Osvědčené postupy pro nasazení a spolehlivost clusteru pro Službu Azure Kubernetes Service (AKS)
Tento článek obsahuje osvědčené postupy pro spolehlivost clusteru implementovanou na úrovni nasazení i clusteru pro úlohy Azure Kubernetes Service (AKS). Článek je určený pro operátory clusteru a vývojáře, kteří zodpovídají za nasazování a správu aplikací v AKS.
Osvědčené postupy v tomto článku jsou uspořádané do následujících kategorií:
Osvědčené postupy na úrovni nasazení
Následující osvědčené postupy na úrovni nasazení pomáhají zajistit vysokou dostupnost a spolehlivost vašich úloh AKS. Tyto osvědčené postupy jsou místní konfigurace, které můžete implementovat v souborech YAML pro vaše pody a nasazení.
Poznámka:
Při každém nasazení aktualizace do aplikace se ujistěte, že tyto osvědčené postupy implementujete. Pokud ne, může docházet k problémům s dostupností a spolehlivostí vaší aplikace, například neúmyslným výpadkem aplikace.
Rozpočty přerušení podů (PDB)
Pokyny k osvědčeným postupům
Rozpočty přerušení podů (PDB) použijte k zajištění, že minimální počet podů zůstane dostupný během dobrovolného přerušení, jako jsou operace upgradu nebo náhodné odstranění podů.
Rozpočty přerušení podů umožňují definovat, jak nasazení nebo sady replik reagují během dobrovolného přerušení, jako jsou operace upgradu nebo náhodné odstranění podů. Pomocí souborů PDB můžete definovat minimální nebo maximální počet prostředků, které nejsou k dispozici. Soubory PDB ovlivňují pouze vyřazování rozhraní API pro dobrovolné přerušení.
Řekněme například, že potřebujete provést upgrade clusteru a už máte definovaný soubor PDB. Před upgradem clusteru plánovač Kubernetes zajistí, aby byl k dispozici minimální počet podů definovaných v souboru PDB. Pokud by upgrade způsobil, že počet dostupných podů klesne pody podů definované v souborech PDB, plánovač naplánuje další pody na jiných uzlech před povolením upgradu pokračovat. Pokud soubor PDB nenastavíte, plánovač nemá žádná omezení počtu podů, které můžou být během upgradu nedostupné, což může vést k nedostatku prostředků a potenciálním výpadkům clusteru.
V následujícím příkladu definiční soubor minAvailable PDB nastaví pole minimální počet podů, které musí zůstat dostupné během dobrovolného přerušení. Hodnota může být absolutní číslo (například 3) nebo procento požadovaného počtu podů (například 10 %).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
Další informace najdete v tématu Plánování dostupnosti pomocí souborů PDB a zadání rozpočtu přerušení pro vaši aplikaci.
Omezení procesoru a paměti podů
Pokyny k osvědčeným postupům
Nastavte omezení procesoru a paměti podů pro všechny pody, abyste zajistili, že pody nebudou využívat všechny prostředky na uzlu a zajistí ochranu při hrozbách služeb, jako jsou útoky DDoS.
Omezení procesoru a paměti podu definují maximální množství procesoru a paměti, které může pod používat. Když pod překročí definované limity, označí se k odebrání. Další informace najdete v tématu Jednotky prostředků procesoru v Kubernetes a jednotky prostředků paměti v Kubernetes.
Nastavení limitů procesoru a paměti pomáhá udržovat stav uzlu a minimalizovat dopad na ostatní pody na uzlu. Vyhněte se nastavení limitu podu vyššího, než můžou uzly podporovat. Každý uzel AKS si vyhrazuje nastavené množství procesoru a paměti pro základní komponenty Kubernetes. Pokud nastavíte limit podů vyšší, než může uzel podporovat, může se vaše aplikace pokusit spotřebovat příliš mnoho prostředků a negativně ovlivnit ostatní pody na uzlu. Správci clusteru musí nastavit kvóty prostředků v oboru názvů, který vyžaduje nastavení požadavků na prostředky a omezení. Další informace najdete v tématu Vynucení kvót prostředků v AKS.
