Announcing key advances to JavaScript performance in Windows 10 Technical Preview
The Windows 10 Technical Preview brings key advances to Chakra, the JavaScript engine that powers Internet Explorer and store based Web apps across a whole range of Windows devices – phones, tablets, 2-in-1’s, PC’s and Xbox. As with all previous releases of Chakra in IE9, IE10 and IE11, this release is a significant step forward to create a JavaScript engine that is highly interoperable, spec compliant, secure and delivers great performance. Chakra now has a highly streamlined execution pipeline to deliver faster startup, supports various new and augmented optimizations in Chakra’s Just-in-Time (JIT) compiler to increase script execution throughput, and has an enhanced Garbage Collection (GC) subsystem to deliver better UI responsiveness for apps and sites. This post details some of these key performance improvements.
Chakra’s Multi-tiered Pipeline: Historical background
Since its inception in IE9, Chakra has supported a multi-tiered architecture – one which utilizes an interpreter for very fast startup, a parallel JIT compiler to generate highly optimized code for high throughput speeds, and a concurrent background GC to reduce pauses and deliver great UI responsiveness for apps and sites. Once the JavaScript source code for an app or site hits the JavaScript subsystem, Chakra performs a quick parse pass to check for syntax errors. After that, all other work in Chakra happens on an as-needed-per-function basis. Whenever possible, Chakra defers the parsing and generation of an abstract syntax tree (AST) for functions that are not needed for immediate execution, and pushes work, such as JIT compilation and GC, off the main UI thread, to harness the available power of the underlying hardware while keeping your apps and sites fast and responsive.
When a function is executed for the first time, Chakra’s parser creates an AST representation of the function’s source. The AST is then converted to bytecode, which is immediately executed by Chakra’s interpreter. While the interpreter is executing the bytecode, it collects data such as type information and invocation counts to create a profile of the functions being executed. This profile data is used to generate highly optimized machine code (a.k.a. JIT’ed code) as a part of the JIT compilation of the function. When Chakra notices that a function or loop-body is being invoked multiple times in the interpreter, it queues up the function in Chakra’s background JIT compiler pipeline to generate optimized JIT’ed code for the function. Once the JIT’ed code is ready, Chakra replaces the function or loop entry points such that subsequent calls to the function or the loop start executing the faster JIT’ed code instead of continuing to execute the bytecode via the interpreter.
Chakra’s background JIT compiler generates highly optimized JIT’ed code based upon the data and infers likely usage patterns based on the profile data collected by the interpreter. Given the dynamic nature of JavaScript code, if the code gets executed in a way that breaks the profile assumptions, the JIT’ed code “bails out” to the interpreter where the slower bytecode execution restarts while continuing to collect more profile data. To strike a balance between the amounts of time spent JIT’ing the code vs. the memory footprint of the process, instead of JIT compiling a function every time a bailout happens, Chakra utilizes the stored JIT’ed code for a function or loop body until the time bailouts become excessive and exceed a specific threshold, which forces the code to be re-JIT’ed and the old JIT code to be discarded.
