Rychlý start: Porozumění konverzačnímu jazyku
Tento článek vám pomůže začít s porozuměním konverzačnímu jazyku pomocí sady Language Studio a rozhraní REST API. Pokud si chcete vyzkoušet příklad, postupujte podle těchto kroků.
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
Přihlášení k sadě Language Studio
Přejděte do sady Language Studio a přihlaste se pomocí svého účtu Azure.
V okně Zvolit prostředek jazyka, které se zobrazí, vyhledejte své předplatné Azure a zvolte prostředek jazyka. Pokud prostředek nemáte, můžete vytvořit nový.
Podrobnosti o instanci Požadovaná hodnota Předplatné Azure Vaše předplatné Azure. Skupina zdrojů Azure Název vaší skupiny prostředků Azure Název prostředku Azure Název vašeho prostředku Azure. Umístění Jedna z podporovaných oblastí pro váš prostředek jazyka. Například "USA – západ 2". Cenová úroveň Jedna z platných cenových úrovní pro váš prostředek jazyka. Službu můžete vyzkoušet pomocí úrovně Free (F0). 

Vytvoření projektu pro porozumění konverzačnímu jazyku
Jakmile vyberete zdroj jazyka, vytvořte projekt pro porozumění konverzačnímu jazyku. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Pro účely tohoto rychlého startu si můžete stáhnout tento ukázkový soubor projektu a importovat ho. Tento projekt dokáže předpovědět zamýšlené příkazy ze vstupu uživatele, například čtení e-mailů, odstraňování e-mailů a připojení dokumentu k e-mailu.
V části Vysvětlení otázek a konverzačního jazyka v sadě Language Studio vyberte Porozumění konverzačnímu jazyku.

Tím se dostanete na stránku projektů pro porozumění konverzačnímu jazyku. Vedle tlačítka Vytvořit nový projekt vyberte Importovat.

V zobrazeném okně nahrajte soubor JSON, který chcete importovat. Ujistěte se, že váš soubor dodržuje podporovaný formát JSON.


Po dokončení nahrávání se dostanete na stránku definice schématu. Pro účely tohoto rychlého startu je schéma již sestavené a promluvy jsou už označené záměry a entitami.
Trénování vašeho modelu
Obvykle byste po vytvoření projektu měli vytvořit schéma a označovat promluvy. Pro účely tohoto rychlého startu jsme už naimportovali připravený projekt s sestaveným schématem a označenými promluvami.
Pokud chcete vytrénovat model, musíte zahájit trénovací úlohu. Výstupem úspěšné trénovací úlohy je trénovaný model.
Zahájení trénování modelu v sadě Language Studio:
V nabídce na levé straně vyberte Trénovat model .
V horní nabídce vyberte Spustit trénovací úlohu .
Vyberte Vytrénovat nový model a do textového pole zadejte nový název modelu. V opačném případě chcete nahradit existující model modelem natrénovaným na nových datech, vyberte Přepsat existující model a pak vyberte existující model. Přepsání natrénovaného modelu je nevratné, ale nebude mít vliv na nasazené modely, dokud nový model nenasadíte.
Vyberte režim trénování. Pro rychlejší trénování můžete zvolit standardní trénování , ale je k dispozici pouze pro angličtinu. Nebo můžete zvolit rozšířené trénování , které je podporováno pro jiné jazyky a vícejazyčné projekty, ale zahrnuje delší dobu trénování. Přečtěte si další informace o režimech trénování.
Vyberte metodu rozdělení dat. Můžete zvolit automatické rozdělení testovací sady z trénovacích dat , kde systém rozdělí promluvy mezi trénovací a testovací sady podle zadaných procent. Nebo můžete použít ruční rozdělení trénovacích a testovacích dat, tato možnost je povolená jenom v případě, že jste do testovací sady přidali promluvy při označování promluv.
Vyberte tlačítko Trénovat.

V seznamu vyberte ID trénovací úlohy. Zobrazí se panel, kde můžete zkontrolovat průběh trénování, stav úlohy a další podrobnosti o této úloze.
Poznámka:
- Pouze úspěšně dokončené trénovací úlohy vygenerují modely.
- Trénování může nějakou dobu trvat několik minut až několik hodin na základě počtu promluv.
- Najednou můžete mít spuštěnou pouze jednu úlohu trénování. Do dokončení spuštěné úlohy nemůžete spustit jiné trénovací úlohy v rámci stejného projektu.
- Strojové učení používané k trénování modelů se pravidelně aktualizuje. Pokud chcete vytrénovat předchozí verzi konfigurace, vyberte Možnost Vybrat, pokud chcete změnit stránku Spustit trénovací úlohu a zvolte předchozí verzi.

Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali jeho podrobnosti o vyhodnocení. V tomto rychlém startu jednoduše nasadíte model a zpřístupníte ho pro vyzkoušení v sadě Language Studio nebo můžete volat rozhraní API pro predikce.
Nasazení modelu v sadě Language Studio:
V nabídce na levé straně vyberte Nasazení modelu .
Výběrem možnosti Přidat nasazení spusťte Průvodce přidáním nasazení .

Výběrem možnosti Vytvořit nový název nasazení vytvořte nové nasazení a v rozevíracím seznamu níže přiřaďte natrénovaný model. Pokud chcete efektivně nahradit model používaný existujícím nasazením, můžete jinak vybrat možnost Přepsat existující název nasazení.
Poznámka:
Přepsání existujícího nasazení nevyžaduje změny volání rozhraní API pro predikce, ale výsledky, které získáte, budou založené na nově přiřazeného modelu.
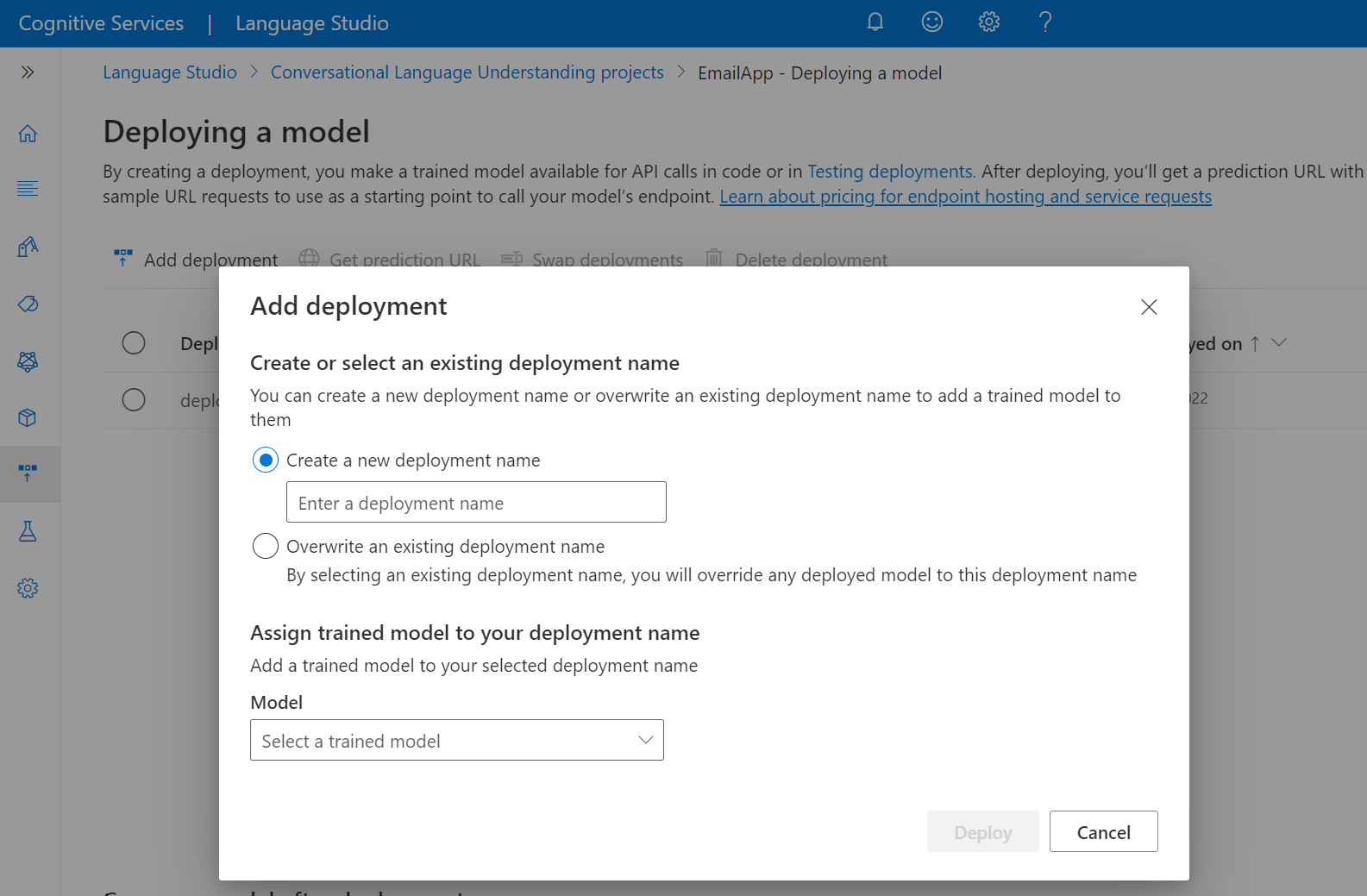
V rozevíracím seznamu Model vyberte natrénovaný model.
Výběrem možnosti Nasadit spustíte úlohu nasazení.
Po úspěšném nasazení se vedle něj zobrazí datum vypršení platnosti. Vypršení platnosti nasazení je v případě, že nasazený model nebude dostupný pro predikci, což obvykle nastane dvanáct měsíců po vypršení platnosti konfigurace trénování.


