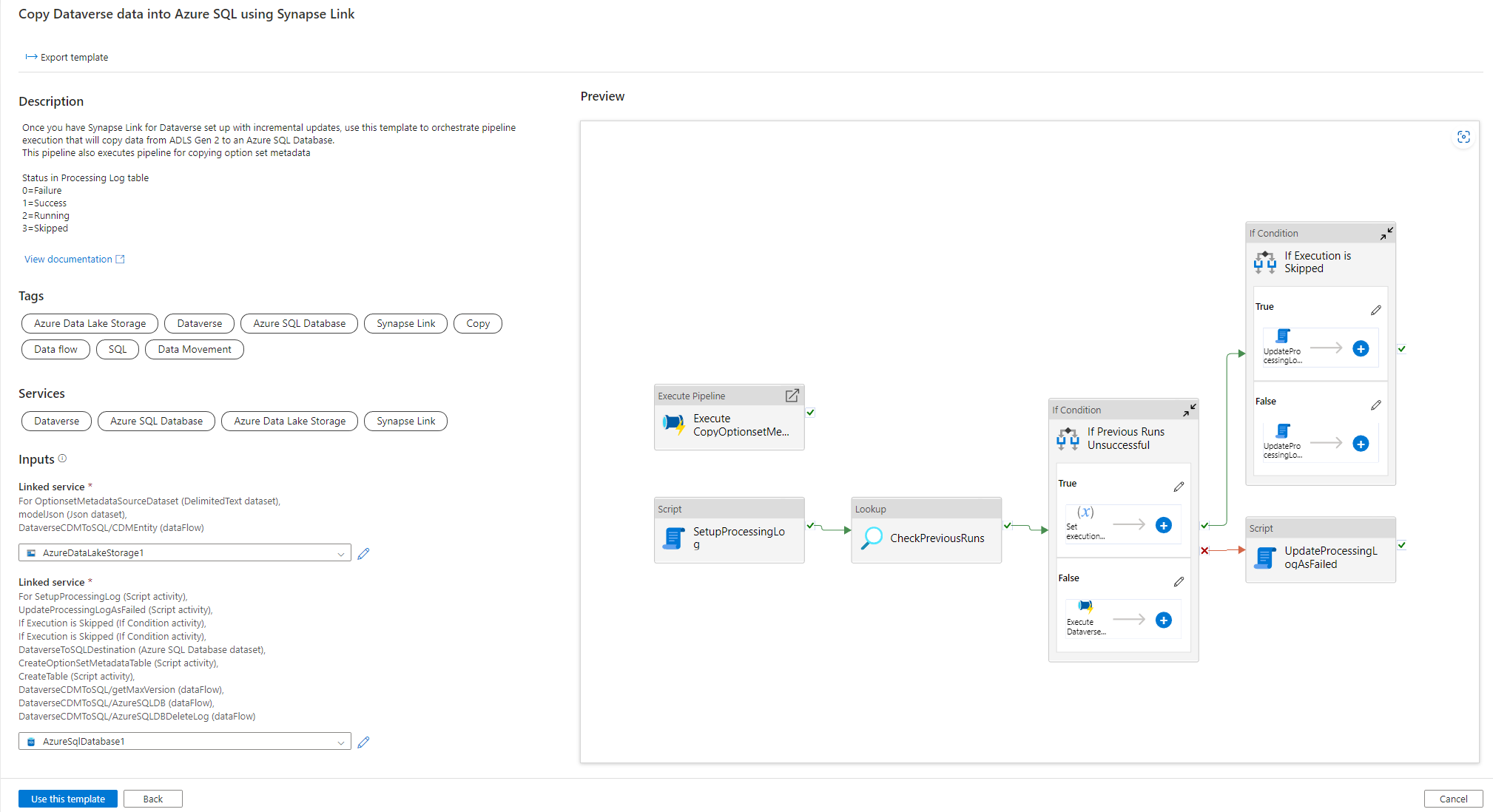
使用解决方案模板
- 转到 Azure 门户并打开 Azure Synapse workspace。
- 选择集成 > 浏览库。
- 从集成库中选择使用 Synapse Link 将 Dataverse 数据复制到 Azure SQL。
配置解决方案模板
创建链接至 Azure Data Lake Storage Gen2 的服务,前者使用适当身份验证类型连接到了 Dataverse。 为此,请选择测试连接以验证连接,然后选择创建。