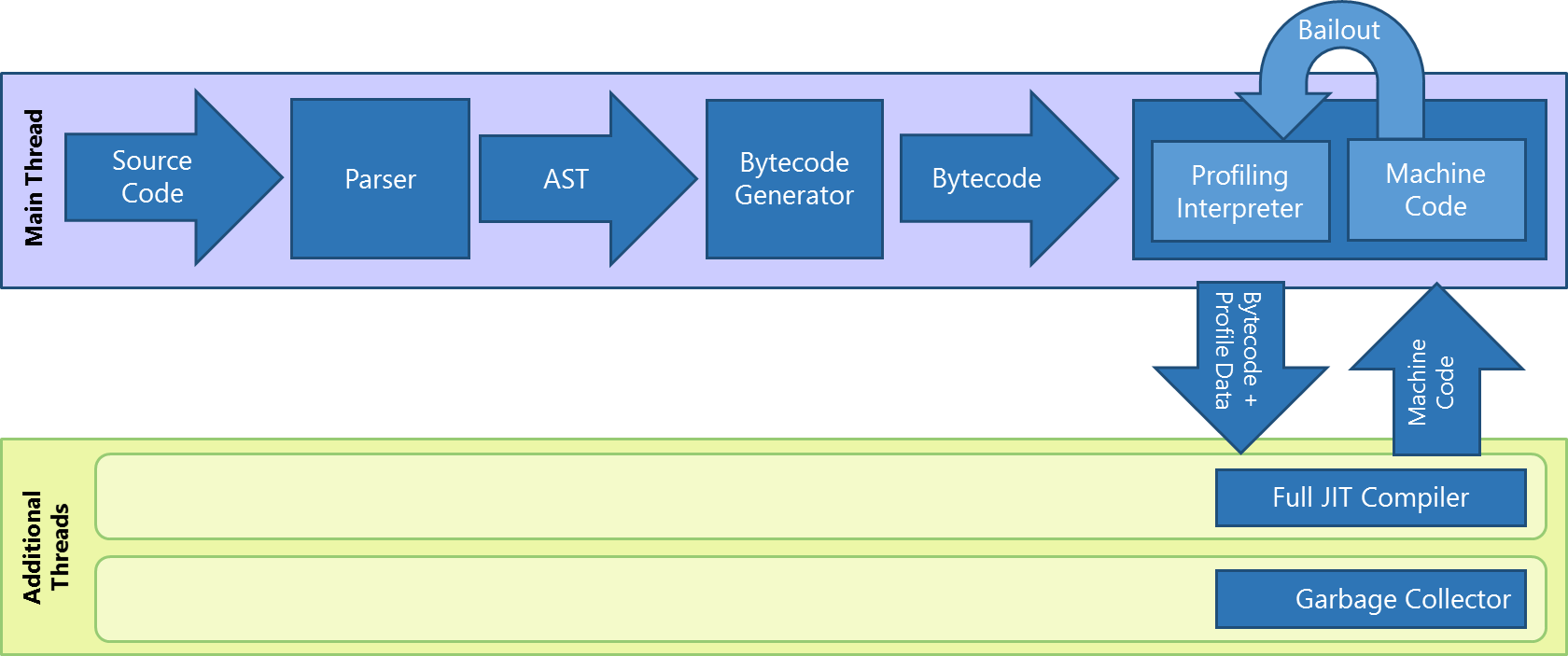
Figure 1 – Chakra’s JavaScript execution pipeline in IE11
Improved Startup Performance: Streamlined execution pipeline
Simple JIT: A new JIT compiling tier
Starting with Windows 10 Technical Preview, Chakra now has an additional JIT compilation tier called Simple JIT, which comes into play in-between the switch over from executing a function in the interpreter to executing the highly optimized JIT code, when the compiled code is ready. As its name implies, Simple JIT avoids generating code with complex optimizations, which is dependent on profile data collection by the interpreter. In most cases, the time to compile the code by the Simple JIT is much smaller than the time needed to compile highly optimized JIT code by the Full JIT compiler. Having a Simple JIT enables Chakra to achieve a faster switchover from bytecode to simple JIT’ed code, which in turn helps Chakra deliver a faster startup for apps and sites. Once the optimized JIT code is generated, Chakra then switches over code execution from the simple JIT’ed code version to the fully optimized JIT’ed code version. The other inherent advantage of having a Simple JIT tier is that in case a bailout happens, the function execution can utilize the faster switchover from interpreter to Simple JIT, till the time the fully optimized re-JIT’ed code is available.
The Simple JIT compiler is essentially a less optimizing version of Chakra’s Full JIT compiler. Similar to Chakra’s Full JIT compiler, the Simple JIT compiler also executes on the concurrent background JIT thread, which is now shared between both JIT compilers. One of the key difference between the two JIT execution tiers is that unlike executing optimized JIT code, the simple JIT’ed code execution pipeline continues to collect profile data which is used by the Full JIT compiler to generate optimized JIT’ed code.

Figure 2 – Chakra’s new Simple JIT tier
Multiple Background JITs: Hardware accelerating your JavaScript
Today, the browser and Web applications are used on a multitude of device configurations – be it phones, tablets, 2-in-1s, PCs or Xbox. While some of these device configurations restrict the availability of the hardware resources, applications running on top of beefy systems often fail to utilize the full power of the underlying hardware. Since inception in IE9, Chakra has used one parallel background thread for JIT compilation. Starting with Windows 10 Technical Preview, Chakra is now even more aware of the hardware it is running on. Whenever Chakra determines that it is running on a potentially underutilized hardware, Chakra now has the ability to spawn multiple concurrent background threads for JIT compilation. For cases where more than one concurrent background JIT thread is spawned, Chakra’s JIT compilation payload for both the Simple JIT and the Full JIT is split and queued for compilation across multiple JIT threads. This architectural change to Chakra’s execution pipeline helps reduce the overall JIT compilation latency – in turn making the switch over from the slower interpreted code to a simple or fully optimized version of JIT’ed code substantially faster at times. This change enables the TypeScript compiler to now run up to 30% faster in Chakra.