V následujícím ukázkovém definičním souboru podu resources oddíl nastaví omezení procesoru a paměti pro pod:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
Tip
Pomocí příkazu můžete kubectl describe node zobrazit kapacitu procesoru a paměti uzlů, jak je znázorněno v následujícím příkladu:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
Další informace naleznete v tématu Přiřazení prostředků procesoru ke kontejnerům a podům a přiřazení prostředků paměti ke kontejnerům a podům.
Představné háky
Pokyny k osvědčeným postupům
Pokud je to možné, použijte představovací háky k zajištění odkladu ukončení kontejneru.
Volání PreStop háku se volá bezprostředně před ukončením kontejneru z důvodu události požadavku nebo správy rozhraní API, jako je preemption, kolize prostředků nebo chyba živého nebo spouštěcího testu. Volání PreStop háku selže, pokud je kontejner již v ukončeném nebo dokončeném stavu a háček se musí dokončit před odesláním signálu TERM. Odpočítávání období odkladu ukončení podu začíná před spuštěním PreStop háku, takže se kontejner nakonec ukončí během období odkladu ukončení.
Následující ukázkový definiční soubor podu PreStop ukazuje, jak pomocí háku zajistit řádné ukončení kontejneru:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
Další informace najdete v tématu háky životního cyklu kontejneru a ukončení podů.
maxUnavailable
Pokyny k osvědčeným postupům
Pomocí pole v nasazení definujte maximální počet podů, které můžou být během postupné aktualizace
maxUnavailablenedostupné, abyste zajistili, že během upgradu zůstane dostupný minimální počet podů.
Pole maxUnavailable určuje maximální počet podů, které mohou být během procesu aktualizace nedostupné. Hodnota může být absolutní číslo (například 3) nebo procento požadovaného počtu podů (například 10 %). maxUnavailable se týká rozhraní API pro odstranění, které se používá při kumulativních aktualizacích.
Následující ukázkový manifest nasazení používá maxAvailable pole k nastavení maximálního počtu podů, které mohou být během procesu aktualizace nedostupné:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the upgrade
Další informace naleznete v tématu Maximální nedostupnost.
Omezení rozložení topologie podů
Pokyny k osvědčeným postupům
Pomocí omezení šíření topologie podů zajistěte, aby se pody rozprostřely mezi různé uzly nebo zóny, aby se zlepšila dostupnost a spolehlivost.
Omezení šíření topologie podů můžete použít k řízení rozložení podů napříč clusterem na základě topologie uzlů a rozložení podů mezi různé uzly nebo zóny za účelem zlepšení dostupnosti a spolehlivosti.
Následující ukázkový definiční soubor podů ukazuje, jak použít topologySpreadConstraints pole k rozložení podů mezi různé uzly:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
Další informace naleznete v tématu Omezení rozložení topologie podů.
Testy připravenosti, aktivity a spouštění
Pokyny k osvědčeným postupům
Nakonfigurujte testy připravenosti, aktivity a spouštění, pokud je to možné, aby se zlepšila odolnost při vysokých zatíženích a nižších restartováních kontejnerů.
Testy připravenosti
V Kubernetes kubelet používá sondy připravenosti ke zjištění, kdy je kontejner připravený začít přijímat provoz. Pod je považovaný za připravený , jakmile budou všechny jeho kontejnery připravené. Pokud pod není připravený, odebere se z nástrojů pro vyrovnávání zatížení služeb. Další informace najdete v tématu Testy připravenosti v Kubernetes.
Následující ukázkový definiční soubor podu ukazuje konfiguraci sondy připravenosti:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Další informace najdete v tématu Konfigurace testů připravenosti.
Sondy živé aktivity
V Kubernetes kubelet používá sondy živé aktivity, které zjistí, kdy se má kontejner restartovat. Pokud kontejner selže se sondou aktivity, kontejner se restartuje. Další informace najdete v tématu Sondy živé aktivity v Kubernetes.
Následující ukázkový definiční soubor podu ukazuje konfiguraci sondy aktivity:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
Jiný druh sondy aktivity používá požadavek HTTP GET. Následující ukázkový definiční soubor podu ukazuje konfiguraci sondy živé aktivity požadavku HTTP GET:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Další informace najdete v tématu Konfigurace sond aktivity a definování požadavku HTTP na liveness.
