Kopírování dat ze serveru HDFS pomocí služby Azure Data Factory nebo Synapse Analytics
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak kopírovat data ze serveru HDFS (Hadoop Distributed File System). Další informace najdete v úvodních článcích pro Azure Data Factory a Synapse Analytics.
Podporované funkce
Tento konektor HDFS je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/-) | (1) (2) |
| Aktivita Lookup | (1) (2) |
| Aktivita odstranění | (1) (2) |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Konkrétně konektor HDFS podporuje:
- Kopírování souborů pomocí windows (Kerberos) nebo anonymního ověřování
- Kopírování souborů pomocí protokolu webhdfs nebo integrované podpory DistCp
- Kopírování souborů tak, jak je, nebo parsováním nebo generováním souborů s podporovanými formáty souborů a kompresí kodeků.
Požadavky
Pokud se vaše úložiště dat nachází uvnitř místní sítě, virtuální sítě Azure nebo amazonového privátního cloudu, musíte nakonfigurovat místní prostředí Integration Runtime pro připojení k němu.
Pokud je vaše úložiště dat spravovanou cloudovou datovou službou, můžete použít Azure Integration Runtime. Pokud je přístup omezený na IP adresy schválené v pravidlech brány firewall, můžete do seznamu povolených přidat IP adresy prostředí Azure Integration Runtime.
K přístupu k místní síti bez nutnosti instalace a konfigurace místního prostředí Integration Runtime můžete také použít funkci Runtime integrace spravované virtuální sítě ve službě Azure Data Factory.
Další informace o mechanismech zabezpečení sítě a možnostech podporovaných službou Data Factory najdete v tématu Strategie přístupu k datům.
Poznámka:
Ujistěte se, že prostředí Integration Runtime má přístup ke všem serverům [názvový uzel]:[port uzlu name] a [servery datových uzlů]:[port datového uzlu] clusteru Hadoop. Výchozí [port uzlu názvu] je 50070 a výchozí [port datového uzlu] je 50075.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby do HDFS pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu s HDFS v uživatelském rozhraní webu Azure Portal.
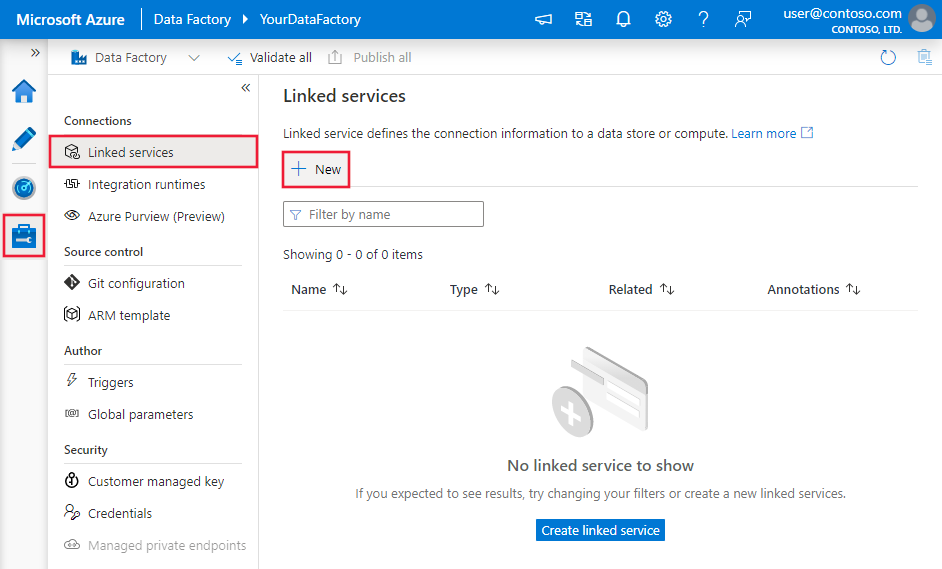
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte HDFS a vyberte konektor HDFS.
