單一用戶計算的細微訪問控制
重要
這項功能處於公開預覽狀態。
本文介紹數據篩選功能,可在單一使用者計算上執行的查詢進行更細緻的訪問控制(以單一使用者存取模式設定的用途或作業計算)。 請參閱 存取模式。
此資料篩選會使用無伺服器計算在幕後執行。
為什麼單一用戶計算上的某些查詢需要數據篩選?
Unity 目錄可讓您使用下列功能來控制資料行和數據列層級表格式數據的存取權(也稱為細部訪問控制):
當使用者查詢從參考數據表或套用篩選和遮罩的查詢數據表中排除數據的檢視時,他們可以使用下列任何計算資源,而不受限制:
- SQL 倉儲
- 共用計算
不過,如果您使用單一使用者計算來執行這類查詢,則計算和您的工作區必須符合特定需求:
單一使用者計算資源必須在 Databricks Runtime 15.4 LTS 或更新版本上。
工作區必須 針對作業、筆記本和 Delta 實時數據表啟用無伺服器計算。
若要確認您的工作區區域支援無伺服器計算,請參閱 具有有限區域可用性的功能。
如果您的單一使用者計算資源和工作區符合這些需求,則每當您查詢使用精細訪問控制的檢視或數據表時,就會自動執行數據篩選。
支援具體化檢視、串流數據表和標準檢視
除了動態檢視、數據列篩選和數據行掩碼之外,數據篩選也會針對執行 Databricks Runtime 15.3 和以下單一使用者計算不支援的下列檢視和數據表啟用查詢:
-
在執行 Databricks Runtime 15.3 和以下的單一用戶計算上,在檢視上執行查詢的用戶必須具有
SELECT檢視所參考的數據表和檢視表,這表示您無法使用檢視來提供更細緻的訪問控制。 在具有數據篩選的 Databricks Runtime 15.4 上,查詢檢視的使用者不需要存取參考的數據表和檢視。
數據篩選如何在單一用戶計算上運作?
每當查詢存取下列資料庫物件時,單一使用者計算資源會將查詢傳遞至無伺服器計算來執行資料篩選:
- 透過用戶沒有許可權的數據表所建置的
SELECT檢視 - 動態檢視
- 已定義數據列篩選或數據行遮罩的數據表
- 具體化檢視和串流數據表
在下圖中,使用者已在 SELECT 、view_2、 和table_w_rls上table_1套用數據列篩選。 用戶沒有 SELECT 上的 table_2,由 參考 view_2。

上的查詢 table_1 完全由單一使用者計算資源處理,因為不需要篩選。 和 上的view_2table_w_rls查詢需要數據篩選,才能傳回使用者可存取的數據。 這些查詢是由無伺服器計算上的數據篩選功能所處理。
會產生哪些成本?
客戶會針對用來執行數據篩選作業的無伺服器計算資源收費。 如需定價資訊,請參閱 平臺層和附加元件。
您可以查詢系統計費使用量數據表,以查看您支付的費用。 例如,下列查詢會依使用者細分計算成本:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
在參與數據篩選時檢視查詢效能
單一用戶計算的Spark UI會顯示可用來了解查詢效能的計量。 針對您在計算資源上執行的每個查詢, [SQL/數據框架 ] 索引標籤會顯示查詢圖表表示法。 如果查詢涉及數據篩選,UI 會在圖形底部顯示 RemoteSparkConnectScan 運算子節點。 該節點會顯示可用來調查查詢效能的計量。 請參閱 在 Apache Spark UI 中檢視計算資訊。
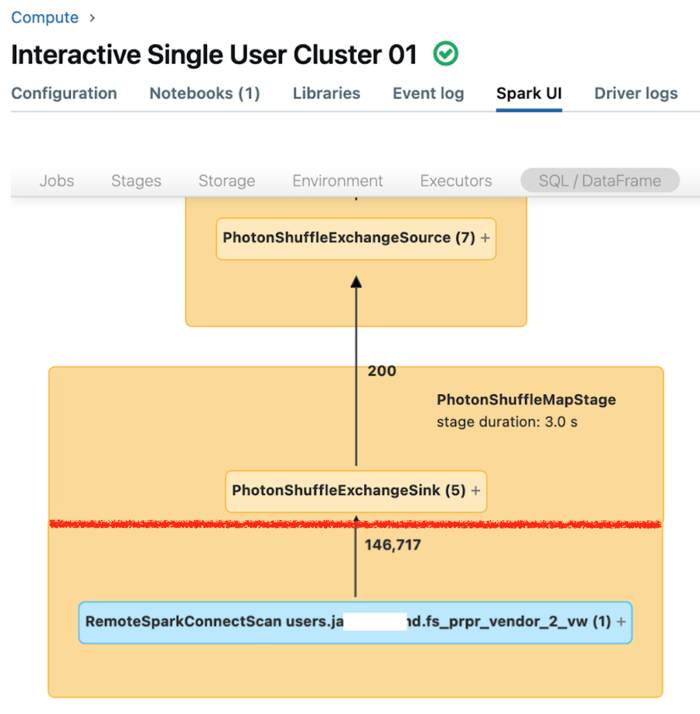
展開 RemoteSparkConnectScan 操作員節點,以查看可解決這類問題的計量,如下所示:
- 數據篩選需要多少時間? 檢視「遠端運行時間總計」。
- 數據篩選之後會保留多少個數據列? 檢視「數據列輸出」。
- 在資料篩選之後,傳回多少資料(以位元組為單位) ? 檢視「數據列輸出大小」。
- 分割區剪除了多少個數據檔,而且不需要從記憶體讀取? 檢視「剪除的檔案」和「剪除的檔案大小」。
- 無法剪除多少個數據檔,而且必須從記憶體讀取? 檢視「讀取的檔案」和「讀取的檔案大小」。
- 在必須讀取的檔案中,快取中已經有多少個檔案? 檢視「快取點擊大小」和「快取遺漏大小」。
限制
在公開預覽期間,適用下列限制:
不支援在套用數據列篩選或數據行遮罩的數據表上寫入或重新整理數據表作業。
具體而言,不支援、、
REFRESH TABLE、 和MERGE等UPDATEINSERT,DELETEDML 作業。 您只能從這些資料表讀取 (SELECT)。呼叫數據篩選時,預設會封鎖自我聯結,但您可以在執行這些命令的計算上將 設定
spark.databricks.remoteFiltering.blockSelfJoins為 false,以允許它們。在單一使用者計算資源上啟用自我聯結之前,請注意數據篩選功能所處理的自我聯結查詢可能會傳回相同遠端數據表的不同快照集。