威胁建模 AI/ML 系统和依赖项
作者:Andrew Marshall、Jugal Parikh、Emre Kiciman 和 Ram Shankar Siva Kumar
特别感谢 Raul Rojas 和 AETHER 安全工程工作流程
2019 年 11 月
本文档是针对 AI 工作组的 AETHER 工程实践的可交付结果,并通过提供有关特定于 AI 和机器学习领域的威胁枚举和缓解措施的新指导来补充现有的 SDL 威胁建模做法。 在安全设计审查以下内容的过程中,它将用作参考:
与 AI/ML 服务交互或依赖于 AI/ML 服务的产品/服务
使用 AI/ML 在核心上构建的产品/服务
传统的安全威胁缓解措施比以往更重要。 安全开发生命周期建立的要求是建立制定本指南的产品安全基础所必需的。 无法解决传统安全威胁的问题有助于实现本文档中所述的软件和物理域中的 AI/ML 特定攻击,并使入侵轻微降低软件堆栈。 有关此领域中的全新安全威胁的介绍,请参阅在 Microsoft 保护 AI 和 ML 的未来。
安全工程师和数据科学家的技能组通常不会重叠。 本指南提供了一种方法,使这两个学科针对这些全新的威胁/缓解措施进行结构性交流,而不要求安全工程师成为数据科学家,反之亦然。
本文档分为两个部分:
- “威胁建模中的重要新注意事项”重点介绍了在威胁建模 AI/ML 系统时要考虑的新思考方法和要提出的新问题。 数据科学家和安全工程师都应该查看此内容,因为它会成为威胁建模讨论和缓解措施优先级的 playbook。
- “AI/ML 特定的威胁及其缓解措施”提供了有关特定攻击的详细信息,以及目前使用的用于防止 Microsoft 产品和服务受到这些威胁的特定缓解步骤。 本部分主要面向数据科学家,他们可能需要实施特定的威胁缓解措施作为威胁建模/安全审查过程的输出。
本指南围绕由 Ram Shankar Siva Kumar、David O’Brien、Kendra Albert、Salome Viljoen 和 Jeffrey Snover 创建的对抗机器学习威胁分类,名为“机器学习中的故障模式”。 有关本文档中详细说明的有关会审安全威胁的事件管理指南,请参阅 AI/ML 威胁的 SDL Bug 条。所有这些都是动态文档,将随着时间的推移而不断更新威胁概况。
威胁建模中重要的新注意事项:改变对信任边界的看法
假设入侵/中毒攻击用于训练的数据以及数据提供方。 了解如何检测异常和恶意数据条目,以及能否区分和恢复它们
总结
训练数据存储和托管这些存储的系统是威胁建模范围的一部分。 目前机器学习面临的最大安全威胁是数据中毒(因为这一领域缺少标准检测和缓解措施),以及对作为训练数据源的不受信任/非策展公共数据集的依赖。 跟踪数据的来源和沿袭对于确保数据的可信度和避免“无用输入,无用输出”训练周期至关重要。
要在安全审查中提出的问题
如果你的数据中毒或被篡改,你如何知道呢?
- 你需要什么遥测技术才能检测出训练数据质量的偏差?
你是否从用户提供的输入进行训练?
- 对该内容执行何种类型的输入验证/清理?
- 此数据的结构是否与数据集的数据表类似?
如果你对联机数据存储进行训练,你采取哪些步骤来确保你的模型与数据之间的连接安全?
- 他们是否有一种向其源使用者报告入侵的方式?
-他们能否这样做?
你训练的数据敏感程度如何?
- 是否要对其进行编目或控制数据条目的添加/更新/删除?
你的模型是否可以输出敏感数据?
- 是否通过源的权限获取了此数据?
模型是否只输出实现其目标所需的结果?
你的模型是返回原始置信度分数还是任何其他可以记录和复制的直接输出?
通过攻击/反转模型恢复训练数据有哪些影响?
如果你的模型输出的置信度突然下降,你是否可以找出程度/原因以及导致此问题的数据?
是否为模型定义了格式正确的输入? 你要做什么以确保输入满足此格式要求,如果不满足要求,该怎么办?
如果输出错误,但未导致报告错误,你如何知道?
你能否判断训练算法是否可以灵活应对数学级别的对抗输入?
如何从对抗污染恢复训练数据?