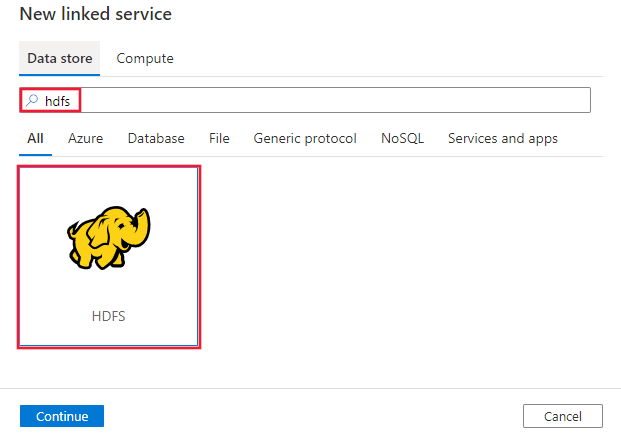
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
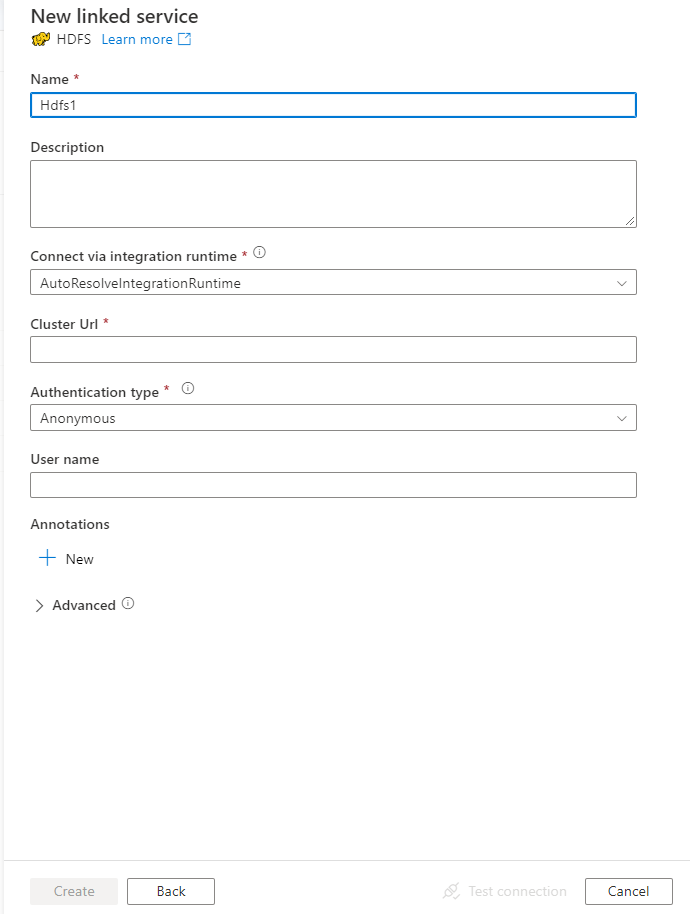
Podrobnosti konfigurace konektoru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit služby Data Factory specifických pro HDFS.
Vlastnosti propojené služby
Propojená služba HDFS podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na Hdfs. | Ano |
| url | Adresa URL hdFS | Ano |
| authenticationType | Povolené hodnoty jsou Anonymní nebo Windows. Pokud chcete nastavit místní prostředí, přečtěte si část Použití ověřování Kerberos pro konektor HDFS. |
Ano |
| userName | Uživatelské jméno pro ověřování systému Windows. Pro ověřování protokolem Kerberos zadejte <uživatelské jméno>@<doména>.com. | Ano (pro ověřování systému Windows) |
| Heslo | Heslo pro ověřování systému Windows. Označte toto pole jako securestring, abyste ho mohli bezpečně uložit, nebo odkazovat na tajný klíč uložený v trezoru klíčů Azure. | Ano (pro ověřování systému Windows) |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný prostředí Integration Runtime, služba používá výchozí prostředí Azure Integration Runtime. | No |
Příklad: Použití anonymního ověřování
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad: Použití ověřování systému Windows
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností, které jsou k dispozici pro definování datových sad, najdete v tématu Datové sady.