与上述步骤类似,创建一个链接至 Azure SQL 数据库的服务,Dataverse 数据将在其中同步。
配置输入之后,请选择使用此模板。
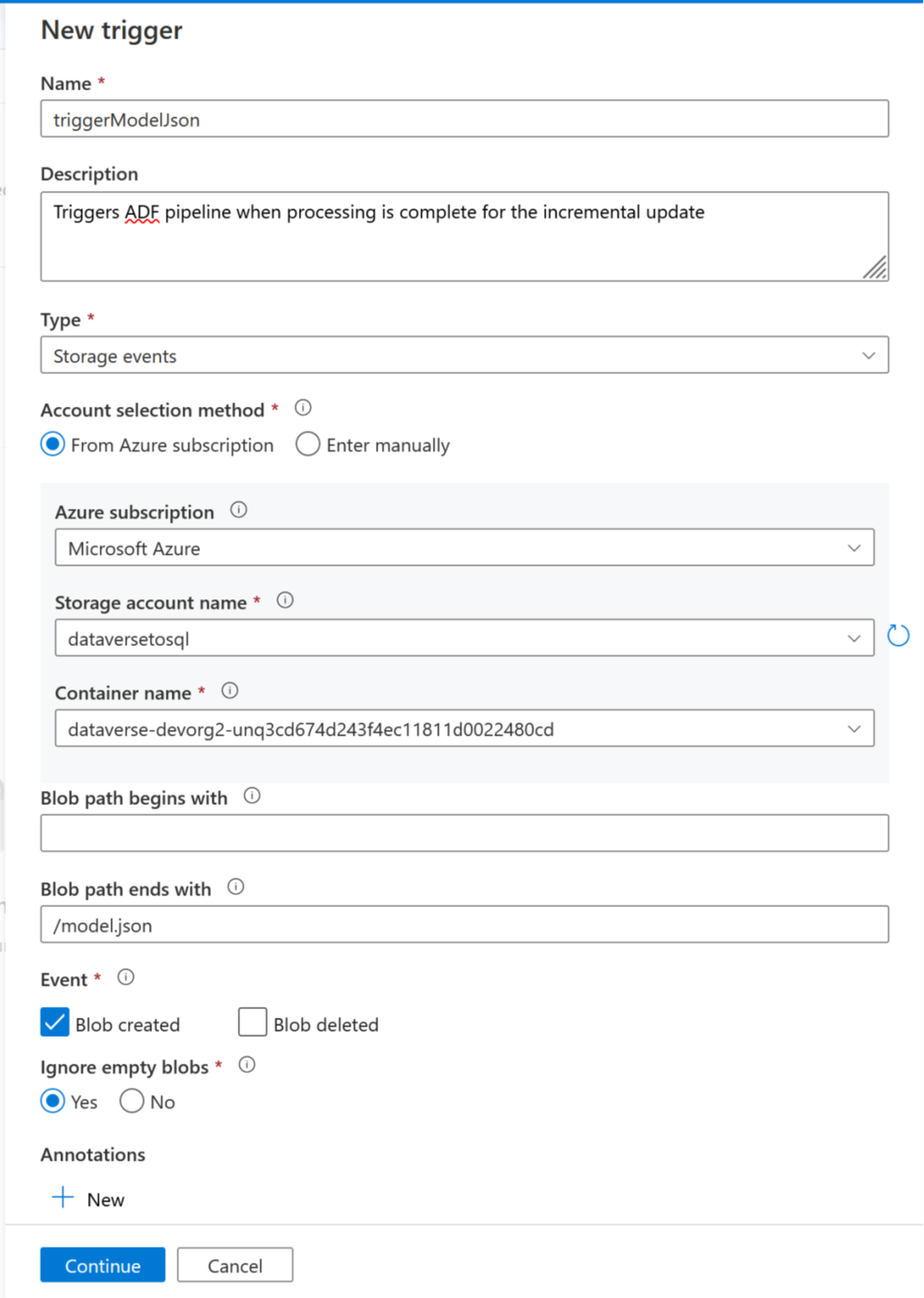
现在,可以添加触发器来自动执行此管道,以便当定期完成增量更新时,该管道始终可以处理文件。 转到管理 > 触发器,然后使用以下属性创建一个触发器:
- 名称:输入触发器的名称,例如 triggerModelJson。
- 类型:存储事件。
- Azure 订阅:选择具有 Azure Data Lake Storage Gen2 的订阅。
- 存储帐户名称:选择有 Dataverse 数据的存储。