Test nasazený model
Testování nasazených modelů v sadě Language Studio:
V nabídce na levé straně vyberte Testovací nasazení .
V případě vícejazyčných projektů v rozevíracím seznamu Vybrat jazyk textu vyberte jazyk promluvy, kterou testujete.
V rozevíracím seznamu Název nasazení vyberte název nasazení odpovídající modelu, který chcete testovat. Můžete testovat jenom modely, které jsou přiřazené k nasazením.
Do textového pole zadejte promluvu, která se má otestovat. Pokud jste například vytvořili aplikaci pro promluvy související s e-mailem, můžete zadat odstranit tento e-mail.
V horní části stránky vyberte Spustit test.
Po spuštění testu by se ve výsledku měla zobrazit odpověď modelu. Výsledky můžete zobrazit v zobrazení karet entit nebo je zobrazit ve formátu JSON.
Vyčištění prostředků
Pokud už projekt nepotřebujete, můžete projekt odstranit pomocí sady Language Studio. V levé navigační nabídce vyberte Projekty , vyberte projekt, který chcete odstranit, a pak v horní nabídce vyberte Odstranit .
Požadavky
- Předplatné Azure – Vytvořte si ho zdarma.
Vytvoření nového prostředku z webu Azure Portal
Přihlaste se k webu Azure Portal a vytvořte nový prostředek jazyka Azure AI.
Vyberte Vytvořit nový prostředek.
V zobrazeném okně vyhledejte službu Jazyk.
Vyberte příkaz Vytvořit.
Vytvořte prostředek jazyka s následujícími podrobnostmi.
Podrobnosti o instanci Požadovaná hodnota Oblast Jedna z podporovaných oblastí pro váš prostředek jazyka. Název Požadovaný název prostředku jazyka Cenová úroveň Jedna z podporovaných cenových úrovní pro váš prostředek jazyka.
Získání klíčů prostředků a koncového bodu
Na webu Azure Portal přejděte na stránku přehledu prostředků.
V nabídce na levé straně vyberte Klíče a koncový bod. Pro požadavky rozhraní API použijete koncový bod a klíč.