- 能否隔离对抗性内容并重新训练受影响的模型?
- 能否回滚/恢复到模型的以前版本以进行重新训练?
是否对非策展公共内容使用强化学习?
开始思考你的数据的沿袭 - 你是否找到了问题,你是否可以跟踪到其何时引入数据集? 如果否,这是否是个问题?
了解训练数据的来源并标识统计常模,以开始了解异常
- 你的训练数据的哪些元素容易受到外部影响?
- 谁可以对用于训练的数据集做出贡献?
- 你如何攻击你的训练数据源以损害竞争对手?
本文档中的相关威胁和缓解措施
对抗扰动(所有变体)
数据中毒(所有变体)
示例攻击
强制将良性电子邮件归类为垃圾邮件,或使恶意示例无法被检测到
攻击者设计的输入可以降低正确分类的置信度,尤其是在高后果应用场景中
攻击者会将干扰随机注入被分类的源数据,以降低将来使用的正确分类的可能性,有效地弱智化模型
训练数据的污染强制错误分类选择的数据点,从而导致系统执行或省略特定操作
确定你的模型或产品/服务可能会采取的操作,此操作可能导致在线或物理领域的客户损害
总结
在 AI/ML 系统上保留未缓解的攻击可以在现实世界中找到自己的方式。 任何可能扭曲用户心理或伤害用户身体的情况,都会对你的产品/服务造成灾难性的风险。 这将扩展到用于训练的客户数据,以及可能泄露这些私有数据点的设计选择。
要在安全审查中提出的问题
你是否使用对抗示例进行训练? 它们对物理域中的模型输出有何影响?
对你的产品/服务而言恶意评论看起来像什么? 如何检测并响应它?
要使你的模型返回导致服务拒绝访问合法用户的结果,会采取什么操作?
你的模型被复制/被盗有何影响?
你的模型是否可用于推断个人在特定组中或仅在训练数据中的成员资格?
攻击者是否会通过强制执行特定操作来导致信誉受损或 PR 抵制你的产品?
如何处理格式正确但明显有偏差的数据(如来自挑衅者的数据)?
由于与模型交互或查询模型的每种方式已公开,是否可以询问该方法来泄露训练数据或模型功能?
本文档中的相关威胁和缓解措施
成员资格推理
模型反演
模型偷窃
示例攻击
重复查询模型以获得最大置信度结果,从而重构和提取训练数据
通过详尽查询/响应匹配复制模型本身
以显示专用数据的特定元素包含在训练集中的方式查询模型
自动驾驶汽车可以被欺骗,并忽视停车标志/交通信号灯
操作以恶意评论良性用户的聊天机器人
标识 AI/ML 依赖关系的所有源以及数据/模型供应链中的前端表示层
总结
AI 和机器学习中的许多攻击都是以合法的方式访问 API,从而提供对模型的查询访问权限。 由于本文所述的丰富数据源和丰富用户体验,经过身份验证但“不适合”(此处有一个灰色区域)的第三方访问你的模型存在风险,因为其能够充当 Microsoft 提供的服务上的表示层。
要在安全审查中提出的问题
哪些客户/合作伙伴已通过身份验证可访问你的模型或服务 API?
- 他们是否可以充当你的服务之上的表示层?
- 是否可以在被入侵时立即撤销其访问权限?
- 如果恶意使用你的服务或依赖关系,你的恢复策略是什么?
第三方是否可以基于你的模型构建外观,以便重复使用它并损害 Microsoft 或其客户?
客户是否向你直接提供训练数据?
- 你如何保护这些数据?
- 如果它是恶意的并且你的服务是目标?
什么是误报? 误报有哪些影响?
你是否可以跟踪和度量跨多个模型的真阳值与误报率的偏差?
需要哪种类型的遥测向客户证明模型输出的可信度?
确定 ML/训练数据供应链中的所有第三方依赖关系 - 不仅包括开源软件,还包括数据提供方
- 为什么要使用它们以及如何验证其可信度?
是使用第三方的预建模型还是将训练数据提交到第三方 MLaaS 提供方?
列出有关对类似产品/服务的攻击的新闻故事。 了解许多 AI/ML 威胁在模型类型之间传输,这些攻击对你自己的产品会产生什么影响?