- 容器名称:选择由 Azure Synapse Link 创建的容器。
- Blob 路径的结尾为:/model.json
- 事件:已创建 Blob。
- 忽略空 Blob:是。
- 启动触发器:启用创建时启动触发器。
选择继续以进入到下一个屏幕。
在下一个屏幕上,触发器将验证匹配文件。 选择确定,创建触发器。
将触发器与管道关联。 转到前面导入的管道,然后选择添加触发器 > 新建/编辑。
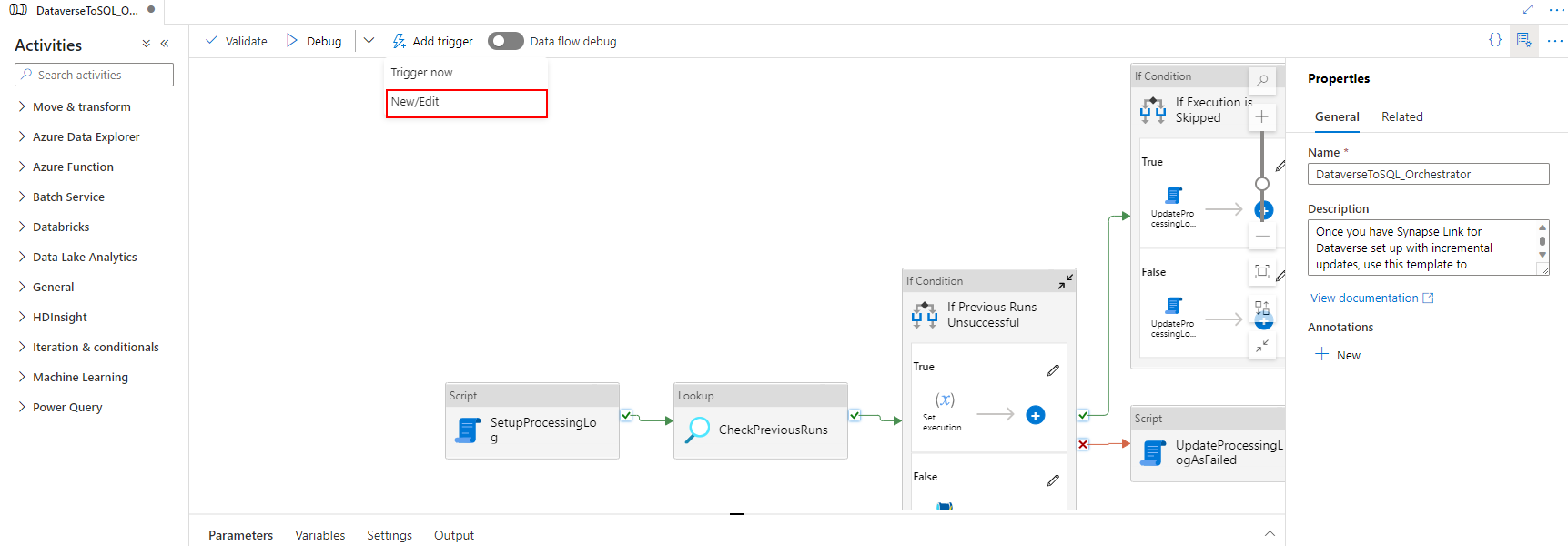
选择前面步骤中的触发器,然后选择继续以进入到下一个屏幕,触发器将在其中验证匹配文件。
