在 Azure HDInsight 上將 Apache Spark 和 Apache Hive 與 Hive Warehouse Connector 整合起來
Apache Hive Warehouse Connector (HWC) 是一個程式庫,可讓您更輕鬆地使用 Apache Spark 和 Apache Hive。 其支援在 Spark 資料框架和 Hive 資料表之間移動資料之類的工作。 此外,藉由將 Spark 串流資料導向 Hive 資料表。 Hive Warehouse Connector 的作用就像是 Spark 和 Hive 之間的橋樑。 其也支援以 Scala、Java 和 Python 作為開發的程式設計語言。
Hive Warehouse Connector 可讓您利用 Hive 和 Spark 的獨特功能來建置功能強大的巨量資料應用程式。
Apache Hive 可支援不可部分完成、一致、隔離和耐用 (ACID) 的資料庫交易。 如需 Hive 中 ACID 和交易的詳細資訊,請參閱 Hive 交易。 Hive 也會透過 Apache Spark 中未提供的 Apache Ranger 和低延遲分析處理 (LLAP) 來提供詳細的安全性控制。
Apache Spark 具有結構化串流 API,可提供 Apache Hive 中無法使用的串流功能。 從 HDInsight 4.0 開始,Apache Spark 2.3.1 和更新版本以及 pache Hive 3.1.0 都有個別的中繼存放區目錄,這使得互通性變得困難。
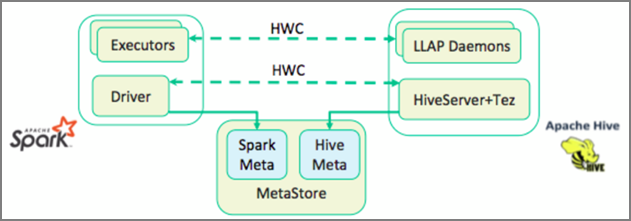
Hive Warehouse Connector (HWC) 可讓您更輕鬆地一起使用 Spark 和 Hive。 HWC 程式庫會以平行方式將 LLAP 精靈中的資料載入到 Spark 執行程式。 此程序的效率和適應性會比 Spark 到 Hive 的標準 JDBC 連線還要好。 這會顯示 HWC 的兩種不同的執行模式:
- 透過 HiveServer2 的 Hive JDBC 模式
- 使用 LLAP 精靈的 Hive LLAP 模式 [建議]
根據預設,HWC 會設定為使用 Hive LLAP 精靈。 如需使用上述模式搭配其各自 API 執行 Hive 查詢 (讀取和寫入),請參閱 HWC API。
Hive Warehouse Connector 所支援的部分作業包括:
- 描述資料表
- 建立 ORC 格式資料的資料表
- 選取 Hive 資料並擷取資料架構
- 將資料架構批次寫入至 Hive
- 執行 Hive 更新陳述式
