使用工作區模型登錄管理模型生命週期(舊版)
重要
本文件涵蓋工作區模型登錄。 如果您的工作區已啟用 Unity 目錄,請勿使用此頁面上的程式。 相反地,請參閱 Unity 目錄中的模型。
如需如何將工作區模型登錄升級至 Unity 目錄的指引,請參閱 將工作流程和模型移轉至 Unity 目錄。
如果您的工作區 預設目錄 位於 Unity 目錄(而非 hive_metastore)中,而且您是使用 Databricks Runtime 13.3 LTS 或更新版本執行叢集,則模型會自動在工作區默認目錄中建立並載入,而不需要設定。 在此情況下,若要使用工作區模型登錄,您必須在工作負載開始時執行 import mlflow; mlflow.set_registry_uri("databricks") 來明確鎖定它。 少數工作區,其中預設目錄在 2024 年 1 月之前設定為 Unity 目錄中的目錄,而工作區模型登錄是在 2024 年 1 月之前使用,則會豁免此行為,並依預設繼續使用工作區模型登錄。
本文說明如何使用工作區模型登錄作為機器學習工作流程的一部分,來管理 ML 模型的完整生命週期。 工作區模型登錄是 Databricks 提供的 MLflow 模型登錄裝載版本。
工作區模型登錄提供:
- 時間模型譜系(MLflow 實驗和執行會在指定時間產生模型)。
- 模型服務。
- 模型版本控制。
- 階段轉換(例如,從預備到生產或封存)。
- Webhook 可讓您根據登錄事件自動觸發動作。
- 模型事件的電子郵件通知。
您也可以建立和檢視模型描述,並留下批注。
本文包含工作區模型登錄UI和工作區模型登錄API的指示。
如需工作區模型登錄概念的概觀,請參閱 使用 MLflow 的 ML 生命週期管理。
建立或註冊模型
您可以使用UI建立或註冊模型,或使用 API 註冊模型。
使用 UI 建立或註冊模型
在工作區模型登錄中註冊模型的方法有兩種。 您可以註冊已記錄至 MLflow 的現有模型,也可以建立並註冊新的空白模型,然後將先前記錄的模型指派給它。
從筆記本註冊現有的記錄模型
在工作區中,識別包含您要註冊之模型的 MLflow 執行。
按兩下筆記本右側提要欄中的 [實驗] 圖示
 。
。
在 [實驗執行] 提要字段中,按兩下
 執行日期旁的圖示。 [MLflow 執行] 頁面隨即顯示。 此頁面會顯示執行的詳細數據,包括參數、計量、標籤和成品清單。
執行日期旁的圖示。 [MLflow 執行] 頁面隨即顯示。 此頁面會顯示執行的詳細數據,包括參數、計量、標籤和成品清單。
在 [成品] 區段中,按兩下名為 xxx-model 的目錄。
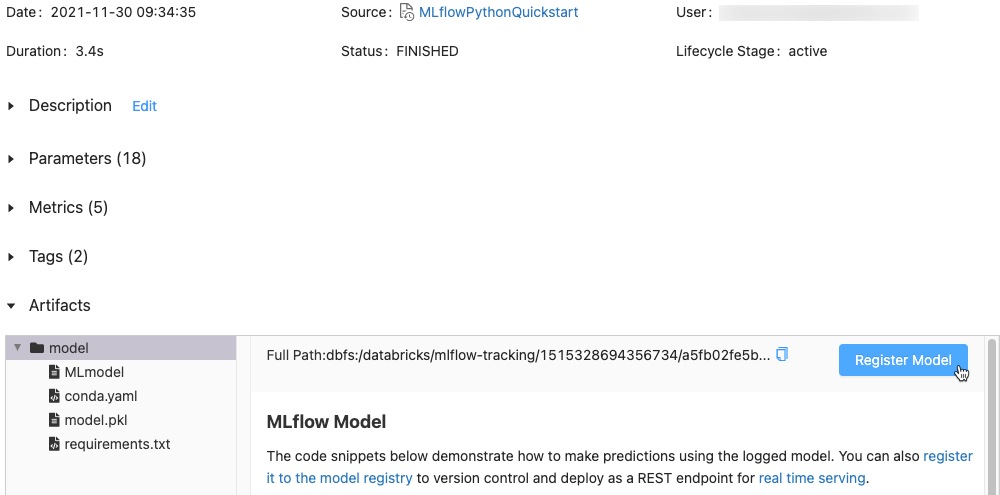
按兩下最右邊的 [ 註冊模型] 按鈕。
在對話框中,按兩下列 [ 模型] 方塊,然後執行下列其中一項動作:
- 從下拉功能表中選取 [建立新模型 ]。 [ 模型名稱] 欄位隨即出現。 輸入模型名稱,例如
scikit-learn-power-forecasting。 - 從下拉功能表中選取現有的模型。
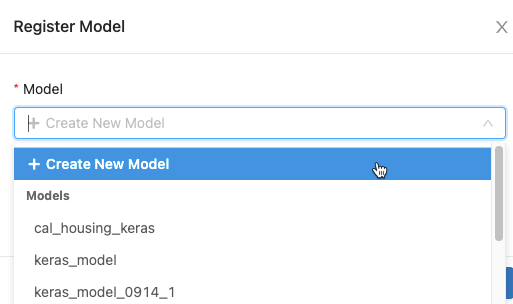
- 從下拉功能表中選取 [建立新模型 ]。 [ 模型名稱] 欄位隨即出現。 輸入模型名稱,例如
按一下 [註冊] 。
- 如果您選取 [ 建立新模型],這會註冊名為
scikit-learn-power-forecasting的模型,將模型複製到工作區模型登錄所管理的安全位置,並建立新版本的模型。 - 如果您選取了現有的模型,這會註冊新版選取的模型。
