Co je datové jezero?
Data Lake je úložiště, které obsahuje velké množství dat v nativním nezpracovaném formátu. Úložiště Data Lake jsou optimalizovaná pro škálování jejich velikosti na terabajty a petabajty dat. Data obvykle pocházejí z více různých zdrojů a můžou zahrnovat strukturovaná, částečně strukturovaná nebo nestrukturovaná data. Datové jezero vám pomůže uložit všechno v původním, nepřeformulovaném stavu. Tato metoda se liší od tradičního datového skladu, který transformuje a zpracovává data v době příjmu dat.
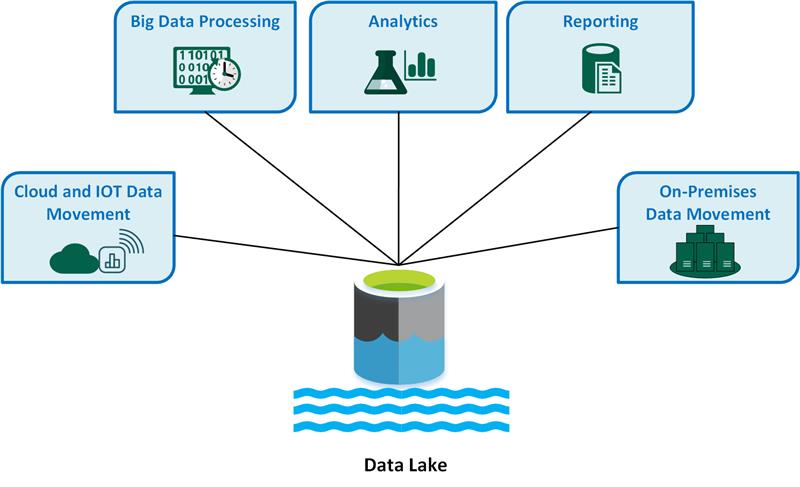
Mezi klíčové případy použití data lake patří:
- Přesun dat v cloudu a internetu věcí (IoT).
- Zpracování velkých objemů dat
- Analýza.
- Hlášení.
- Přesun místních dat.
Zvažte následující výhody datového jezera:
Datové jezero nikdy neodstraní data, protože ukládá data v nezpracované podobě. Tato funkce je zvlášť užitečná v prostředí pro velké objemy dat, protože nemusíte předem vědět, jaké přehledy můžete z dat získat.
Uživatelé můžou zkoumat data a vytvářet vlastní dotazy.
Datové jezero může být rychlejší než tradiční nástroje pro extrakci, transformaci a načítání (ETL).
Datové jezero je flexibilnější než datový sklad, protože může ukládat nestrukturovaná a částečně strukturovaná data.
Kompletní řešení Data Lake se skládá z úložiště i zpracování. Služba Data Lake Storage je navržená pro odolnost proti chybám, neomezenou škálovatelnost a příjem dat s vysokou propustností různých tvarů a velikostí dat. Zpracování datového jezera zahrnuje jeden nebo více procesorů, které můžou tyto cíle začlenit a mohou pracovat s daty uloženými ve velkém datovém jezeře.
Kdy byste měli použít data lake
Doporučujeme použít datové jezero pro zkoumání dat, analýzu dat a strojové učení.
Datové jezero může fungovat jako zdroj dat datového skladu. Při použití této metody data lake ingestuje nezpracovaná data a pak je transformuje do strukturovaného dotazovatelného formátu. Tato transformace obvykle používá kanál extrakce, načítání, transformace (ELT), ve kterém se data ingestují a transformují. Relační zdrojová data můžou přejít přímo do datového skladu prostřednictvím procesu ETL a přeskočit datové jezero.
Úložiště Data Lake můžete použít ve scénářích streamování událostí nebo IoT, protože datová jezera můžou uchovávat velké objemy relačních a nerelačních dat bez transformace nebo definice schématu. Datová jezera můžou zpracovávat velké objemy malých zápisů s nízkou latencí a jsou optimalizovaná pro obrovskou propustnost.
