如何選取 Azure Machine Learning 的演算法
如果您想知道要使用哪一種機器學習演算法,則答案主要取決於資料科學案例的兩個層面:
您要如何處理資料? 具體而言,您想從過去的資料學習以解決的業務問題是什麼?
您的資料科學案例有哪些需求? 解決方案支援的功能、正確性、訓練時間、線性和參數為何?
注意
Azure Machine Learning 設計工具支援兩種類型的元件:傳統預先建置的元件 (v1) 和自訂元件 (v2)。 這兩種類型的元件互不相容。
傳統預先建置元件主要用於資料處理和傳統機器學習工作 (例如迴歸和分類)。 此類型的元件會繼續受到支援,但將不會新增任何新元件。
自訂元件可讓您包裝自己的程式碼作為元件。 其支援跨工作區共用元件,及跨工作室、CLI v2 和 SDK v2 介面的無縫製作。
對於新專案,我們強烈建議您使用與 AzureML V2 相容的自訂元件,且會持續接收新的更新。
本文適用於傳統預先建置元件,且與 CLI v2 和 SDK v2 不相容。
Azure Machine Learning 演算法小祕技
Azure Machine Learning 演算法速查表可協助您進行首個考量:您要如何處理資料?在速查表上,尋找您想要執行的工作,然後尋找預測性分析解決方案的 Azure Machine Learning 設計工具演算法。
注意
您可以下載 Machine Learning 演算法速查表 (英文)。
設計工具提供完整的演算法組合,例如多類別決策樹系、建議系統、神經網路迴歸、多元神經網路,以及K-Means 叢集。 每種演算法皆是設計用來處理不同類型的機器學習問題。 如需完整清單、每種演算法的運作方式,以及如何微調參數將演算法最佳化的相關文件,請參閱演算法和元件參考。
除了本指南之外,選擇機器學習演算法時,請記住其他需求。 以下是要考慮的其他因素,例如正確性、定型時間、線性、參數數目和特徵數目。
機器學習演算法的比較
有些演算法會對資料結構或想要的結果做出特定假設。 如果可以找到符合需求的假設,您就能獲得更實用的結果、更精確的預測或更快的定型時間。
下表摘要說明來自分類、迴歸和叢集系列的一些最重要演算法特性:
| 演算法 | 準確度 | 定型時間 | 線性 | 參數 | 注意事項 |
|---|---|---|---|---|---|
| 分類系列 | |||||
| 二元羅吉斯迴歸 | 良好 | 快速 | Yes | 4 | |
| 二元決策樹系 | 非常好 | 中等 | No | 5 | 顯示較慢的評分時間。 我們建議不要使用「一對多」多元分類,因為在累積的樹狀結構預測中執行緒鎖定會造成評分時間較慢 |
| 二元促進式決策樹 | 非常好 | 中等 | No | 6 | 高記憶體使用量 |
| 二元神經網路 | 良好 | 中等 | No | 8 | |
| 二元平均感知器 | 良好 | 中等 | Yes | 4 | |
| 二元支援向量機器 | 良好 | 快速 | Yes | 5 | 適用於大型特徵集 |
| 多元羅吉斯迴歸 | 良好 | 快速 | Yes | 4 | |
| 多元決策樹系 | 非常好 | 中等 | No | 5 | 顯示較慢的評分時間 |
| 多元促進式決策樹 | 非常好 | 中等 | No | 6 | 通常會減少涵蓋範圍,藉由承擔小型風險來改善精確度 |
| 多元神經網路 | 良好 | 中等 | No | 8 | |
| 「一對多」多元分類 | - | - | - | - | 請參閱選取的兩個類別方法的屬性 |
| 迴歸系列 | |||||
| 線性迴歸 | 良好 | 快速 | Yes | 4 | |
| 決策樹系迴歸 | 非常好 | 中等 | No | 5 | |
| 促進式決策樹迴歸 | 非常好 | 中等 | No | 6 | 高記憶體使用量 |
| 神經網路迴歸 | 良好 | 中等 | No | 8 | |
| 叢集系列 | |||||
| K-Means 叢集 | 非常好 | 中等 | Yes | 8 | 叢集演算法 |
資料科學案例需求
在您知道要如何處理資料後,就須要判斷資料科學案例的其他需求。
進行下列需求的選擇和其可能帶來的取捨:
- 準確率
- 定型時間
- 線性
- 參數數目
- 特徵數目
準確率
機器學習正確性是以整體案例中結果為真的比例,來衡量模型的效能。 在設計工具中,評估模型元件會計算一組業界標準的評估計量。 您可使用此元件測量已定型模型的正確性。
您不一定需要取得最準確的答案。 視您的用途而定,有時候近似值便已足夠。 如果是這樣,您即可採用近似法,並大幅縮短處理時間。 近似法也可能避免過度學習。
使用 [評估模型] 元件的方式有三種:
- 產生定型資料的分數以評估模型。
- 產生模型分數,但會與保留的測試集進行比較。
- 使用相同的資料集,比較兩個不同但相關模型的分數。
如需可用來評估機器學習模型正確性的計量和方法完整清單,請參閱〈評估模型元件〉。
定型時間
在監督式學習中,定型表示使用歷程記錄資料來建置機器學習模型,以將錯誤降至最低。 定型出一個模型可能需要幾分鐘或幾小時,這在各個演算法間有很大的差異。 定型時間通常取決於正確性,這兩者的關係密不可分。
此外,有些演算法對資料點的數目較為敏感。 由於具有時間限制,因此您可以選擇特定的演算法,尤其是當資料集很大時。
在設計工具中,建立和使用機器學習模型通常是三步驟的流程:
選擇特定類型的演算法並定義其參數或超參數來設定模型。
定型完成之後,請使用定型的模型搭配其中一個評分元件,以針對新資料進行預測。
線性
統計資料和機器學習中的線性,表示資料集內的變數和常數之間有線性關聯性。 例如,線性分類演算法會假設可以用直線 (或較高維度類比) 來分隔類別。
許多機器學習演算法都會使用線性。 在 Azure Machine Learning 設計工具中,它們包含:
線性迴歸演算法會假設資料趨勢依循著一條直線。 對某些問題來說這種假設並沒有錯,但對其他問題來說則會降低正確性。 儘管有其缺點,線性演算法也是最常見的首要策略。 這種演算法定型起來通常又快又簡單。
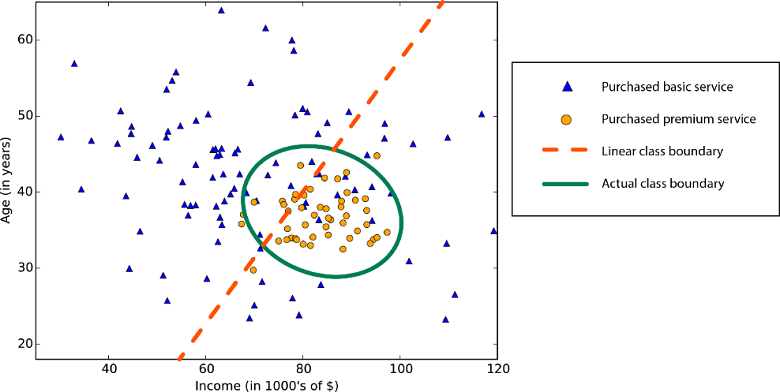
非線性類別界限:仰賴線性分類演算法會造成低正確性的結果。
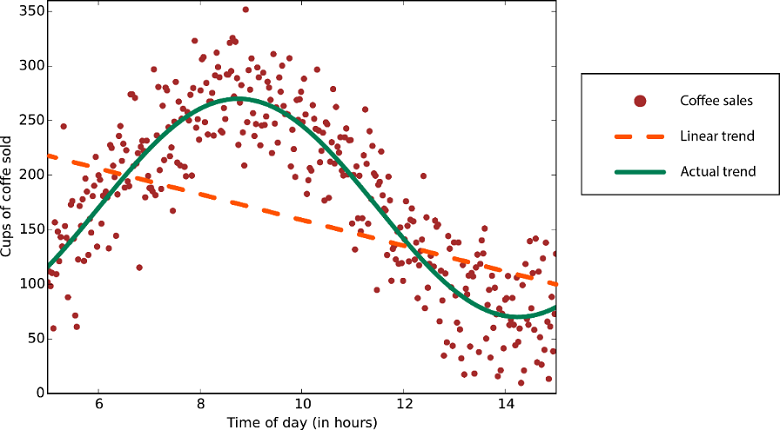
具有非線性趨勢的資料:使用線性迴歸方法會產生較大且不必要的誤差。
參數數目
參數是資料科學家在設定演算法時的必經之路。 參數就是會影響演算法行為的數值,例如容錯或反覆運算次數,或是演算法運作方式的變化選項。 定型時間和演算法的正確性,有時很容易會因為設定是否正確而受到影響。 一般而言,具有大量參數的演算法需要最多次的反覆試驗,才能找出良好的組合。
或者,設計工具中有調整模型超參數元件。 此元件的目標是判斷機器學習模型的最佳超參數。 此元件會使用不同的設定組合來建置和測試多個模型。 其會比較所有模型的計量,以取得設定的組合。
雖然這是確保定義生成參數空間的好方法,但定型模型時所需的時間會隨參數數目而呈指數增加。 一般而言,具有許多參數的優點是可讓演算法有更大的彈性。 若您可以找到正確的參數設定組合,通常可以達到非常好的正確性。
特徵數目
在機器學習中,特徵是您所嘗試分析之現象的可量化變數。 就特定的資料類型而言,可能會有比資料點數目更龐大的特徵數目。 基因學或文字資料通常屬於這種情況。
大量的特徵可能會拖累部分學習演算法,讓定型時間長到無法作業。 支援向量機器適用於具有大量特徵的案例。 基於這個理由,許多應用程式都採用這個方式,從資訊擷取到文字和影像分類皆然。 支援向量機器可用於分類和迴歸工作。
特徵選取是指在指定的輸出中,將統計測試套用至輸入的流程。 其目標在於判斷輸出中的哪些資料行較具有預測性。 設計工具中的「以篩選為基礎的特徵選取元件」提供多種特徵選取演算法可供選擇。 此元件包含相互關聯方法,例如皮耳森相互關聯和卡方值。
您也可以使用排列特徵重要性元件,來計算資料集的一組特徵重要性分數。 然後,您可以使用這些分數,協助您判斷要在模型中使用的最佳特徵。