幾分鐘后,[ 註冊模型 ] 按鈕會變更為新註冊模型版本的連結。
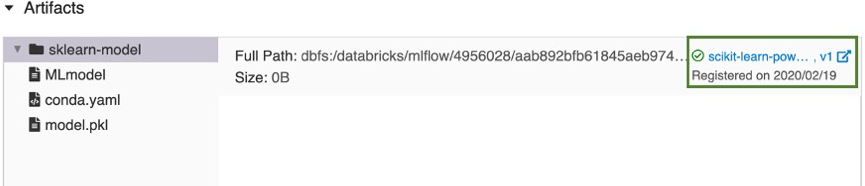
- 如果您選取 [ 建立新模型],這會註冊名為
按兩下連結,以在工作區模型登錄UI中開啟新的模型版本。 您也可以按下
 提要字段中的 [模型],在工作區模型登錄中找到模型。
提要字段中的 [模型],在工作區模型登錄中找到模型。
建立新的已註冊模型,並將記錄的模型指派給它
您可以使用已註冊模型頁面上的 [建立模型] 按鈕來建立新的空白模型,然後將記錄的模型指派給它。 執行下列步驟:
在 [已註冊的模型] 頁面上,按兩下 [ 建立模型]。 輸入模型的名稱,然後按兩下 [ 建立]。
請遵循從筆記本註冊現有記錄模型中的步驟 1 到 3。
在 [註冊模型] 對話框中,選取您在步驟 1 中建立的模型名稱,然後按兩下 [ 註冊]。 這會使用您建立的名稱來註冊模型、將模型複製到工作區模型登錄所管理的安全位置,並建立模型版本:
Version 1。幾分鐘后,MLflow 執行 UI 會以新註冊模型版本的連結取代 [註冊模型] 按鈕。 您現在可以從 [實驗執行] 頁面上的 [註冊模型] 對話框中的 [模型] 下拉式清單中選取模型。 您也可以在 API 命令中指定其名稱,例如 Create ModelVersion 來註冊新版本的模型。
使用 API 註冊模型
在工作區模型登錄中註冊模型的方法有三種程序設計方式。 所有方法都會將模型複製到工作區模型登錄所管理的安全位置。
若要記錄模型,並在 MLflow 實驗期間以指定的名稱註冊模型,請使用
mlflow.<model-flavor>.log_model(...)方法。 如果名稱為已註冊的模型不存在,則方法會註冊新的模型、建立第 1 版ModelVersion,並傳回 MLflow 物件。 如果已註冊的模型名稱已經存在,則方法會建立新的模型版本,並傳回版本物件。with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )若要在完成所有實驗之後,使用指定名稱註冊模型,而且您已決定哪一個模型最適合新增至登錄,請使用
mlflow.register_model()方法。 針對這個方法,您需要自變數的執行mlruns:URI標識符。 如果名稱為已註冊的模型不存在,則方法會註冊新的模型、建立第 1 版ModelVersion,並傳回 MLflow 物件。 如果已註冊的模型名稱已經存在,則方法會建立新的模型版本,並傳回版本物件。result=mlflow.register_model("runs:<model-path>", "<model-name>")若要建立具有指定名稱的新已註冊模型,請使用 MLflow 用戶端 API
create_registered_model()方法。 如果模型名稱存在,這個方法會MLflowException擲回 。client = MlflowClient() result = client.create_registered_model("<model-name>")
您也可以向 Databricks Terraform 提供者 註冊模型,並 databricks_mlflow_model。
配額限制
從 2024 年 5 月開始,所有 Databricks 工作區的工作區模型登錄都會針對每個工作區的已註冊模型和模型版本總數施加配額限制。 請參閱資源限制。 如果您超過登錄配額,Databricks 建議您刪除不再需要的已註冊模型和模型版本。 Databricks 也建議您調整模型註冊和保留策略,以維持在限制之下。 如果您需要增加工作區限制,請連絡您的 Databricks 帳戶小組。