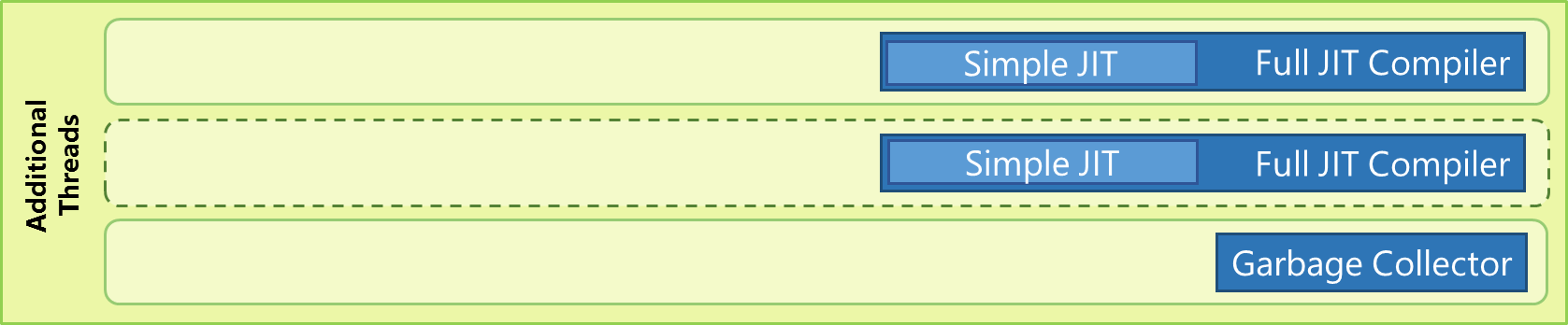
Figure 3 – Simple and full JIT compilation, along with garbage collection is performed on multiple background threads, when available
Fast JavaScript Execution: JIT compiler optimizations
Previewing Equivalent Object Type Specialization
The internal representation of an object’s property layout in Chakra is known as a “Type.” Based on the number of properties and layout of an object, Chakra creates either a Fast Type or a Slower Property Bag Type for each different object layout encountered during script execution. As properties are added to an object, its layout changes and a new type is created to represent the updated object layout. Most objects, which have the exact same property layout, share the same internal Fast Type.
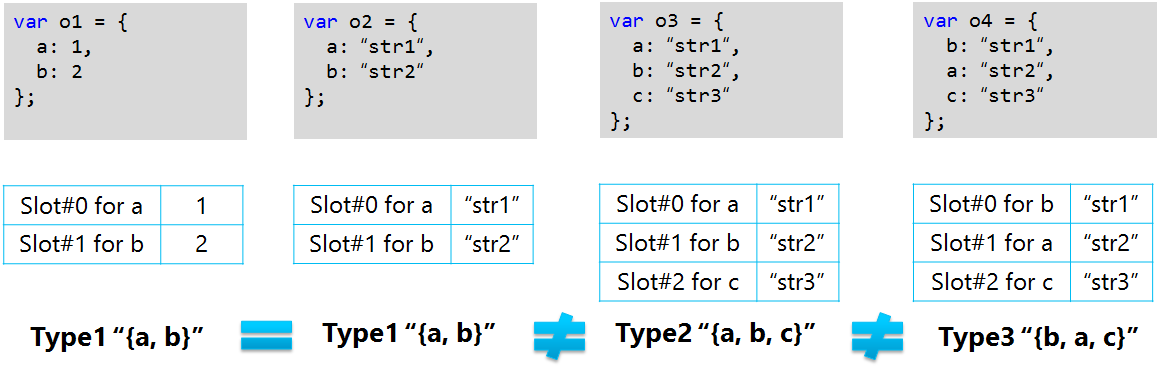
Figure 4 – Illustration of Chakra’s internal object types
Despite having different property values, objects `o1` and `o2` in the above example share the same type (Type1) because they have the same properties in the same order, while objects `o3` and ‘o4’ have a different types (Type2 and Type3 respectively) because their layout is not exactly similar to that of `o1` or `o2`.
To improve the performance of repeat property lookups for an internal Fast Type at a given call site, Chakra creates inline caches for the Fast Type to associate a property name with its associated slot in the layout. This enables Chakra to directly access the property slot, when a known object type comes repetitively at a call site. While executing code, if Chakra encounters an object of a different type than what is stored in the inline cache, an inline cache “miss” occurs. When a monomorphic inline cache (one which stores info for only a single type) miss occurs, Chakra needs to find the location of the property by accessing a property dictionary on the new type. This path is slower than getting the location from the inline cache when a match occurs. In IE11, Chakra delivered several type system enhancements, including the ability to create polymorphic inline caches for a given property access. Polymorphic caches provide the ability to store the type information of more than one Fast Type at a given call site, such that if multiple object types come repetitively to a call site, they continue to perform fast by utilizing the property slot information from the inlined cache for that type. The code snippet below is a simplified example that shows polymorphic inline caches in action.