- 從 Hive 讀取資料表資料、在 Spark 中轉換它,並將它寫入至新的 Hive 資料表
- 使用 HiveStreaming 將資料架構或 Spark 串流寫入至 Hive
Hive Warehouse Connector 設定
重要
- 不支援在 Spark 2.4 企業安全性套件叢集上安裝的 HiveServer2 Interactive 執行個體搭配 Hive Warehouse Connector 使用。 相反地,您必須設定個別的 HiveServer2 Interactive 叢集以裝載 HiveServer2 Interactive 工作負載。 不支援使用單一 Spark 2.4 叢集的 Hive Warehouse Connector 設定。
- 不支援 Hive Warehouse Connector (HWC) 程式庫搭配已啟用工作負載管理 (WLM) 功能的 Interactive Query 叢集使用。
在只有 Spark 工作負載且想要使用 HWC 程式庫的案例中,請確定 Interactive Query 叢集未啟用工作負載管理功能 (hive.server2.tez.interactive.queue組態未設定於 Hive 組態中)。
針對 Spark 工作負載 (HWC) 和 LLAP 原生工作負載皆存在的情況,您必須建立兩個共用中繼存放區資料庫的不同 Interactive Query 叢集。 一個叢集適用於原生 LLAP 工作負載,在其中可視需要啟用 WLM 功能,而另一個叢集則適用於僅限 HWC 工作負載,在其中不得設定 WLM 功能。 請務必注意,即使僅在一個叢集中啟用 WLM 功能,您還是可以從這兩個叢集檢視 WLM 資源計劃。 請勿在已停用 WLM 功能的叢集中對資源計劃進行任何變更,因為這可能影響其他叢集中的 WLM 功能。 - 雖然 Spark 支援 R 運算語言以簡化其資料分析,但不支援 Hive Warehouse Connector (HWC) Library 搭配 R 使用。若要執行 HWC 工作負載,您可以使用僅支援 Scala、Java 和 Python 的 JDBC 樣式 HiveWarehouseSession API,從 Spark 對 Hive 執行查詢。
- 對於 Arrays/Struct/Map 類型等複雜的資料類型,不支援經由 JDBC 模式透過 HiveServer2 執行查詢 (讀取和寫入)。
- HWC 僅支援以 ORC 檔案格式撰寫。 不支援透過 HWC 的非 ORC 寫入 (例如:parquet 和文字檔格式)。
Hive Warehouse Connector 需要為 Spark 和 Interactive Query 工作負載準備不同叢集。 請遵循下列步驟,在 Azure HDInsight 中設定這些叢集。
