將數據從 Apache Kafka 內嵌到 Azure Data Explorer
Apache Kafka 是分散式串流平臺,可用來建置即時串流數據管線,以可靠地在系統或應用程式之間移動數據。 Kafka Connect 是一種工具,可用來調整且可靠的 Apache Kafka 與其他數據系統之間的數據串流。 Kusto Kafka 接收可作為 Kafka 的連接器,而且不需要使用程式代碼。 從 Git 存放庫 或 Confluent 連接器中樞下載接收連接器 jar。
本文說明如何使用獨立 Docker 設定來內嵌 Kafka 的數據,以簡化 Kafka 叢集和 Kafka 連接器叢集設定。
必要條件
- Azure 訂用帳戶。 建立 Azure 免費帳戶。
- Azure Data Explorer 具有預設快取和保留原則的叢集和資料庫,或Microsoft Fabric 中的 KQL 資料庫。
- Azure CLI。
- Docker 和 Docker Compose。
建立 Microsoft Entra 服務主體
Microsoft Entra 服務主體可以透過 Azure 入口網站 或程序設計方式建立,如下列範例所示。
此服務主體將是連接器用來在 Kusto 中寫入數據表數據的身分識別。 您稍後會授與此服務主體的許可權,以存取 Kusto 資源。
透過 Azure CLI 登入您的 Azure 訂用帳戶。 然後在瀏覽器中進行驗證。
az login選擇要裝載主體的訂用帳戶。 當您有多個訂用帳戶時,需要此步驟。
az account set --subscription YOUR_SUBSCRIPTION_GUID建立服務主體。 在這裡範例中,服務主體稱為
my-service-principal。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}從傳回的 JSON 數據中,複製
appId、password和tenant以供日後使用。{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
您已建立 Microsoft Entra 應用程式和服務主體。
建立目標數據表
從您的查詢環境,使用下列命令建立名為 的
Storms資料表:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)使用下列命令建立擷取資料的對應資料表對應
Storms_CSV_Mapping:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'在數據表上建立擷 取批處理原則 ,以設定佇列擷取延遲。
提示
擷取批處理原則是效能優化器,包含三個參數。 滿足第一個條件的觸發程式會擷取至 Azure Data Explorer 數據表。
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'使用建立 Microsoft Entra 服務主體中的服務主體,授與使用資料庫的許可權。
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
執行實驗室
下列實驗室旨在讓您開始建立數據、設定 Kafka 連接器,以及使用連接器將此數據串流至 Azure Data Explorer。 然後,您可以查看內嵌的數據。
複製 git 存放庫
複製實驗室的 Git 存放庫。
在您的電腦上建立本機目錄。
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-hol複製存放庫。
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
複製存放庫的內容
執行下列命令來列出複製存放庫的內容:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
此搜尋的結果如下:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
檢閱複製存放庫中的檔案
下列各節說明上述檔案樹狀結構中檔案的重要部分。
adx-sink-config.json
此檔案包含 Kusto 接收屬性檔案,您將在其中更新特定的設定詳細資料:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