本文档中的相关威胁和缓解措施
神经网络重新编程
物理领域中的对抗示例
恶意 ML 提供方恢复训练数据
攻击 ML 供应链
带后门的模型
被入侵的 ML 特定依赖关系
示例攻击
恶意 MLaaS 提供方使用特定的绕过以特洛伊木马攻击你的模型
对手客户发现你使用的常见 OSS 依赖关系中的漏洞,上传设计好的训练数据有效载荷以入侵你的服务
不道德的合作伙伴使用面部识别 API,并通过服务创建表示层以生成深层假脸。
AI/ML 特定的威胁及其缓解措施
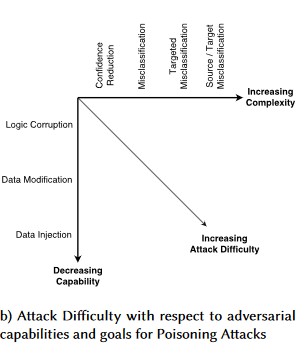
#1:对抗扰动
说明
在扰动型攻击中,攻击者秘密修改查询以从生产部署模型获得所需响应[1]。 这是对模型输入完整性的破坏,会导致模糊式攻击,最终结果不一定是访问冲突或 EOP,而是损害模型的分类性能。 挑衅者使用 AI 会禁止的某些目标字词,有效地拒绝向名称与“已禁止”字词相匹配的合法用户提供服务,这也证实了这一点。
 [24]
[24]
变体 #1a:目标错误分类
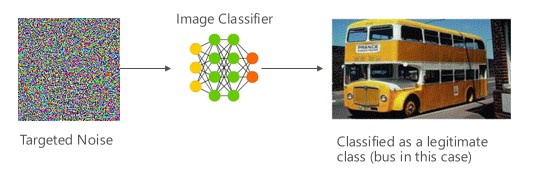
在这种情况下,攻击者会生成一个不在目标分类器的输入类中的示例,但会按照该特定输入类由模型对其进行分类。 对抗示例可能类似于对用户眼睛的随机干扰,但攻击者对目标机器学习系统有一定的了解,以生成不是随机的、但利用目标模型的某些特定方面的白色噪音。 攻击者提供了一个不是合法示例的输入示例,但目标系统会将其分类为合法类。
示例
 [6]
[6]
缓解措施
使用对抗训练引发的模型置信度加强对抗鲁棒性 [19]:作者建议使用高度可信近邻 (HCNN),这是一个结合了置信度信息和最近邻搜索的框架,用于强化基础模型的对抗鲁棒性。 这有助于区分从基础训练分布采样的点邻域的正确和错误模型预测。
归因驱动的因果分析 [20]:作者研究了对抗扰动的复原能力与对机器学习模型生成的各种决策的基于归因的解释之间的联系。 他们报告说,对抗输入在归因领域并不可靠,也就是说,用高归因掩盖一些特征会导致机器学习模型在对抗示例上发生变化的不确定性。 与此相反,自然输入在归因领域是可靠的。
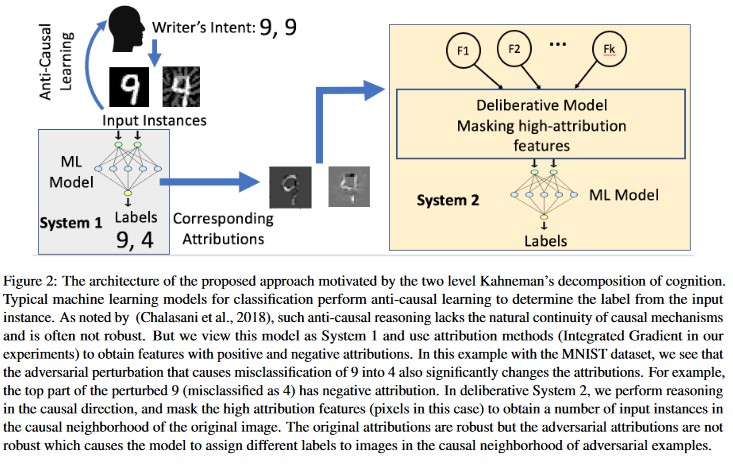 [20]
[20]
利用这些方法,机器学习模型可以更灵活地应对对抗攻击,因为诱骗此两层认知系统不仅需要攻击原始模型,还需要确保为对抗示例生成的归因与原始示例相似。 为了成功地进行对抗性攻击,必须同时入侵这两个系统。
传统相似物
远程特权提升,因为攻击者现已控制你的模型
Severity
严重
变体 #1b:源/目标错误分类
这种方法的特征是攻击者尝试让一个模型返回给定输入所需的标签。 这通常会强制模型返回误报或漏报。 最终结果是巧妙接管模型的分类准确性,使得攻击者能够随意导致特定绕过。
虽然这种攻击对分类准确性有重大影响,但它也可能需要更多的时间来执行,因为对手不能仅对源数据进行操作(导致无法正确标记源数据),还可以专门使用所需的欺诈标签进行标记。 这些攻击通常涉及多个步骤/尝试强制错误分类 [3]。 如果模型容易受到强制目标错误分类的传输学习攻击,则可能没有可识别攻击者流量占用情况,因为探测攻击可以脱机执行。
示例
强制将良性电子邮件归类为垃圾邮件,或使恶意示例无法被检测到。 这也称为模型逃逸或拟态攻击。
缓解措施
反应式/防御性检测操作
- 在提供分类结果的 API 调用之间实现最小时间阈值。 这会增加查找成功扰动所需的总时间,从而减慢多步攻击测试。
主动式/保护性操作
特征去噪以提高对抗鲁棒性 [22]:作者开发了一种新的网络体系结构,该体系结构通过执行特征去噪来提高对抗鲁棒性。 具体而言,网络包含使用非本地方法或其他筛选器去噪特征的块;整个网络经过端到端训练。 当与对抗性训练相结合时,特征去噪网络可在白盒和黑盒攻击设置中显著提高最新的对抗鲁棒性。
对抗性训练与正则化:使用已知的对抗性示例进行训练,以建立抵御恶意输入的复原能力和鲁棒性。 这也可能被视为一种正则化形式,它将惩罚输入梯度规范化,并使分类器的预测功能更平滑(增加输入边距)。 这包括具有更低置信度的正确分类。