Despite the speedup provided by polymorphic inline caches for multiple types, from a performance perspective, polymorphic caches are somewhat slower than monomorphic (or a single) type cache, as the compiler needs to do a hash lookup for a type match for every access. In Windows 10 Technical Preview, Chakra introduces a new JIT optimization called “Equivalent Object Type Specialization,” which builds on top of “Object Type Specialization” that Chakra has supported since IE10. Object Type Specialization allows the JIT to eliminate redundant type checks against the inline cache when there are multiple property accesses to the same object. Instead of checking the cache for each access, the type is checked only for the first one. If it does not match, a bailout occurs. If it does match, Chakra does not check the type for other accesses as long as it can prove that the type of the object can’t be changed between the accesses. This enables properties to be accessed directly from the slot location that was stored in the profile data for the given type. Equivalent Object Type Specialization extends this concept to multiple types and enables Chakra to directly access property values from the slots, as long as the relative slot location of the properties protected by the given type check matches for all the given types.
The following example showcases how this optimization kicks in for the same code sample as above, but improves the performance of such coding patterns by over 20%.
Code Inlining Enhancements
One of the key optimizations supported by JIT compilers is function inlining. Function inlining occurs when the function body of a called function is inserted, or inlined, into the caller’s body as if it was part of the caller’s source, thereby saving the overhead of function invocation and return (register saving and restore). For dynamic languages like JavaScript, inlining needs to verify that the correct function was inlined, which requires additional tracking to preserve the parameters and allow for stack walks in case code in the inlinee uses .caller or .argument. In Windows 10 Technical Preview, Chakra has eliminated the inlining overhead for most cases by using static data to avoid the dynamic overhead. This provides up to 10% performance boost in certain cases and makes the code generated by Chakra’s optimizing JIT compiler comparable to that of manually inlined code in terms of code execution performance.
The code snippet below is a simplified example of inlining. When the doSomething function is called repetitively, Chakra’s optimizing Full JIT compiler eliminates the call to add by inlining the add function into doSomething. Of course, this inlining doesn’t happen at the JavaScript source level as shown below, but rather happens in the machine code generated by the JIT compiler.
JIT compilers need to strike a balance to inlining. Inlining too much increases the memory overhead, in part from pressure on the register allocator as well as JIT compiler itself because a new copy of the inline function needs to be created in each place it is called. Inlining too little could lead to overall slower performance of the code. Chakra uses several heuristics to make inlining decisions based on data points like the bytecode size of a function, location of a function (leaf or non-leaf function) etc. For example, the smaller a function, the better chance it has of being inlined.
Inlining ECMAScript5 (ES5) Getter and Setter APIs: Enabling and supporting performance optimizations for the latest additions to JavaScript language specifications (ES5, ES6 and beyond) helps ensure that the new language features are more widely adopted by developers. In IE11, Chakra added support for inlining ES5 property getters. Windows 10 Technical Preview extends this by enabling support for inlining of ES5 property setters. In the simplified example below, you can visualize how the getter and setter property functions of o.x are now inlined by Chakra, boosting their performance by 5-10% in specific cases.
call() and apply() inlining: call() and apply() JavaScript methods are used extensively in real world code and JS frameworks like jQuery, at times to create mixins that help with code reuse. The call and apply methods of a target function allow setting the this binding as well as passing it arguments. The call method accepts target function arguments individually, e.g. foo.call(thisArg, arg1, arg2) , while apply accepts them as a collection of arguments, e.g. foo.apply(thisArg, [arg1, arg2]). In IE11, Chakra added support for function call/apply inlining. In the simplified example below, the call invocation is converted into a straight (inlined) function call.
In Windows 10 Technical Preview, Chakra takes this a step further and now inlines the call/apply target. The simplified example below illustrates this optimization, and in some of the patterns we tested, this optimization improves the performance by over 15%.
Auto-typed Array Optimizations
Starting with IE11, Chakra’s backing store and heuristics were optimized to treat numeric JavaScript arrays as typed arrays. This enabled JavaScript arrays with either all integers or all floats, to be auto-detected by Chakra and encoded internally as typed arrays. This change enabled Chakra to optimize array loads, avoid integer tagging and avoid boxing of float values for arrays of such type. In Windows 10 Technical Preview, Chakra further enhances the performance of such arrays by adding optimizations to hoist out array bounds checks, speed up internal array memory loads, and length loads. Apart from usage in real Web, many JS utility libraries that loop over arrays like Lo-Dash and Underscore benefit from these optimizations. In specific patterns we tested, Chakra now performs 40% faster when operating on such arrays.
The code sample below illustrates the hoisting of bounds checks and length loads that is now done by Chakra, to speed up array operations.
Chakra’s bounds check elimination handles many of the typical array access cases:
And the bounds check elimination works outside of loops as well:
Better UI Responsiveness: Garbage Collection Improvements
Chakra has a mark and sweep garbage collector that supports concurrent and partial collections. In Windows 10 Technical Preview, Chakra continues to build upon the GC improvements in IE11 by pushing even more work to the dedicated background GC thread. In IE11, when a full concurrent GC was initiated, Chakra’s background GC would perform an initial marking pass, rescan to find objects that were modified by main thread execution while the background GC thread was marking, and perform a second marking pass to mark objects found during the rescan. Once the second marking pass was complete, the main thread was stopped and a final rescan and marking pass was performed, followed by a sweep performed mostly by the background GC thread to find unreachable objects and add them back to the allocation pool.
