Kopírování a transformace dat v Azure Data Lake Storage Gen2 pomocí Azure Data Factory nebo Azure Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Azure Data Lake Storage Gen2 (ADLS Gen2) je sada funkcí vyhrazených pro analýzy velkých objemů dat integrovaných do služby Azure Blob Storage. Můžete ji použít pro připojení k datům pomocí paradigmat systému souborů a úložiště objektů.
Tento článek popisuje, jak pomocí aktivity kopírování kopírovat data z Azure Data Lake Storage Gen2 a jak pomocí Tok dat transformovat data v Azure Data Lake Storage Gen2. Další informace najdete v úvodním článku pro Azure Data Factory nebo Azure Synapse Analytics.
Tip
V případě scénáře migrace data lake nebo datového skladu se dozvíte více v tématu Migrace dat z data lake nebo datového skladu do Azure.
Podporované funkce
Tento konektor Azure Data Lake Storage Gen2 je podporovaný pro následující funkce:
| Podporované funkce | IR | Spravovaný privátní koncový bod |
|---|---|---|
| aktivita Copy (zdroj/jímka) | (1) (2) | ✓ |
| Mapování toku dat (zdroj/jímka) | (1) | ✓ |
| Aktivita Lookup | (1) (2) | ✓ |
| Aktivita GetMetadata | (1) (2) | ✓ |
| Aktivita odstranění | (1) (2) | ✓ |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Pro aktivita Copy můžete pomocí tohoto konektoru:
- Kopírování dat z a do Azure Data Lake Storage Gen2 pomocí klíče účtu, instančního objektu nebo spravovaných identit pro ověřování prostředků Azure
- Kopírovat soubory tak, jak je, parsovat nebo generovat soubory s podporovanými formáty souborů a komprimačními kodeky.
- Během kopírování zachová metadata souboru.
- Při kopírování z Azure Data Lake Storage Gen1/Gen2 zachováte seznamy ACL .
Začínáme
Tip
Postup použití konektoru Data Lake Storage Gen2 najdete v tématu Načtení dat do Azure Data Lake Storage Gen2.
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby Azure Data Lake Storage Gen2 pomocí uživatelského rozhraní
Pomocí následujících kroků vytvořte propojenou službu Azure Data Lake Storage Gen2 v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Azure Data Lake Storage Gen2 a vyberte konektor Azure Data Lake Storage Gen2.
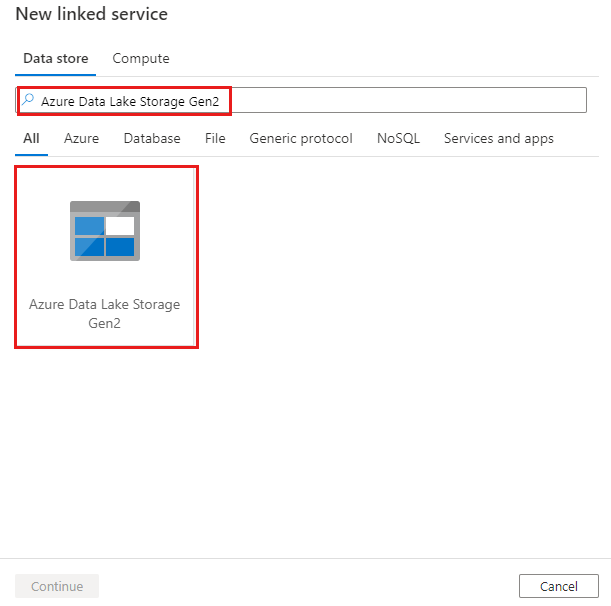
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
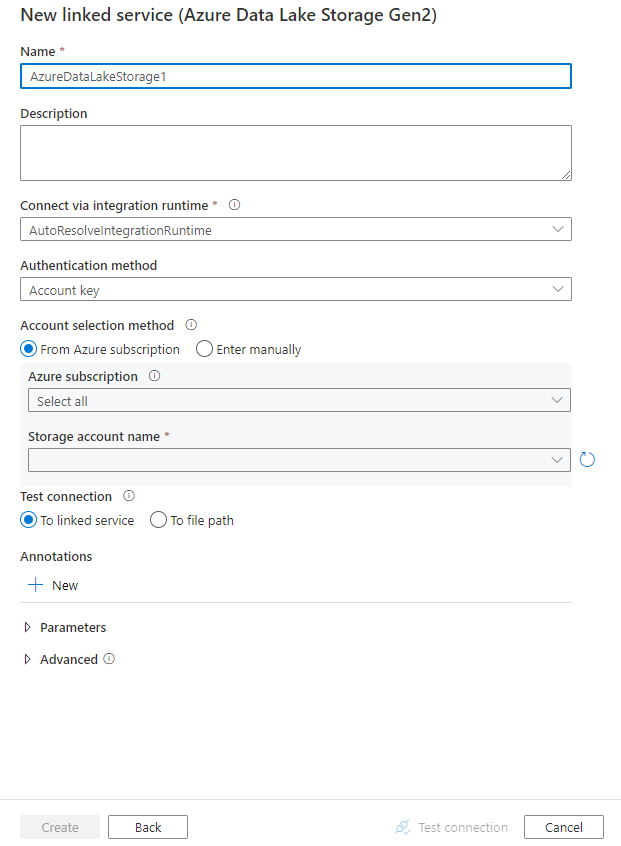
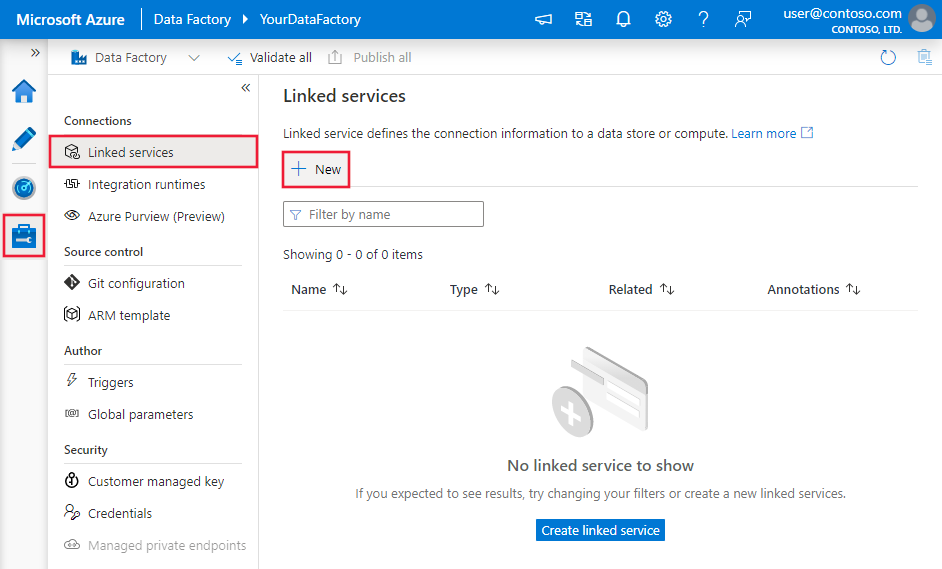
Podrobnosti konfigurace konektoru
Následující části obsahují informace o vlastnostech, které slouží k definování entit kanálu Data Factory a Synapse specifických pro Data Lake Storage Gen2.
