自然語言處理 (NLP) 的用途很廣,包刮情緒分析、主題偵測、語言偵測、關鍵字詞擷取和文件分類。
具體來說,您可以使用 NLP 來:
- 分類文件。 例如,您可以將文件標記為敏感或垃圾郵件。
- 進行後續處理或搜尋。 您可以將 NLP 輸出用於這些目的。
- 透過識別文件中存在的實體來總結文字。
- 用關鍵字標記文件。 對於關鍵字,NLP 可以使用已識別的實體。
- 進行基於內容的搜尋和檢索。 標記使此功能成為可能。
- 總結文件的重要主題。 NLP 可以將識別的實體組合成主題。
- 將文件分類以便導航。 為此,NLP 使用偵測到的主題。
- 根據選定的主題列舉相關文件。 為此,NLP 使用偵測到的主題。
- 對文字的情緒進行評分。 透過使用此功能,您可以評估文件的正面或負面基調。
Apache®、Apache Spark 和火焰標誌是 Apache Software Foundation 在美國和/或其他國家的註冊商標或商標。 使用這些標記不會隱含 Apache Software Foundation 的背書。
潛在使用案例
可以從自訂 NLP 中受益的業務情境包括:
- 文件智慧,適用於金融、醫療保健、零售、政府和其他領域的手寫或機器建立的文件。
- 用於與產業無關的 NLP 文字處理工作,例如名稱實體辨識 (NER)、分類、摘要和關係擷取。 這些工作會自動執行檢索、識別和分析文字和非結構化資料等文件資訊的過程。 這些工作的範例包括風險分層模型、本體分類和零售摘要。
- 用於語義搜尋的資訊檢索和知識圖建立。 此功能使得建立支援藥物發現和臨床試驗的醫學知識圖成為可能。
- 適用於零售、金融、旅遊和其他行業面向客戶的應用程式中對話式 AI 系統的文字翻譯。
Apache Spark 作為客製化的 NLP 架構
Apache Spark 是一個平行處理架構,可支援記憶體內部處理,以大幅提升巨量資料分析應用程式的效能。 Azure Synapse Analytics、Azure HDInsight 和 Azure Databricks 提供對 Spark 的存取並利用其處理能力。
對於客製化的 NLP 工作負載,Spark NLP 可作為處理大量文字的高效率架構。 這個開放原始碼 NLP 函式庫提供了 Python、Java 和 Scala 函式庫,具備傳統 NLP 函式庫 (如 spaCy、NLTK、Stanford CoreNLP 和 Open NLP) 的完整功能。 Spark NLP 還提供拼字檢查、情緒分析和文件分類等功能。 Spark NLP 透過提供最先進的準確性、速度和可擴展性來改善先前的工作。
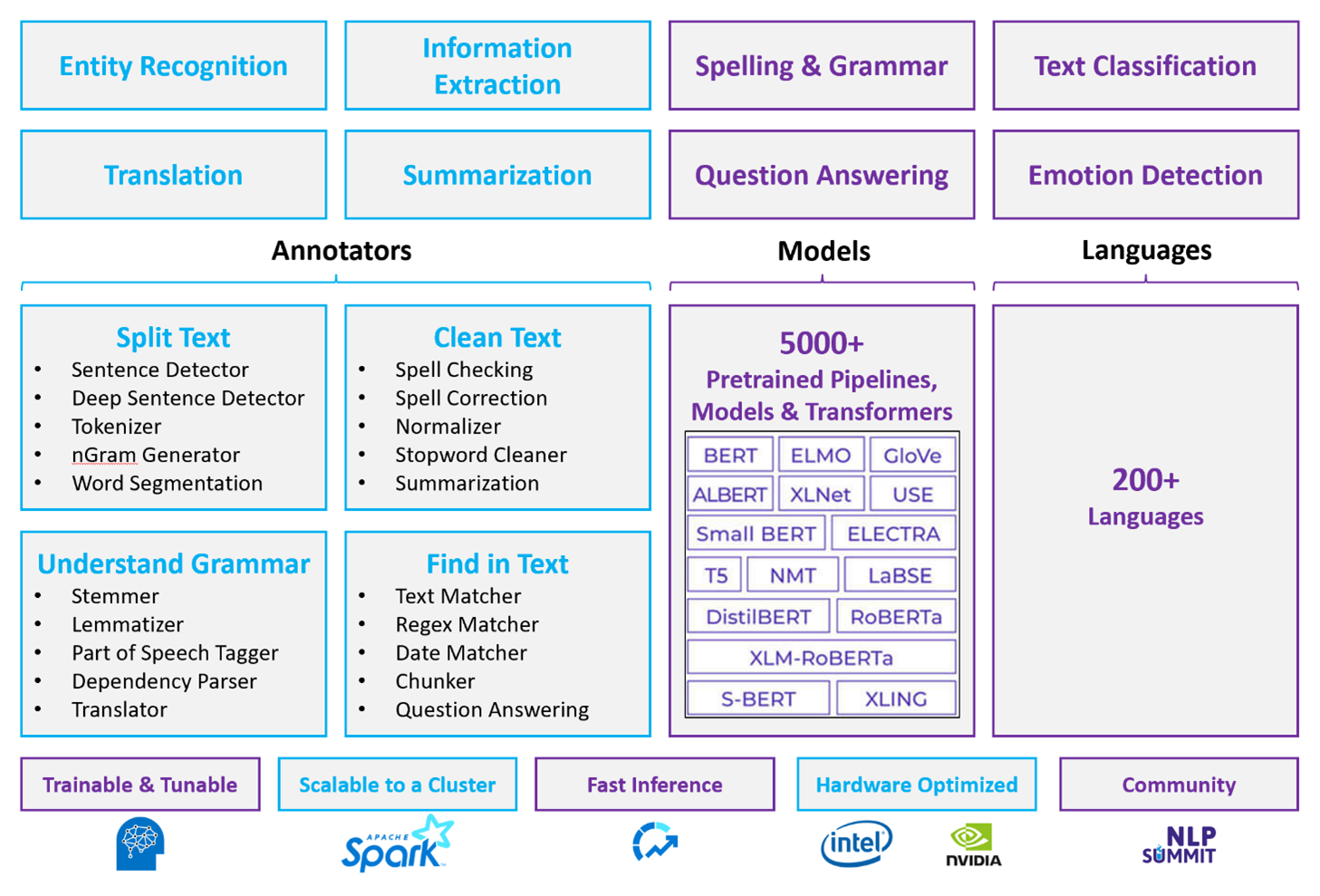