Azure Data Factory podporuje následující formáty souborů. Informace o nastaveních založených na formátu najdete v jednotlivých článcích.
- Formát Avro
- Binární formát
- Formát textu s oddělovači
- Formát aplikace Excel
- Formát JSON
- Formát ORC
- Formát Parquet
- Formát XML
V nastavení v datové sadě založené na formátu se podporují následující vlastnosti hdFS location :
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost location typu v datové sadě musí být nastavena na HdfsLocation. |
Ano |
| folderPath | Cesta ke složce. Pokud chcete k filtrování složky použít zástupný znak, přeskočte toto nastavení a zadejte cestu v nastavení zdroje aktivity. | No |
| fileName | Název souboru v zadané cestě folderPath. Pokud chcete k filtrování souborů použít zástupný znak, přeskočte toto nastavení a zadejte název souboru v nastavení zdroje aktivity. | No |
Příklad:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností, které jsou k dispozici pro definování aktivit, najdete v tématu Kanály a aktivity. Tato část obsahuje seznam vlastností podporovaných zdrojem HDFS.
HDFS jako zdroj
Azure Data Factory podporuje následující formáty souborů. Informace o nastaveních založených na formátu najdete v jednotlivých článcích.
- Formát Avro
- Binární formát
- Formát textu s oddělovači
- Formát aplikace Excel
- Formát JSON
- Formát ORC
- Formát Parquet
- Formát XML
V nastavení ve zdroji kopírování založeném na formátu jsou podporovány následující vlastnosti systému HDFS storeSettings :
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu pod storeSettings musí být nastavena na HdfsReadSettings. |
Ano |
| Vyhledejte soubory, které chcete zkopírovat. | ||
| MOŽNOST 1: Statická cesta |
Zkopírujte ze složky nebo cesty k souboru zadané v datové sadě. Pokud chcete zkopírovat všechny soubory ze složky, dále zadejte wildcardFileName jako *. |
|
| MOŽNOST 2: Zástupný znak – zástupný znakFolderPath |
Cesta ke složce se zástupnými znaky pro filtrování zdrojových složek. Povolené zástupné znaky jsou: * (odpovídá nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku). Slouží ^ k řídicímu znaku, pokud má skutečný název složky zástupný znak nebo tento řídicí znak uvnitř. Další příklady najdete v příkladech filtru složek a souborů. |
No |
| MOŽNOST 2: Zástupný znak - wildcardFileName |
Název souboru se zástupnými znaky pod zadanou složkouPath nebo zástupnými znakyFolderPath pro filtrování zdrojových souborů. Povolené zástupné znaky jsou: * (odpovídá nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku), použijte ^ k řídicímu znaku, pokud má skutečný název souboru zástupný znak nebo tento řídicí znak uvnitř. Další příklady najdete v příkladech filtru složek a souborů. |
Ano |
| MOŽNOST 3: seznam souborů - fileListPath |
Označuje, že chcete zkopírovat zadanou sadu souborů. Přejděte na textový soubor, který obsahuje seznam souborů, které chcete kopírovat (jeden soubor na řádek s relativní cestou k cestě nakonfigurované v datové sadě). Pokud použijete tuto možnost, nezadávejte v datové sadě název souboru. Další příklady najdete v tématu Příklady seznamu souborů. |