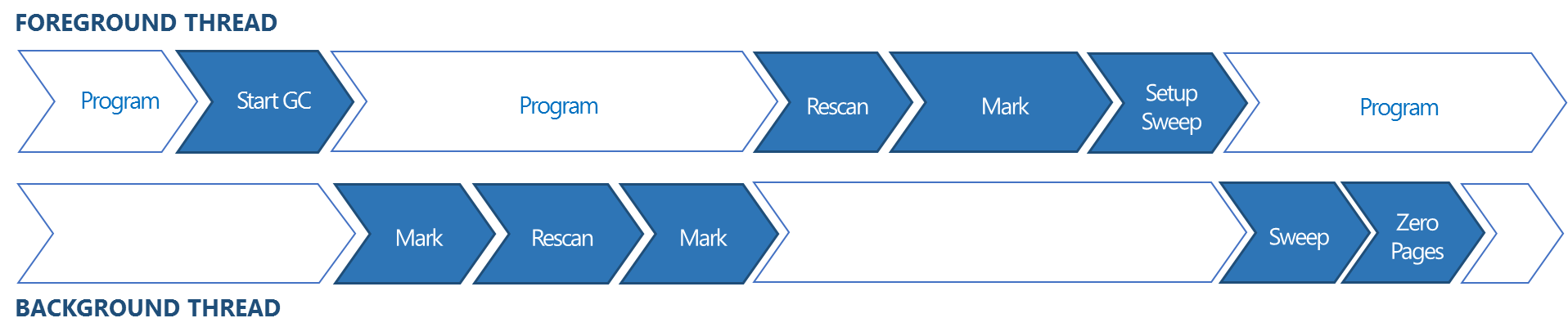
Figure 5 – Full concurrent GC life cycle in IE11
In IE11, the final mark pass was performed only on the main thread and could cause delays if there were lots of objects to mark. Those delays contributed to dropped frames or animation stuttering in some cases. In Windows 10 Technical Preview, this final mark pass is now split between the main thread and the dedicated GC thread to reduce the main thread execution pauses even further. With this change, the time that Chakra’s GC spends in the final mark phase on the main thread has reduced up to 48%.
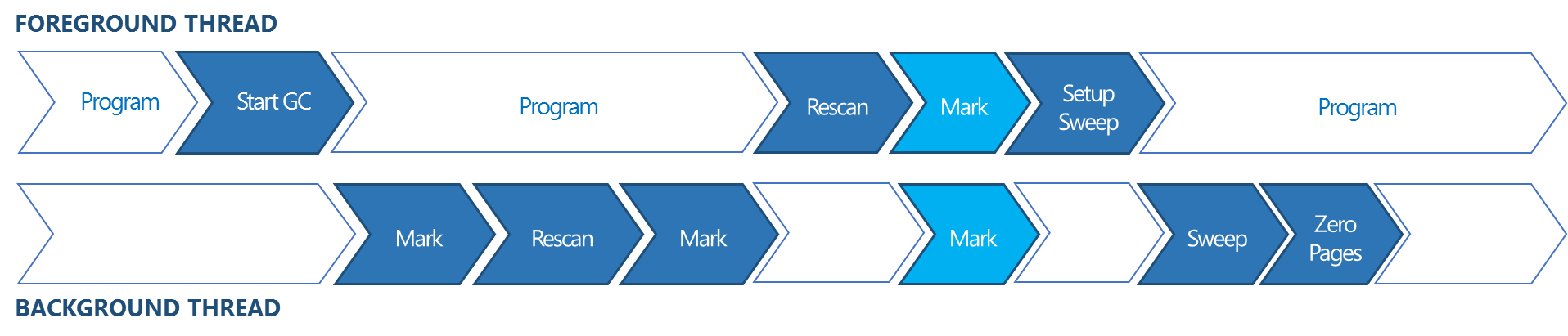
Figure 6 – Full concurrent GC life cycle in Windows 10 Technical Preview
Summary
We are excited to preview the above performance optimizations in Chakra in the Windows 10 Technical Preview. Without making any changes to your app or site code, these optimizations will allow your apps and sites to have a faster startup by utilizing Chakra’s streamlined execution pipeline that now supports a Simple JIT and multiple background JIT threads, have increased execution throughput by utilizing Chakra’s more efficient type, inlining and auto-typed array optimizations, and have improved UI responsiveness due to a more parallelized GC. Given that performance is a never ending pursuit, we remain committed to refining these optimizations, improving Chakra’s performance further and are excited for what’s to come. Stay tuned for more updates and insights as we continue to make progress. In the meanwhile, if you have any feedback on the above or anything related to Chakra, please drop us a note or simply reach out on Twitter @IEDevChat, or on Connect.