支援的叢集類型與版本
| HWC 版本 | Spark 版本 | InteractiveQuery 版本 |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
建立叢集
使用儲存體帳戶和自訂的 Azure 虛擬網路建立 HDInsight Spark 4.0 叢集。 如需在 Azure 虛擬網路中建立叢集的相關資訊,請參閱將 HDInsight 新增至現有虛擬網路。
使用與 Spark 叢集相同的儲存體帳戶和 Azure 虛擬網路,建立 HDInsight Interactive Query (LLAP) 4.0 叢集。
設定 HWC 設定
收集初步資訊
從網頁瀏覽器瀏覽至
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE,其中 LLAPCLUSTERNAME 是您互動式查詢叢集的名稱。瀏覽至 [摘要]>[HiveServer2 互動式 JDBC URL] 並記下該值。 此值可能類似於:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive。瀏覽至 [設定]>[進階]>[進階 Hive 網站]>[hive.zookeeper.quorum] 並記下該值。 此值可能類似於:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181。瀏覽至 [設定]>[進階]>[一般]>[hive.metastore.uris],並記下該值。 此值可能類似於:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083。瀏覽至 [設定]>[進階]>[進階 Hive 互動式網站]>[hive.llap.daemon.service.hosts] 並記下該值。 此值可能類似於:
@llap0。
設定 Spark 叢集設定
從網頁瀏覽器瀏覽至
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs,其中 CLUSTERNAME 是您 Apache Spark 叢集的名稱。展開 [自訂 spark2-defaults]。
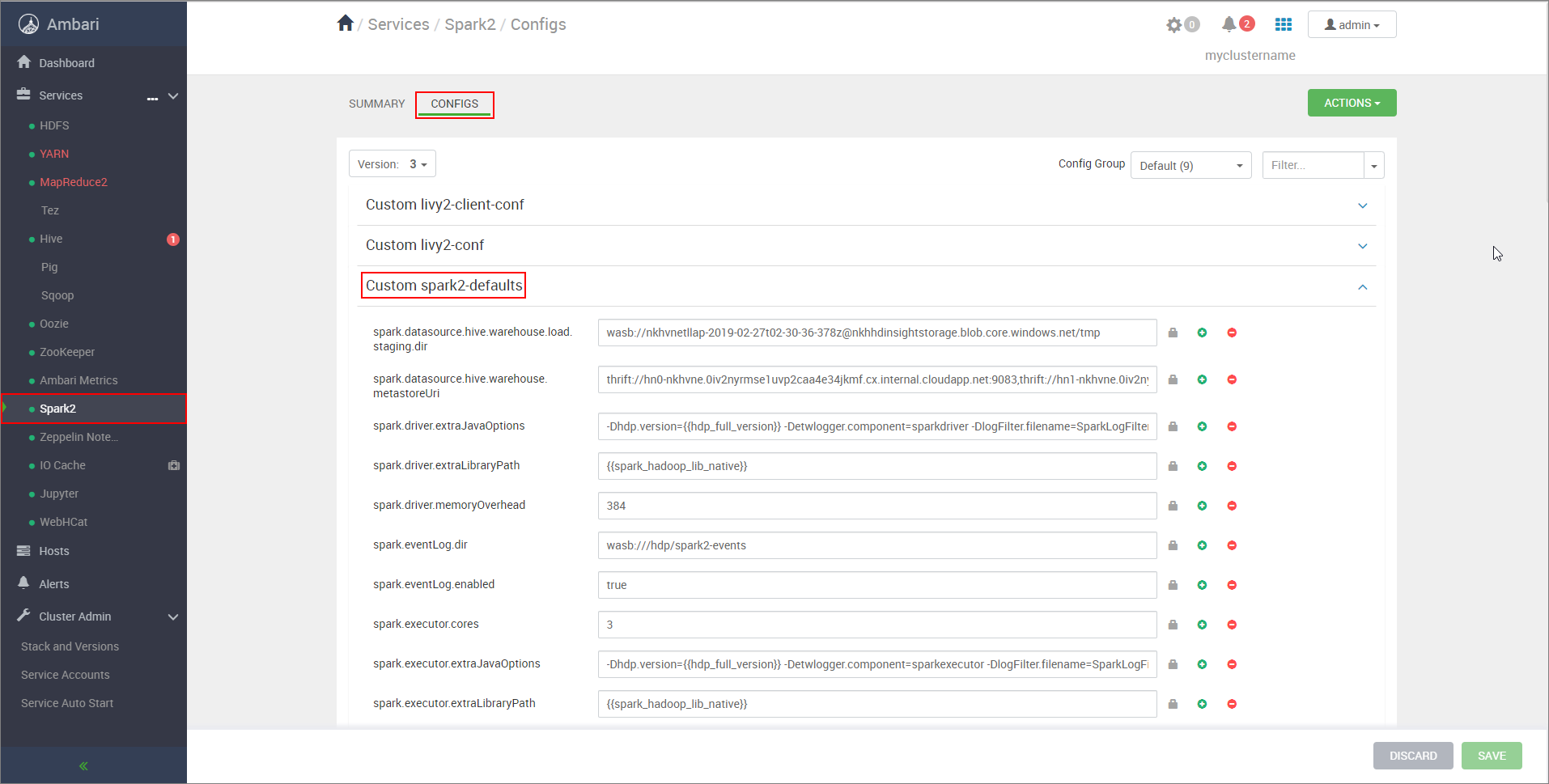
選取 [新增屬性] 以新增下列設定:
組態 值 spark.datasource.hive.warehouse.load.staging.dir若您使用 ADLS Gen2 儲存體帳戶,請使用 abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