最近的公開基準測試顯示 Spark NLP 的速度比 spaCy 快 38 倍和 80 倍,並且訓練自訂模型的準確性相當。 Spark NLP 是唯一可以使用分散式 Spark 叢集的開放原始碼程式庫。 Spark NLP 是 Spark ML 的原生擴充功能,可直接在資料框架上運作。 因此,叢集的加速會帶來另一個數量級的效能提升。 由於每個 Spark NLP 管線都是 Spark ML 管線,因此 Spark NLP 非常適合建立統一的 NLP 和機器學習管線,例如文件分類、風險預測和推薦管線。
除了出色的效能之外,Spark NLP 還為越來越多的 NLP 工作提供最先進的準確性。 Spark NLP 團隊定期閱讀最新的相關學術論文並實施最先進的模型。 在過去的兩到三年裡,表現最好的模型都使用了深度學習。 該庫配備了預先建立的深度學習模型,用於命名實體辨識、文件分類、情感和情感偵測以及句子偵測。 該庫還包括數十個預先訓練的語言模型,包括對單字、區塊、句子和文件嵌入的支援。
該函式庫針對 CPU、GPU 和最新的 Intel Xeon 晶片進行了最佳化建置。 您可以擴展訓練和推斷流程以利用 Spark 叢集。 這些流程可以在所有熱門的分析平台中在生產中運作。
挑戰
- 處理自由格式文字文件的集合需要大量的運算資源。 處理過程也很耗時。 此類過程通常涉及 GPU 運算部署。
- 如果沒有標準化的文件格式,當您使用自由格式文字處理從文件中提取特定事實時,可能很難獲得一致準確的結果。 例如,考慮發票的文字表示形式,當發票來自不同的供應商時,建立正確提取發票編號和日期的流程可能很困難。
索引鍵選取準則
在 Azure 中,Azure Databricks、Azure Synapse Analytics 和 Azure HDInsight 等 Spark 服務在與 Spark NLP 結合使用時提供 NLP 功能。 Azure AI 服務是 NLP 功能的另一個選項。 要決定使用哪種服務,請考慮以下問題:
您想使用預先建置或預先訓練的模型嗎? 如果是,請考慮使用 Azure AI 服務提供的 API。 或透過 Spark NLP 下載您選擇的模型。
您是否需要針對大量文字資料訓練自訂模型? 如果是,請考慮將 Azure Databricks、Azure Synapse Analytics 或 Azure HDInsight 與 Spark NLP 結合使用。
您是否需要低階 NLP 功能,例如標記化、詞幹擷取、詞形還原和術語頻率/逆文件頻率 (TF/IDF)? 如果是,請考慮將 Azure Databricks、Azure Synapse Analytics 或 Azure HDInsight 與 Spark NLP 結合使用。 或在您選擇的處理工具中使用開放原始碼軟體庫。
您是否需要簡單、進階的 NLP 功能,例如實體和意圖辨識、主題偵測、拼字檢查或情緒分析? 如果是,請考慮使用 Azure AI 服務提供的 API。 或透過 Spark NLP 下載您選擇的模型。
功能對照表
下表總結了 NLP 服務功能的主要差異。
一般功能
| 功能 | 具有 Spark NLP 的 Spark 服務 (Azure Databricks、Azure Synapse Analytics、Azure HDInsight) | Azure AI 服務 |
