訓練建議程式模型
本文包含兩個 Azure Databricks 上深度學習型的建議程式模型範例。 與舊版建議程式模型相比,深度學習模型可以達到更高品質的結果,並可擴展至更大的資料量。 隨著這些模型持續演進,Databricks 提供了一個架構,可有效訓練能夠處理數億使用者的大型建議模型。
一般建議系統可視為一個漏斗,其階段如圖所示。
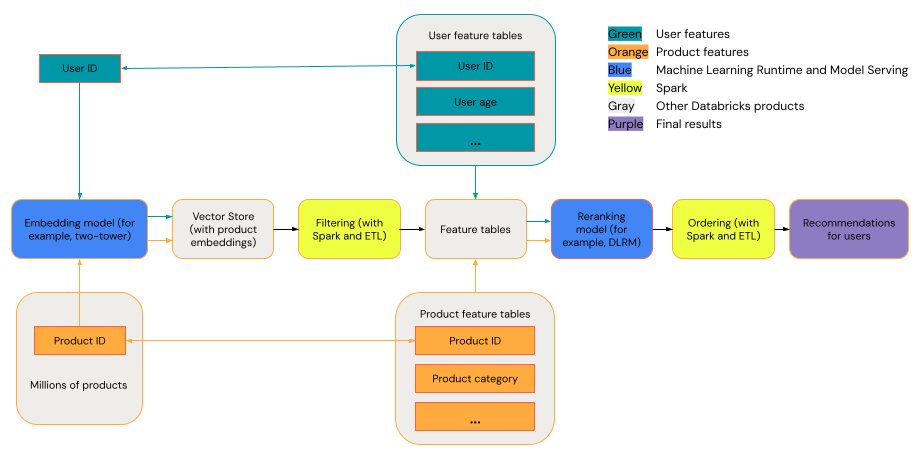
某些模型,如雙塔模型,執行更好的擷取模型。 這些模型較小,而且可在數百萬個資料點上有效作業。 其他模型,例如 DLRM 或 DeepFM,在重新排名模型時表現更好。 這些模型可以接收更多資料、規模較大,並且可以提供精細度的建議。
需求
Databricks Runtime 14.3 LTS ML
工具
本文中範例說明下列值:
- TorchDistributor:TorchDistributor 是一個架構,可讓您在 Databricks 上執行大規模 PyTorch 模型訓練。 此架構使用 Spark 進行協調流程,並可擴展至您叢集中可用的 GPU 數量。
- Mosaic StreamingDataset:StreamingDataset 使用預先擷取和交錯等功能,改善在 Databricks 上大型資料集訓練的效能和可擴縮性。
- MLflow:Mlflow 可讓您追蹤參數、計量和模型檢查點。
- TorchRec:現代的建議程式系統使用內嵌式查閱資料表來處理數百萬的使用者和項目,以產生高品質的建議。 較大的內嵌大小可提升模型效能,但需要大量的 GPU 記憶體和多 GPU 設定。 TorchRec 提供了一個架構,可在多個 GPU 上擴展建議模型和查閱資料表,因此非常適合大型內嵌項目。
範例:使用雙塔模型結構的電影建議
雙塔模型是專為處理大規模的個人化工作而設計,先分別處理使用者和項目資料,然後再將其合併。 此模型能夠有效率地產生數百或數千個品質優良的建議。 該模型通常需要三個輸入:user_id 特徵、product_id 特徵,以及定義<使用者與產品>互動是正面 (使用者購買產品) 還是負面 (使用者給予產品一星級評等) 的二進位標籤。 該模型的輸出是使用者和商品的內嵌,然後一般會將其合併 (通常使用內積或餘弦相似性) 來預測使用者與商品之間的互動。
由於雙塔模型提供使用者和產品的內嵌,您可以將這些內嵌放入向量資料庫,例如 Databricks 向量存放區,並對使用者和商品執行相似性搜尋式的作業。 舉例來說,您可以將所有項目放入向量存放庫,並針對每位使用者,查詢向量存放庫,找出內嵌與使用者相似的前一百個項目。
以下的筆記本範例使用「從項目集學習」資料集實作雙塔模型訓練,以預測使用者對某部電影給予高評分的可能性。 它使用 Mosaic StreamingDataset 進行分散式資料載入,使用 TorchDistributor 進行分散式模型訓練,並使用 Mlflow 進行模型追蹤和記錄。
雙塔建議程式模型筆記本
此筆記本也可在 Databricks 市集購買:雙塔模型筆記本
注意
- 雙塔模型的輸入通常是類別特徵 user_id 和 product_id。 該模型可以修改,以支援使用者和產品的多重特徵向量。
- 雙塔模型的輸出通常是二進位值,表示使用者與產品會產生正面或負面的互動。 該模型可針對其他應用程式修改,例如迴歸、多類分類,以及多重使用者動作 (例如關閉或購買) 的機率。 複雜的輸出應該小心實作,因為競爭的目標可能會降低模型產生的內嵌品質。
範例:使用合成資料集訓練 DLRM 結構
DLRM 是專為個人化和建議系統設計的最先進神經網路架構。 此架構結合了分類和數值輸入,可有效地建立使用者與項目互動的模型,並預測使用者的喜好設定。 DLRM 通常期望輸入包含稀疏特徵 (例如使用者識別碼、商品識別碼、地理位置或產品類別) 和密集特徵 (例如使用者年齡或商品價格)。 DLRM 的輸出通常是對使用者參與度的預測,例如點擊率或購買可能性。
DLRM 提供高度可自訂的架構,可以處理大規模的資料,因此適用於各種網域的複雜建議工作。 由於此架構是一個比雙塔結構更大的模型,因此此模型通常用於重新排名階段。
下列的筆記本範例組建了一個 DLRM 模型,使用密集 (數值) 特徵和稀疏 (類別) 特徵來預測二進位標籤。 它使用合成資料集來訓練模型、Mosaic StreamingDataset 來進行分散式資料載入、TorchDistributor 來進行分散式模型訓練,以及 Mlflow 來進行模型追蹤與記錄。
DLRM 筆記本
此筆記本也可在 Databricks 市集購買:DLRM 筆記本
雙塔和 DLRM 模型的比較
該資料表顯示一些選取使用哪個建議程式模型的指導方針。
| 模型類型 | 訓練所需的資料集大小 | 模型大小 | 支援的輸入類型 | 支援的輸出類型 | 使用案例 |
|---|---|---|---|---|---|
| 雙塔 | 變小 | 變小 | 通常是兩個特徵 (user_id、product_id) | 主要是二元分類和內嵌產生 | 產生數百或數千個可能的建議 |
| DLRM | 較大 | 較大 | 各種類別和密集特徵 (user_id、性別、geographic_location、product_id、product_category、…) | 多類分類、迴歸、其他 | 精細擷取 (建議數十項高度相關項目) |
總而言之,雙塔模型最適合用於非常有效率地產生數以千計的高品質建議。 例如,有線電視供應商提供的電影建議。 DLRM 模型最適合用於根據更多資料產生非常特定的建議。 舉例來說,零售商希望向客戶提供他們極有可能購買的少量商品。