— John-David Dalton, Gaurav Seth, Louis Lafreniere
Chakra Team
Comments
Anonymous
October 09, 2014
The comment has been removedAnonymous
October 09, 2014
Excellent test case for you: go to github and try to read long source code (e.g. 2000+ lines of code). If you feel like it, in addition to scrolling you can try to use the "Find" command and type some keywords. With IE11 on Win7, the experience becomes quickly totally unusable on large files: very large loading times, sluggish scrolling or hangs when typing in the Find field. When I switch to Chrome: the same page works like a charm...Anonymous
October 09, 2014
Is your performanceaffecting battery?Anonymous
October 09, 2014
Thanks for the comprehensive and interesting article. Will you post concrete measurements of benchmarks and real-world cases in the future? It's hard to draw any conclusions with percentages for the ideal case only.Anonymous
October 09, 2014
Wonderfull, Just tested IE on Windows 10 with the Sunspiders Javascript benchmark. IE shows 184 ms and Chrome 401ms. IE is now twice as fast on this benchmark. Stability is not very good in this preview, so there is still some work to do. But this change is appriciated!Anonymous
October 09, 2014
Good news ! I love looking under the hood :) I noticed a little mistake in the "Figure 4 – Illustration of Chakra’s internal object types" The last part shows a variable named o3, it should be o4 according to the text below.Anonymous
October 09, 2014
@bystander: Investigating the issue; will open a bug so that we can track this for IE. From a quick look, this doesn’t seem to be a script related. @vantsuyoshi: Not really. As an analogy, you can imagine that every change goes through multiple performance gates before making it in, which helps ensure that we are not compromising on things like battery performance without fully understanding the tradeoffs. Given that we are in preview state, we continue to fine-tune all-up performance. @Daniel: While we’d like to encourage you to take IE/Chakra for a spin, if you look through some of the details in the post, you’ll notice that real world JS heavy payloads like the TypeScript compiler have improved by over 30% due to these changes. And yes, we’ll post more data/updates as we continue to make progress. @ChrisCamicas: Thanks for the feedback! Fixed it.Anonymous
October 09, 2014
Would love some optimization on Windows Phone. When you look at benchmarks between iOS, Android and WP, with similar or better hardware, Windows Phone is typically the slowest in javascript performance, often by a factor of 10 times. Almost like no JIT optimizer is running. Hopefully some optimization can be focused on ARM platforms too.Anonymous
October 09, 2014
@Gaurev: You may want to take a look at the source code view of Codeplex as well, e.g. http://bit.ly/1o1Ypcs. Even with short files scrolling is very slow on IE11.Anonymous
October 09, 2014
The comment has been removedAnonymous
October 09, 2014
I am sorry. The new report of translation of those other than an English-language edition has stopped three months ago. Although commented again and again from before, there is still no reaction, but the way of the translation version should also write the following report early.Anonymous
October 09, 2014
@Dave: Thanks for the feedback! ARM performance is surely on our radar. Chakra on WP does support JIT’ing. Chakra also supports almost all the compiler optimizations that are available for the desktop version for ARM. In the ARM world, the devil is often in the details as perf differences could be due to varying hardware configurations and attributes incl. chipset, clock speed, RAM, cache configs etc. rather than just software based differences. If you compare JS browsers on similar hardware (like the HTC One – see one of the reviews at http://aka.ms/md28ga), you’ll notice that it’s a mixed bag with Chakra leading in some scenarios. The work mentioned in this blog post is not restricted to any architecture and definitely helps Chakra advance on ARM as well. Curious, could you share in which config and JS benchmark do you see a 10x difference on a JS benchmark? Would love to take a closer look and understand what’s happening. @Daniel: Will do, thanks again ...Anonymous
October 09, 2014
This was an excellent read, thank you for posting this!Anonymous
October 09, 2014
Also, you folks should look into adding support for a fast path for code that parses as valid asm.js code. nudge nudge wink wink ;-PAnonymous
October 09, 2014
IE in windows 10 is exactly fast and soft.Anonymous
October 09, 2014
This looks amazing, why not make it open source like V8? Node.js was possible because of V8 being open source. Does IE11 use Chakra when it's in enterprise mode, or does it fall back to the IE8 js engine?Anonymous
October 09, 2014
Could you also take a look at Connect bug: connect.microsoft.com/.../ie11-16428-win7-causing-deadlocks-with-iwebbrowser2 This bug breaks existing software, as jscript9.dll violates restrictions on DllMain code, turning to dead lock.Anonymous
October 09, 2014
Really great read. Enjoyed the post, great work. Make it open source like V8, Typescript... Cheers!Anonymous
October 09, 2014
@Gaurav_Seth, When will the next version of IE 12 for Windows 7 and 8.1?Anonymous
October 09, 2014
Interesting post, thanks for the write up. However I was wondering why the simple JIT didn't completely replace the interpreter? The approach taken by V8 AFAIK is not to have any interpreter mode at all, just a really fast-to-generate simple JIT. This sounds like it would still start up fast, guarantee a better minimum level of performance, and simplify the codebase so there are fewer tiers to maintain. What's the IE team's viewpoint on this?Anonymous
