佈建的輸送量基礎模型 API
本文示範如何搭配使用基礎模型 API 與佈建的輸送量來部署模型。 Databricks 建議針對生產工作負載使用佈建的輸送量端點,並為具有效能保證的基礎模型提供最佳化推斷。
如需支援的模型結構清單,請參閱佈建的輸送量基礎模型 API。
需求
請參閱需求。 如需部署微調的基礎模型,請參閱部署微調的基礎模型。
[建議] 從 Unity 目錄部署基礎模型
重要
這項功能處於公開預覽狀態。
Databricks 建議使用 Unity 目錄中預先安裝的基礎模型。 您可以在結構描述 ai (system.ai) 的目錄 system 下找到這些模型。
若要部署基礎模型:
- 瀏覽至目錄總管中的
system.ai。 - 按下要部署的模型名稱。
- 在模型頁面上,按下 [提供此模型] 按鈕。
- [建立服務端點] 頁面隨即出現。 請參閱使用 UI 建立佈建的輸送量端點。
從 Databricks Marketplace 部署基礎模型
或者,您可以從 Databricks Marketplace 將基礎模型安裝到 Unity 目錄。
您可以搜尋模型系列,並從模型頁面選取 [取得存取權],並提供登入認證,以將模型安裝至 Unity 目錄。
將模型安裝到 Unity 目錄之後,您可以使用服務 UI 建立模型服務端點。
部署 DBRX 模型
Databricks 建議為您的工作負載提供 DBRX Instruct 模型。 若要使用佈建的輸送量來提供 DBRX Instruct 模型,請遵循 [建議] 從 Unity 目錄部署基礎模型中的指導。
提供這些 DBRX 模型時,佈建的輸送量會支援最多 16k 的內容長度。
DBRX 模型會使用下列預設系統提示,以確保模型回應的相關性和正確性:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
部署經微調的基礎模型
如果您無法使用 system.ai 結構描述中的模型,或從 Databricks Marketplace 安裝模型,您可以將模型記錄至 Unity 目錄,以部署微調的基礎模型。 本節和下列各節說明如何設定程式碼,以將 MLflow 模型記錄至 Unity 目錄,並使用 UI 或 REST API 建立佈建的輸送量端點。
需求
- MLflow 2.11 或更新版本僅支援部署經微調的基礎模型。 Databricks Runtime 15.0 ML 和更新版本會預先安裝相容的 MLflow 版本。
- 若要內嵌端點,模型必須是小型或大型 BGE 內嵌模型結構。
- Databricks 建議在 Unity 目錄中使用模型,以便更快速地上傳和下載大型模型。
定義目錄、結構描述和模型名稱
若要部署微調的基礎模型,請定義目標 Unity 目錄、結構描述和您選擇的模型名稱。
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
記錄您的模型
若要啟用模型端點的佈建輸送量,您必須使用 MLflow transformers 類別來記錄模型,並從下列選項指定具有適當模型類型介面的 task 引數:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
這些引數會指定用於模型服務端點的 API 簽章。 如需這些工作和對應的輸入/輸出結構描述的詳細資料,請參閱 MLflow 文件。
以下是如何使用 MLflow 記錄記錄的文字完成語言模型的範例:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency
save_pretrained=False
)
注意
如果您使用早於 2.12 的 MLflow,則必須改為在相同的 mlflow.transformer.log_model() 函式的 metadata 參數內指定工作。
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
佈建的輸送量也支援基本和大型 GTE 內嵌模型。 以下是如何記錄模型 Alibaba-NLP/gte-large-en-v1.5 的範例,讓模型可以透過佈建的輸送量來提供服務:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
將您的模型記錄到 Unity 目錄之後,請繼續使用 UI 建立佈建的輸送量端點,以建立具有已布建輸送量的端點服務模型。
使用 UI 建立佈建的輸送量端點。
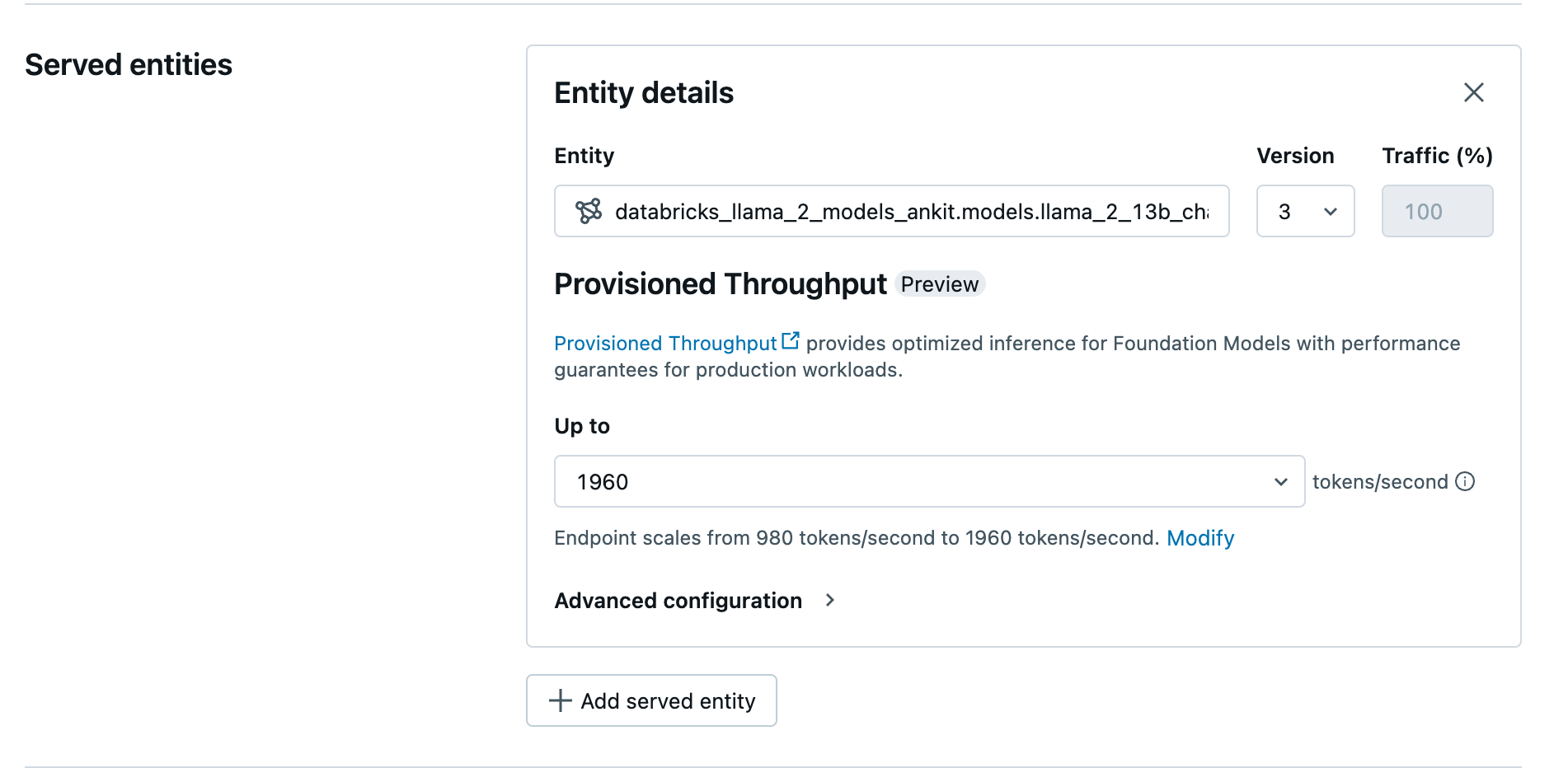
記錄的模型位於 Unity 目錄之後,請使用下列步驟建立佈建的輸送量服務端點:
- 瀏覽至工作區中的服務 UI。
- 選取 [建立服務端點]。
- 在 [實體] 欄位中,從 Unity 目錄選取您的模型。 對於合格的模型,服務實體的 UI 會顯示佈建的輸送量畫面。
- 在 [最多] 下拉式清單中,您可以為您的端點設定每秒最大權杖輸送量。
- 佈建的輸送量端點會自動調整,因此您可以選取 [修改],以檢視端點每秒可相應縮減到的最小權杖數。
使用 REST API 建立佈建的輸送量端點
若要使用 REST API 在佈建的輸送量模式中部署模型,您必須在要求中指定 min_provisioned_throughput 和 max_provisioned_throughput 欄位。 如果您偏好使用 Python,也可以使用 MLflow 部署 SDK 來建立端點。
若要識別模型的適當佈建輸送量範圍,請參閱以遞增方式取得布建的輸送量。
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
聊天完成工作的對數機率
對於聊天完成工作,您可以使用 logprobs 參數來提供在大型語言模型產生流程中進行採樣的權杖的對數機率。 您可以將 logprobs 用於各種案例,包括分類、評估模型不確定性,以及執行評估計量。 如需參數的詳細資訊,請參閱聊天工作。
以遞增方式取得佈建的輸送量
佈建的輸送量會以每秒權杖的增量提供,而特定增量會依模型而異。 若要識別適合您需求的範圍,Databricks 建議在平台中使用模型最佳化資訊 API。
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
以下是 API 回應範例:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
筆記本範例
下列筆記本示範如何建立佈建輸送量基礎模型 API 的範例:
為 GTE 模型筆記本佈建輸送量服務
為 Llama2 模型筆記本佈建的輸送量服務
為 Mistral 模型筆記本佈建的輸送量服務
為 BGE 模型筆記本佈建輸送量服務
限制
- 模型部署可能會因為 GPU 容量問題而失敗,進而導致端點建立或更新期間發生逾時。 若要協助解決,請連絡 Databricks 客戶團體。
- 基礎模型 API 的自動調整速度比 CPU 模型服務要慢。 Databricks 建議過度佈建,以避免要求逾時。