通过选择单调特征,投资开发单调分类。 这可确保对手只需通过从被动类填充特征即可规避分类器 [13]。
可通过检测对抗性示例使用特征挤压 [18] 强化 DNN 模型。 它通过将对应于原始空间中的许多不同特征向量的样本合并为单个样本,减少了对手可用的搜索空间。 通过将 DNN 模型对原始输入的预测与对挤压输入的预测进行比较,特征挤压可以帮助检测对抗示例。 如果原始示例和挤压后的示例从模型生成的输出大不相同,则输入可能是对抗性的。 通过度量预测之间的不一致并选择阈值,系统可以为合法示例输出正确的预测,并拒绝对抗输入。

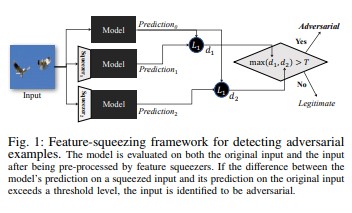 [18]
[18]针对对抗示例的认证防御 [22]:作者根据半正定松弛提议一个方法,该方法可输出给定网络和测试输入的证书,没有任何攻击可强制错误超过特定值。 其次,由于此证书是可微的,因此作者会将其与网络参数一起进行优化,并提供自适应正则化项来鼓励针对所有攻击的鲁棒性。
响应操作
- 对分类器之间具有较大方差的分类结果发出警报,尤其是在来自单个用户或一小组用户时。
传统相似物
远程特权提升
Severity
严重
变体 #1c:随机错误分类
这是一种特殊的变化,其中,攻击者的目标分类可以是合法源分类以外的任何内容。 攻击通常涉及将干扰随机注入源数据,以降低未来使用正确分类的可能性 [3]。
示例
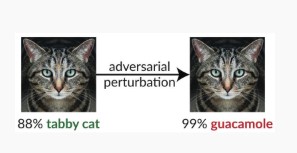
缓解措施
与变体 1a 相同。
传统相似物
非永久性拒绝服务
Severity
重要
变体 #1d:置信度降低
攻击者可以设计输入以降低正确分类的置信度,尤其是在高后果应用场景中。 这也可能采用大量误报的形式,这些误报的目的是让管理员或监控系统无法区分合法警报和欺诈警报 [3]。
示例

缓解措施
- 除了变体 #1a 中涵盖的操作,还可以使用事件限制来减少单个源的警报量。
传统相似物
非永久性拒绝服务
Severity
重要
#2a 目标数据中毒
说明
攻击者的目标是污染在训练阶段生成的机器模型,以在测试阶段修改对新数据的预测[1]。 在定向中毒攻击中,攻击者试图对特定示例进行错误分类,从而导致采取或忽略特定操作。
示例
将 AV 软件作为恶意软件提交,以强制将其误分类为恶意软件,并消除在客户端系统上使用目标 AV 软件的情况。
缓解措施
定义异常传感器,以查看每天的数据分布,并在变化时发出警报
- 每天度量训练数据变化(倾斜/偏移遥测)
输入验证(清理和完整性检查)
中毒注入外训练示例。 对抗这一威胁的两个主要策略是:
- 数据清理/验证:从训练数据中移除中毒示例 - 装袋以用于反击中毒攻击 [14]
- 拒绝负面影响 (RONI) 防御 [15]
- 可靠的学习:选择在存在中毒示例时可靠的学习算法。
-在 [21] 中介绍了这样一种方法,其中作者通过两个步骤解决了数据中毒问题:1) 引入了新型可靠矩阵因子分解方法来恢复真正的子空间,以及 2)新型可靠的主成分回归,根据步骤 (1) 中恢复的基础修剪对抗实例。 它们描述了成功恢复真正的子空间的必要和足够的条件,并介绍了与真实情况相比预期预测损失的限制。
传统相似物
特洛伊木马攻击的主机,其中攻击者会留在网络上。 训练或配置数据被入侵,并为创建模型引入/受信任。
Severity
严重
#2b 任意数据中毒
说明
目标是破坏受攻击的数据集的质量/完整性。 许多数据集是公共/不受信任/非策展的,因此,这会导致在第一次发现此类数据完整性违规的能力方面产生额外的问题。 训练无意被入侵的数据是“无用输入,无用输出”的情形。 检测到之后,会审需要确定已被破坏、隔离/重新训练的数据范围。
示例
一家公司在一个值得信赖的知名网站上搜集原油期货数据来训练他们的模型。 数据提供方的网站随后通过 SQL 注入攻击遭到破坏。 攻击者可以随意毒害数据集,而正在训练的模型并不知道数据已被感染。