下列筆記本說明如何清查和刪除您的模型登錄實體。
清查工作區模型登錄實體筆記本
在UI中檢視模型
已註冊的模型頁面
當您按下![]() 提要欄中的 [模型] 時,就會顯示已註冊的模型頁面。 此頁面會顯示登錄中的所有模型。
提要欄中的 [模型] 時,就會顯示已註冊的模型頁面。 此頁面會顯示登錄中的所有模型。
您可以從 此頁面建立新的模型 。
此外,工作區系統管理員也可以 從此頁面設定工作區模型登錄中所有模型的許可權。

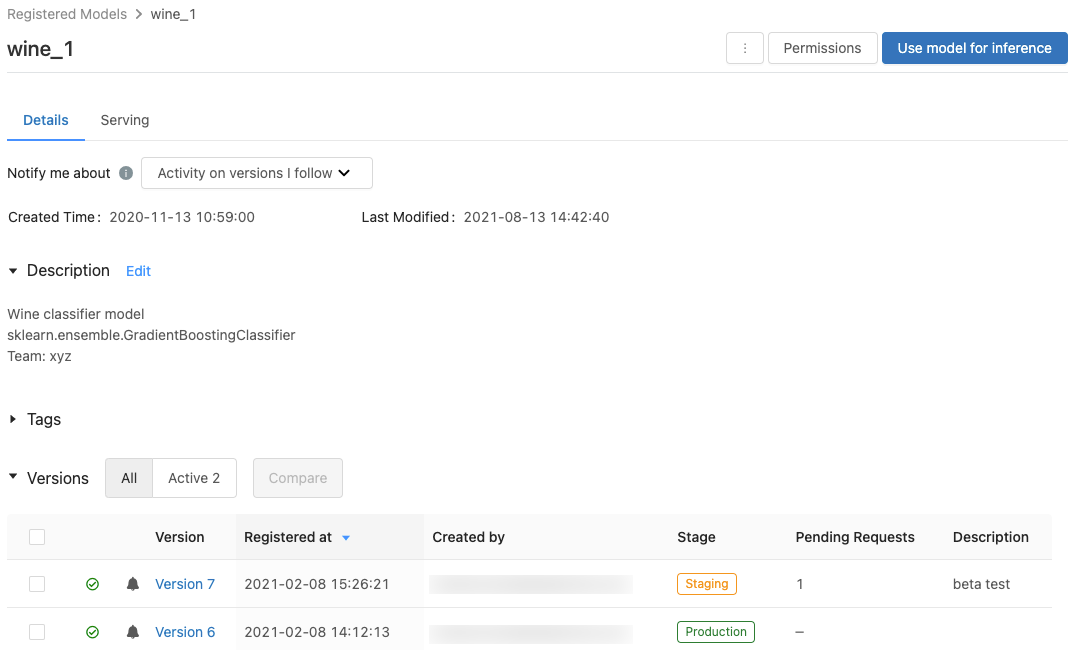
已註冊的模型頁面
若要顯示模型的已註冊模型頁面,請按下已註冊模型頁面中的模型名稱。 已註冊的模型頁面會顯示所選模型的相關信息,以及含有每個模型版本相關信息的數據表。 您也可以從此頁面:
模型版本頁面
若要檢視模型版本頁面,請執行下列其中一項動作:
- 在 [已註冊的模型] 頁面上的 [最新版本] 數據行中,按兩下版本名稱。
- 在已註冊的模型頁面中,按兩下 [版本] 資料行中的版本名稱。
此頁面會顯示已註冊模型特定版本的相關信息,並提供來源執行的連結(執行以建立模型的筆記本版本)。 您也可以從此頁面:
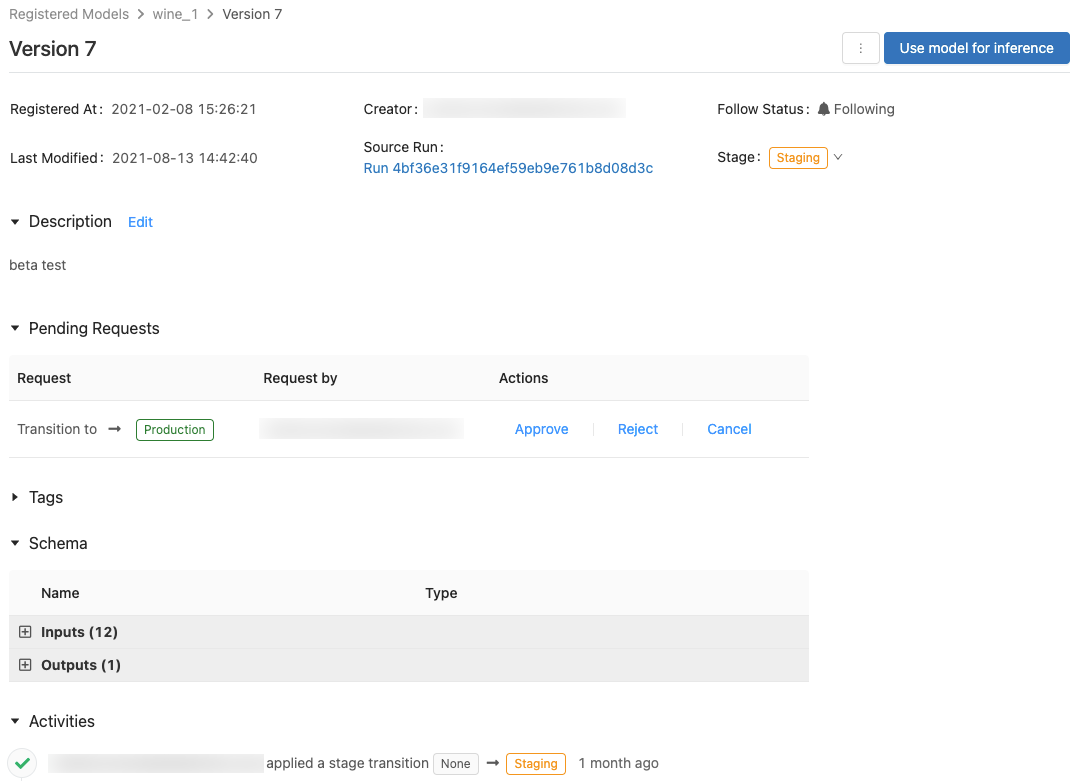
控制模型的存取
您必須至少有 CAN MANAGE 許可權,才能設定模型的許可權。 如需模型許可權等級的資訊,請參閱 MLflow 模型 ACL。 模型版本會繼承其父模型的許可權。 您無法設定模型版本的許可權。
在提要欄位中,按兩下 [
模型]。選取模型名稱。
按兩下 [ 許可權]。 [許可權設定] 對話框隨即開啟

在對話框中,選取 [ 選取使用者、群組或服務主體...] 下拉式清單,然後選取使用者、群組或服務主體。
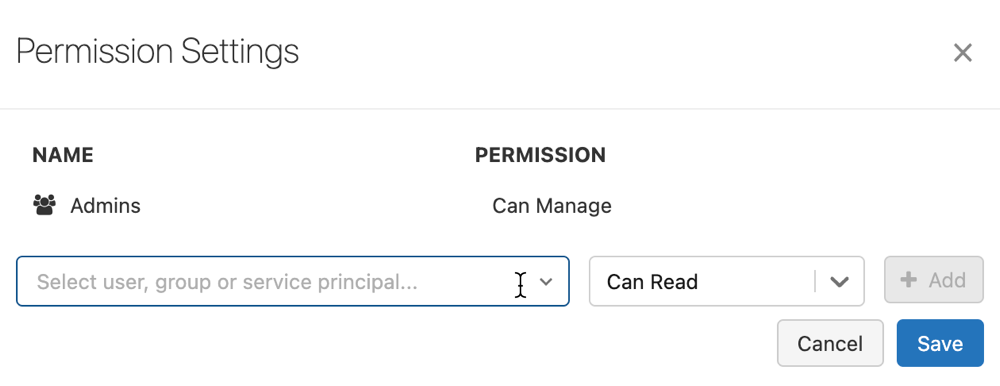
從許可權下拉式清單中選取許可權。
按兩下 [ 新增 ],然後按兩下 [ 儲存]。
在全登錄層級具有 CAN MANAGE 許可權的工作區系統管理員和使用者,可以按兩下 [模型] 頁面上的 [許可權 ],在工作區中的所有模型上設定許可權等級。
轉換模型階段
模型版本具有下列其中一個階段: 無、 預備、 生產或 封存。 預備階段適用於模型測試和驗證,而生產階段適用於已完成測試或檢閱程式的模型版本,並已部署至應用程式以進行即時評分。 封存的模型版本假設為非使用中,此時您可以考慮 將其刪除。 不同版本的模型可以處於不同的階段。
具有適當 許可權 的用戶可以在階段之間轉換模型版本。 如果您有將模型版本轉換為特定階段的許可權,您可以直接進行轉換。 如果您沒有許可權,您可以要求階段轉換,且具有轉換模型版本許可權的使用者可以 核准、拒絕或取消要求。
您可以使用UI或使用 API 轉換模型階段。
使用UI轉換模型階段
請遵循這些指示來轉換模型的階段。
若要顯示可用模型階段的清單和可用的選項,請在模型版本頁面中,按兩下 [階段:] 旁的 下拉式清單, 然後要求或選取轉換至另一個階段。
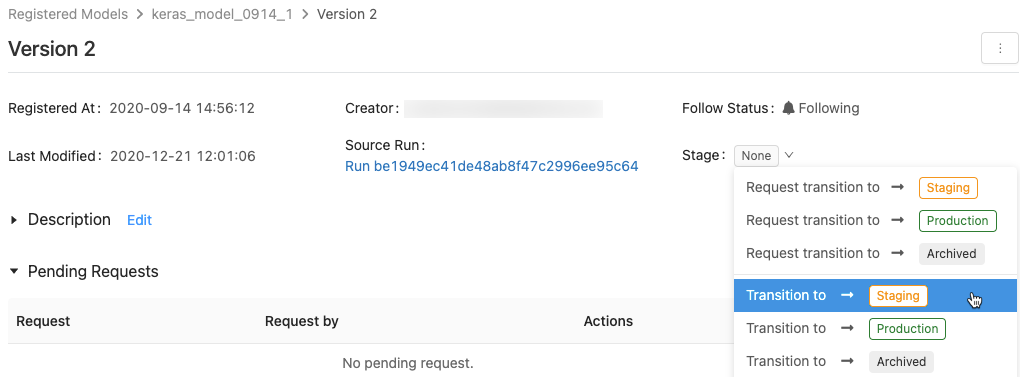
輸入選擇性批注,然後按兩下 [ 確定]。
將模型版本轉換至生產階段
測試和驗證之後,您可以轉換或要求轉換至生產階段。
工作區模型登錄可在每個階段中允許多個已註冊的模型版本。 如果您想要在生產環境中只有一個版本,您可以藉由檢查 [將現有的生產模型版本轉換至封存],將目前在生產環境中的所有模型版本轉換為 [封存]。