Import nového ukázkového projektu CLU
Jakmile máte vytvořený zdroj jazyka, vytvořte projekt pro porozumění konverzačnímu jazyku. Projekt je pracovní oblast pro vytváření vlastních modelů ML na základě vašich dat. K vašemu projektu má přístup jenom vy a ostatní, kteří mají přístup k používanému prostředku jazyka.
Pro účely tohoto rychlého startu si můžete stáhnout tento ukázkový projekt a importovat ho. Tento projekt dokáže předpovědět zamýšlené příkazy ze vstupu uživatele, například čtení e-mailů, odstraňování e-mailů a připojení dokumentu k e-mailu.
Aktivace úlohy importu projektu
Odešlete požadavek POST pomocí následující adresy URL, hlaviček a textu JSON pro import projektu.
Adresa URL požadavku
Při vytváření požadavku rozhraní API použijte následující adresu URL. Zástupné hodnoty nahraďte vlastními hodnotami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text
Text JSON, který odešlete, je podobný následujícímu příkladu. Další podrobnosti o objektu JSON najdete v referenční dokumentaci .
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| Klíč | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
{API-VERSION} |
Verze rozhraní API, které voláte. | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | EmailAppDemo |
language |
{LANGUAGE-CODE} |
Řetězec určující kód jazyka pro promluvy použité v projektu. Pokud je projekt vícejazyčný, zvolte kód jazyka většiny promluv. | en-us |
multilingual |
true |
Logická hodnota, která umožňuje mít v datové sadě dokumenty ve více jazycích. Po nasazení modelu můžete dotazovat model v libovolném podporovaném jazyce , včetně jazyků, které nejsou součástí trénovacích dokumentů. | true |
dataset |
{DATASET} |
Podívejte se, jak vytrénovat model pro informace o rozdělení dat mezi testovací a trénovací sadu. Možné hodnoty pro toto pole jsou Train a Test. |
Train |
Po úspěšném požadavku bude odpověď rozhraní API obsahovat hlavičku operation-location s adresou URL, kterou můžete použít ke kontrole stavu úlohy importu. Formátuje se takto:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
Získání stavu úlohy importu
Když odešlete žádost o úspěšný import projektu, úplná adresa URL požadavku pro kontrolu stavu úlohy importu (včetně koncového bodu, názvu projektu a ID úlohy) je obsažena v hlavičce odpovědi operation-location .
Pomocí následujícího požadavku GET zadejte dotaz na stav úlohy importu. Můžete použít adresu URL, kterou jste obdrželi z předchozího kroku, nebo nahradit zástupné hodnoty vlastními hodnotami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Popis | Hodnota |
|---|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. | {YOUR-PRIMARY-RESOURCE-KEY} |
Text odpovědi
Po odeslání požadavku získáte následující odpověď. Pokračujte v dotazování na tento koncový bod, dokud se parametr stavu nezmění na "úspěch".
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
Zahájení trénování modelu
Obvykle byste po vytvoření projektu měli vytvořit schéma a označit promluvy. Pro účely tohoto rychlého startu jsme už naimportovali připravený projekt s sestaveným schématem a označenými promluvami.
K odeslání trénovací úlohy vytvořte požadavek POST pomocí následující adresy URL, hlaviček a textu JSON.
Adresa URL požadavku
Při vytváření požadavku rozhraní API použijte následující adresu URL. Zástupné hodnoty nahraďte vlastními hodnotami.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text požadavku
V požadavku použijte následující objekt. Po dokončení trénování bude model pojmenován po hodnotě, kterou pro modelLabel parametr použijete.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Klíč | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Název vašeho modelu. | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
Verze trénovacího konfiguračního modelu. Ve výchozím nastavení se používá nejnovější verze modelu. | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
Režim trénování, který se má použít pro trénování. Podporované režimy jsou standardní trénování, rychlejší trénování, ale k dispozici je pouze pro angličtinu a pokročilé trénování podporované pro jiné jazyky a vícejazyčné projekty, ale zahrnuje delší dobu trénování. Přečtěte si další informace o režimech trénování. | standard |
kind |
percentage |
Rozdělte metody. Možné hodnoty jsou percentage nebo manual. Další informace najdete v tématu trénování modelu . |
percentage |
trainingSplitPercentage |
80 |
Procento označených dat, která se mají zahrnout do trénovací sady Doporučená hodnota je 80. |
80 |
testingSplitPercentage |
20 |
Procento označených dat, která se mají zahrnout do testovací sady Doporučená hodnota je 20. |
20 |
Poznámka:
testingSplitPercentage A trainingSplitPercentage jsou vyžadovány pouze v případě, že Kind je nastavena percentage hodnota a součet obou procent by měl být roven 100.
Po odeslání požadavku rozhraní API obdržíte 202 odpověď, která značí úspěch. V hlavičce odpovědi extrahujte operation-location hodnotu. Bude formátován takto:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Tuto adresu URL můžete použít k získání stavu trénovací úlohy.
Získání stavu trénovací úlohy
Dokončení trénování může nějakou dobu trvat – někdy mezi 10 a 30 minut. Pomocí následujícího požadavku můžete pokračovat v dotazování stavu úlohy trénování, dokud se úspěšně nedokončil.
Když odešlete úspěšnou žádost o trénování, úplná adresa URL požadavku pro kontrolu stavu úlohy (včetně koncového bodu, názvu projektu a ID úlohy) je obsažena v hlavičce odpovědi operation-location .