Vlastnosti propojené služby
Konektor Azure Data Lake Storage Gen2 podporuje následující typy ověřování. Podrobnosti najdete v odpovídajících částech:
- Ověřování pomocí klíče účtu
- Ověřování pomocí sdíleného přístupového podpisu
- Ověřování instančních objektů
- Ověřování spravované identity přiřazené systémem
- Ověřování spravované identity přiřazené uživatelem
Poznámka:
- Pokud chcete použít veřejný prostředí Azure Integration Runtime pro připojení k Data Lake Storage Gen2 pomocí možnosti Povolit důvěryhodné služby Microsoft pro přístup k tomuto účtu úložiště povolenému v bráně firewall služby Azure Storage, musíte použít ověřování spravované identity. Další informace o nastavení brány firewall služby Azure Storage najdete v tématu Konfigurace bran firewall služby Azure Storage a virtuálních sítí.
- Pokud k načtení dat do Azure Synapse Analytics použijete příkaz PolyBase nebo COPY, pokud je zdroj nebo příprava Data Lake Storage Gen2 nakonfigurovaný s koncovým bodem služby Azure Virtual Network, musíte použít ověřování spravované identity podle požadavků služby Azure Synapse. Další požadavky na konfiguraci najdete v části ověřování spravovaných identit.
Ověřování pomocí klíče účtu
Pokud chcete použít ověřování pomocí klíče účtu úložiště, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na AzureBlobFS. | Ano |
| url | Koncový bod pro Data Lake Storage Gen2 se vzorem https://<accountname>.dfs.core.windows.net. |
Ano |
| accountKey | Klíč účtu pro Data Lake Storage Gen2 Označte toto pole jako securestring, abyste ho mohli bezpečně uložit, nebo odkazovat na tajný klíč uložený ve službě Azure Key Vault. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud tato vlastnost není zadaná, použije se výchozí prostředí Azure Integration Runtime. | No |
Poznámka:
Sekundární koncový bod systému souborů ADLS se při ověřování pomocí klíče účtu nepodporuje. Můžete použít jiné typy ověřování.
Příklad:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"accountkey": {
"type": "SecureString",
"value": "<accountkey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování pomocí sdíleného přístupového podpisu
Sdílený přístupový podpis poskytuje delegovaný přístup k prostředkům ve vašem účtu úložiště. Sdílený přístupový podpis můžete použít k udělení omezených oprávnění klienta k objektům ve vašem účtu úložiště po určitou dobu.
Přístupové klíče účtu nemusíte sdílet. Sdílený přístupový podpis je identifikátor URI, který zahrnuje v parametrech dotazu všechny informace potřebné pro ověřený přístup k prostředku úložiště. Pro přístup k prostředkům úložiště pomocí sdíleného přístupového podpisu musí klient předat sdílený přístupový podpis pouze příslušnému konstruktoru nebo metodě.
Další informace o sdílených přístupových podpisech najdete v tématu Sdílené přístupové podpisy: Vysvětlení modelu sdíleného přístupového podpisu.
Poznámka:
- Služba teď podporuje sdílené přístupové podpisy služby i sdílené přístupové podpisy účtu. Další informace o sdílených přístupových podpisech najdete v tématu Udělení omezeného přístupu k prostředkům Azure Storage pomocí sdílených přístupových podpisů.
- V pozdějších konfiguracích datové sady je cesta ke složce absolutní cestou počínaje úrovní kontejneru. Musíte nakonfigurovat jednu zarovnanou s cestou v identifikátoru URI SAS.
Pro použití ověřování pomocí sdíleného přístupového podpisu se podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost type musí být nastavená na AzureBlobFS (navržená). |
Ano |
| sasUri | Zadejte identifikátor URI sdíleného přístupového podpisu k prostředkům úložiště, jako je například objekt blob nebo kontejner. Označte toto pole jako SecureString bezpečné uložení. Token SAS můžete také vložit do služby Azure Key Vault, abyste mohli použít automatickou rotaci a odebrat část tokenu. Další informace najdete v následujících ukázkách a ukládání přihlašovacích údajů ve službě Azure Key Vault. |
Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud je vaše úložiště dat v privátní síti). Pokud tato vlastnost není zadaná, služba používá výchozí prostředí Azure Integration Runtime. | No |
Poznámka:
Pokud používáte propojenou AzureStorage službu typu, je stále podporovaná tak, jak je. Doporučujeme ale použít nový AzureDataLakeStorageGen2 propojený typ služby.
Příklad:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Uložení klíče účtu ve službě Azure Key Vault
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Při vytváření identifikátoru URI sdíleného přístupového podpisu zvažte následující body:
- Nastavte příslušná oprávnění ke čtení a zápisu u objektů na základě způsobu použití propojené služby (čtení, zápis, čtení a zápis).
- Nastavte čas vypršení platnosti odpovídajícím způsobem. Ujistěte se, že platnost přístupu k objektům úložiště nevyprší v aktivním období kanálu.
- Identifikátor URI by se měl vytvořit v pravém kontejneru nebo objektu blob podle potřeby. Identifikátor URI sdíleného přístupového podpisu objektu blob umožňuje datové továrně nebo kanálu Synapse přístup k tomuto konkrétnímu objektu blob. Identifikátor URI sdíleného přístupového podpisu kontejneru úložiště objektů blob umožňuje datové továrně nebo kanálu Synapse iterovat objekty blob v daném kontejneru. Pokud chcete později poskytnout přístup k více nebo menším objektům nebo aktualizovat identifikátor URI sdíleného přístupového podpisu, nezapomeňte aktualizovat propojenou službu novým identifikátorem URI.
Ověřování instančního objektu
Pokud chcete použít ověřování instančního objektu, postupujte takto.
Zaregistrujte aplikaci na platformě Microsoft Identity Platform. Postup najdete v tématu Rychlý start: Registrace aplikace na platformě Microsoft Identity Platform. Poznamenejte si tyto hodnoty, které použijete k definování propojené služby:
- ID aplikace
- Klíč aplikace
- ID tenanta
Udělte instančnímu objektu správné oprávnění. Podívejte se na příklady fungování oprávnění v Data Lake Storage Gen2 ze seznamů řízení přístupu u souborů a adresářů.