No |
| Další nastavení | ||
| rekurzivní | Určuje, zda se data čtou rekurzivně z podsložek nebo pouze ze zadané složky. Pokud recursive je nastavena hodnota true a jímka je úložiště založené na souborech, prázdná složka nebo podsložka se nezkopíruje ani nevytvoří v jímce. Povolené hodnoty jsou true (výchozí) a false. Tato vlastnost se nepoužije při konfiguraci fileListPath. |
No |
| deleteFilesAfterCompletion | Určuje, zda se binární soubory odstraní ze zdrojového úložiště po úspěšném přesunutí do cílového úložiště. Odstranění souboru je na každém souboru, takže když aktivita kopírování selže, uvidíte, že se některé soubory už zkopírovaly do cíle a odstranily ze zdroje, zatímco ostatní zůstávají ve zdrojovém úložišti. Tato vlastnost je platná pouze ve scénáři kopírování binárních souborů. Výchozí hodnota: false. |
No |
| modifiedDatetimeStart | Soubory se filtrují na základě atributu Naposledy změněno. Soubory jsou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu 2018-12-01T05:00:00Z. Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady není použit žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že jsou vybrány soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, jsou vybrány.Tato vlastnost se nepoužije při konfiguraci fileListPath. |
No |
| modifiedDatetimeEnd | Platí to samé jako výše. | |
| enablePartitionDiscovery | U souborů, které jsou rozdělené na oddíly, určete, zda chcete analyzovat oddíly z cesty k souboru a přidat je jako další zdrojové sloupce. Povolené hodnoty jsou false (výchozí) a true. |
No |
| partitionRootPath | Pokud je povolené zjišťování oddílů, zadejte absolutní kořenovou cestu, abyste mohli číst dělené složky jako datové sloupce. Pokud není ve výchozím nastavení zadán, – Při použití cesty k souboru v datové sadě nebo seznamu souborů ve zdroji je kořenová cesta oddílu cesta nakonfigurovaná v datové sadě. – Pokud používáte filtr složky se zástupnými otazemi, je kořenová cesta oddílu dílčí cestou před prvním zástupným znakem. Předpokládejme například, že cestu v datové sadě nakonfigurujete jako "root/folder/year=2020/month=08/day=27": – Pokud zadáte kořenovou cestu oddílu jako "root/folder/year=2020", aktivita kopírování vygeneruje dva další sloupce month a day s hodnotou 08 a 27 kromě sloupců uvnitř souborů.– Pokud není zadaná kořenová cesta oddílu, nevygeneruje se žádný sloupec navíc. |
No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
| Nastavení DistCp | ||
| distcpSettings | Skupinavlastnostích | No |
| resourceManagerEndpoint | Koncový bod YARN (ještě jiný vyjednavač prostředků) | Ano, pokud používáte DistCp |
| tempScriptPath | Cesta ke složce, která se používá k uložení dočasného skriptu příkazu DistCp. Soubor skriptu se vygeneruje a po dokončení úlohy kopírování se odebere. | Ano, pokud používáte DistCp |
| distcpOptions | K dispozici jsou další možnosti příkazu DistCp. | No |
Příklad:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Příklady filtrů složek a souborů
Tato část popisuje výsledné chování, pokud použijete filtr se zástupným znakem s cestou ke složce a názvem souboru.
