在计算选项之间决定
如果要训练自己的模型,将使用的最有价值的资源是计算。 特别是在模型训练期间,选择最合适的计算非常重要。 此外,还应监视计算利用率,以了解何时纵向扩展或缩减以节省时间和成本。
尽管查找最符合需求的虚拟机大小是一个迭代过程,但在开始开发时可以遵循一些准则。
CPU 或 GPU
配置计算时要做出的一个重要决定是要使用中央处理单元 (CPU) 还是图形处理单元 (GPU)。 对于较小的表格数据集,CPU 的使用就足够且成本更低。 每当使用非结构化数据(如图像或文本)时,GPU 将更强大且有效。
对于较大的表格数据量,使用 GPU 可能也会有所帮助。 处理数据和训练模型需要很长时间,即使有最大的 CPU 计算可用,也可能需要考虑改用 GPU 计算。 RAPID 等库(由 NVIDIA 开发)可用于使用较大的表格数据集高效执行数据准备和模型训练。 由于 GPU 的成本高于 CPU,因此可能需要一些试验来探索使用 GPU 是否对你的情况有利。
提示
常规用途或内存优化
为机器学习工作负载创建计算资源时,有两种常见类型的虚拟机大小可供选择:
- 常规用途:CPU 与内存比率平衡。 非常适合使用较小的数据集进行测试和开发。
- 内存优化:内存与 CPU 比率高。 非常适合内存中分析,非常适合有较大数据集或在笔记本中工作时使用。
Azure 机器学习中的计算大小显示为虚拟机大小。 这些大小遵循与 Azure 虚拟机相同的命名约定。
提示
详细了解 Azure 中虚拟机的大小。
Spark
Azure Synapse Analytics 和 Azure Databricks 等服务提供 Spark 计算。 Spark 计算或群集使用与 Azure 中的虚拟机相同的大小调整,但会分发工作负载。
Spark 群集由驱动程序节点和工作器节点组成。 代码最初将与驱动程序节点通信。 然后在工作器节点之间分发工作。 使用分发工作的服务时,可以并行执行部分工作负载,从而减少处理时间。 最后,汇总了工作,驱动程序节点将结果传回给你。
重要
若要充分利用 Spark 群集,需要使用 Spark 友好语言(如 Scala、SQL、RSpark 或 PySpark)编写代码,以便分发工作负载。 如果使用 Python 编写,则只会使用驱动程序节点,并使工作器节点保持未使用状态。
创建 Spark 群集时,必须选择是要使用 CPU 还是 GPU 计算。 还必须为驱动程序和工作器节点选择虚拟机大小。
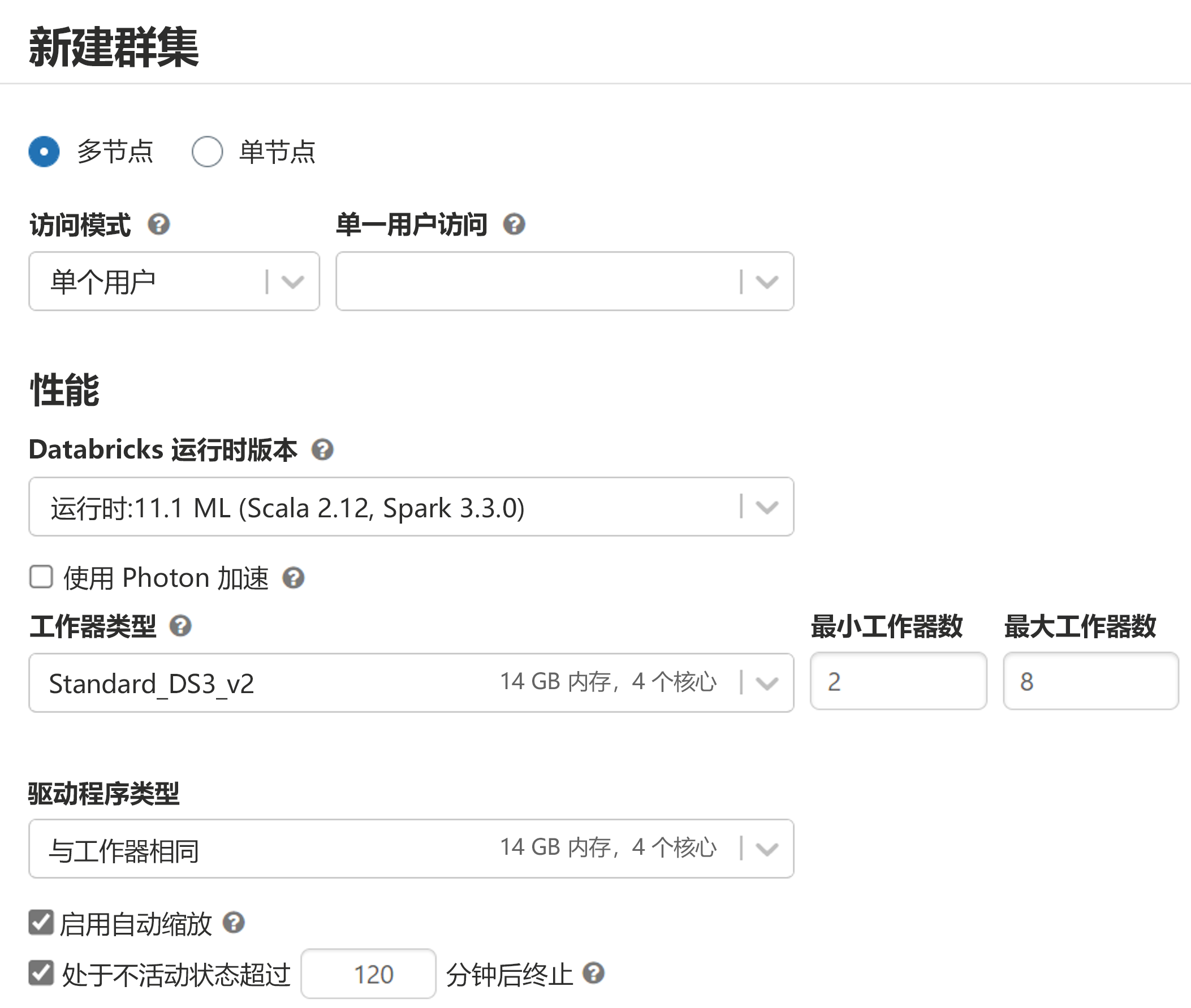
监视计算利用率
配置计算资源以训练机器学习模型是一个迭代过程。 当你知道有多少数据以及想要如何训练模型时,你就会知道哪些计算选项最适合训练模型。
每次训练模型时,都应监视训练模型所需的时间以及用于执行代码的计算量。 通过监视计算利用率,你将知道是纵向扩展还是缩减计算。 如果训练模型花费的时间太长(即使计算大小最大),你可能希望使用 GPU 而不是 CPU。 或者,可以选择使用 Spark 计算分发模型训练,这可能需要重写训练脚本。