- Jako zdroj: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů a dále oprávnění ke čtení kopírovaných souborů. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Čtenář dat v objektech blob služby Storage.
- Jako jímka: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů spolu s oprávněním k zápisu do cílové složky. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Přispěvatel dat v objektech blob služby Storage.
Poznámka:
Pokud k vytvoření uživatelského rozhraní použijete uživatelské rozhraní a instanční objekt není nastavený s rolí Čtenář dat objektů blob služby Storage v IAM, při testování připojení nebo procházení nebo procházení složek zvolte Testovací připojení k cestě k souboru nebo Procházení ze zadané cesty a zadejte cestu s oprávněním Číst + Spustit , abyste mohli pokračovat.
Propojená služba podporuje tyto vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na AzureBlobFS. | Ano |
| url | Koncový bod pro Data Lake Storage Gen2 se vzorem https://<accountname>.dfs.core.windows.net. |
Ano |
| servicePrincipalId | Zadejte ID klienta aplikace. | Ano |
| servicePrincipalCredentialType | Typ přihlašovacích údajů, který se má použít pro ověřování instančního objektu. Povolené hodnoty jsou ServicePrincipalKey a ServicePrincipalCert. | Ano |
| servicePrincipalCredential | Přihlašovací údaje instančního objektu. Pokud jako typ přihlašovacích údajů použijete ServicePrincipalKey , zadejte klíč aplikace. Označte toto pole jako SecureString , abyste ho mohli bezpečně uložit, nebo odkazovat na tajný kód uložený ve službě Azure Key Vault. Pokud jako přihlašovací údaje použijete ServicePrincipalCert , odkazujte na certifikát ve službě Azure Key Vault a ujistěte se, že typ obsahu certifikátu je PKCS #12. |
Ano |
| servicePrincipalKey | Zadejte klíč aplikace. Označte toto pole jako SecureString , abyste ho mohli bezpečně uložit, nebo odkazovat na tajný kód uložený ve službě Azure Key Vault. Tato vlastnost je stále podporována tak, jak je určena servicePrincipalId + servicePrincipalKey. Vzhledem k tomu, že ADF přidává nové ověřování certifikátu instančního objektu, nový model pro ověřování instančního objektu je servicePrincipalIdservicePrincipalCredential + servicePrincipalCredentialType + . |
No |
| klient | Zadejte informace o tenantovi (název domény nebo ID tenanta), pod kterým se vaše aplikace nachází. Načtěte ho tak, že nainstalujete myš v pravém horním rohu webu Azure Portal. | Ano |
| azureCloudType | Pro ověřování instančního objektu zadejte typ cloudového prostředí Azure, ke kterému je zaregistrovaná vaše aplikace Microsoft Entra. Povolené hodnoty jsou AzurePublic, AzureChina, AzureUsGovernment a AzureGermany. Ve výchozím nastavení se používá cloudové prostředí datové továrny nebo kanálu Synapse. |
No |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití ověřování pomocí instančního klíče
Ve službě Azure Key Vault můžete také uložit instanční klíč.
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Použití ověřování certifikátů instančního objektu
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalCredential": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<AKV reference>",
"type": "LinkedServiceReference"
},
"secretName": "<certificate name in AKV>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování spravované identity přiřazené systémem
Datovou továrnu nebo pracovní prostor Synapse je možné přidružit ke spravované identitě přiřazené systémem. Tuto spravovanou identitu přiřazenou systémem můžete použít přímo pro ověřování Data Lake Storage Gen2, podobně jako při použití vlastního instančního objektu. Umožňuje této určené továrně nebo pracovnímu prostoru přistupovat k datům a kopírovat je do nebo z vašeho Data Lake Storage Gen2.
Pokud chcete použít ověřování spravované identity přiřazené systémem, postupujte takto.
Načtěte informace o spravované identitě přiřazené systémem tak, že zkopírujete hodnotu ID objektu spravované identity vygenerované spolu s vaší datovou továrnou nebo pracovním prostorem Synapse.
Udělte spravované identitě přiřazené systémem správné oprávnění. Podívejte se na příklady fungování oprávnění v Data Lake Storage Gen2 ze seznamů řízení přístupu u souborů a adresářů.
- Jako zdroj: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů a dále oprávnění ke čtení kopírovaných souborů. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Čtenář dat v objektech blob služby Storage.
- Jako jímka: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů spolu s oprávněním k zápisu do cílové složky. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Přispěvatel dat v objektech blob služby Storage.
Propojená služba podporuje tyto vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na AzureBlobFS. | Ano |
| url | Koncový bod pro Data Lake Storage Gen2 se vzorem https://<accountname>.dfs.core.windows.net. |
Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování spravované identity přiřazené uživatelem
Datovou továrnu je možné přiřadit pomocí jedné nebo několika spravovaných identit přiřazených uživatelem. Tuto spravovanou identitu přiřazenou uživatelem můžete použít pro ověřování úložiště objektů blob, která umožňuje přístup k datům a jejich kopírování z nebo do Data Lake Storage Gen2. Další informace o spravovaných identitách pro prostředky Azure najdete v tématu Spravované identity pro prostředky Azure.
Pokud chcete použít ověřování spravované identity přiřazené uživatelem, postupujte takto:
Vytvořte jednu nebo více spravovaných identit přiřazených uživatelem a udělte přístup k Azure Data Lake Storage Gen2. Podívejte se na příklady fungování oprávnění v Data Lake Storage Gen2 ze seznamů řízení přístupu u souborů a adresářů.
- Jako zdroj: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů a dále oprávnění ke čtení kopírovaných souborů. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Čtenář dat v objektech blob služby Storage.
- Jako jímka: V Průzkumníku služby Storage udělte aspoň jedno oprávnění ke spuštění VŠECH nadřazených složek a systému souborů spolu s oprávněním k zápisu do cílové složky. Nebo můžete v Řízení přístupu (IAM) udělit aspoň roli Přispěvatel dat v objektech blob služby Storage.
Přiřaďte k datové továrně jednu nebo více spravovaných identit přiřazených uživatelem a vytvořte přihlašovací údaje pro každou spravovanou identitu přiřazenou uživatelem.