核准、拒絕或取消模型版本階段轉換要求
沒有階段轉換許可權的使用者可以要求階段轉換。 要求會出現在 模型版本頁面的 [擱置要求 ] 區段中:

若要核准、拒絕或取消階段轉換要求,請按兩下 [核准]、[拒絕] 或 [取消] 連結。
轉換要求的建立者也可以取消要求。
檢視模型版本活動
若要檢視已要求、已核准、擱置及套用至模型版本的所有轉換,請移至 [活動] 區段。 此活動記錄會提供模型生命週期的譜系,以進行稽核或檢查。
使用 API 轉換模型階段
具有適當 許可權 的使用者可以將模型版本轉換為新階段。
若要將模型版本階段更新為新的階段,請使用 MLflow 用戶端 API transition_model_version_stage() 方法:
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
接受值為<stage>:、、、"Archived"|"archived"。"Production"|"production""None"|"none""Staging"|"staging"
使用模型進行推斷
重要
這項功能處於公開預覽狀態。
在工作區模型登錄中註冊模型之後,您可以自動產生筆記本以使用模型進行批次或串流推斷。 或者,您可以建立端點,以使用模型服務 進行實時服務。
在已註冊的模型頁面或模型版本頁面的右上角,按兩下  。 [設定模型推斷] 對話框隨即出現,可讓您設定批次、串流或即時推斷。
。 [設定模型推斷] 對話框隨即出現,可讓您設定批次、串流或即時推斷。
重要
Anaconda Inc. 更新了其 anaconda.org 頻道服務條款 。 根據新的服務條款,如果您依賴 Anaconda 的封裝和散發,您可能需要商業授權。 如需詳細資訊,請參閱 Anaconda Commercial Edition 常見問題 。 您使用任何 Anaconda 通道會受到其服務條款的規範。
在 v1.18 之前記錄的 MLflow 模型(Databricks Runtime 8.3 ML 或更早版本)預設會以 conda defaults 通道 (https://repo.anaconda.com/pkgs/) 記錄為相依性。 由於此授權變更,Databricks 已停止針對使用 MLflow v1.18 和更新版本記錄的模型使用 defaults 通道。 記錄的預設通道現在是 conda-forge,指向社群管理的 https://conda-forge.org/。
如果您在 MLflow v1.18 之前記錄模型,但未從模型的 conda 環境排除 defaults 通道,該模型可能相依 defaults 於您可能未預期的通道。
若要手動確認模型是否具有此相依性,您可以檢查 channel 以記錄模型封裝的 conda.yaml 檔案中的值。 例如,具有defaults通道相依性之conda.yaml模型的 可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由於 Databricks 無法判斷您在與 Anaconda 的關係下是否允許使用 Anaconda 存放庫與模型互動,因此 Databricks 不會強制其客戶進行任何變更。 如果您在 Anaconda 條款下允許使用 Anaconda.com 存放庫,您就不需要採取任何動作。
如果您想要變更模型環境中所使用的通道,您可以使用新的 conda.yaml將模型重新登錄至工作區模型登錄。 您可以藉由在 的 log_model()參數中conda_env指定通道來執行此動作。