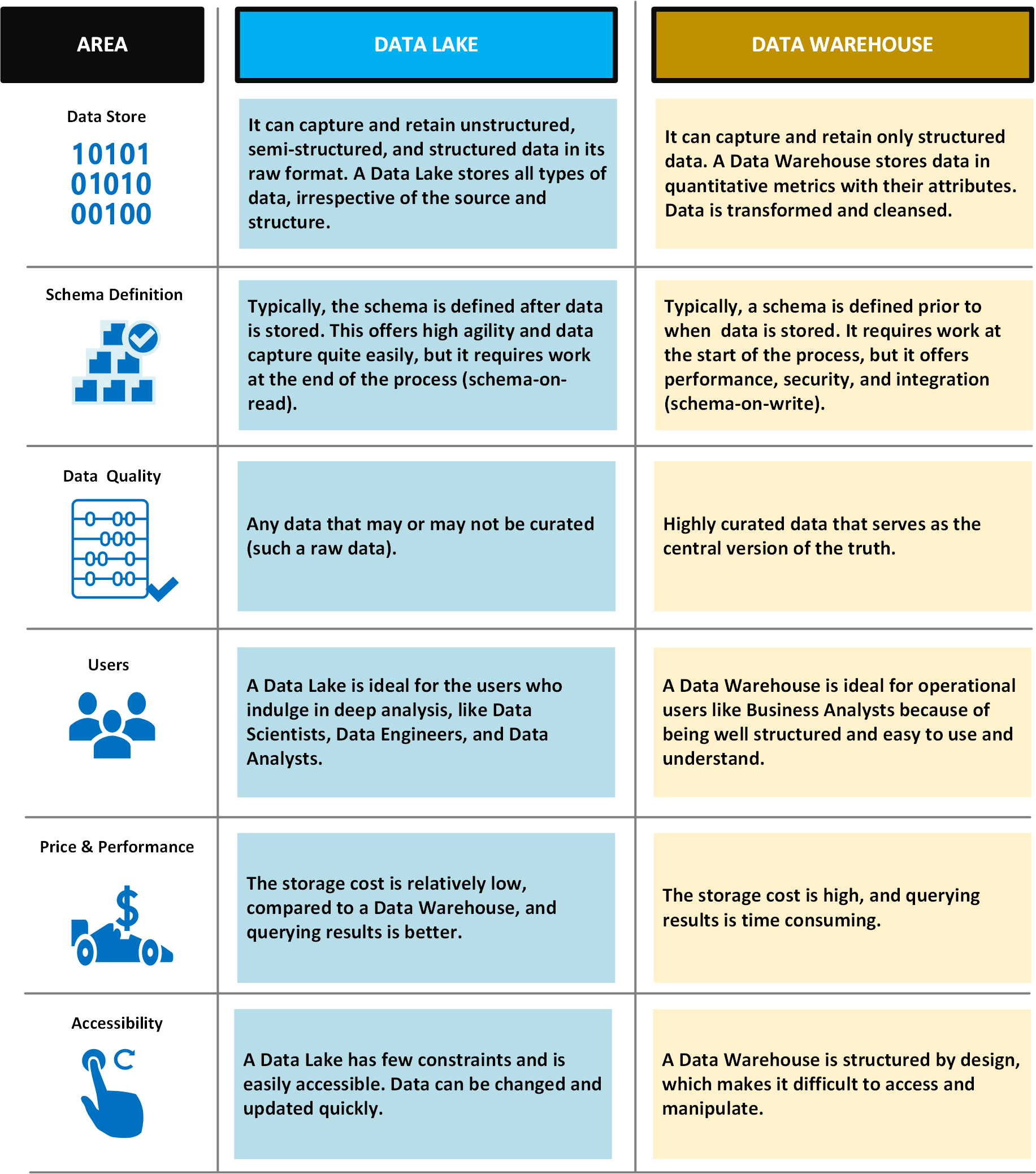
Následující tabulka porovnává datová jezera a datové sklady.
Výzvy
Velké objemy dat: Správa obrovských objemů nezpracovaných a nestrukturovaných dat může být složitá a náročná na prostředky, takže potřebujete robustní infrastrukturu a nástroje.
Potenciální kritické body: Zpracování dat může představovat zpoždění a nevýkonnost, zejména v případě, že máte velké objemy dat a různé datové typy.
Rizika poškození dat: Nesprávné ověření a monitorování dat představuje riziko poškození dat, které může ohrozit integritu datového jezera.
Problémy s kontrolou kvality: Správná kvalita dat je výzvou z důvodu různých zdrojů a formátů dat. Musíte implementovat přísné postupy zásad správného řízení dat.
Problémy s výkonem: Výkon dotazů může snížit při růstu datového jezera, takže je nutné optimalizovat strategie úložiště a zpracování.
Technologické volby
Při vytváření komplexního řešení Data Lake v Azure zvažte následující technologie:
Azure Data Lake Storage kombinuje Službu Azure Blob Storage s funkcemi data Lake, které poskytují přístup kompatibilní s Apache Hadoopem, možnosti hierarchického oboru názvů a vylepšené zabezpečení pro efektivní analýzu velkých objemů dat.
Azure Databricks je jednotná platforma, pomocí které můžete zpracovávat, ukládat, analyzovat a zpeněžit data. Podporuje procesy ETL, řídicí panely, zabezpečení, zkoumání dat, strojové učení a generování umělé inteligence.
Azure Synapse Analytics je jednotná služba, pomocí které můžete ingestovat, zkoumat, připravovat, spravovat a obsluhovat data pro okamžité potřeby business intelligence a strojového učení. Integruje se hlouběji s datovými jezery Azure, abyste mohli efektivně dotazovat a analyzovat velké datové sady.
Azure Data Factory je cloudová služba pro integraci dat, kterou můžete použít k vytváření pracovních postupů řízených daty k orchestraci a automatizaci přesunu a transformace dat.
Microsoft Fabric je komplexní datová platforma, která sjednocuje datové inženýrství, datové vědy, datové sklady, analýzy v reálném čase a business intelligence do jednoho řešení.
Přispěvatelé
Tento článek spravuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autor:
- Avijit Prasad | Cloud Consultant
Pokud chcete zobrazit neveřejné profily LinkedIn, přihlaste se na LinkedIn.
Další kroky
- Co je OneLake?
- Seznámení se službou Data Lake Storage
- Dokumentace ke službě Azure Data Lake Analytics
- Školení: Úvod do Služby Data Lake Storage
- Integrace Hadoopu a Azure Data Lake Storage
- Připojení ke službě Data Lake Storage a Blob Storage
- Načtení dat do Služby Data Lake Storage pomocí služby Azure Data Factory