Propojená služba podporuje tyto vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavená na AzureBlobFS. | Ano |
| url | Koncový bod pro Data Lake Storage Gen2 se vzorem https://<accountname>.dfs.core.windows.net. |
Ano |
| přihlašovací údaje | Jako objekt přihlašovacích údajů zadejte spravovanou identitu přiřazenou uživatelem. | Ano |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Pokud je vaše úložiště dat v privátní síti, můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime. Pokud není zadaný, použije se výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AzureDataLakeStorageGen2LinkedService",
"properties": {
"type": "AzureBlobFS",
"typeProperties": {
"url": "https://<accountname>.dfs.core.windows.net",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Poznámka:
Pokud k vytváření a spravované identitě používáte uživatelské rozhraní služby Data Factory a spravovaná identita není v IAM nastavená s rolí Čtenář dat objektů blob služby Storage, při testování připojení nebo procházení nebo procházení složek zvolte Testovací připojení k cestě k souboru nebo Procházení ze zadané cesty a zadejte cestu s oprávněním Číst + Spustit , abyste mohli pokračovat.
Důležité
Pokud k načtení dat z Data Lake Storage Gen2 do Azure Synapse Analytics použijete příkaz PolyBase nebo COPY, nezapomeňte při použití ověřování spravované identity pro Data Lake Storage Gen2 postupovat také podle kroků 1 až 3 v těchto doprovodných materiálech. Tyto kroky zaregistrují váš server pomocí Microsoft Entra ID a přiřadí k vašemu serveru roli Přispěvatel dat objektů blob služby Storage. Služba Data Factory zpracovává zbytek. Pokud nakonfigurujete úložiště objektů blob s koncovým bodem služby Azure Virtual Network, musíte mít také možnost Povolit důvěryhodným služby Microsoft přístup k tomuto účtu úložiště zapnuté v nabídce brány firewall účtu služby Azure Storage a nastavení virtuálních sítí, jak to vyžaduje Azure Synapse.
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v tématu Datové sady.
Azure Data Factory podporuje následující formáty souborů. Informace o nastaveních založených na formátu najdete v jednotlivých článcích.
- Formát Avro
- Binární formát
- Formát textu s oddělovači
- Formát aplikace Excel
- Iceberg format
- Formát JSON
- Formát ORC
- Formát Parquet
- Formát XML
Data Lake Storage Gen2 location se v nastavení v datové sadě založené na formátu podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost location typu v datové sadě musí být nastavená na AzureBlobFSLocation. |
Ano |
| fileSystem | Název systému souborů Data Lake Storage Gen2. | No |
| folderPath | Cesta ke složce v daném systému souborů. Pokud chcete k filtrování složek použít zástupný znak, přeskočte toto nastavení a zadejte ho v nastavení zdroje aktivity. | No |
| fileName | Název souboru pod daným systémem fileSystem + folderPath. Pokud chcete k filtrování souborů použít zástupný znak, přeskočte toto nastavení a zadejte ho v nastavení zdroje aktivity. | No |
Příklad:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobFSLocation",
"fileSystem": "filesystemname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v tématu aktivita Copy konfigurace a kanály a aktivity. Tato část obsahuje seznam vlastností podporovaných zdrojem a jímkou Data Lake Storage Gen2.
Azure Data Lake Storage Gen2 jako typ zdroje
Azure Data Factory podporuje následující formáty souborů. Informace o nastaveních založených na formátu najdete v jednotlivých článcích.
- Formát Avro
- Binární formát
- Formát textu s oddělovači
- Formát aplikace Excel
- Formát JSON
- Formát ORC
- Formát Parquet
- Formát XML
Máte několik možností kopírování dat z ADLS Gen2:
- Zkopírujte z dané cesty zadané v datové sadě.
- Filtr zástupných znaků pro cestu ke složce nebo název souboru, viz
wildcardFolderPathawildcardFileName. - Zkopírujte soubory definované v daném textovém souboru jako sadu souborů, viz
fileListPath.
Pro Data Lake Storage Gen2 storeSettings se v nastavení ve zdroji kopírování založeném na formátu podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu v části storeSettings musí být nastavena na AzureBlobFSReadSettings. |
Ano |
| Vyhledejte soubory, které chcete zkopírovat: | ||
| MOŽNOST 1: Statická cesta |
Zkopírujte z daného systému souborů nebo cesty ke složce nebo souboru zadané v datové sadě. Pokud chcete zkopírovat všechny soubory ze systému souborů nebo složky, dále zadejte wildcardFileName jako *. |
|
| MOŽNOST 2: Zástupný znak – zástupný znakFolderPath |
Cesta ke složce se zástupnými znaky v daném systému souborů nakonfigurovaným v datové sadě pro filtrování zdrojových složek. Povolené zástupné znaky jsou: * (odpovídá nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku), použijte ^ k řídicímu znaku, pokud má skutečný název složky zástupný znak nebo tento řídicí znak uvnitř. Další příklady najdete v příkladech filtru složek a souborů. |
No |
| MOŽNOST 2: Zástupný znak - wildcardFileName |
Název souboru se zástupnými znaky v daném systému souborů + folderPath / wildcardFolderPath pro filtrování zdrojových souborů. Povolené zástupné znaky jsou: * (odpovídá nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku), použijte ^ k řídicímu znaku, pokud má váš skutečný název souboru zástupný znak nebo tento řídicí znak uvnitř. Další příklady najdete v příkladech filtru složek a souborů. |
Ano |
| MOŽNOST 3: seznam souborů - fileListPath |
Označuje, že chcete zkopírovat danou sadu souborů. Přejděte na textový soubor, který obsahuje seznam souborů, které chcete kopírovat, jeden soubor na řádek, což je relativní cesta k cestě nakonfigurované v datové sadě. Při použití této možnosti nezadávejte v datové sadě název souboru. Další příklady najdete v příkladech seznamu souborů. |
No |
| Další nastavení: | ||
| rekurzivní | Určuje, zda se data čtou rekurzivně z podsložek nebo pouze ze zadané složky. Všimněte si, že pokud je rekurzivní nastavena na hodnotu true a jímka je úložiště založené na souborech, prázdná složka nebo podsložka se v jímce nezkopíruje ani nevytvoří. Povolené hodnoty jsou true (výchozí) a false. Tato vlastnost se nepoužije při konfiguraci fileListPath. |
No |
| deleteFilesAfterCompletion | Určuje, zda se binární soubory odstraní ze zdrojového úložiště po úspěšném přesunutí do cílového úložiště. Odstranění souboru je na každém souboru, takže když aktivita kopírování selže, uvidíte, že se některé soubory už zkopírovaly do cíle a odstranily ze zdroje, zatímco ostatní zůstávají ve zdrojovém úložišti. Tato vlastnost je platná pouze ve scénáři kopírování binárních souborů. Výchozí hodnota: false. |
No |
| modifiedDatetimeStart | Filtr souborů na základě atributu: Naposledy změněno. Soubory budou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu "2018-12-01T05:00:00Z". Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady se nepoužije žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime, budou vybrány. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, budou vybrány.Tato vlastnost se nepoužije při konfiguraci fileListPath. |
No |
| modifiedDatetimeEnd | Platí to samé jako výše. | No |
| enablePartitionDiscovery | U souborů, které jsou rozdělené na oddíly, určete, zda chcete analyzovat oddíly z cesty k souboru a přidat je jako další zdrojové sloupce. Povolené hodnoty jsou false (výchozí) a true. |
No |
| partitionRootPath | Pokud je povolené zjišťování oddílů, zadejte absolutní kořenovou cestu, abyste mohli číst dělené složky jako datové sloupce. Pokud není ve výchozím nastavení zadán, – Při použití cesty k souboru v datové sadě nebo seznamu souborů ve zdroji je kořenová cesta oddílu cesta nakonfigurovaná v datové sadě. – Pokud používáte filtr složky se zástupnými otazemi, je kořenová cesta oddílu dílčí cestou před prvním zástupným znakem. Předpokládejme například, že cestu v datové sadě nakonfigurujete jako "root/folder/year=2020/month=08/day=27": – Pokud zadáte kořenovou cestu oddílu jako "root/folder/year=2020", aktivita kopírování vygeneruje dva další sloupce month a day s hodnotou 08 a 27 kromě sloupců uvnitř souborů.– Pokud není zadaná kořenová cesta oddílu, nevygeneruje se žádný sloupec navíc. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
Příklad:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobFSReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Storage Gen2 jako typ jímky
Azure Data Factory podporuje následující formáty souborů. Informace o nastaveních založených na formátu najdete v jednotlivých článcích.