如需 API 的詳細資訊 log_model() ,請參閱您正在使用之模型類別的 MLflow 檔, 例如 scikit-learn log_model。
如需檔案的詳細資訊 conda.yaml ,請參閱 MLflow 檔。
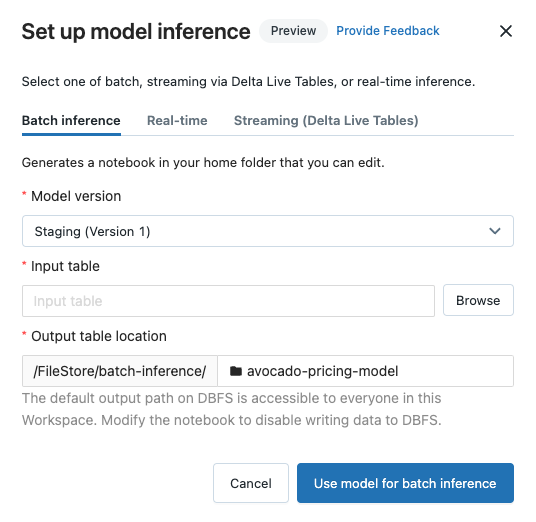
設定批次推斷
當您遵循下列步驟來建立批次推斷筆記本時,筆記本會儲存在具有模型名稱的資料夾下的使用者資料夾中 Batch-Inference 。 您可以視需要編輯筆記本。
按兩下 [ 批次推斷] 索引 標籤。
從 [ 模型版本] 下拉式清單中,選取要使用的模型版本。 下拉式清單中的前兩個專案是模型目前的 [生產] 和 [預備] 版本(如果有的話)。 當您選取其中一個選項時,筆記本會在執行時自動使用生產或預備版本。 當您繼續開發模型時,不需要更新筆記本。
按兩下 [輸入數據表] 旁的 [瀏覽] 按鈕。 [ 選取輸入數據] 對話框隨即出現。 如有必要,您可以在 [ 計算 ] 下拉式列表中變更叢集。
注意
針對已開啟 Unity 目錄的工作區,[ 選擇取輸入資料 ] 對話框可讓您從三個層級
<catalog-name>.<database-name>.<table-name>選取 。選取包含模型輸入數據的數據表,然後按兩下 [ 選取]。 產生的筆記本會自動匯入此數據,並將其傳送至模型。 如果數據在輸入模型之前需要任何轉換,您可以編輯產生的筆記本。
預測會儲存在目錄中的資料夾中
dbfs:/FileStore/batch-inference。 根據預設,預測會儲存在名稱與模型相同的資料夾中。 產生的筆記本每次執行都會將新檔案寫入此目錄,並將時間戳附加至名稱。 您也可以選擇不要包含時間戳,並使用筆記本的後續執行覆寫檔案;產生的筆記本中會提供指示。您可以在 [輸出數據表位置] 字段中輸入新的資料夾名稱,或按下資料夾圖示來瀏覽目錄並選取不同的資料夾,來變更預測儲存所在的資料夾。
若要將預測儲存至 Unity 目錄中的位置,您必須編輯筆記本。 如需示範如何定型使用 Unity 目錄中數據的機器學習模型,並將結果寫回 Unity 目錄的範例筆記本,請參閱 機器學習教學課程。
使用 Delta Live Tables 設定串流推斷
當您遵循下列步驟來建立串流推斷筆記本時,筆記本會儲存在具有模型名稱的資料夾下的使用者資料夾中 DLT-Inference 。 您可以視需要編輯筆記本。
按兩下 [ 串流][差異實時資料表] 索引標籤。
從 [ 模型版本] 下拉式清單中,選取要使用的模型版本。 下拉式清單中的前兩個專案是模型目前的 [生產] 和 [預備] 版本(如果有的話)。 當您選取其中一個選項時,筆記本會在執行時自動使用生產或預備版本。 當您繼續開發模型時,不需要更新筆記本。
按兩下 [輸入數據表] 旁的 [瀏覽] 按鈕。 [ 選取輸入數據] 對話框隨即出現。 如有必要,您可以在 [ 計算 ] 下拉式列表中變更叢集。
注意
針對已開啟 Unity 目錄的工作區,[ 選擇取輸入資料 ] 對話框可讓您從三個層級
<catalog-name>.<database-name>.<table-name>選取 。選取包含模型輸入數據的數據表,然後按兩下 [ 選取]。 產生的筆記本會建立使用輸入數據表作為來源的數據轉換,並整合 MLflow PySpark 推斷 UDF 來執行模型預測。 如果數據在套用模型之前或之後需要任何其他轉換,您可以編輯產生的筆記本。