如果您使用 Azure Blob 儲存體帳戶,請使用wasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp。
設定為適當的 HDFS 相容暫存目錄。 如果您有兩個不同的叢集,則暫存目錄必須是 LLAP 叢集儲存體帳戶的暫存目錄所含資料夾,HiveServer2 才能存取該目錄。 將STORAGE_ACCOUNT_NAME取代為叢集所使用儲存體帳戶的名稱,並將STORAGE_CONTAINER_NAME取代為儲存體容器的名稱。spark.sql.hive.hiveserver2.jdbc.url您先前從 HiveServer2 Interactive JDBC URL 取得的值 spark.datasource.hive.warehouse.metastoreUri您先前從 hive.metastore.uris 取得的值。 spark.security.credentials.hiveserver2.enabled若為 YARN 叢集模式則為 true,若為 YARN 用戶端模式則為false。spark.hadoop.hive.zookeeper.quorum您先前從 hive.zookeeper.quorum 取得的值。 spark.hadoop.hive.llap.daemon.service.hosts您先前從 hive.llap.daemon.service.hosts 取得的值。 儲存變更並重新啟動所有受影響的元件。
設定企業安全性套件 (ESP) 叢集的 HWC
企業安全性套件 (ESP) 會為 Azure HDInsight 中的 Apache Hadoop 叢集提供企業級的功能,例如 Active Directory 型驗證、多使用者支援和角色型存取控制。 如需 ESP 的詳細資訊,請參閱在 HDInsight 中使用企業安全性套件。
除了上一節提到的設定外,請再新增下列設定以在 ESP 叢集上使用 HWC。
從 Spark 叢集的 Ambari Web UI,瀏覽至 [Spark2]>[設定]>[自訂 Spark2-defaults]。
更新下列屬性。
組態 值 spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>從網頁瀏覽器,瀏覽至