October 09, 2014
This is all great stuff! Any chance you can talk about what's being done to improve the stability of IE on various hardware? Also, I have issues on my WP8.1 devices where the browser seems to re-render content a couple of times before it stabilizes. In Modern IE the swipe-to-go-back feature returns to a static representation of the previous page which then reloads completely. Can anything be done about that?Anonymous
October 10, 2014
The comment has been removedAnonymous
October 10, 2014
@Nick: A lot of the work we've done recently has helped optimize like code. Just look with the Preview at the scores of Mandreel or Zlib in the Octane benchmark or look at the asm.js tests in Jetstream. @Ashley: For code that runs only once, nothing beats the speed of the interpreter. A JIT has to decode the bytecode instruction, generate code for it, run the code that evaluates it. An interpreter decode the instruction and then runs the code that evaluates it. Plus, the interpreter starts running right away as a JIT typically JITs the whole function first. A lot of startup code does run only once. If we notice a loop while interpreting, our ability to JIT a loop body allows us to switch quickly to JIT'd code. If we see the same function executed multiple times, then the Simple JIT kicks in but the main thread does not have to wait for it. The interpreter also has allowed the Simple JIT to spend a little time to produce code of better quality then we would if the main thread was stalled waiting for code to be JIT'd to start running.Anonymous
October 10, 2014
Great write-up. Couple of points: Would it be worth adding type hints into the code to help things like type identification? For example, it may help the JITer if two different types were equivalent if they supported the same TypeScript interface. Just a thought that some of that erased type information may be useful to keep in as optimization hints. As the JS engine becomes more complex, what metrics are there available for runtime performance analysis to see where the bottlenecks are? If we want to understand how the engine is performing. Usually bad practice - I admit - but it can be useful for HTML apps on mobile devices.Anonymous
October 10, 2014
The comment has been removedAnonymous
October 11, 2014
@Joe: Type annotations were discussed recently in September's TC39 meeting. The meeting notes can be found at github.com/.../2014-09 @Real McCoy: Thanks for the heads up in Connect and here. JavaScript micro-benchmarks are tricky because they may not necessarily represent real world performance. Outcomes can vary greatly as the result of minor changes to a test and it's often hard to reduce outside factors to ensure exactly what's being measured across engines. That said, we do appreciate the feedback and investigate issues raised.Anonymous
October 13, 2014
The comment has been removedAnonymous
October 13, 2014
John-David Dalton [MSFT], thanks for reverting. I understand that micro-benchmarks are tricky. But since this is where the world is going, JS is needs critical refinements. We can't say for a fact that developers try those basic constructs in building large-scale apps in their apps when consuming WebGL, WebRTC etc. So JS team is expected to bring these tiny improvements to the table. VisualC @MSFT team brought tons of performance in their compiler, but the loop-invariant-hoisting and loop-interchange optimizations. If JS team,.NET and VC teams work together on performance, I think all Microsoft stack will get mega improvements. This is how Clang team at Google seems to role. thanks again and I really wish IE taking the lead in those rudimentary tests. If Chrome can do it in 50ms, IE can surely perform better!Anonymous
October 13, 2014
@Real McCoy: There's actually a push to move away from micro-benchmarks among JS engines and focus on benchmarks that better reflect real world scenarios. You can see this effort in benchmarks like Octane and JetStream. To reiterate the closing message of the post, performance is a never ending pursuit & we remain committed to improving Chakra’s performance :DAnonymous
October 13, 2014
The comment has been removedAnonymous
October 13, 2014
Honestly, tweaking a micro-benchmark is meaningless when entire pages are freezing, slowing down, ceasing to render, ceasing to respond to events, or just flat-out crashing ALL THE TIME. I'd much rather all those problems (see the "White Tabs" issue in Connect I linked above). It's been killing me of late. If I were a normal user I would have abandoned IE ages ago over these issues. It hit me over a dozen times yesterday. The "neowin" site seems rather adept at triggering this bug, I've found... especially if facebook and twitter are open in other tabs, along with a few other sites in various tabs. Come on Microsoft... find and fix this issue. I refuse to believe nobody in Microsoft has experienced it, given the frequency I experience it on a regular basis across all sorts of PCs and devices. It's not possible. It's been happening since IE9, and just gets worse with each new version and every passing month...Anonymous
October 14, 2014
The comment has been removedAnonymous
October 14, 2014
Any chance we'll get developer improvements for creating apps against the Chachra engine without requiring the rest of the browser object model?Anonymous
October 14, 2014