提供輸出 Delta Live Table 名稱。 筆記本會建立具有指定名稱的實時數據表,並用它來儲存模型預測。 您可以視需要修改產生的筆記本來自定義目標數據集,例如:將串流實時數據表定義為輸出、新增架構資訊或數據品質條件約束。
然後,您可以使用此筆記本建立新的 Delta Live Tables 管線,或將它新增至現有的管線作為其他筆記本連結庫。
設定即時推斷
模型服務 會將 MLflow 機器學習模型公開為可調整的 REST API 端點。 若要建立模型服務端點,請參閱 建立自定義模型服務端點。
提供意見反應
這項功能處於預覽狀態,我們很想得到您的意見反應。 若要提供意見反應,請按兩下 Provide Feedback [設定模型推斷] 對話框中。
比較模型版本
您可以在工作區模型登錄中比較模型版本。
- 在 已註冊的模型頁面上,按兩下模型版本左邊的複選框,選取兩個或多個模型版本。
- 按兩下 [ 比較]。
- [比較
<N>版本] 畫面隨即出現,其中顯示比較所選模型版本的參數、架構和計量的數據表。 在畫面底部,您可以選取繪圖的類型(散佈圖、輪廓或平行座標),以及要繪製的參數或計量。
控制通知喜好設定
您可以設定工作區模型登錄,以透過電子郵件通知您已註冊的模型和您指定的模型版本上的活動。
在已註冊的模型頁面上,[ 通知我] 功能表會顯示三個選項:
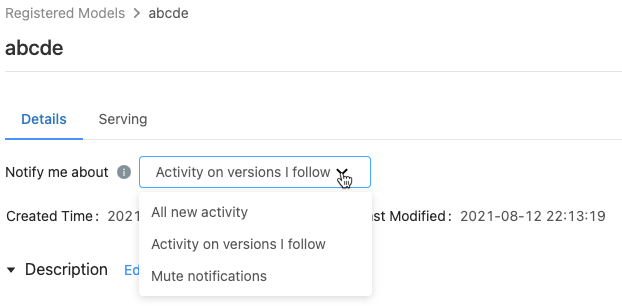
- 所有新活動:在此模型的所有模型版本上傳送所有活動的電子郵件通知。 如果您已建立已註冊的模型,則此設定為預設值。
- 我遵循的版本活動:僅傳送您追蹤之模型版本的電子郵件通知。 選取此選項后,您會收到所遵循之所有模型版本的通知;您無法關閉特定模型版本的通知。
- 靜音通知:請勿傳送此已註冊模型上活動的電子郵件通知。
下列事件會觸發電子郵件通知:
- 建立新的模型版本
- 階段轉換的要求
- 階段轉換
- 新增批注
當您執行下列任何動作時,系統會自動訂閱模型通知:
- 該模型版本的批注
- 轉換模型版本的階段
- 為模型的階段提出轉換要求
若要查看您是否遵循模型版本,請查看模型版本頁面上的 [追蹤狀態] 字段,或查看已註冊模型頁面上的模型版本數據表。
關閉所有電子郵件通知
您可以在[使用者設定] 選單的 [工作區模型登錄設定] 索引標籤中關閉電子郵件通知:
- 單擊 Azure Databricks 工作區右上角的使用者名稱,然後從下拉功能表中選取 [設定 ]。
- 在 [ 設定] 提要欄位中,選取 [ 通知]。
- 關閉 模型登錄電子郵件通知。
帳戶管理員可以在 [系統管理員設定] 頁面中關閉整個組織的電子郵件通知。
傳送的電子郵件數目上限
工作區模型登錄會限制每一活動每天傳送給每個用戶的電子郵件數目。 例如,如果您在一天內收到針對已註冊模型建立之新模型版本的相關 20 封電子郵件,工作區模型登錄會傳送一封電子郵件,指出已達到每日限制,而且不會傳送有關該事件的其他電子郵件,直到第二天為止。
若要增加允許的電子郵件數目限制,請連絡您的 Azure Databricks 帳戶小組。
Webhooks
重要
這項功能處於公開預覽狀態。
Webhook 可讓您接聽工作區模型登錄事件,讓您的整合可以自動觸發動作。 您可以使用 Webhook,將機器學習管線與現有的 CI/CD 工具和工作流程自動化並整合。 例如,您可以在建立新的模型版本時觸發 CI 組建,或每次要求模型轉換至生產環境時,透過 Slack 通知您的小組成員。
標註模型或模型版本
您可以標註模型或模型版本的相關信息。 例如,您可能想要包含問題的概觀,或所使用方法和演算法的相關信息。