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary,其中 CLUSTERNAME 是您的 Interactive Query 叢集名稱。 按一下 [HiveServer2 Interactive]。 您會看到 LLAP 執行所在前端節點的完整網域名稱 (FQDN),如螢幕擷取畫面所示。 以此值取代<llap-headnode>。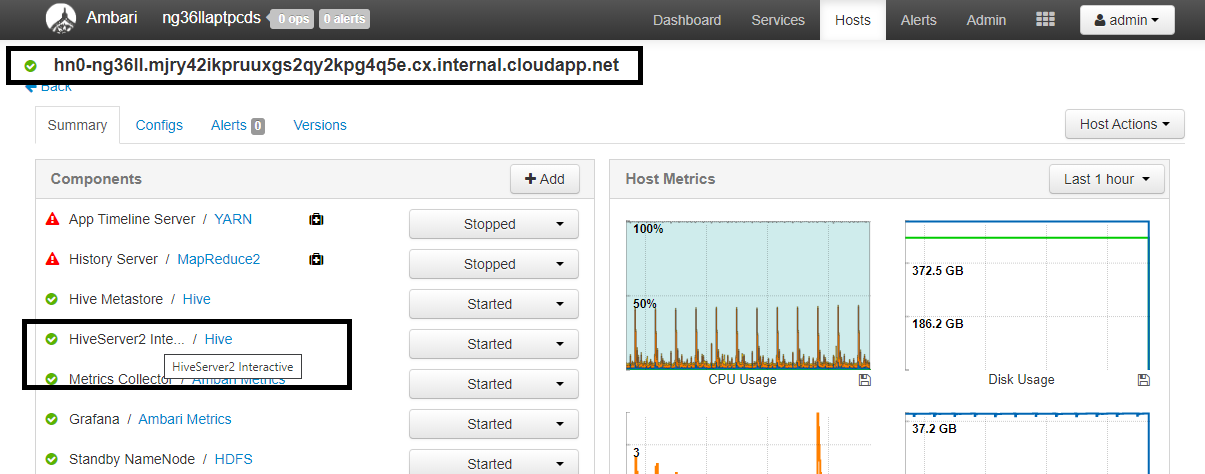
使用 ssh 命令來連線到 Interactive Query 叢集。 在
/etc/krb5.conf檔案中尋找default_realm參數。 以此值取代<AAD-DOMAIN>成為大寫字串,否則找不到認證。
例如
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET。
儲存變更並視需要重新啟動元件。
Hive Warehouse Connector 使用方式
您可以選擇幾種不同的方法來連線到 Interactive Query 叢集,並使用 Hive Warehouse Connector 執行查詢。 支援的方法包括下列工具:
以下是從 Spark 連線到 HWC 的一些範例。
Spark-shell
這是透過修改過的 Scala 殼層版本以互動方式執行 Spark 的方式。
使用 ssh 命令來連線到 Apache Spark 叢集。 編輯以下命令並將 CLUSTERNAME 取代為您叢集的名稱,然後輸入命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net從 ssh 工作階段執行下列命令,以記下
hive-warehouse-connector-assembly版本:ls /usr/hdp/current/hive_warehouse_connector使用上面所識別的
hive-warehouse-connector-assembly版本來編輯下列程式碼。 然後執行命令以啟動 Spark 殼層:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false啟動 Spark 殼層之後,您可以使用下列命令來啟動 Hive Warehouse Connector 執行個體:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit 是一個公用程式,可將任何 Spark 程式 (或作業) 提交至 Spark 叢集。
spark-submit 作業會依照我們的指示來設定 Spark 和 Hive Warehouse Connector、執行我們傳遞給它的程式,然後完全釋出正在使用的資源。
一旦您將 scala/java 程式碼和相依性建置到組件 jar 後,請使用下列命令來啟動 Spark 應用程式。 以實際的值取代 <VERSION> 和 <APP_JAR_PATH>。