缓解措施
与变体 2a 相同。
传统相似物
针对高价值资产的经过身份验证的拒绝服务
Severity
重要
#3 模型反演攻击
说明
机器学习模型中使用的专用特征可以恢复 [1]。 这包括重建攻击者无权访问的专用训练数据。 在生物识别社区中也称为爬山法攻击 [16、17]。这是通过查找可最大化返回的置信度的输入来实现的,取决于与目标匹配的分类 [4]。
示例
 [4]
[4]
缓解措施
从敏感数据训练的模型的接口需要强访问控制。
模型允许的速率-限制查询
通过对所有建议的查询执行输入验证,拒绝不满足模型的输入正确性定义要求的任何内容,并仅返回有用所需的最少信息,来实现用户/调用方与实际模型之间的入口。
传统相似物
目标、转换信息泄露
Severity
这对于每个标准 SDL bug 条来说默认都是重要的,但提取的敏感数据或个人身份数据会将其提升为严重。
#4 成员资格推理攻击
说明
攻击者可以确定给定的数据记录是否是模型的训练数据集的一部分[1]。 研究人员能够根据各种属性(例如年龄、性别、医院)预测患者的主要手术(例如:患者经历的外科手术)[1]。
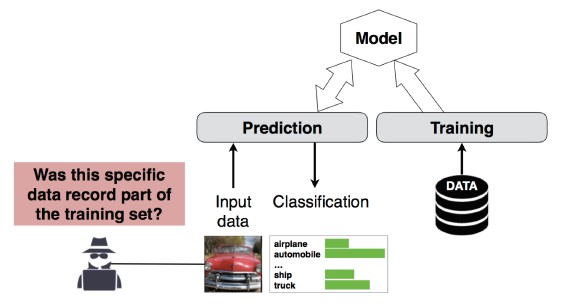 [12]
[12]
缓解措施
说明此攻击可行性的研究论文表明,差异隐私 [4、9] 将是一种有效的缓解措施。 Microsoft 刚刚开始研究这一领域,AETHER 安全工程团队建议在此领域内使用研究投资培养专业技能。 此调查需要枚举差异化隐私功能,并评估其作为缓解措施的实际效果,然后设计在联机服务平台上以透明方式继承这些防御的方法,类似于 Visual Studio 中的编译代码如何提供对开发人员和用户透明的默认启用的安全保护。
使用神经元随机失活和模型堆栈可以有效地缓解范围。 使用神经元随机失活不仅会提高此攻击的神经网络的复原能力,还会增加模型的性能 [4]。
传统相似物
数据隐私。 正在对训练集中的数据点包含进行推断,但不会泄露训练数据本身
Severity
这是一个隐私问题,而不是一个安全问题。 它在威胁建模指南中得到了解决,因为域重叠,但此处的任何响应都是由隐私而非安全驱动的。
#5 模型偷窃
说明
攻击者通过合法查询模型来重新创建底层模型。 新模型的功能与基础模型的功能相同[1]。 重新创建模型后,可以对其进行反演以恢复特征信息或对训练数据进行推理。
公式求解 - 对于通过 API 输出返回类概率的模型,攻击者可以创建查询来确定模型中的未知变量。
路径查找 - 一种攻击方式,攻击者利用 API 特殊性来提取目录树在对输入进行分类时所做出的“决策”[7]。
可转移性攻击 - 攻击者可以训练本地模型(可能是通过向目标模型发出预测查询),并用它来创建转移到目标模型的对抗示例[8]。 如果攻击者提取到你的模型并发现其易受某种类型的对抗输入的攻击,则提取模型副本的攻击者可以完全脱机开发针对生产部署模型的新攻击。
示例
在 ML 模型用于检测对抗行为的设置(如识别垃圾邮件、恶意软件分类和网络异常检测)中,模型提取可以辅助逃逸攻击[7]。
缓解措施
主动式/保护性操作
最大程度地减少或模糊预测 API 中返回的详细信息,同时仍保持其对“诚实”的应用程序的有用性 [7]。
为模型输入定义格式正确的查询并仅返回结果,以响应与该格式匹配的已完成且格式正确的输入。
返回舍入的置信度值。 大多数合法调用方无需多小数位数的精度。
传统相似物
未经身份验证、对系统数据的只读篡改、目标高价值信息泄露?
Severity
重要(在安全敏感模型中),中等(其他)
#6 神经网络重新编程
说明
通过攻击者特别设计的查询,机器学习系统可能被重新编程为一个偏离创建者初衷的任务 [1]。
示例
面部识别 API 上的弱访问控制使第三方能够合并到旨在损害 Microsoft 用户的应用,如深层假脸生成器。
缓解措施
强客户端<->服务器相互身份验证和对模型接口的访问控制
撤销有问题的帐户。