Spouštěcí sondy
V Kubernetes kubelet používá spouštěcí sondy ke zjištění, kdy se spustila aplikace kontejneru. Když nakonfigurujete spouštěcí sondu, testy připravenosti a aktivity se nespustí, dokud se spouštěcí sonda nepovedá, zajistíte, aby testy připravenosti a aktivity nenarušovaly spuštění aplikace. Další informace najdete v tématu Spouštěcí sondy v Kubernetes.
Následující ukázkový definiční soubor podu ukazuje konfiguraci sondy po spuštění:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
Aplikace s více replikou
Pokyny k osvědčeným postupům
Nasaďte aspoň dvě repliky aplikace, abyste zajistili vysokou dostupnost a odolnost ve scénářích mimo uzly.
V Kubernetes můžete pomocí replicas pole v nasazení určit počet podů, které chcete spustit. Spouštění více instancí aplikace pomáhá zajistit vysokou dostupnost a odolnost ve scénářích mimo uzly. Pokud máte povolené zóny dostupnosti, můžete pomocí replicas pole určit počet podů, které chcete spustit napříč několika zónami dostupnosti.
Následující ukázkový definiční soubor podů ukazuje, jak pomocí replicas pole určit počet podů, které chcete spustit:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Další informace najdete v tématu Doporučené řešení s vysokou dostupností aktivní-aktivní pro AKS a repliky ve specifikacích nasazení.
Osvědčené postupy na úrovni clusteru a fondu uzlů
Následující osvědčené postupy na úrovni clusteru a fondu uzlů pomáhají zajistit vysokou dostupnost a spolehlivost clusterů AKS. Tyto osvědčené postupy můžete implementovat při vytváření nebo aktualizaci clusterů AKS.
Zóny dostupnosti
Pokyny k osvědčeným postupům
Při vytváření clusteru AKS použijte více zón dostupnosti, abyste zajistili vysokou dostupnost ve scénářích mimo zónu. Mějte na paměti, že po vytvoření clusteru nemůžete změnit konfiguraci zóny dostupnosti.
Zóny dostupnosti jsou oddělené skupiny datacenter v rámci oblasti. Tyto zóny jsou dostatečně blízko, aby měly připojení s nízkou latencí k sobě navzájem, ale dostatečně daleko od sebe, aby se snížila pravděpodobnost, že místní výpadky nebo počasí ovlivní více než jednu zónu. Používání zón dostupnosti pomáhá vašim datům zůstat synchronizovaná a přístupná ve scénářích mimo zónu. Další informace naleznete v tématu Spuštění ve více zónách.
Automatické škálování clusteru
Pokyny k osvědčeným postupům
Pomocí automatického škálování clusteru se ujistěte, že váš cluster dokáže zvládnout zvýšené zatížení a snížit náklady během nízké zátěže.
Abyste udrželi krok s požadavky aplikací v AKS, možná budete muset upravit počet uzlů, na kterých běží vaše úlohy. Komponenta automatického škálování clusteru sleduje pody v clusteru, které nelze naplánovat kvůli omezením prostředků. Když automatické škálování clusteru zjistí problémy, škáluje počet uzlů ve fondu uzlů tak, aby splňoval požadavky aplikace. Také pravidelně kontroluje, jestli uzly nemají spuštěné pody, a podle potřeby vertikálně navyšuje kapacitu počtu uzlů. Další informace najdete v tématu Automatické škálování clusteru v AKS.
Parametr můžete použít --enable-cluster-autoscaler při vytváření clusteru AKS k povolení automatického škálování clusteru, jak je znázorněno v následujícím příkladu:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
Automatické škálování clusteru můžete také povolit ve stávajícím fondu uzlů a nakonfigurovat podrobnější podrobnosti automatického škálování clusteru změnou výchozích hodnot v profilu automatického škálování v rámci clusteru.
Další informace najdete v tématu Použití automatického škálování clusteru v AKS.
Load Balancer úrovně Standard
Pokyny k osvědčeným postupům
Load Balancer úrovně Standard umožňuje poskytovat větší spolehlivost a prostředky, podporovat více zón dostupnosti, sondy HTTP a funkce napříč několika datovými centry.