- Formát Avro
- Binární formát
- Formát textu s oddělovači
- Iceberg format
- Formát JSON
- Formát ORC
- Formát Parquet
Data Lake Storage Gen2 storeSettings v nastavení v jímce kopírování založeném na formátu podporují následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu v části storeSettings musí být nastavena na AzureBlobFSWriteSettings. |
Ano |
| copyBehavior | Definuje chování kopírování, pokud je zdrojem soubory ze souborového úložiště dat. Povolené hodnoty jsou následující: - PreserveHierarchy (výchozí):: Zachová hierarchii souborů v cílové složce. Relativní cesta zdrojového souboru ke zdrojové složce je shodná s relativní cestou cílového souboru s cílovou složkou. - FlattenHierarchy: Všechny soubory ze zdrojové složky jsou na první úrovni cílové složky. Cílové soubory mají automaticky vygenerované názvy. - MergeFiles: Sloučí všechny soubory ze zdrojové složky do jednoho souboru. Pokud je zadaný název souboru, je zadaným názvem sloučený soubor. V opačném případě se jedná o automaticky vygenerovaný název souboru. |
No |
| blockSizeInMB | Zadejte velikost bloku v MB použitou k zápisu dat do ADLS Gen2. Přečtěte si další informace o objektech blob bloku. Povolená hodnota je mezi 4 MB a 100 MB. Ve výchozím nastavení ADF automaticky určuje velikost bloku na základě typu a dat zdrojového úložiště. V případě nebinární kopie do ADLS Gen2 je výchozí velikost bloku 100 MB, aby se vešla maximálně do 4,75 TB dat. Nemusí být optimální, pokud vaše data nejsou velká, zejména pokud používáte místní prostředí Integration Runtime s nízkým síťovým výkonem, což vede k vypršení časového limitu operace nebo problému s výkonem. Můžete explicitně zadat velikost bloku, zatímco se ujistěte, že blockSizeInMB*50000 je dostatečně velký k uložení dat, jinak se spuštění aktivity kopírování nezdaří. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
| metadata | Při kopírování do jímky nastavte vlastní metadata. Každý objekt pod metadata polem představuje další sloupec. Definuje name název klíče metadat a value označuje hodnotu dat tohoto klíče. Pokud se použije funkce zachování atributů, zadaná metadata se sjednocují nebo přepíšou metadaty zdrojového souboru.Povolené datové hodnoty jsou: - $$LASTMODIFIED: Rezervovaná proměnná označuje, že se má uložit čas poslední změny zdrojových souborů. Platí pouze pro souborový zdroj s binárním formátem.-Výraz - Statická hodnota |
No |
Příklad:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobFSWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Příklady filtrů složek a souborů
Tato část popisuje výsledné chování cesty ke složce a názvu souboru pomocí filtrů zástupných znaků.
| folderPath | fileName | rekurzivní | Struktura zdrojové složky a výsledek filtru (soubory se načítají tučně ) |
|---|---|---|---|
Folder* |
(Prázdné, použít výchozí) | false (nepravda) | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(Prázdné, použít výchozí) | true | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false (nepravda) | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Příklady seznamu souborů
Tato část popisuje výsledné chování použití cesty k seznamu souborů ve zdroji aktivity kopírování.
Za předpokladu, že máte následující strukturu zdrojové složky a chcete zkopírovat soubory tučně:
| Ukázková zdrojová struktura | Obsah v FileListToCopy.txt | Konfigurace ADF |
|---|---|---|
| systém souborů FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Podsložka1/File3.csv Podsložka1/File5.csv |
V datové sadě: -Systém souborů: filesystem- Cesta ke složce: FolderAVe zdroji aktivity kopírování: - Cesta k seznamu souborů: filesystem/Metadata/FileListToCopy.txt Cesta k seznamu souborů odkazuje na textový soubor ve stejném úložišti dat, který obsahuje seznam souborů, které chcete kopírovat, jeden soubor na řádek s relativní cestou k cestě nakonfigurované v datové sadě. |
Příklady rekurzivního a copyBehavioru
Tato část popisuje výsledné chování operace kopírování pro různé kombinace rekurzivních a copyBehavior hodnot.