选择继续以进入到下一个屏幕。
在触发器运行参数部分,输入以下参数,然后选择确定。
- 容器:
@split(triggerBody().folderPath,'/')[0] - 文件夹:
@split(triggerBody().folderPath,'/')[1]
- 容器:
将触发器与管道关联后,选择全部验证。
验证成功后,请选择全部发布。
选择发布以发布所有更改。



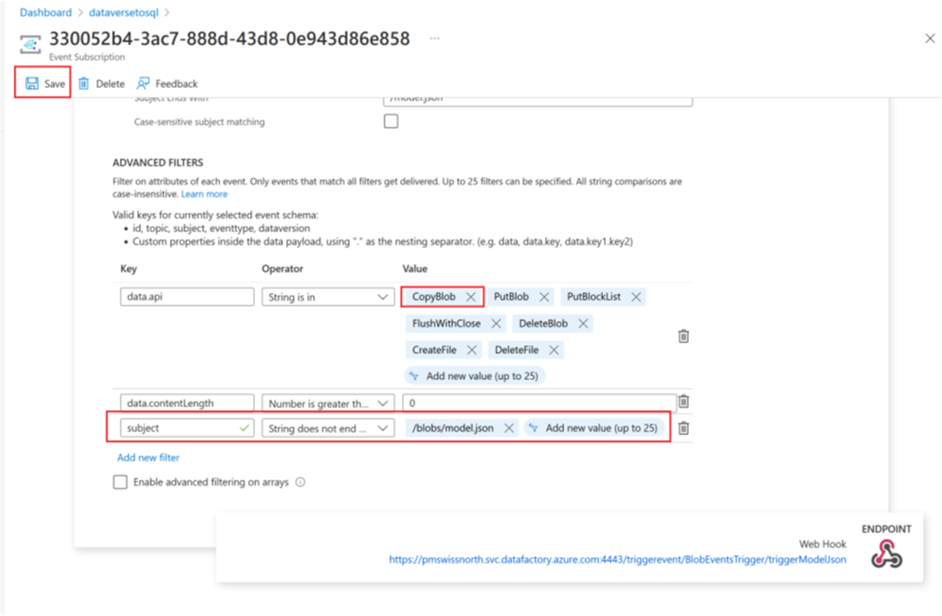
添加事件订阅筛选器
若要确保仅在 model.json 创建完成时启动触发器,需要为触发器的事件订阅更新高级筛选器。 首次运行触发器时,会针对存储帐户注册事件。