People should embed IE blocking code like show here, connect.microsoft.com/.../breaking-issue-ie-11-11-0-9600-17031-freezes-on-right-clicking-the-page-for-context-menu on their sites.Anonymous
October 14, 2014
Great to hear that you guys invest in JavaScript performance. With client-side frameworks iT is gecombineerd more and more important. IE11 is not quite on par with the other major browsers. To my surprise, IE11 is sometimes faster when profiling is enabled (see also connect.microsoft.com/.../ie11-javascript-much-faster-with-profiler-enabled).Anonymous
October 14, 2014
@John-David Dalton [MSFT], actually JS engine in other browsers are already performing well. I wonder why they perform so better in such a non-real-world scenarios? That alibi is really old, don't you think? So please first fix it and then join the league of "Who cares about micro-benchmarking anyway!". And if it is not going to happen, then please stop comparing against Chrome in your blogs. There is tons of test bed where Chrome exceeds IE.. But as soon as we will bring up, you will tag it non-real-world scenario as well. Pretty convenient huh! Thanks for not giving up!Anonymous
October 14, 2014
[EDITORIAL]: I believe gist.github.com/.../aec142b40616628c94c9 should have o2.add(x, y) or o1.add(this:o2, x, y) and not a plain o1.add(x, y). I think it would be more obvious what the code is actually doing.Anonymous
October 14, 2014
Question: did you consider in the bound checks elimination cases like "for(var i = array.length; i--;) { array[i].doSomething(); }" ?Anonymous
October 14, 2014
Benchmarks or it doesn't exists :)Anonymous
October 15, 2014
@Daniel, I can't replicate scrolling issues on my pcAnonymous
October 16, 2014
Awesome. Now please port these changes to WSH so that the OS uses a single JS engine vs. one for IE and an ancient and very much second-class citizen for JS in the OS itself.Anonymous
October 16, 2014
@Real McCoy: To illustrate the fickle nature of micro-benchmarks I've rewritten your branch prediction benchmark with a totally different outcome jsperf.com/.../2. There are also plenty of micro-benchmarks where IE performs well jsperf.com/.../9. Vyacheslav Egorov, who has worked on V8 in the past, has done some great talks on micro-benchmarks (http://mrale.ph/talks/) and the problems associated with them. Here's one of his more recent ones webrebels.23video.com/crooked-mirrors-of-performance-by. That said we do investigate performances issues raised and are proactive about identifying and optimizing for popular and emerging patterns to avoid performance issues in the first place. This post is focused on our JavaScript engine improvements but performance in other areas like the DOM and rendering is a top priority as well. @FremyCompany: I've commented on the gist code example over on GitHub's end. To answer your question about bound check elimination, yes your example case would benefit from bounds check elimination as long asdoSomethingis inlined. IfdoSomethingdoesn't qualify for inlining then the function call would cause the optimization to be abandoned. However, any checks before the function call would still be eliminated.Anonymous
October 16, 2014
@JDDalton: Interesting. I guess the issue is the 'doSomething' function could have a reference to the array & change its length, and it's very hard to find out it doesn't if the function isn't inlinable. Too bad, this is probably very common in real codes. Immutables structures would help, here.Anonymous
October 20, 2014
Why don't you just fork webkit and make our lives easier ?Anonymous
October 20, 2014
@Pierre: For starters WebKit isn't a JavaScript engine. Diversity of JS engines is a good thing.Anonymous
October 22, 2014
IE's issue has always been the rendering engine, I think it is time for you guys to embrace webkit. Frankly, the community is tired of catering to IE to achieve consistency. Why not crate another version of IE that runs the webkit rendering engine? Those that need Trident engine can still use the that version of IE. Reiterating on @bystander complaint, try saving a complex website as local html file and open it in IE and try the same thing on other browsers and u be the judge. Sorry, for the complaint, I think u guys do tremendous job when it comes to software, but why not solve this problem that has been plaguing IE forever.Anonymous
March 20, 2015
I have a question on Garbage Collection in relation to Single Page Applications (SPA). I understand that JavaScript garbage collection is related to references, either to DOM elements or JavaScript variables. In a data intensive SPA App where the page should not refresh and the memory is kept alive for a long time there are times when I, as a Developer, want to actively own the garbage collection process. I think in a SPA this is actually necessary, where before in a regular HTML page it is not. The operations I would like to own as a SPA Developer are freeing a single object explicitly (C style) or triggering a complete memory clear such as normally happens when the page is reloaded.Anonymous
March 20, 2015
Clarification: when I said "triggering a complete memory clear such as normally happens when the page is reloaded." what I meant is that as the SPA traverses "Pages" of DOM & JavaScript Data I want to be able to designate that this is loaded into a page of memory. And then when I route to the next "Page" in the SPA to alert the Chakra engine to free the previous page of memory. This may be difficult and it may be required to be done on the per-object basis as we do in C.