Stav průběhu trénování modelu získáte pomocí následujícího požadavku GET . Nahraďte níže uvedené zástupné hodnoty vlastními hodnotami.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text odpovědi
Po odeslání požadavku se zobrazí následující odpověď. Pokračujte v dotazování na tento koncový bod, dokud se parametr stavu nezmění na "úspěch".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Key | Hodnota | Příklad |
|---|---|---|
modelLabel |
Název modelu | Model1 |
trainingConfigVersion |
Verze konfigurace trénování. Ve výchozím nastavení se používá nejnovější verze . | 2022-05-01 |
trainingMode |
Vybraný režim trénování. | standard |
startDateTime |
Čas zahájení trénování | 2022-04-14T10:23:04.2598544Z |
status |
Stav úlohy trénování | running |
estimatedEndDateTime |
Odhadovaný čas dokončení trénovací úlohy | 2022-04-14T10:29:38.2598544Z |
jobId |
ID trénovací úlohy | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Datum a čas vytvoření trénovací úlohy | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Datum a čas poslední aktualizace trénovací úlohy | 2022-04-14T10:23:45Z |
expirationDateTime |
Datum a čas vypršení platnosti trénovací úlohy | 2022-04-14T10:22:42Z |
Nasazení modelu
Obecně platí, že po trénování modelu byste zkontrolovali jeho podrobnosti o vyhodnocení. V tomto rychlém startu jednoduše nasadíte model a zavoláte rozhraní API pro predikce pro dotazování výsledků.
Odeslání úlohy nasazení
Vytvořte požadavek PUT pomocí následující adresy URL, hlaviček a textu JSON, abyste mohli začít nasazovat konverzační model pro porozumění jazyku.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text požadavku
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Klíč | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Název modelu, který se přiřadí k vašemu nasazení. Úspěšně natrénované modely můžete přiřadit pouze. U této hodnoty se rozlišují malá a velká písmena. | myModel |
Po odeslání požadavku rozhraní API obdržíte 202 odpověď, která značí úspěch. V hlavičce odpovědi extrahujte operation-location hodnotu. Bude formátován takto:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Tuto adresu URL můžete použít k získání stavu úlohy nasazení.
Získání stavu úlohy nasazení
Když odešlete žádost o úspěšné nasazení, úplná adresa URL požadavku pro kontrolu stavu úlohy (včetně koncového bodu, názvu projektu a ID úlohy) je obsažena v hlavičce odpovědi operation-location .
Stav úlohy nasazení získáte pomocí následujícího požadavku GET . Zástupné hodnoty nahraďte vlastními hodnotami.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text odpovědi
Po odeslání požadavku získáte následující odpověď. Pokračujte v dotazování na tento koncový bod, dokud se parametr stavu nezmění na "úspěch".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Dotazování modelu
Po nasazení modelu ho můžete začít používat k předpovědím prostřednictvím rozhraní API pro predikce.
Po úspěšném nasazení můžete začít dotazovat nasazený model na předpovědi.
Vytvořte požadavek POST pomocí následující adresy URL, hlaviček a textu JSON, abyste mohli začít testovat konverzační model pro porozumění jazyku.
Adresa URL požadavku
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Text požadavku
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| Klíč | Zástupný symbol | Hodnota | Příklad |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
Promluva, ze které chcete předpovědět svůj záměr a extrahovat entity. | "Read Matt's email |
projectName |
{PROJECT-NAME} |
Název projektu. U této hodnoty se rozlišují malá a velká písmena. | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
Název nasazení. U této hodnoty se rozlišují malá a velká písmena. | staging |
Po odeslání požadavku získáte následující odpověď pro predikci.
Text odpovědi
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| Klíč | Ukázková hodnota | Popis |
|---|---|---|
| query | "Přečtěte si Mattův e-mail" | text, který jste odeslali pro dotaz. |
| TopIntent | "Číst" | Predikovaný záměr s nejvyšším skóre spolehlivosti. |
| záměry | [] | Seznam všech záměrů, které byly předpovězeny pro text dotazu, každý z nich s skóre spolehlivosti. |
| entities | [] | pole obsahující seznam extrahovaných entit z textu dotazu. |
Odpověď rozhraní API pro projekt konverzací
V projektu konverzací získáte předpovědi pro záměry i entity, které jsou přítomné v rámci projektu.
- Záměry a entity zahrnují skóre spolehlivosti od 0,0 do 1,0 přidružené k tomu, jak je model přesvědčený o předpovídání určitého prvku v projektu.
- Záměr nejvyššího bodování je obsažený ve vlastním parametru.
- V odpovědi se zobrazí jenom předpovězené entity.
- Entity označují:
- Text extrahované entity
- Počáteční umístění označené hodnotou posunu
- Délka textu entity označeného hodnotou délky.
Vyčištění prostředků
Pokud už projekt nepotřebujete, můžete projekt odstranit pomocí rozhraní API.
Vytvořte požadavek DELETE pomocí následující adresy URL, hlaviček a textu JSON k odstranění projektu pro porozumění konverzačnímu jazyku.
Adresa URL požadavku
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
Hlavičky
K ověření požadavku použijte následující hlavičku.
| Key | Hodnota |
|---|---|
Ocp-Apim-Subscription-Key |
Klíč k vašemu prostředku. Používá se k ověřování požadavků rozhraní API. |
Po odeslání požadavku rozhraní API obdržíte 202 odpověď s informací o úspěchu, což znamená, že projekt byl odstraněn.