| folderPath | fileName | rekurzivní | Struktura zdrojové složky a výsledek filtru (soubory se načítají tučně ) |
|---|---|---|---|
Folder* |
(prázdné, použijte výchozí) | false (nepravda) | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(prázdné, použijte výchozí) | true | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false (nepravda) | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Příklady seznamu souborů
Tato část popisuje chování, které má za následek použití cesty k seznamu souborů ve zdroji aktivita Copy. Předpokládá se, že máte následující strukturu zdrojové složky a chcete zkopírovat soubory, které jsou tučného typu:
| Ukázková zdrojová struktura | Obsah v FileListToCopy.txt | Konfigurace |
|---|---|---|
| kořen FolderA File1.csv File2.json Podsložka 1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Podsložka1/File3.csv Podsložka1/File5.csv |
V datové sadě: - Cesta ke složce: root/FolderAVe zdroji aktivita Copy: - Cesta k seznamu souborů: root/Metadata/FileListToCopy.txt Cesta k seznamu souborů odkazuje na textový soubor ve stejném úložišti dat, který obsahuje seznam souborů, které chcete kopírovat (jeden soubor na řádek s relativní cestou k cestě nakonfigurované v datové sadě). |
Kopírování dat z HDFS pomocí DistCp
DistCp je nativní nástroj příkazového řádku Hadoop pro provádění distribuované kopie v clusteru Hadoop. Když spustíte příkaz v DistCp, nejprve vypíše všechny soubory, které se mají zkopírovat, a pak v clusteru Hadoop vytvoří několik úloh mapování. Každá úloha mapování provede binární kopii ze zdroje do jímky.
Aktivita Copy podporuje kopírování souborů pomocí DistCp tak, jak je to ve službě Azure Blob Storage (včetně fázované kopie) nebo ve službě Azure Data Lake Store. V takovém případě může DistCp využívat výkon vašeho clusteru místo toho, aby běžel v místním prostředí Integration Runtime. Použití DistCp poskytuje lepší propustnost kopírování, zejména pokud je váš cluster velmi výkonný. Na základě konfigurace aktivita Copy automaticky vytvoří příkaz DistCp, odešle ho do clusteru Hadoop a monitoruje stav kopírování.
Požadavky
Pokud chcete použít DistCp ke kopírování souborů z HDFS do Azure Blob Storage (včetně fázované kopie) nebo Azure Data Lake Store, ujistěte se, že váš cluster Hadoop splňuje následující požadavky:
Jsou povoleny služby MapReduce a YARN.
Verze YARN je 2.5 nebo novější.
Server HDFS je integrovaný s vaším cílovým úložištěm dat: Azure Blob Storage nebo Azure Data Lake Store (ADLS Gen1):
- Azure Blob FileSystem se nativně podporuje, protože Hadoop 2.7. V konfiguraci prostředí Hadoop je potřeba zadat pouze cestu JAR.
- Azure Data Lake Store FileSystem je zabalený od Hadoopu 3.0.0-alpha1. Pokud je vaše verze clusteru Hadoop starší než tato verze, musíte do clusteru ručně importovat balíčky JAR související se službou Azure Data Lake Store (azure-datalake-store.jar) a zadat cestu k souboru JAR v konfiguraci prostředí Hadoop.
Připravte dočasnou složku v HDFS. Tato dočasná složka se používá k ukládání skriptu prostředí DistCp, takže zabírají prostor na úrovni KB.
Ujistěte se, že uživatelský účet, který je součástí propojené služby HDFS, má oprávnění k:
- Odešlete aplikaci v YARN.
- V dočasné složce vytvořte podsložku a soubory pro čtení a zápis.
Konfigurace
Informace o konfiguracích a příkladech souvisejících s DistCp najdete v části HDFS jako zdroj .
Použití ověřování Kerberos pro konektor HDFS
Pro nastavení místního prostředí pro použití ověřování Kerberos pro konektor HDFS existují dvě možnosti. Můžete si vybrat ten, který lépe vyhovuje vaší situaci.
- Možnost 1: Připojení počítače místního prostředí Integration Runtime v sférě Kerberos
- Možnost 2: Povolení vzájemného vztahu důvěryhodnosti mezi doménou Windows a sférou Kerberos
U obou možností se ujistěte, že pro cluster Hadoop zapnete webhdfs:
Vytvořte objekt zabezpečení HTTP a klíčovou kartu pro webhdfs.