V Azure je skladová položka Load Balanceru úrovně Standard navržená tak, aby byla vybavena pro vyrovnávání zatížení síťového provozu, pokud je potřeba vysoký výkon a nízká latence. Load Balancer úrovně Standard směruje provoz v rámci oblastí a napříč oblastmi a do zón dostupnosti za účelem zajištění vysoké odolnosti. Skladová položka Standard je doporučená a výchozí skladová položka, která se má použít při vytváření clusteru AKS.
Důležité
30. září 2025 bude Load Balancer úrovně Basic vyřazen. Další informace najdete v oficiálním oznámení. Doporučujeme použít Load Balancer úrovně Standard pro nová nasazení a upgradovat stávající nasazení na Load Balancer úrovně Standard. Další informace najdete v tématu Upgrade z Load Balanceru úrovně Basic.
Následující příklad ukazuje LoadBalancer manifest služby, který používá Load Balancer úrovně Standard:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
Další informace najdete v tématu Použití standardního nástroje pro vyrovnávání zatížení v AKS.
Tip
Ke správě síťového provozu můžete použít také kontroler příchozího přenosu dat nebo síť služeb, přičemž každá možnost poskytuje různé funkce a možnosti.
Fondy systémových uzlů
Použití vyhrazených fondů systémových uzlů
Pokyny k osvědčeným postupům
Fondy systémových uzlů použijte k zajištění, aby se žádné jiné uživatelské aplikace spouštěly na stejných uzlech, což může způsobit nedostatek prostředků a ovlivnit pody systému.
Pomocí vyhrazených fondů systémových uzlů zajistěte, aby se žádná jiná uživatelská aplikace nespustí na stejných uzlech, což může způsobit nedostatek prostředků a potenciální výpadky clusteru kvůli podmínkám časování. Pokud chcete použít vyhrazený fond systémových uzlů, můžete použít CriticalAddonsOnly taint ve fondu systémových uzlů. Další informace naleznete v tématu Použití fondů systémových uzlů v AKS.
Automatické škálování fondů systémových uzlů
Pokyny k osvědčeným postupům
Nakonfigurujte automatické škálování pro fondy systémových uzlů a nastavte minimální a maximální limity škálování pro fond uzlů.
Pomocí automatického škálování ve fondech uzlů nakonfigurujte minimální a maximální omezení škálování pro fond uzlů. Fond systémových uzlů by měl být vždy schopný škálovat tak, aby splňoval požadavky systémových podů. Pokud fond systémových uzlů nemůže škálovat, cluster vyčerpá prostředky, které pomáhají spravovat plánování, škálování a vyrovnávání zatížení, což může vést k nereagujícímu clusteru.
Další informace najdete v tématu Použití automatického škálování clusteru ve fondech uzlů.
Nejméně tři uzly na fond systémových uzlů
Pokyny k osvědčeným postupům
Zajistěte, aby fondy systémových uzlů měly alespoň tři uzly, aby se zajistila odolnost proti scénářům zablokování/upgradu, což může vést k restartování nebo vypnutí uzlů.
Fondy systémových uzlů se používají ke spouštění systémových podů, jako jsou kube-proxy, coredns a modul plug-in Azure CNI. Doporučujeme zajistit, aby fondy systémových uzlů měly alespoň tři uzly , abyste zajistili odolnost proti scénářům zablokování/upgradu, což může vést k restartování nebo vypnutí uzlů. Další informace naleznete v tématu Správa fondů systémových uzlů v AKS.
Akcelerované síťové služby
Pokyny k osvědčeným postupům
Pomocí akcelerovaných síťových služeb můžete zajistit nižší latenci, snížit zpoždění a snížit využití procesoru na virtuálních počítačích.
Akcelerované síťové služby umožňují virtualizaci rozhraní SR-IOV (Single Root I/O Virtualization) u podporovaných typů virtuálních počítačů, což výrazně zlepšuje výkon sítě.