根據 Azure Data Explorer 設定取代下列屬性的值:、、aad.auth.appid、 kusto.tables.topics.mappingaad.auth.appkey (資料庫名稱) kusto.ingestion.url、 和 kusto.query.urlaad.auth.authority
連接器 - Dockerfile
此檔案具有命令來產生連接器實例的 Docker 映像。 它包含從 git 存放庫發行目錄下載的連接器。
Storm-events-producer 目錄
此目錄具有 Go 程式,可讀取本機 「StormEvents.csv」檔案,並將數據發佈至 Kafka 主題。
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
啟動容器
在終端機中,啟動容器:
docker-compose up產生者應用程式會開始將事件傳送至
storm-events主題。 您應該會看到類似下列記錄的記錄:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....若要檢查記錄,請在不同的終端機中執行下列命令:
docker-compose logs -f | grep kusto-connect
啟動連接器
使用 Kafka Connect REST 呼叫來啟動連接器。
在不同的終端機中,使用下列命令啟動接收工作:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectors若要檢查狀態,請在個別終端機中執行下列命令:
curl http://localhost:8083/connectors/storm/status
連接器會開始將擷取程式排入佇列至 Azure Data Explorer。
注意
如果您有記錄連接器問題, 請建立問題。
查詢和檢閱數據
確認數據擷取
等候數據抵達
Storms數據表。 若要確認數據傳輸,請檢查數據列計數:Storms | count確認擷取程式中沒有失敗:
.show ingestion failures一旦您看到數據,請嘗試一些查詢。
查詢資料
若要查看所有記錄,請執行下列 查詢:
Storms使用
where與project來篩選特定資料:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdsummarize使用 運算子:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart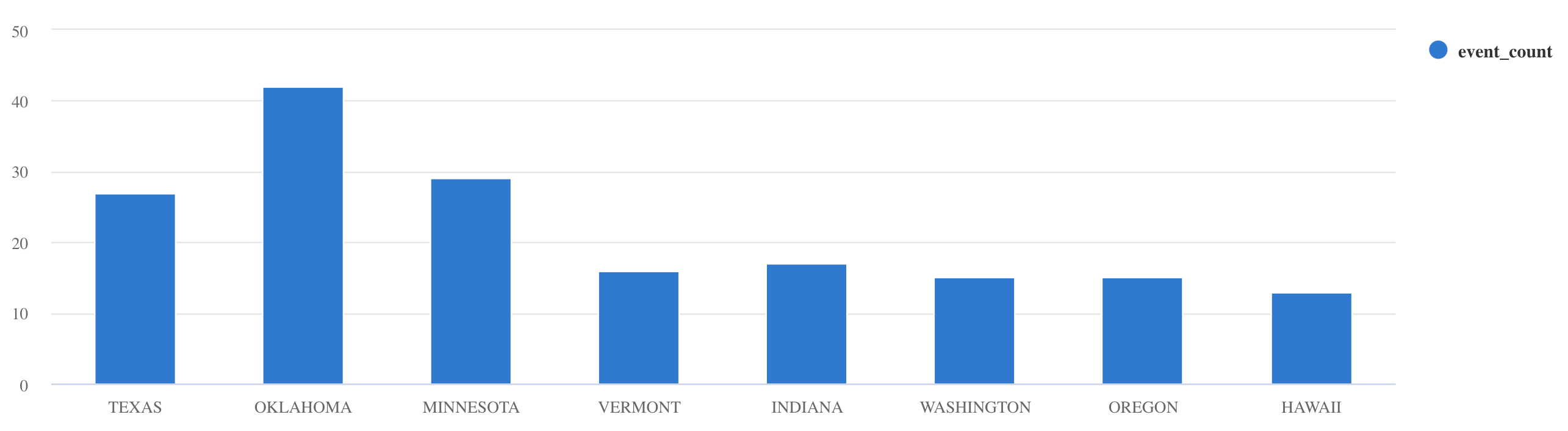
如需更多查詢範例和指引,請參閱在 KQL 中撰寫查詢和 Kusto 查詢語言 檔。
重設
若要重設,請執行下列步驟:
- 停止容器 (
docker-compose down -v) - 刪除 (
drop table Storms) - 重新建立
Storms數據表 - 重新建立數據表對應
- 重新啟動容器 (
docker-compose up)
清除資源
若要刪除 Azure Data Explorer 資源,請使用 az cluster delete 或 az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
微調 Kafka 接收連接器
- 從 1 MB 開始調整 Kafka 接收
flush.size.bytes大小限制,遞增 10 MB 或 100 MB。 - 使用 Kafka 接收時,數據會匯總兩次。 連接器端數據會根據排清設定進行匯總,並根據批處理原則在 Azure Data Explorer 服務端匯總。 如果批處理時間太短,而且連接器和服務都無法擷取任何數據,則必須增加批處理時間。 設定 1 GB 的批處理大小,並視需要增加或減少 100 MB 的增量。 例如,如果排清大小為 1 MB,且批處理原則大小為 100 MB,在 Kafka 接收連接器匯總 100 MB 批次之後,Azure Data Explorer 服務將會內嵌 100 MB 批次。 如果批處理原則時間是 20 秒,而 Kafka 接收連接器會在 20 秒期間排清 50 MB,則服務會內嵌 50 MB 批次。
- 您可以藉由新增實例和 Kafka 數據分割來調整規模。 增加
tasks.max至分割區數目。 如果您有足夠數據可產生 Blob 的設定大小,flush.size.bytes請建立分割區。 如果 Blob 較小,批次會在達到時間限制時進行處理,因此分割區不會收到足夠的輸送量。 大量的分割區表示更多處理額外負荷。