|---|---|---|
| 提供預訓練模型作為服務 | Yes | Yes |
| REST API | Yes | Yes |
| 可程式性 | Python、斯卡拉 | 有關支援的語言,請參閱「其他資源」 |
| 支援處理巨量資料集和大型文件 | 是 | No |
低級 NLP 能力
| 註解工具的能力 | 具有 Spark NLP 的 Spark 服務 (Azure Databricks、Azure Synapse Analytics、Azure HDInsight) | Azure AI 服務 |
|---|---|---|
| 句子偵測器 | 是 | No |
| 深度句子偵測器 | Yes | Yes |
| 權杖化工具 | Yes | Yes |
| N 元語法產生器 | 是 | No |
| 分詞 | Yes | Yes |
| 詞幹分析器 | 是 | No |
| 詞形還原器 | 是 | No |
| Part-of-speech 標記 | 是 | No |
| 依存解析器 | 是 | No |
| 翻譯 | 是 | No |
| 停用詞清理器 | 是 | No |
| 拼字更正 | 是 | No |
| 標準化器 | Yes | Yes |
| 文字匹配器 | 是 | No |
| 特遣部隊/以色列國防軍 | 是 | No |
| 規則運算式匹配器 | Yes | 嵌入語言理解服務 (LUIS)。 正在取代 LUIS 的交談語言理解 (CLU) 不支援。 |
| 日期匹配器 | Yes | 透過日期時間識別器可以在 LUIS 和 CLU 中實現 |
| 分塊器 | 是 | No |
高水平 NLP 能力
| 功能 | 具有 Spark NLP 的 Spark 服務 (Azure Databricks、Azure Synapse Analytics、Azure HDInsight) | Azure AI 服務 |
|---|---|---|
| 拼字檢查 | 是 | No |
| 摘要 | Yes | Yes |
| 問題解答 | Yes | Yes |
| 情感偵測 | Yes | Yes |
| 表情偵測 | Yes | 支援意見挖掘 |
| 詞元分類 | Yes | 是的,透過客製化模型 |
| 文字分類 | Yes | 是的,透過客製化模型 |
| 文字表示法 | 是 | No |
| NER | Yes | 是的——文字分析提供了一組NER,自訂模型用於實體辨識 |
| 實體辨識 | Yes | 是的,透過客製化模型 |
| 語言偵測 | Yes | Yes |
| 支援英語以外的語言 | 是的,支援 200 多種語言 | 是的,支援超過 97 種語言 |
在 Azure 中設定 Spark NLP
若要安裝 Spark NLP,請使用以下程式碼,但將 <version> 替換為最新版本號。 有關更多資訊,請參閱「Spark NLP 文件」。