使用UI標註模型或模型版本
Azure Databricks UI 提供數種方式來標註模型和模型版本。 您可以使用描述或批註來新增文字資訊,也可以新增 可搜尋的索引鍵/值標籤。 模型和模型版本可以使用描述和標記;批註僅適用於模型版本。
- 描述的目的是提供模型的相關信息。
- 批注提供一種方式來維護有關模型版本活動的持續討論。
- 標籤可讓您自定義模型元數據,讓您更輕鬆地尋找特定模型。
新增或更新模型或模型版本的描述
從已註冊的模型或模型版本頁面,按兩下 [描述] 旁的 [編輯]。 編輯視窗隨即出現。
在編輯視窗中輸入或編輯描述。
按兩下 [ 儲存 ] 以儲存您的變更或 [取消 ] 以關閉視窗。
如果您輸入模型版本的描述,描述會出現在已註冊模型頁面上數據表的 [描述] 數據行中。 數據行最多會顯示 32 個字元或一行文字,只要較短。
新增模型版本的批注
- 向下卷動模型版本頁面,然後按兩下 [活動] 旁的向下箭號。
- 在編輯視窗中輸入您的批注,然後按兩下 [ 新增批注]。
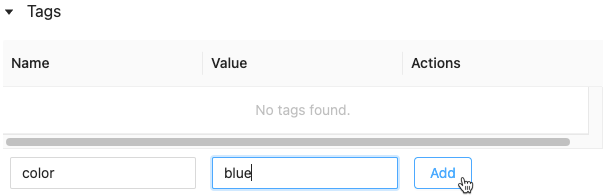
新增模型或模型版本的標籤
 它是否尚未開啟。 標記數據表隨即出現。
它是否尚未開啟。 標記數據表隨即出現。
編輯或刪除模型或模型版本的標籤
若要編輯或刪除現有的標記,請使用 [動作] 資料行中的圖示。

使用 API 標註模型版本
若要更新模型版本描述,請使用 MLflow 用戶端 API update_model_version() 方法:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
若要設定或更新已註冊模型或模型版本的標記,請使用 MLflow 用戶端 API set_registered_model_tag()) 或 set_model_version_tag() 方法:
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
重新命名模型(僅限 API)
若要重新命名已註冊的模型,請使用 MLflow 用戶端 API rename_registered_model() 方法:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
注意
只有在沒有版本,或所有版本都在 [無] 或 [封存] 階段時,才可以重新命名已註冊的模型。
搜尋模型
您可以使用 UI 或 API 在工作區模型登錄中搜尋模型。
注意
當您搜尋模型時,只會傳回您至少具有 CAN READ 許可權的模型。
使用UI搜尋模型
若要顯示已註冊的模型,請按下提要字段中的 [![]() 模型]。
模型]。
若要搜尋特定模型,請在搜尋方塊中輸入文字。 您可以輸入模型的名稱或名稱的任何部份:
您也可以搜尋標籤。 以下列格式輸入標籤: tags.<key>=<value>。 若要搜尋多個標記,請使用 AND 運算符。

您可以使用 MLflow 搜尋語法來搜尋模型名稱和標籤。 例如:

使用 API 搜尋模型
您可以使用 MLflow 用戶端 API 方法 在工作區模型登錄中搜尋已註冊的模型search_registered_models()
如果您已在 模型上設定標籤 ,也可以使用 這些標籤 search_registered_models()進行搜尋。
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
