探索 MLOps 体系结构
作为数据科学家,你想要训练最佳机器学习模型。 若要实现模型,需要将其部署到终结点,并将其与应用程序集成。
随着时间的推移,可能想要重新训练模型。 例如,当你拥有更多的训练数据时,可以重新训练模型。
一般情况下,训练机器学习模型后,你会想要为企业级模型做好准备。 若要准备模型并使其运作,需要:
- 将模型训练转换为可靠且可重现的管道。
- 在开发环境中测试代码和模型。
- 在生产环境中部署模型。
- 自动化端到端过程。
设置开发和生产环境
在 MLOps 中(与 DevOps 情况类似),环境是指资源的集合。 这些资源用于部署应用程序,或与机器学习项目一起用来部署模型。
注意
在本模块中,我们将引用环境的 DevOps 解释。 请注意,Azure 机器学习还使用术语环境来描述运行脚本所需的 Python 包集合。 这两个环境概念彼此独立。
你使用的环境数取决于你的组织。 通常,至少有两个环境:开发和生产。此外,还可以在过渡或预生产环境之间添加环境。
典型的方法是:
- 试用开发环境中的模型训练。
- 将最佳模型移动到过渡或预生产环境以部署和测试模型。
- 最后,将模型发布到生产环境以部署模型,以便最终用户能够使用它。
组织 Azure 机器学习环境
实现 MLOps 并大规模使用机器学习模型时,最好在不同的阶段使用单独的环境。
假设你的团队使用开发、预生产和生产环境。 并非你的所有团队成员都应获取对所有环境的访问权限。 数据科学家只能在具有非生产数据的开发环境中工作,而机器学习工程师在具有生产数据的预生产和生产环境中部署模型。
使用单独的环境可以更轻松地控制对资源的访问。 然后,每个环境都可以与单独的 Azure 机器学习工作区相关联。

在 Azure 中,你使用基于角色的访问控制 (RBAC) 为同事提供对他们需要处理的资源子集的适当访问权限级别。
或者,只能使用一个 Azure 机器学习工作区。 使用一个工作区进行开发和生产时,Azure 占用空间更小,管理开销更少。 但是,RBAC 同时应用于开发环境和专业环境,这可能意味着你为用户提供对资源的访问权限太少或太多。
提示
详细了解组织 Azure 机器学习资源的最佳做法。
设计 MLOps 体系结构
将模型投入到生产意味着你需要缩放解决方案并与其他团队合作。 与其他数据科学家、数据工程师和基础结构团队一起,你可能决定使用以下方法:
- 将所有数据存储在由数据工程师管理的 Azure Blob 存储中。
- 基础结构团队创建所有必要的 Azure 资源,例如 Azure 机器学习工作区。
- 数据科学家专注于他们最擅长的工作:开发和训练模型(内部循环)。
- 机器学习工程师部署训练的模型(外部循环)。
因此,MLOps 体系结构包括以下部分:
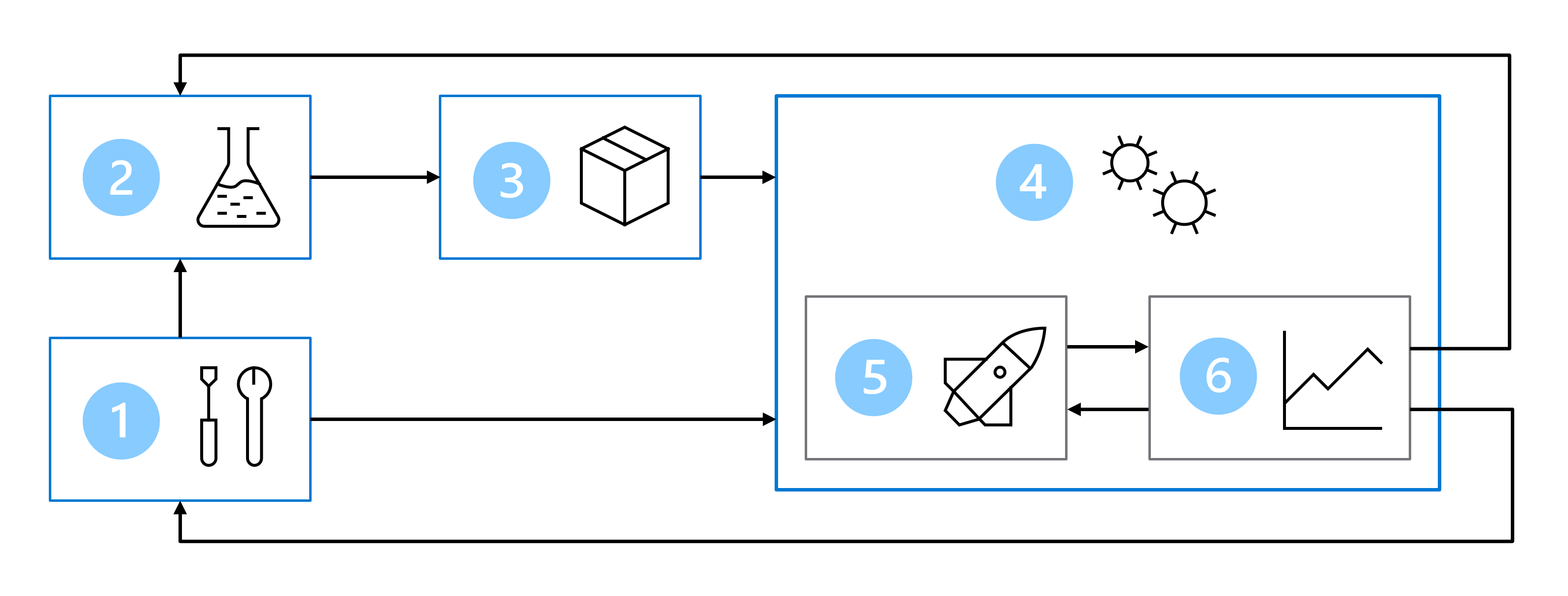
- 设置:为解决方案创建所有必需的 Azure 资源。
- 模型开发(内部循环):浏览并处理数据来训练和评估模型。
- 持续集成:打包并注册模型。
- 模型部署(外部循环):部署模型。
- 持续部署:测试模型并提升到生产环境。
- 监视:监视模型和终结点性能。
与大型团队合作时,不应以数据科学家的身份负责 MLOps 体系结构的所有部分。 但是,若要为 MLOps 准备模型,应考虑如何针对监视和重新训练进行设计。