Následující diagram znázorňuje, jak dva virtuální počítače komunikují s akcelerovanými síťovými službami a bez ní:
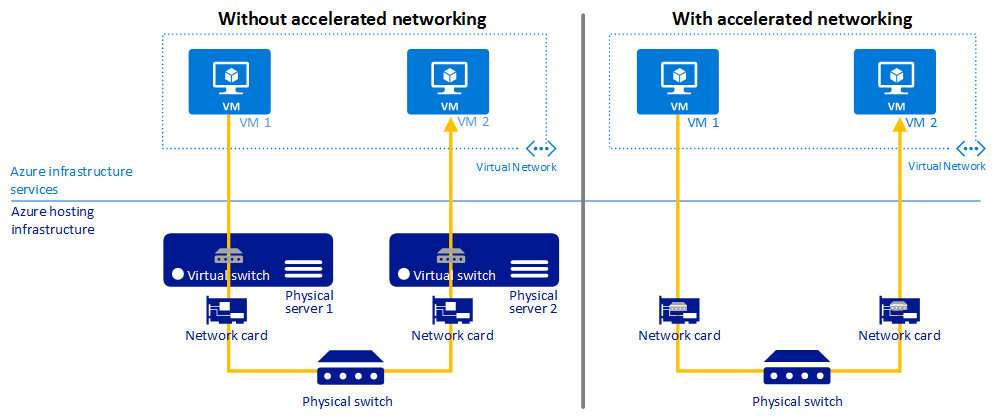
Další informace najdete v tématu Přehled akcelerovaných síťových služeb.
Verze imagí
Pokyny k osvědčeným postupům
Obrázky by neměly používat
latestznačku.
Značky imagí kontejnerů
Použití značky latest pro image kontejnerů může vést k nepředvídatelným chováním a znesnadňuje sledování verze image spuštěné v clusteru. Tato rizika můžete minimalizovat integrací a spuštěním nástrojů pro kontrolu a nápravu v kontejnerech za běhu. Další informace najdete v tématu Osvědčené postupy pro správu imagí kontejnerů v AKS.
Upgrady imagí uzlů
AKS poskytuje několik kanálů automatického upgradu pro upgrady imagí operačního systému uzlů. Tyto kanály můžete použít k řízení načasování upgradů. Doporučujeme připojit se k těmto kanálům automatického upgradu, abyste měli jistotu, že vaše uzly používají nejnovější opravy zabezpečení a aktualizace. Další informace najdete v tématu Automatický upgrade imagí operačního systému uzlu v AKS.
Úroveň Standard pro produkční úlohy
Pokyny k osvědčeným postupům
Úroveň Standard použijte pro úlohy produktů pro větší spolehlivost a prostředky clusteru, podporu až 5 000 uzlů v clusteru a ve výchozím nastavení je povolená smlouva SLA pro dobu provozu. Pokud potřebujete LTS, zvažte použití úrovně Premium.
Úroveň Standard pro Azure Kubernetes Service (AKS) poskytuje pro vaše produkční úlohy finančně zajištěnou smlouvu o 99,9% době provozuschopnosti (SLA). Úroveň Standard také poskytuje větší spolehlivost a prostředky clusteru, podporu až 5 000 uzlů v clusteru a ve výchozím nastavení je povolená smlouva SLA pro dobu provozu. Další informace najdete v tématu Cenové úrovně pro správu clusteru AKS.
Azure CNI pro dynamické přidělování IP adres
Pokyny k osvědčeným postupům
Nakonfigurujte Azure CNI pro dynamické přidělování IP adres, aby se zlepšilo využití IP adres a zabránilo vyčerpání IP adres pro clustery AKS.
Funkce dynamického přidělování IP adres v Azure CNI přiděluje IP adresy podů z podsítě oddělené od podsítě hostující cluster AKS a nabízí následující výhody:
- Lepší využití IP adres: IP adresy se dynamicky přidělují podům clusteru z podsítě Pod. To vede k lepšímu využití IP adres v clusteru v porovnání s tradičním řešením CNI, které dělá statické přidělování IP adres pro každý uzel.
- Škálovatelné a flexibilní: Podsítě uzlů a podů je možné škálovat nezávisle. Jednu podsíť lze sdílet napříč několika fondy uzlů clusteru nebo napříč několika clustery AKS nasazenými ve stejné virtuální síti. Můžete také nakonfigurovat samostatnou podsíť pro fond uzlů.
- Vysoký výkon: Vzhledem k tomu, že mají pod přiřazené IP adresy virtuální sítě, mají přímé připojení k dalším podům clusteru a prostředkům ve virtuální síti. Řešení podporuje velmi velké clustery bez jakéhokoli snížení výkonu.
- Samostatné zásady virtuální sítě pro pody: Protože pody mají samostatnou podsíť, můžete pro ně nakonfigurovat samostatné zásady virtuální sítě, které se liší od zásad uzlů. To umožňuje mnoho užitečných scénářů, jako je povolení připojení k internetu jenom pro pody, ne pro uzly, oprava zdrojové IP adresy pro pod ve fondu uzlů pomocí služby Azure NAT Gateway a použití skupin zabezpečení sítě k filtrování provozu mezi fondy uzlů.
- Zásady sítě Kubernetes: Zásady sítě Azure i Calico pracují s tímto řešením.
Další informace najdete v tématu Konfigurace sítí Azure CNI pro dynamické přidělování IP adres a rozšířenou podporu podsítě.
Virtuální počítače skladové položky v5
Pokyny k osvědčeným postupům
Skladové položky virtuálních počítačů v5 můžete použít k lepšímu výkonu během aktualizací a po aktualizacích, menší celkový dopad a spolehlivější připojení pro vaše aplikace.
Pro fondy uzlů v AKS použijte virtuální počítače skladové položky v5 s dočasnými disky operačního systému, které poskytují dostatek výpočetních prostředků pro pody kube-system. Další informace najdete v tématu Osvědčené postupy pro výkon a škálování velkých úloh v AKS.
Nepoužívejte virtuální počítače řady B
Pokyny k osvědčeným postupům
Nepoužívejte virtuální počítače řady B series pro clustery AKS, protože jsou nízké výkon a nefungují dobře s AKS.
Virtuální počítače řady B series mají nízký výkon a nefungují dobře s AKS. Místo toho doporučujeme používat virtuální počítače skladové položky v5.
Disky Premium
Pokyny k osvědčeným postupům
Pomocí disků Premium dosáhnete 99,9% dostupnosti na jednom virtuálním počítači.
Disky Azure Premium nabízejí konzistentní latenci disků v milisekundách a vysoké IOPS a v celém prostředí. Disky Premium jsou navržené tak, aby poskytovaly virtuální počítače s nízkou latencí, vysokým výkonem a konzistentním výkonem disku.
Následující příklad manifest YAML ukazuje definici třídy úložiště pro disk úrovně Premium:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
Další informace najdete v tématu Použití disků SSD úrovně Azure Premium v2 v AKS.
Container Insights
Pokyny k osvědčeným postupům
Povolte Container Insights monitorování a diagnostiku výkonu kontejnerizovaných aplikací.
Container Insights je funkce služby Azure Monitor, která shromažďuje a analyzuje protokoly kontejnerů z AKS. Shromážděná data můžete analyzovat pomocí kolekce zobrazení a předem připravených sešitů.
Monitorování Container Insights můžete povolit v clusteru AKS pomocí různých metod. Následující příklad ukazuje, jak povolit monitorování Container Insights v existujícím clusteru pomocí Azure CLI:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
Další informace najdete v tématu Povolení monitorování pro clustery Kubernetes.
Azure Policy
Pokyny k osvědčeným postupům
Použijte a vynucujte požadavky na zabezpečení a dodržování předpisů pro clustery AKS pomocí služby Azure Policy.
Pomocí služby Azure Policy můžete použít a vynutit předdefinované zásady zabezpečení v clusterech AKS. Azure Policy pomáhá vynucovat standardy organizace a vyhodnocovat dodržování předpisů ve velkém měřítku. Po instalaci doplňku Azure Policy pro AKS můžete u clusterů použít jednotlivé definice zásad nebo skupiny definic zásad označovaných jako iniciativy.
Další informace najdete v tématu Zabezpečení clusterů AKS pomocí služby Azure Policy.
Další kroky
Tento článek se zaměřuje na osvědčené postupy pro nasazení a spolehlivost clusteru pro clustery Azure Kubernetes Service (AKS). Další osvědčené postupy najdete v následujících článcích:

Azure Kubernetes Service