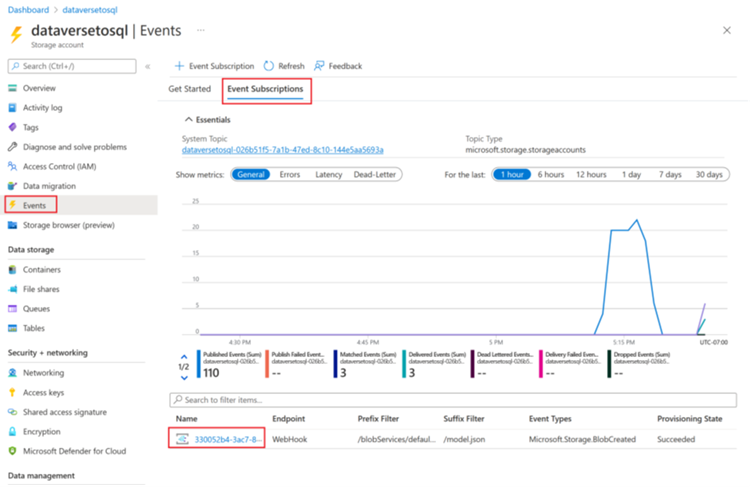
触发器运行完成后,转到存储帐户 > 事件 > 事件订阅。
选择为 model.json 触发器注册的事件。
选择触发器选项卡,然后选择添加新筛选器。
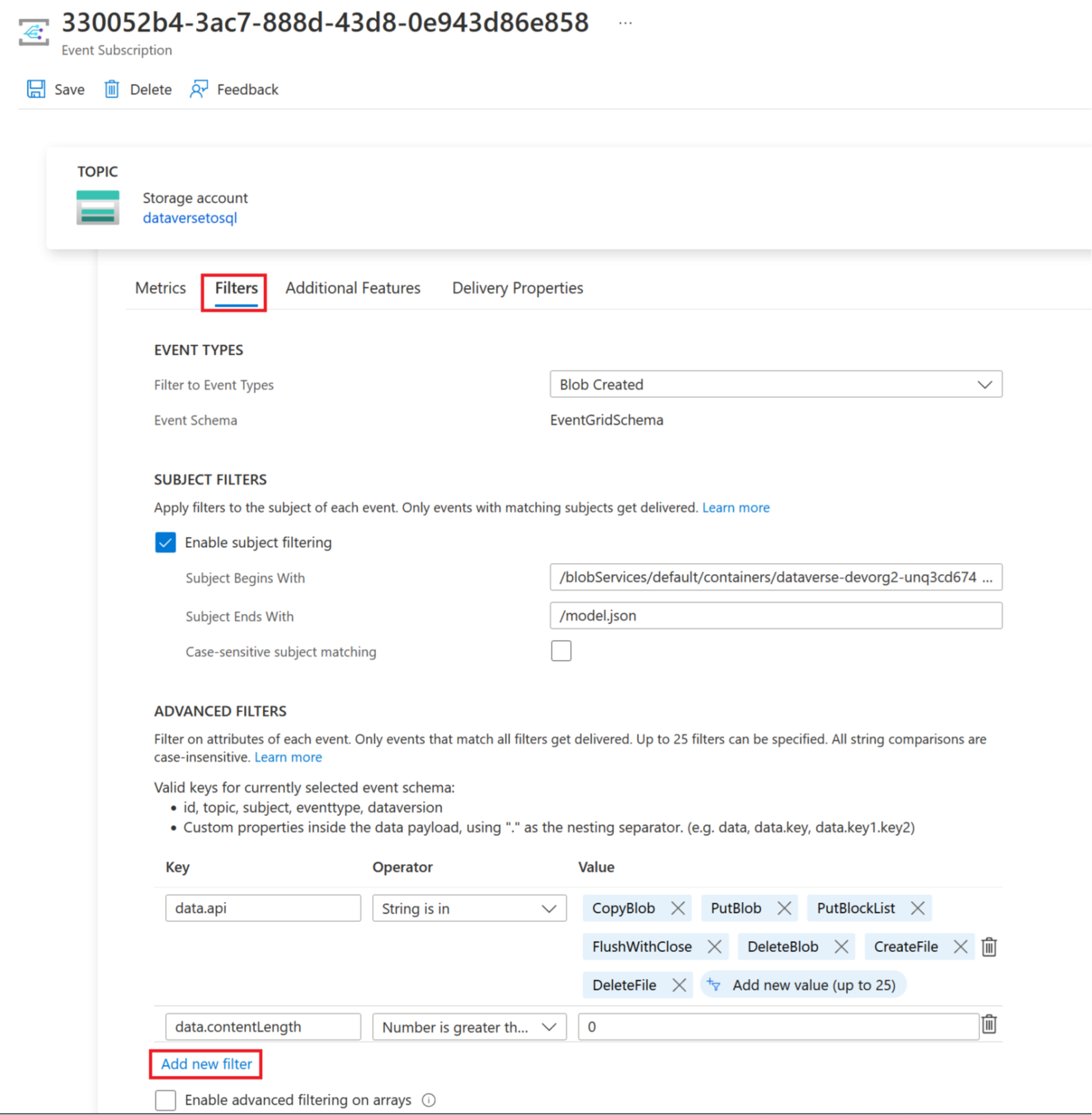
创建筛选器:
- 键:主题
- 运算符:字符串不以此为结尾
- 值:/blobs/model.json
从 data.api 值数组中删除 CopyBlob 参数。
选择保存以部署其他筛选器。