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
開發 NLP 管線
對於 NLP 管線的執行順序,Spark NLP 遵循與傳統 Spark ML 機器學習模型相同的開發理念。 但Spark NLP應用了NLP技術。
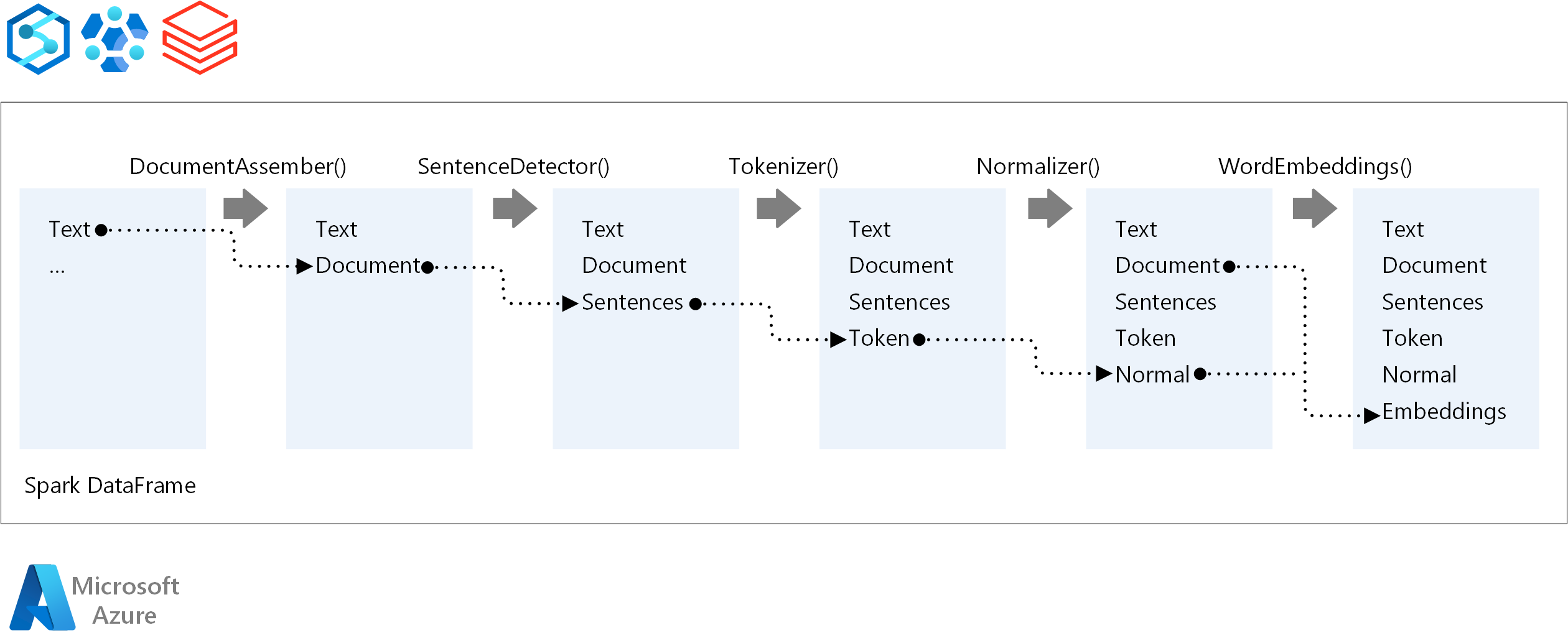
Spark NLP 管線的核心組件是:
DocumentAssembler:一種轉換器,透過將資料變更為 Spark NLP 可以處理的格式來準備資料。 此階段是每個 Spark NLP 管線的入口點。 DocumentAssembler 可以讀取
String列或Array[String]。 您可以使用setCleanupMode來預先處理文字。 預設情況下,此模式處於關閉狀態。SentenceDetector:使用指定方法偵測句子邊界的註解工具。 此註解工具可以以
Array傳回每個擷取的句子。 如果explodeSentences設定為 True,它還可以傳回不同行中的每個句子。標記器:一種註解工具,它將原始文字分成標記或單字、數字和符號等單元,並以
TokenizedSentence結構形式傳回標記。 這個類別是非擬合的。 如果您安裝了標記器,內部RuleFactory將使用輸入設定來設定標記化規則。 標記器會使用開放標準來識別標記。 如果預設設定無法滿足您的需求,您可以新增規則來自訂標記器。標準化器:清理標記的註解工具。 標準化器需要詞根。 標準化器會使用規則運算式和字典來轉換文字,並移除不必要的字元。
WordEmbeddings:一種查閱註解器,可將標記對應到向量。 您可以使用
setStoragePath來指定自訂標記查閱字典以進行嵌入。 字典的每一行都需要包含一個標記及其向量表示,並用空格分隔。 如果在字典中找不到標記,則結果是相同維度的零向量。
Spark NLP 使用 MLflow 本身支援的 Spark MLlib 管線。 MLflow 是一個用於機器學習生命週期的開放原始碼平台。 其組成部分包括:
- MLflow Tracking:記錄實驗並提供查詢結果的方法。
- MLflow 專案:使得在任何平台上執行資料科學程式碼成為可能。
- MLflow 模型:將模型部署到不同的環境。
- 模型登錄:管理儲存在中央儲存庫中的模型。
MLflow 整合在 Azure Databricks 中。 您可以在任何其他基於 Spark 的環境中安裝 MLflow 來追蹤和管理您的實驗。 您也可以使用 MLflow Model Registry 使模型可用於生產目的。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Moritz Steller | 資深雲端解決方案架構師
- Zoiner Tejada | CEO 暨架構設計師
下一步
Spark NLP 文件:
Azure 元件:
學習資源: