Lakehouse 教學課程:準備和轉換 Lakehouse 中的數據
在本教學課程中,您會搭配 Spark 運行時間 使用筆記本,在 Lakehouse 中轉換和準備原始數據。
必要條件
如果您沒有包含資料的 Lakehouse,您必須:
- 建立 Lakehouse,以及
- 將數據內嵌到湖屋。
準備資料
從先前的教學課程步驟中,我們已從來源擷取原始數據到 Lakehouse 的 [檔案 ] 區段。 現在您可以轉換該數據,並準備建立 Delta 數據表。
從 Lakehouse 教學課程原始碼 資料夾下載筆記本。
從位於畫面左下方的切換器中,選取 [資料工程師。
![顯示尋找切換器位置並選取 [資料工程師] 的螢幕快照。](media/tutorial-lakehouse-data-preparation/workload-switcher-data-engineering.png)
從登陸頁面頂端的 [新增] 區段選取 [匯入筆記本]。
從畫面右側開啟的 [匯入狀態] 窗格中選取 [上傳]。
選取您在本節第一個步驟中下載的所有筆記本。
![此螢幕快照顯示何處可尋找下載的筆記本和 [開啟] 按鈕。](media/tutorial-lakehouse-data-preparation/select-notebooks-open.png)
選取開啟。 指出匯入狀態的通知會出現在瀏覽器視窗右上角。
匯入成功之後,請移至工作區的項目檢視,並查看新匯入的筆記本。 選取 wwilakehouse lakehouse 以開啟它。
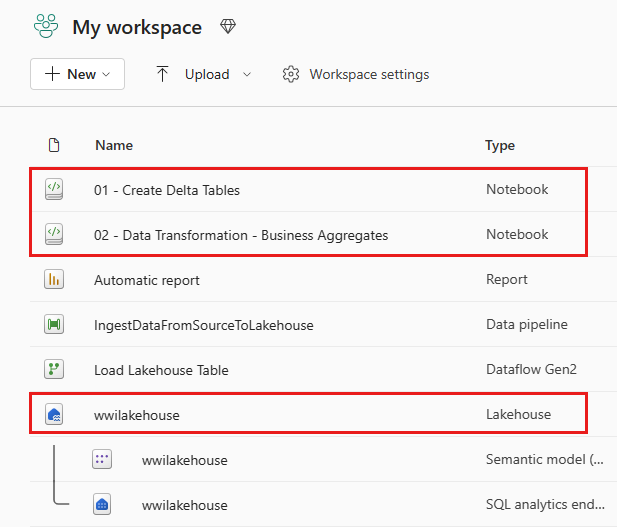
開啟 wwilakehouse Lakehouse 之後,請從頂端導覽功能表中選取 [開啟筆記本現有筆記本>]。
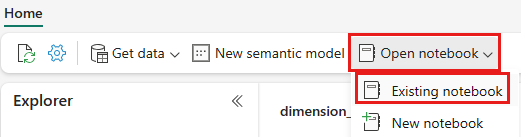
從現有筆記本清單中,選取 [01 - 建立差異數據表] 筆記本,然後選取 [ 開啟]。
在 Lakehouse Explorer 的開啟筆記本中,您會看到筆記本已連結至已開啟的 Lakehouse。
在 Lakehouse 的 [資料表] 區段中將數據寫入為 Delta Lake Tables 之前,您會使用兩個網狀架構功能(V 順序和優化寫入)來將數據寫入優化,並改善讀取效能。 若要在您的工作階段中啟用這些功能,請在筆記本的第一個數據格中設定這些設定。
若要啟動筆記本並依序執行所有儲存格,請選取頂端功能區上的[全部執行] (首頁下方)。 或者,若要只從特定單元格執行程式碼,請選取 滑鼠暫留時出現在單元格左邊的 [執行 ] 圖示,或在控件位於單元格中時按 鍵盤上的 SHIFT + ENTER 。
![Spark 工作階段設定畫面的螢幕快照,包括程式代碼資料格和 [執行] 圖示。](media/tutorial-lakehouse-data-preparation/spark-session-run-execution.png)
執行數據格時,您不需要指定基礎 Spark 集區或叢集詳細數據,因為 Fabric 會透過 Live Pool 提供它們。 每個網狀架構工作區都隨附預設 Spark 集區,稱為「即時集區」。 這表示當您建立筆記本時,不需要擔心指定任何 Spark 組態或叢集詳細數據。 當您執行第一個筆記本命令時,即時集區會在幾秒鐘內啟動並執行。 而且會建立Spark工作階段,並開始執行程式代碼。 當 Spark 工作階段處於使用中狀態時,此筆記本中的後續程式代碼執行幾乎瞬間完成。
接下來,您會從 Lakehouse 的 [檔案 ] 區段讀取原始數據,並在轉換中新增更多不同日期部分的數據行。 最後,您可以使用數據分割 By Spark API 將數據分割,然後再根據新建立的數據部分數據行 (Year 和 Quarter) 將它寫入為 Delta 數據表格式。
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)在事實數據表載入之後,您可以繼續載入其餘維度的數據。 下列數據格會建立函式,從 Lakehouse 的 Files 區段讀取作為參數傳遞之每個數據表名稱的原始數據。 接下來,它會建立維度數據表的清單。 最後,它會迴圈查看資料表清單,併為從輸入參數讀取的每個數據表名稱建立 Delta 資料表。 請注意,腳本會卸除此範例中名為
Photo的數據行,因為未使用數據行。from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)若要驗證已建立的數據表,請以滑鼠右鍵按兩下並選取 wwilakehouse Lakehouse 上的重新整理。 數據表隨即出現。
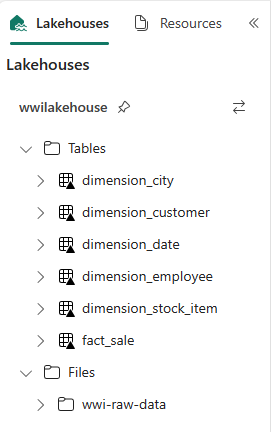
再次移至工作區的項目檢視,然後選取 wwilakehouse Lakehouse 加以開啟。
現在,開啟第二個筆記本。 在 Lakehouse 檢視中,從功能區選取 [開啟筆記本現有的筆記本>]。
從現有筆記本清單中,選取 02 - 資料轉換 - 商務 筆記本加以開啟。
![[開啟現有筆記本] 功能表的螢幕快照,其中顯示要選取筆記本的位置。](media/tutorial-lakehouse-data-preparation/existing-second-notebook.png)
在 Lakehouse Explorer 的開啟筆記本中,您會看到筆記本已連結至已開啟的 Lakehouse。
組織可能會有數據工程師使用 Scala/Python,以及其他使用 SQL 的數據工程師(Spark SQL 或 T-SQL),都處理相同的數據複本。 網狀架構可讓這些不同的群組使用不同的體驗和喜好設定,以工作和共同作業。 這兩種不同的方法會轉換併產生商務匯總。 您可以挑選適合您的方法,或根據您的喜好設定來混合和比對這些方法,而不會影響效能:
方法 #1 - 使用 PySpark 聯結和匯總數據,以產生商務匯總。 這個方法最好是具有程序設計背景(Python 或 PySpark) 背景的人員。
方法 #2 - 使用 Spark SQL 聯結和匯總數據,以產生商務匯總。 此方法最好是具有 SQL 背景、轉換至 Spark 的人員。
方法 #1 (sale_by_date_city) - 使用 PySpark 聯結和匯總數據來產生商務匯總。 使用下列程序代碼,您會建立三個不同的 Spark 數據框架,每個架構都會參考現有的 Delta 數據表。 然後,您可以使用數據框架來聯結這些數據表、執行分組來產生匯總、重新命名幾個數據行,最後將其寫入 Lakehouse 的 [數據表 ] 區段中的 Delta 數據表,以保存數據。
在此數據格中,您會建立三個不同的 Spark 數據框架,每個框架都會參考現有的 Delta 數據表。
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")在此數據格中,您會使用稍早建立的數據框架來聯結這些數據表、執行分組來產生匯總、重新命名幾個數據行,最後將其寫入 Lakehouse 的 [ 數據表 ] 區段中的 Delta 數據表。
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")方法 #2 (sale_by_date_employee) - 使用 Spark SQL 聯結和匯總數據,以產生商務匯總。 使用下列程式代碼,您可以聯結三個數據表來建立暫存 Spark 檢視、執行分組以產生匯總,以及重新命名其中一些數據行。 最後,您會從暫存的 Spark 檢視讀取,最後將其寫入 Lakehouse 之 [ 數據表 ] 區段中的 Delta 數據表,以保存數據。
在此數據格中,您會聯結三個數據表來建立暫存 Spark 檢視、執行分組以產生匯總,以及重新命名幾個數據行。
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC在此數據格中,您會從上一個單元格中建立的暫存 Spark 檢視讀取,最後將其寫入 Lakehouse 的 [數據表 ] 區段中做為 Delta 數據表。
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")若要驗證已建立的數據表,請在 wwilakehouse Lakehouse 上按兩下滑鼠右鍵,然後選取 [重新整理]。 匯總數據表隨即出現。
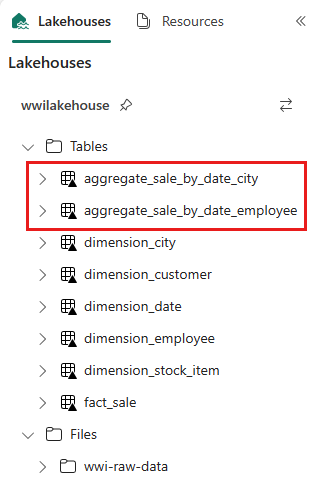
這兩種方法會產生類似的結果。 若要將學習新技術或效能危害的需求降到最低,請選擇最符合背景和喜好設定的方法。
您可能會注意到您正在將數據寫入為 Delta Lake 檔案。 Fabric 的自動數據表探索和註冊功能會在中繼存放區中挑選並加以註冊。 您不需要明確呼叫 CREATE TABLE 語句,即可建立要與 SQL 搭配使用的數據表。