| rekurzivní | copyBehavior | Struktura zdrojových složek | Výsledný cíl |
|---|---|---|---|
| true | preserveHierarchy | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří se stejnou strukturou jako zdroj: Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
| true | flattenHierarchy | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří s následující strukturou: Složka 1 automaticky vygenerovaný název souboru 1 automaticky vygenerovaný název souboru 2 automaticky vygenerovaný název souboru 3 automaticky vygenerovaný název souboru 4 automaticky vygenerovaný název souboru 5 |
| true | mergeFiles | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří s následující strukturou: Složka 1 File1 + File2 + File3 + File4 + File5 obsah jsou sloučeny do jednoho souboru s automaticky vygenerovaným názvem souboru. |
| false (nepravda) | preserveHierarchy | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří s následující strukturou: Složka 1 Soubor 1 Soubor 2 Podsložka1 se souborem File3, File4 a File5 se nenabídne. |
| false (nepravda) | flattenHierarchy | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří s následující strukturou: Složka 1 automaticky vygenerovaný název souboru 1 automaticky vygenerovaný název souboru 2 Podsložka1 se souborem File3, File4 a File5 se nenabídne. |
| false (nepravda) | mergeFiles | Složka 1 Soubor 1 Soubor 2 Podsložka 1 Soubor 3 Soubor 4 Soubor 5 |
Cílová složka1 se vytvoří s následující strukturou: Složka 1 Obsah File1 + File2 se sloučí do jednoho souboru s automaticky vygenerovaným názvem souboru. automaticky vygenerovaný název souboru 1 Podsložka1 se souborem File3, File4 a File5 se nenabídne. |
Zachování metadat během kopírování
Při kopírování souborů z AmazonU S3/ Azure Blob / Azure Data Lake Storage Gen2 do Azure Data Lake Storage Gen2 / Azure Blob můžete zachovat metadata souborů spolu s daty. Další informace najdete v možnosti Zachovat metadata.
Zachování seznamů ACL ze služby Data Lake Storage Gen1/Gen2
Při kopírování souborů z Azure Data Lake Storage Gen1/Gen2 do Gen2 se můžete rozhodnout zachovat seznamy řízení přístupu (ACL) POSIX spolu s daty. Přečtěte si další informace o zachování seznamů ACL z Data Lake Storage Gen1/Gen2 na Gen2.
Tip
Pokud chcete zkopírovat data z Azure Data Lake Storage Gen1 do Gen2 obecně, přečtěte si téma Kopírování dat z Azure Data Lake Storage Gen1 do Gen2 , kde najdete návod a osvědčené postupy.
Mapování vlastností toku dat
Při transformaci dat v mapování toků dat můžete číst a zapisovat soubory z Azure Data Lake Storage Gen2 v následujících formátech:
Nastavení specifické pro formátování se nachází v dokumentaci pro tento formát. Další informace najdete v tématu Transformace zdroje v mapování toku dat a transformace jímky v mapování toku dat.
Transformace zdroje
Ve zdrojové transformaci můžete číst z kontejneru, složky nebo jednotlivého souboru v Azure Data Lake Storage Gen2. Karta Možnosti zdroje umožňuje spravovat, jak se soubory čtou.
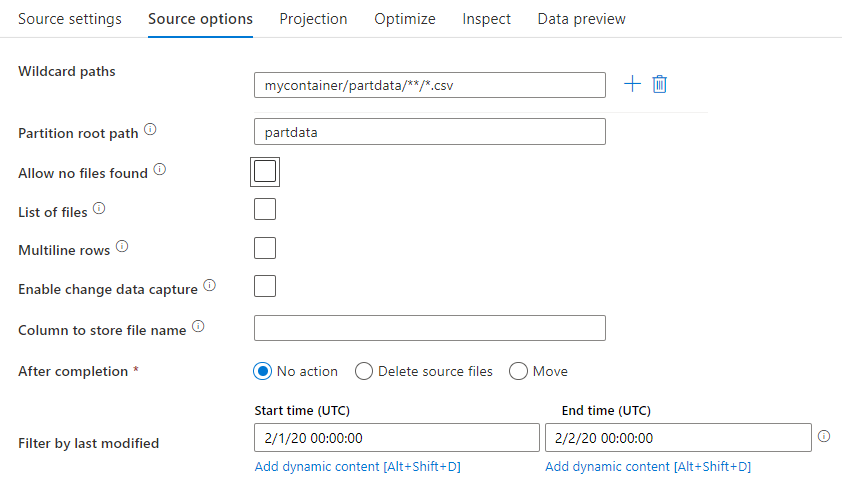
Cesta se zástupným znakem: Použití vzoru se zástupným znakem dá ADF pokyn, aby prošel každou odpovídající složkou a souborem v jedné transformaci zdroje. Jedná se o efektivní způsob, jak zpracovat více souborů v rámci jednoho toku. Přidejte několik vzorů porovnávání se zástupnými znaménkami a znaménkem +, které se zobrazí při najetí myší na existující vzor se zástupnými znaménkami.
Ve zdrojovém kontejneru zvolte řadu souborů, které odpovídají vzoru. V datové sadě je možné zadat pouze kontejner. Cesta se zástupným znakem proto musí obsahovat také cestu ke složce z kořenové složky.
Příklady zástupných znaků:
*Představuje libovolnou sadu znaků.**Představuje rekurzivní vnoření adresářů.?Nahradí jeden znak.[]Odpovídá jednomu z více znaků v hranatých závorkách./data/sales/**/*.csvZíská všechny soubory CSV v části /data/sales./data/sales/20??/**/Získá všechny soubory v 20./data/sales/*/*/*.csvZíská soubory CSV ve dvou úrovních pod /data/sales./data/sales/2004/*/12/[XY]1?.csvZíská všechny soubory CSV v prosinci 2004 počínaje X nebo Y předponou dvouciferné číslo
Kořenová cesta oddílu: Pokud máte ve zdroji souborů rozdělené složky s formátem key=value (například year=2019), můžete přiřadit nejvyšší úroveň stromu složek oddílů k názvu sloupce ve streamu dat toku dat.
Nejprve nastavte zástupný znak tak, aby zahrnoval všechny cesty, které jsou rozdělené složky a soubory typu list, které chcete přečíst.
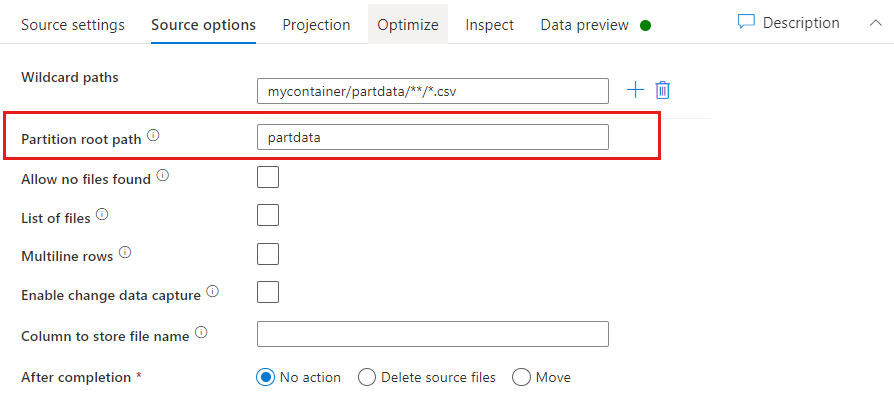
Pomocí nastavení Kořenová cesta oddílu definujte, jaká je nejvyšší úroveň struktury složek. Když si zobrazíte obsah dat prostřednictvím náhledu dat, uvidíte, že ADF přidá vyřešené oddíly nalezené v jednotlivých úrovních složek.
Seznam souborů: Toto je sada souborů. Vytvořte textový soubor, který obsahuje seznam souborů relativní cesty ke zpracování. Přejděte na tento textový soubor.
Sloupec pro uložení názvu souboru: Uložte název zdrojového souboru do sloupce ve vašich datech. Sem zadejte nový název sloupce, do které se uloží řetězec názvu souboru.
Po dokončení: Po spuštění toku dat můžete s zdrojovým souborem dělat nic, odstranit zdrojový soubor nebo ho přesunout. Cesty pro přesunutí jsou relativní.
Chcete-li přesunout zdrojové soubory do jiného umístění po zpracování, vyberte nejprve možnost Přesunout pro operaci se souborem. Pak nastavte adresář "from". Pokud pro svou cestu nepoužíváte žádné zástupné cardy, bude nastavení "from" stejné jako vaše zdrojová složka.
Pokud máte zdrojovou cestu se zástupným znakem, syntaxe bude vypadat takto:
/data/sales/20??/**/*.csv
Můžete zadat "from" jako
/data/sales
A "komu" jako
/backup/priorSales
V tomto případě se všechny soubory, které byly zdrojové pod položkou /data/sales, přesunou do složky /backup/priorSales.
Poznámka:
Operace se soubory se spouštějí pouze při spuštění toku dat ze spuštění kanálu (spuštění ladění kanálu nebo spuštění), který používá aktivitu Spustit Tok dat v kanálu. Operace se soubory se nespouštějí v režimu ladění Tok dat.
Filtrovat podle poslední změny: Můžete filtrovat soubory, které zpracováváte, zadáním rozsahu dat, ve kterém byly naposledy změněny. Všechna data a časy jsou ve standardu UTC.
Povolit zachytávání dat změn: Pokud je true, získáte nové nebo změněné soubory pouze z posledního spuštění. Počáteční načtení úplných dat snímků se vždy dostane při prvním spuštění a následně zachytí nové nebo změněné soubory pouze v dalších spuštěních. Další podrobnosti najdete v tématu Změna zachytávání dat.

Vlastnosti jímky
V transformaci jímky můžete zapisovat do kontejneru nebo složky ve službě Azure Data Lake Storage Gen2. Karta Nastavení umožňuje spravovat způsob zápisu souborů.
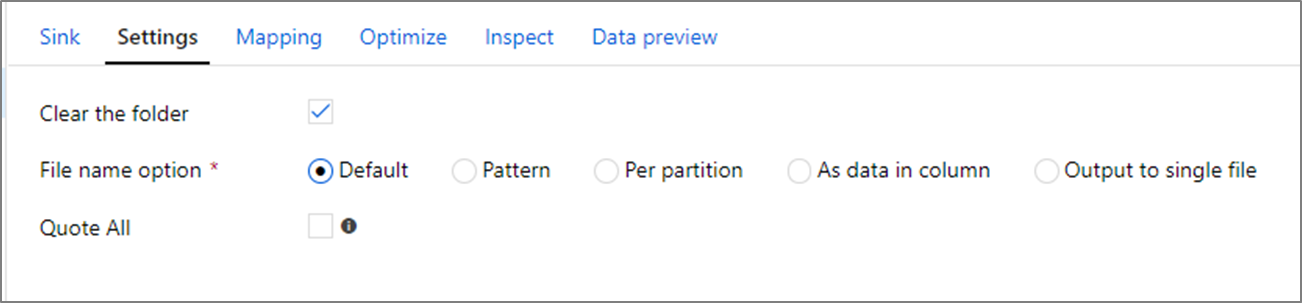
Vymazat složku: Určuje, zda se cílová složka vymaže před zápisem dat.
Možnost název souboru: Určuje, jak mají cílové soubory název v cílové složce. Možnosti názvu souboru jsou:
- Výchozí: Povolit Sparku pojmenování souborů na základě výchozích hodnot PART.
- Vzor: Zadejte vzor, který vypíše výstupní soubory na oddíl. Například půjčky[n].csv vytvoří loans1.csv, loans2.csv atd.
- Na oddíl: Zadejte jeden název souboru na oddíl.
- Jako data ve sloupci: Nastavte výstupní soubor na hodnotu sloupce. Cesta je relativní vzhledem ke kontejneru datové sady, nikoli cílové složce. Pokud máte v datové sadě cestu ke složce, přepíše se.
- Výstup do jednoho souboru: Zkombinujte rozdělené výstupní soubory do jednoho pojmenovaného souboru. Cesta je relativní vzhledem ke složce datové sady. Mějte na paměti, že operace sloučení může selhat na základě velikosti uzlu. Tato možnost se nedoporučuje pro velké datové sady.
Všechny uvozovky: Určuje, zda chcete uzavřít všechny hodnoty do uvozovek.
umask
Volitelně můžete nastavit umask soubory pomocí příkazu POSIX pro čtení, zápis, spouštění příznaků pro vlastníka, uživatele a skupinu.
Příkazy předběžného zpracování a následného zpracování
Volitelně můžete spustit příkazy systému souborů Hadoop před nebo po zápisu do jímky ADLS Gen2. Podporují se následující příkazy:
cpmvrmmkdir
Příklady:
mkdir /folder1mkdir -p folder1mv /folder1/*.* /folder2/cp /folder1/file1.txt /folder2rm -r /folder1
Parametry jsou podporovány také prostřednictvím tvůrce výrazů, například:
mkdir -p {$tempPath}/commands/c1/c2
mv {$tempPath}/commands/*.* {$tempPath}/commands/c1/c2
Ve výchozím nastavení se složky vytvářejí jako uživatel nebo kořen. Odkazujte na kontejner nejvyšší úrovně pomocí /.
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Vlastnosti aktivity GetMetadata
Podrobnosti o vlastnostech najdete v aktivitě GetMetadata.
Odstranění vlastností aktivity
Podrobnosti o vlastnostech najdete v aktivitě Odstranění.
Starší modely
Poznámka:
Následující modely jsou stále podporovány, protože je to kvůli zpětné kompatibilitě. Doporučujeme použít nový model uvedený v předchozích částech a uživatelské rozhraní pro vytváření ADF se přepnulo na generování nového modelu.