Důležité
Instanční objekt protokolu HTTP Kerberos musí začínat protokolem HTTP/podle specifikace PROTOKOLU KERBEROS HTTP SPNEGO. Další informace najdete tady.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>Možnosti konfigurace SYSTÉMU HDFS: přidejte do souboru následující tři vlastnosti
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Možnost 1: Připojení počítače místního prostředí Integration Runtime v sférě Kerberos
Požadavky
- Počítač místního prostředí Integration Runtime musí připojit sféru Kerberos a nemůže se připojit k žádné doméně Windows.
Způsob konfigurace
Na serveru KDC:
Vytvořte objekt zabezpečení a zadejte heslo.
Důležité
Uživatelské jméno by nemělo obsahovat název hostitele.
Kadmin> addprinc <username>@<REALM.COM>
Na počítači s místním prostředím Integration Runtime:
Spuštěním nástroje Ksetup nakonfigurujte server ADC (Kerberos Key Distribution Center) a sféru.
Počítač musí být nakonfigurovaný jako člen pracovní skupiny, protože sféra Kerberos se liší od domény Windows. Tuto konfiguraci můžete dosáhnout nastavením sféry Kerberos a přidáním serveru KDC spuštěním následujících příkazů. Nahraďte REALM.COM vlastním názvem sféry.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>Po spuštění těchto příkazů restartujte počítač.
Pomocí příkazu ověřte konfiguraci
Ksetup. Výstup by měl vypadat takto:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
V datové továrně nebo pracovním prostoru Synapse:
- Nakonfigurujte konektor HDFS pomocí ověřování systému Windows spolu s hlavním názvem protokolu Kerberos a heslem pro připojení ke zdroji dat HDFS. Podrobnosti o konfiguraci najdete v části vlastností propojené služby HDFS.
Možnost 2: Povolení vzájemného vztahu důvěryhodnosti mezi doménou Windows a sférou Kerberos
Požadavky
- Počítač místního prostředí Integration Runtime se musí připojit k doméně Windows.
- Potřebujete oprávnění k aktualizaci nastavení řadiče domény.
Způsob konfigurace
Poznámka:
V následujícím kurzu nahraďte REALM.COM a AD.COM vlastním názvem sféry a řadičem domény.
Na serveru KDC:
Upravte konfiguraci KDC v souboru krb5.conf tak, aby služba KDC důvěřovala doméně Windows pomocí následující šablony konfigurace. Ve výchozím nastavení se konfigurace nachází na adrese /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }Po nakonfigurování souboru restartujte službu KDC.
Připravte objekt zabezpečení s názvem krbtgt/REALM.COM@AD.COM na serveru KDC pomocí následujícího příkazu:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMDo konfiguračního souboru služby hadoop.security.auth_to_local HDFS přidejte
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
Na řadiči domény:
Spuštěním následujících
Ksetuppříkazů přidejte položku sféry:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMNavázání vztahu důvěryhodnosti z domény Windows do sféry Kerberos. [password] je heslo pro instanční objekt krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Vyberte šifrovací algoritmus, který se používá v protokolu Kerberos.
a. Vyberte Správce serveru> Skupit objekty>zásad skupiny domén správy>zásad>skupiny výchozí nebo aktivní zásady domény a pak vyberte Upravit.
b. V podokně Editor pro správu zásad skupiny vyberte Možnosti zabezpečení místní zásady>zabezpečení nastavení>zabezpečení Nastavení zabezpečení>nastavení>konfigurace počítače>a pak nakonfigurujte zabezpečení sítě: Konfigurace typů šifrování povolených pro Protokol Kerberos.
c. Vyberte šifrovací algoritmus, který chcete použít při připojení k serveru KDC. Můžete vybrat všechny možnosti.

d.
KsetupPomocí příkazu zadejte šifrovací algoritmus, který se má použít v zadané sférě.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Vytvořte mapování mezi účtem domény a objektem zabezpečení Kerberos, abyste mohli použít instanční objekt Kerberos v doméně Windows.
a. Vyberte nástroje pro> správu Uživatelé a počítače služby Active Directory.
b. Nakonfigurujte pokročilé funkce výběrem možnosti Zobrazit>pokročilé funkce.
c. V podokně Rozšířené funkce klikněte pravým tlačítkem myši na účet, na který chcete vytvořit mapování, a v podokně Mapování názvů vyberte kartu Názvy protokolu Kerberos.
d. Přidejte objekt zabezpečení z sféry.
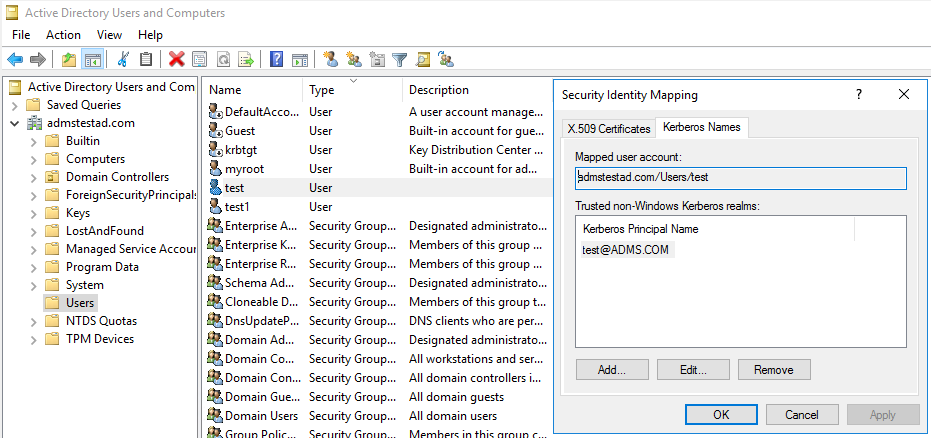
Na počítači s místním prostředím Integration Runtime:
Spuštěním následujících
Ksetuppříkazů přidejte položku sféry.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
V datové továrně nebo pracovním prostoru Synapse:
- Nakonfigurujte konektor HDFS pomocí ověřování systému Windows společně s vaším účtem domény nebo instančním objektem Kerberos pro připojení ke zdroji dat HDFS. Podrobnosti o konfiguraci najdete v části vlastnosti propojené služby HDFS.
Vlastnosti aktivity vyhledávání
Informace o vlastnostech aktivity Vyhledávání naleznete v tématu Aktivita vyhledávání.
Odstranění vlastností aktivity
Informace o vlastnostech aktivity odstranění naleznete v tématu Odstranění aktivity.
Starší modely
Poznámka:
Následující modely jsou stále podporovány, stejně jako v případě zpětné kompatibility. Doporučujeme použít dříve probíraný nový model, protože uživatelské rozhraní pro vytváření se přepnulo na generování nového modelu.
Starší model datové sady
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavená na FileShare. | Ano |
| folderPath | Cesta ke složce. Podporuje se filtr zástupných znaků. Povolené zástupné znaky jsou * (odpovídají nule nebo více znaků) a ? (odpovídá nule nebo jednomu znaku), použijte ^ k řídicímu znaku, pokud má váš skutečný název souboru zástupný znak nebo tento řídicí znak uvnitř. Příklady: rootfolder/podsložka/, viz další příklady v příkladech filtru složek a souborů. |
Ano |
| fileName | Název nebo filtr zástupných znaků pro soubory v zadané cestě folderPath. Pokud pro tuto vlastnost nezadáte hodnotu, datová sada odkazuje na všechny soubory ve složce. Pro filtr jsou * povolené zástupné znaky (odpovídají nule nebo více znakům) a ? (odpovídá nule nebo jednomu znaku).– Příklad 1: "fileName": "*.csv"– Příklad 2: "fileName": "???20180427.txt"Slouží ^ k řídicímu znaku, pokud má skutečný název složky zástupný znak nebo tento řídicí znak uvnitř. |
No |
| modifiedDatetimeStart | Soubory se filtrují na základě atributu Naposledy změněno. Soubory jsou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu 2018-12-01T05:00:00Z. Mějte na paměti, že celkový výkon přesunu dat bude ovlivněn povolením tohoto nastavení, pokud chcete použít filtr souborů na velký počet souborů. Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady není použit žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že jsou vybrány soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, jsou vybrány. |
No |
| modifiedDatetimeEnd | Soubory se filtrují na základě atributu Naposledy změněno. Soubory jsou vybrány, pokud je jejich čas poslední změny větší nebo roven modifiedDatetimeStart a menší než modifiedDatetimeEnd. Čas se použije u časového pásma UTC ve formátu 2018-12-01T05:00:00Z. Mějte na paměti, že celkový výkon přesunu dat bude ovlivněn povolením tohoto nastavení, pokud chcete použít filtr souborů na velký počet souborů. Vlastnosti můžou mít hodnotu NULL, což znamená, že u datové sady není použit žádný filtr atributů souboru. Pokud modifiedDatetimeStart má hodnotu datetime, ale modifiedDatetimeEnd má hodnotu NULL, znamená to, že jsou vybrány soubory, jejichž atribut poslední změny je větší nebo roven hodnotě datetime. Pokud modifiedDatetimeEnd má hodnotu datetime, ale modifiedDatetimeStart má hodnotu NULL, znamená to, že soubory, jejichž atribut poslední změny je menší než hodnota datetime, jsou vybrány. |
No |
| format | Pokud chcete kopírovat soubory tak, jak je to mezi úložišti založenými na souborech (binární kopie), přeskočte oddíl formátu v definicích vstupní i výstupní datové sady. Pokud chcete analyzovat soubory s určitým formátem, podporují se následující typy formátů souborů: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Nastavte vlastnost typu ve formátu na jednu z těchto hodnot. Další informace najdete v částech Formát textu, Formát JSON, Formát Avro, Formát ORC a Parquet . |
Ne (pouze pro scénář binárního kopírování) |
| komprese | Zadejte typ a úroveň komprese dat. Další informace naleznete v tématu Podporované formáty souborů a komprimační kodeky. Podporované typy jsou: Gzip, Deflate, Bzip2 a ZipDeflate. Podporované úrovně jsou: Optimální a nejrychlejší. |
No |
Tip
Chcete-li kopírovat všechny soubory ve složce, zadejte pouze folderPath .
Pokud chcete zkopírovat jeden soubor se zadaným názvem, zadejte folderPath s částí složky a fileName s názvem souboru.
Chcete-li zkopírovat podmnožinu souborů ve složce, zadejte folderPath s částí složky a fileName s filtrem zástupných znaků.
Příklad:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Starší verze zdrojového modelu aktivita Copy
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivita Copy musí být nastavena na HdfsSource. | Ano |
| rekurzivní | Určuje, zda se data čtou rekurzivně z podsložek nebo pouze ze zadané složky. Pokud je rekurzivní nastavena na hodnotu true a jímka je úložiště založené na souborech, prázdná složka nebo podsložka se v jímce nezkopíruje ani nevytvoří. Povolené hodnoty jsou true (výchozí) a false. |
No |
| distcpSettings | Skupina vlastností při použití distCp HDFS. | No |
| resourceManagerEndpoint | Koncový bod Resource Manageru YARN | Ano, pokud používáte DistCp |
| tempScriptPath | Cesta ke složce, která se používá k uložení dočasného skriptu příkazu DistCp. Soubor skriptu se vygeneruje a po dokončení úlohy kopírování se odebere. | Ano, pokud používáte DistCp |
| distcpOptions | K dispozici jsou další možnosti příkazu DistCp. | No |
| maxConcurrentConnections | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | No |
Příklad: Zdroj HDFS v aktivita Copy pomocí DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivita Copy najdete v podporovaných úložištích dat.