您也可以使用 MLflow 用戶端 API search_model_versions() 方法搜尋特定模型名稱並列出其版本詳細資料:
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
其會輸出:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
刪除模型或模型版本
您可以使用 UI 或 API 刪除模型。
使用UI刪除模型版本或模型
警告
您無法恢復這個動作。 您可以將模型版本轉換為封存階段,而不是從登錄中刪除它。 當您刪除模型時,工作區模型登錄所儲存的所有模型成品和與已註冊模型相關聯的所有元數據都會被刪除。
注意
您只能在 [無] 或 [封存] 階段中刪除模型和模型版本。 如果已註冊的模型在預備或生產階段中有版本,您必須先將它們轉換為 None 或 Archived 階段,才能刪除模型。
若要刪除模型版本:
- 按兩下提要欄位中的 [模型]。
- 按兩下模型名稱。
- 按兩下模型版本。
 點擊畫面右上角,然後從下拉功能表中選取 [刪除]。
點擊畫面右上角,然後從下拉功能表中選取 [刪除]。
若要刪除模型:
- 按兩下提要欄位中的 [模型]。
- 按兩下模型名稱。
- 點擊畫面右上角,然後從下拉功能表中選取 [刪除]。
使用 API 刪除模型版本或模型
警告
您無法恢復這個動作。 您可以將模型版本轉換為封存階段,而不是從登錄中刪除它。 當您刪除模型時,工作區模型登錄所儲存的所有模型成品和與已註冊模型相關聯的所有元數據都會被刪除。
注意
您只能在 [無] 或 [封存] 階段中刪除模型和模型版本。 如果已註冊的模型在預備或生產階段中有版本,您必須先將它們轉換為 None 或 Archived 階段,才能刪除模型。
刪除模型版本
若要刪除模型版本,請使用 MLflow 用戶端 API delete_model_version() 方法:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
刪除模型
若要刪除模型,請使用 MLflow 用戶端 API delete_registered_model() 方法:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
跨工作區共用模型
Databricks 建議使用 Unity 目錄中 的模型,跨工作區共用模型。 Unity 目錄提供跨工作區模型存取、治理和稽核記錄的現用支援。
不過,如果使用工作區模型登錄,您也可以 使用某些設定,跨多個工作區 共用模型。 例如,您可以在自己的工作區中開發和記錄模型,然後使用遠端工作區模型登錄從另一個工作區存取模型。 當多個小組共用模型的存取權時,這非常有用。 您可以建立多個工作區,並在這些環境中使用和管理模型。
在工作區之間複製 MLflow 物件
若要在 Azure Databricks 工作區中匯入或匯出 MLflow 物件,您可以使用社群驅動 開放原始碼 專案 MLflow Export-Import 來移轉工作區之間的 MLflow 實驗、模型及執行。
使用這些工具,您可以:
- 與相同或另一個追蹤伺服器中的其他數據科學家共用和共同作業。 例如,您可以將實驗從其他用戶複製到您的工作區。
- 將模型從某個工作區複製到另一個工作區,例如從開發到生產工作區。
- 將 MLflow 實驗從本機追蹤伺服器複製到 Databricks 工作區中執行。
- 將任務關鍵性實驗和模型備份到另一個 Databricks 工作區。
範例
此範例說明如何使用工作區模型登錄來建置機器學習應用程式。