Starší model datové sady
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na AzureBlobFSFile. | Ano |
| folderPath | Cesta ke složce v Data Lake Storage Gen2 Pokud není zadaný, odkazuje na kořen. Podporuje se filtr zástupných znaků. Povolené zástupné znaky jsou * (odpovídají nule nebo více znakům) a ? (odpovídá nule nebo jednomu znaku). Slouží ^ k řídicímu znaku, pokud má váš skutečný název složky zástupný znak nebo je uvnitř tohoto řídicího znaku. Příklady: systém souborů, složka/. Další příklady najdete v příkladech filtru složek a souborů. |
No |
| fileName | Filtr názvů nebo zástupných znaků pro soubory v zadané cestě folderPath. Pokud pro tuto vlastnost nezadáte hodnotu, datová sada odkazuje na všechny soubory ve složce. Pro filtr jsou * povolené zástupné znaky (odpovídá nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku).– Příklad 1: "fileName": "*.csv"– Příklad 2: "fileName": "???20180427.txt"Slouží ^ k řídicímu znaku, pokud má váš skutečný název souboru zástupný znak nebo je uvnitř tohoto řídicího znaku.Pokud pro výstupní datovou sadu není zadaný název fileName a v jímce aktivity není zadána vlastnost preserveHierarchy , aktivita kopírování automaticky vygeneruje název souboru s následujícím vzorem: Data.[ GUID ID spuštění aktivity]. [GUID pokud FlattenHierarchy]. [formát, pokud je nakonfigurovaný]. [komprese, pokud je nakonfigurovaná]", například "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Pokud kopírujete z tabulkového zdroje místo dotazu název tabulky, vzor názvů je [název tabulky].[ formát]. [komprese, pokud je nakonfigurovaná]", například "MyTable.csv". |
No |
| modifiedDatetimeStart | Filtr souborů na základě atributu Naposledy změněno Soubory jsou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu "2018-12-01T05:00:00Z". Celkový výkon přesunu dat je ovlivněn povolením tohoto nastavení, když chcete filtrovat soubory s velkým množstvím souborů. Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady není použit žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že jsou vybrané soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, jsou vybrány. |
No |
| modifiedDatetimeEnd | Filtr souborů na základě atributu Naposledy změněno Soubory jsou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu "2018-12-01T05:00:00Z". Celkový výkon přesunu dat je ovlivněn povolením tohoto nastavení, když chcete filtrovat soubory s velkým množstvím souborů. Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady není použit žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že jsou vybrané soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, jsou vybrány. |
No |
| format | Pokud chcete kopírovat soubory tak, jak je to mezi úložišti založenými na souborech (binární kopie), přeskočte oddíl formátu v definicích vstupní i výstupní datové sady. Pokud chcete analyzovat nebo generovat soubory s určitým formátem, podporují se následující typy formátů souborů: TextFormat, JsonFormat, AvroFormat, OrcFormat a ParquetFormat. Nastavte vlastnost typu ve formátu na jednu z těchto hodnot. Další informace najdete v částech Formát textu, Formát JSON, Formát Avro, Formát ORC a Parquet . |
Ne (pouze pro scénář binárního kopírování) |
| komprese | Zadejte typ a úroveň komprese dat. Další informace naleznete v tématu Podporované formáty souborů a komprimační kodeky. Podporované typy jsou **GZip**, **Deflate**, **BZip2**, and **ZipDeflate**.Podporované úrovně jsou Optimální a Nejrychlejší. |
No |
Tip
Chcete-li kopírovat všechny soubory ve složce, zadejte pouze folderPath .
Pokud chcete zkopírovat jeden soubor s daným názvem, zadejte folderPath s částí složky a fileName s názvem souboru.
Chcete-li zkopírovat podmnožinu souborů ve složce, zadejte folderPath s částí složky a fileName pomocí filtru se zástupnými otazníky.
Příklad:
{
"name": "ADLSGen2Dataset",
"properties": {
"type": "AzureBlobFSFile",
"linkedServiceName": {
"referenceName": "<Azure Data Lake Storage Gen2 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "myfilesystem/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Model zdroje starší verze aktivity kopírování
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na AzureBlobFSSource. | Ano |
| rekurzivní | Určuje, zda se data čtou rekurzivně z podsložek nebo pouze ze zadané složky. Pokud je rekurzivní nastavena na hodnotu true a jímka je úložiště založené na souborech, prázdná složka nebo podsložka se v jímce nezkopíruje ani nevytvoří. Povolené hodnoty jsou true (výchozí) a false. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
Příklad:
"activities":[
{
"name": "CopyFromADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen2 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureBlobFSSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Starší model jímky aktivity kopírování
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu jímky aktivity kopírování musí být nastavena na AzureBlobFSSink. | Ano |
| copyBehavior | Definuje chování kopírování, pokud je zdrojem soubory ze souborového úložiště dat. Povolené hodnoty jsou následující: - PreserveHierarchy (výchozí):: Zachová hierarchii souborů v cílové složce. Relativní cesta zdrojového souboru ke zdrojové složce je shodná s relativní cestou cílového souboru s cílovou složkou. - FlattenHierarchy: Všechny soubory ze zdrojové složky jsou na první úrovni cílové složky. Cílové soubory mají automaticky vygenerované názvy. - MergeFiles: Sloučí všechny soubory ze zdrojové složky do jednoho souboru. Pokud je zadaný název souboru, je zadaným názvem sloučený soubor. V opačném případě se jedná o automaticky vygenerovaný název souboru. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
Příklad:
"activities":[
{
"name": "CopyToADLSGen2",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen2 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureBlobFSSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Change data capture
Azure Data Factory může získat nové nebo změněné soubory pouze z Azure Data Lake Storage Gen2 povolením povolení zachytávání dat změn v transformaci zdroje toku dat mapování. Pomocí této možnosti konektoru můžete číst pouze nové nebo aktualizované soubory a použít transformace před načtením transformovaných dat do cílových datových sad podle vašeho výběru.
Ujistěte se, že název kanálu a aktivity zůstane beze změny, aby se kontrolní bod mohl vždy zaznamenávat z posledního spuštění, abyste odsud získali změny. Pokud změníte název kanálu nebo název aktivity, kontrolní bod se resetuje a začnete od začátku dalšího spuštění.
Při ladění kanálu funguje také funkce Povolit zachytávání dat změn. Mějte na paměti, že kontrolní bod se resetuje při aktualizaci prohlížeče během spuštění ladění. Jakmile budete s výsledkem spuštění ladění spokojeni, můžete kanál publikovat a aktivovat. Vždy začne od začátku bez ohledu na předchozí kontrolní bod zaznamenaný spuštěním ladění.
V části monitorování máte vždy možnost znovu spustit kanál. Když to uděláte, změny se vždy z záznamu kontrolního bodu ve vybraném spuštění kanálu zobrazí.
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v tématu Podporované úložiště dat.