YARN 用戶端模式
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN 叢集模式
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
當我們以 pySpark 中撰寫整個應用程式並封裝至 .py 檔案 (Python) 後,也會使用此公用程式,以便將整個程式碼提交至 Spark 叢集進行執行。
對於 Python 應用程式,請傳遞 .py 檔案來取代 /<APP_JAR_PATH>/myHwcAppProject.jar,並使用 --py-files 將以下組態 (Python .zip) 檔案新增至搜尋路徑。
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
在企業安全性套件 (ESP) 叢集上執行查詢
在啟動 spark-shell 或 spark-submit 之前,請先使用 kinit。 將 USERNAME 取代為具有叢集存取權限的網域帳戶名稱,然後執行下列命令:
kinit USERNAME
保護 Spark ESP 叢集上的資料
輸入下列命令,以建立具有一些範例資料的資料表
demo:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');使用下列命令來檢視資料表的內容。 在套用原則之前,
demo資料表會顯示完整的資料行。hive.executeQuery("SELECT * FROM demo").show()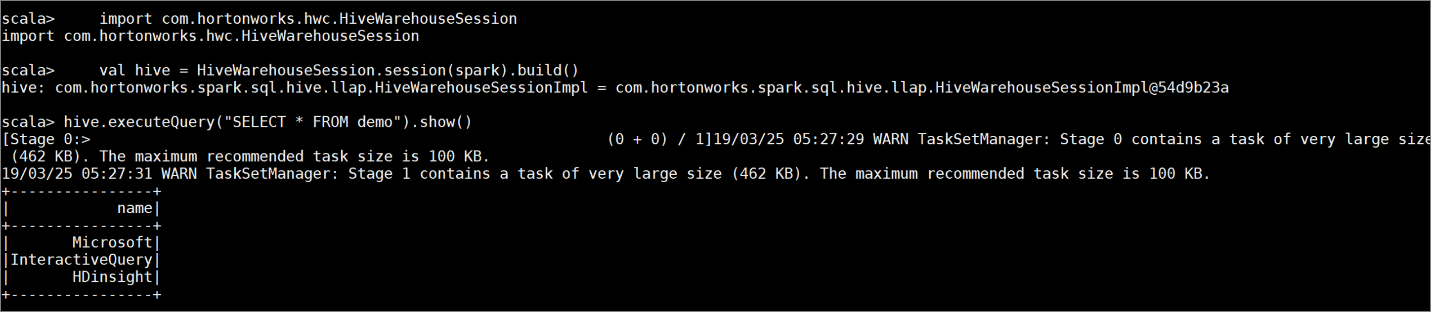
套用資料行遮罩原則以便只顯示資料行的最後四個字元。
移至
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/上的 Ranger 管理員 UI。在 [Hive] 底下按一下叢集的 Hive 服務。
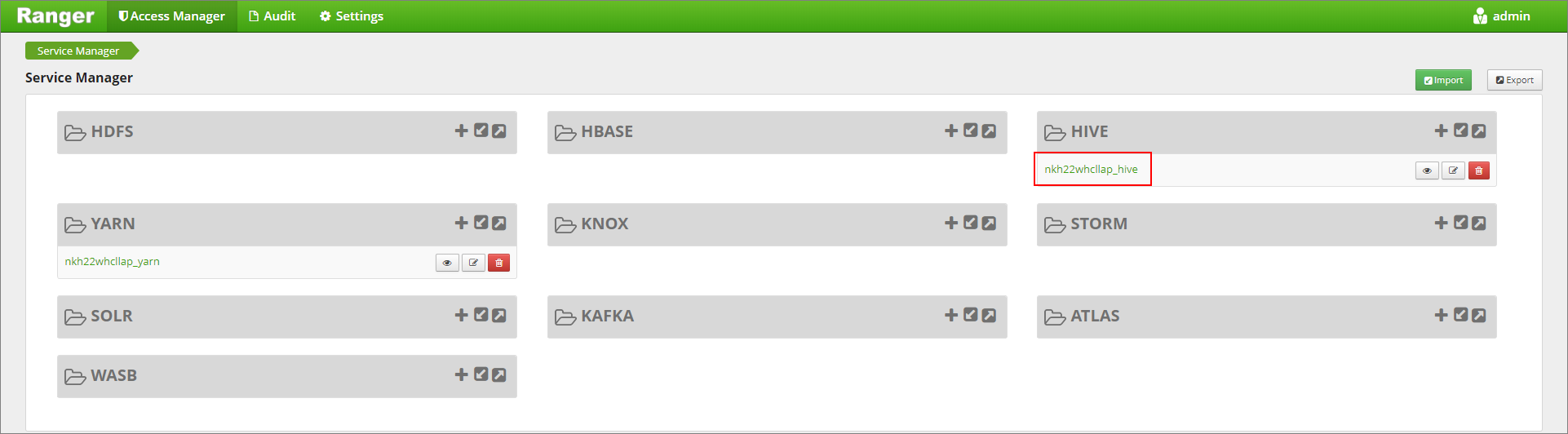
依序按一下 [遮罩] 索引標籤和 [新增原則]
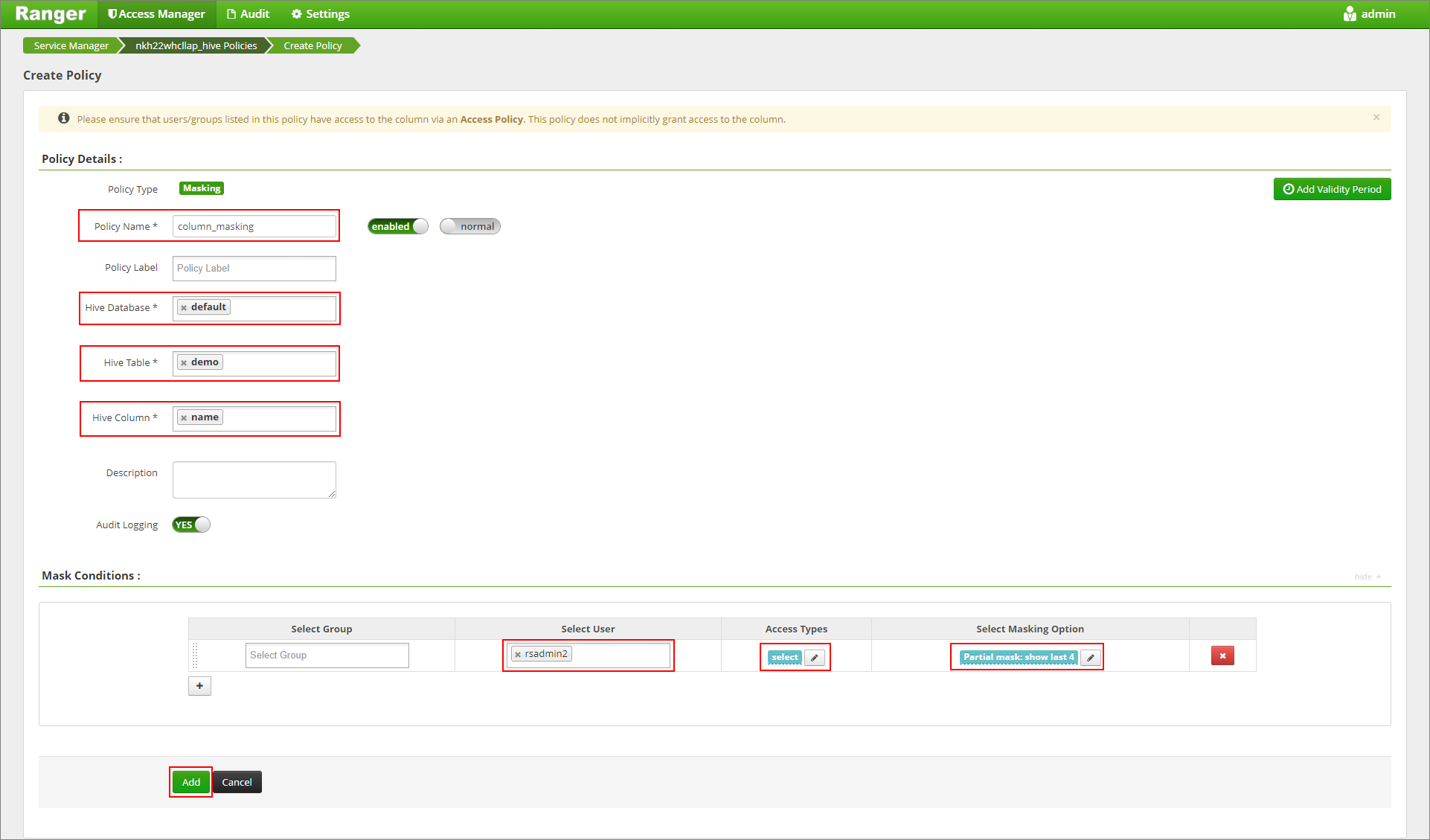
提供所需的原則名稱。 選取資料庫:[預設]、Hive 資料表:[示範]、Hive 資料行:[名稱]、使用者:[rsadmin2]、存取類型:[選取] 和部分遮罩:[顯示最後 4 個] (從 [選取遮罩選項] 功能表中)。 按一下新增。
再次檢視資料表的內容。 套用 ranger 原則之後,我們只能看到資料行的最後四個字元。