为 API 标识并强制实施服务级协议。 确定已报告问题的可接受修复时间,并确保在 SLA 过期后该问题不再重现。
传统相似物
这是一种滥用情形。 在这种情况下,你不太可能打开安全事件,而只会禁用违规者的帐户。
Severity
重要到关键
#7 物理领域中的对抗示例(位->原子)
说明
对抗示例是来自恶意实体的输入/查询,发送它的唯一目的是误导机器学习系统 [1]
示例
这些示例可以在物理领域体现出来,例如,就像一辆自动驾驶的汽车由于某种颜色的光线(对抗输入)照射在停车标志上而被骗驶过停车标志,迫使图像识别系统不再将停车标志视为停车标志。
传统相似物
特权提升,远程执行代码
缓解措施
这些攻击清单本身因为机器学习层中的问题(AI 驱动的决策下的数据和算法层)未得到缓解。 与任何其他软件*或*物理系统一样,目标下的层始终可以通过传统媒介进行攻击。 因此,传统的安全做法比以往更重要,尤其是在 AI 和传统软件之间使用的未缓解漏洞层(数据/算法层)。
Severity
严重
#8 可恢复训练数据的恶意 ML 提供方
说明
恶意提供方展示一个带后门的算法,可用来恢复专用训练数据。 他们仅凭模型就能复原人脸和文本。
传统相似物
目标信息泄漏
缓解措施
说明此攻击可行性的研究论文表明,同态加密将是一种有效的缓解措施。 这是 Microsoft 当前投资较少的领域,AETHER 安全工程团队建议在此领域内使用研究投资培养专业技能。 此研究需要枚举同态加密原则,并评估其作为恶意 ML 即服务提供方缓解措施的实际效果。
Severity
重要(如果数据为 PII),中等(其他情况)
#9 攻击 ML 供应链
说明
由于训练算法需要使用大量资源(数据 + 计算),因此目前的做法是重用大型公司训练的模型,并根据现有任务对已有模型稍加修改(例如:ResNet 是 Microsoft 提供的常用图像识别模型)。 这些模型是通过 Model Zoo(Caffe 托管常用图像识别模型)管理的。 在此类攻击中,攻击者会攻击 Caffe 中托管的模型,进而危及使用该模型的人的安全。 [1]
传统相似物
入侵第三方非安全依赖关系
无意托管恶意软件的应用商店
缓解措施
尽可能将模型和数据的第三方依赖关系降到最低。
将这些依赖关系纳入威胁建模过程。
在第一方/第三方系统之间利用强身份验证、访问控制和加密。
Severity
严重
#10 后门机器学习
说明
训练过程外包给恶意第三方,其篡改了训练数据,并提供了强制执行目标误分类的被特洛伊木马攻击的模型,例如将特定病毒分类为非恶意病毒 [1]。 这是 ML 即服务模型生成方案中的风险。
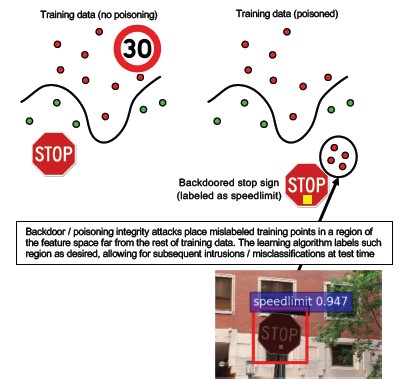 [12]
[12]
传统相似物
入侵第三方安全依赖关系
被入侵的软件更新机制
证书颁发机构入侵
缓解措施
反应式/防御性检测操作
- 发现此威胁时,损坏已完成,因此无法信任该模型以及恶意提供方提供的任何训练数据。
主动式/保护性操作
内部训练所有敏感模型
编目训练数据,或确保它来自具有强大安全做法的受信任的第三方
对 MLaaS 提供方与你自己的系统之间的交互威胁建模
响应操作
- 与入侵外部依赖关系相同
Severity
严重
#11 利用 ML 系统的软件依赖关系
说明
在此类攻击中,攻击者不会操纵算法, 而是利用软件漏洞,如缓冲区溢出或跨站点脚本[1]。 与直接攻击学习层相比,入侵 AI/ML 下的软件层更容易,因此“安全开发生命周期”中详细介绍的传统安全威胁缓解措施是必不可少的。
传统相似物
遭到入侵的开源软件依赖关系
Web 服务器漏洞(XSS、CSRF、API 输入验证失败)
缓解措施
与安全团队合作,遵循适用的安全开发生命周期/操作安全保障最佳实践。
Severity
最高为严重的变量,取决于传统软件漏洞的类型。
参考文献
[1] Failure Modes in Machine Learning, Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen, and Jeffrey Snover, https://video2.skills-academy.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Adversarial Examples in Deep Learning: Characterization and Divergence, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha, and T. Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures,” in Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Adversarial Examples in Machine Learning AIWTB 2017
[7] Stealing Machine Learning Models via Prediction APIs, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] The Space of Transferable Adversarial Examples, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh , and Patrick McDaniel
[9] Understanding Membership Inferences on Well-Generalized Learning Models Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 , and Kai Chen3,4
[10] Simon-Gabriel et al., Adversarial vulnerability of neural networks increases with input dimension, ArXiv 2018;
[11] Lyu et al., A unified gradient regularization family for adversarial examples, ICDM 2015
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto, and Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks
[15] An Improved Reject on Negative Impact Defense Hongjiang Li and Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. 5th Int’l Conf. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. 2018 Network and Distributed System Security Symposium. 18-21 February.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robust Linear Regression Against Training Data Poisoning – Chang Liu et al.
[22] Feature Denoising for Improving Adversarial Robustness, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certified Defenses against Adversarial Examples - Aditi Raghunathan, Jacob Steinhardt, Percy Liang