Nasazení modelů strojového učení do Azure
PLATÍ PRO: Rozšíření Azure CLI ml v1Python SDK azureml v1
Rozšíření Azure CLI ml v1Python SDK azureml v1
Zjistěte, jak nasadit model strojového učení nebo hlubokého učení jako webovou službu v cloudu Azure.
Poznámka:
Koncové body služby Azure Machine Learning (v2) poskytují vylepšené a jednodušší prostředí pro nasazení. Koncové body podporují scénáře odvození v reálném čase i dávkového odvozu. Koncové body poskytují jednotné rozhraní pro vyvolání a správu nasazení modelu napříč typy výpočetních prostředků. Podívejte se, co jsou koncové body služby Azure Machine Learning?
Pracovní postup pro nasazení modelu
Pracovní postup je podobný bez ohledu na to, kam model nasadíte:
- Zaregistrujte model.
- Připravte vstupní skript.
- Připravte konfiguraci odvozování.
- Nasaďte model místně, abyste zajistili, že všechno funguje.
- Zvolte cílový výpočetní objekt.
- Nasaďte model do cloudu.
- Otestujte výslednou webovou službu.
Další informace o konceptech, které jsou součástí pracovního postupu nasazení strojového učení, najdete v tématu Správa, nasazení a monitorování modelů pomocí služby Azure Machine Learning.
Požadavky
PLATÍ PRO: Rozšíření Azure CLI ml v1
Důležité
Některé příkazy Azure CLI v tomto článku používají azure-cli-mlrozšíření (nebo v1) pro Azure Machine Learning. Podpora rozšíření v1 skončí 30. září 2025. Do tohoto data budete moct nainstalovat a používat rozšíření v1.
Doporučujeme přejít na mlrozšíření (nebo v2) před 30. zářím 2025. Další informace o rozšíření v2 najdete v tématu Rozšíření Azure ML CLI a Python SDK v2.
- Pracovní prostor služby Azure Machine Learning. Další informace najdete v tématu Vytvoření prostředků pracovního prostoru.
- Model. Příklady v tomto článku používají předem natrénovaný model.
- Počítač, který může spouštět Docker, například výpočetní instanci.
Připojení k pracovnímu prostoru
PLATÍ PRO: Rozšíření Azure CLI ml v1
Pokud chcete zobrazit pracovní prostory, ke kterým máte přístup, použijte následující příkazy:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registrace modelu
Typická situace nasazené služby machine learning je, že potřebujete následující komponenty:
- Prostředky představující konkrétní model, který chcete nasadit (například soubor modelu pytorch).
- Kód, který budete používat ve službě, která spouští model na daném vstupu.
Azure Machine Learnings umožňuje rozdělit nasazení do dvou samostatných komponent, abyste mohli zachovat stejný kód a aktualizovat jenom model. Mechanismus, kterým nahrajete model odděleně od kódu, definujeme jako registraci modelu.
Když zaregistrujete model, nahrajeme ho do cloudu (do výchozího účtu úložiště vašeho pracovního prostoru) a pak ho připojíme ke stejnému výpočetnímu prostředí, ve kterém je spuštěná vaše webová služba.
Následující příklady ukazují, jak zaregistrovat model.
Důležité
Měli byste používat pouze modely, které jste sami vytvořili nebo získali z důvěryhodného zdroje. Se serializovanými modely byste měli zacházet jako s kódem, protože v řadě oblíbených formátů se zjistila ohrožení zabezpečení. Modely také můžou být záměrně natrénované se zlými úmysly, aby poskytovaly zkreslený nebo nepřesný výstup.
PLATÍ PRO: Rozšíření Azure CLI ml v1
Následující příkazy stáhnutí modelu a jeho registraci v pracovním prostoru Azure Machine Learning:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Nastavte -p cestu ke složce nebo souboru, který chcete zaregistrovat.
Další informace najdete az ml model registerv referenční dokumentaci.
Registrace modelu z trénovací úlohy služby Azure Machine Learning
Pokud potřebujete zaregistrovat model vytvořený dříve prostřednictvím trénovací úlohy služby Azure Machine Learning, můžete zadat experiment, spustit a přejít k modelu:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Parametr --asset-path odkazuje na cloudové umístění modelu. V tomto příkladu se používá cesta k jednomu souboru. Pokud chcete do registrace modelu zahrnout více souborů, nastavte --asset-path cestu ke složce, která obsahuje soubory.
Další informace najdete az ml model registerv referenční dokumentaci.
Poznámka:
Model můžete také zaregistrovat z místního souboru prostřednictvím portálu uživatelského rozhraní pracovního prostoru.
V současné době existují dvě možnosti pro nahrání souboru místního modelu v uživatelském rozhraní:
- Z místních souborů, které zaregistrují model v2.
- Z místních souborů (na základě architektury) se zaregistruje model verze 1.
Všimněte si, že pomocí SDKv1/CLIv1 je možné nasadit pouze modely zaregistrované prostřednictvím místních souborů (na základě architektury), které se označují jako modely verze 1.
Definování fiktivního vstupního skriptu
Vstupní skript přijímá data odeslaná do nasazené webové služby a předává je do modelu. Pak vrátí odpověď modelu klientovi. Skript je specifický pro váš model. Vstupní skript musí rozumět datům, která model očekává a vrací.
Ve vstupním skriptu je potřeba provést dvě věci:
- Načtení modelu (pomocí funkce s názvem
init()) - Spuštění modelu na vstupních datech (pomocí funkce s názvem
run())
Pro počáteční nasazení použijte fiktivní vstupní skript, který vytiskne data, která obdrží.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Uložte tento soubor jako echo_score.py uvnitř adresáře s názvem source_dir. Tento fiktivní skript vrátí data, která do něj odesíláte, takže model nepoužívá. Je ale užitečné otestovat, že je skript bodování spuštěný.
Definování konfigurace odvozování
Konfigurace odvozování popisuje kontejner a soubory Dockeru, které se mají použít při inicializaci webové služby. Všechny soubory ve zdrojovém adresáři, včetně podadresářů, se při nasazení webové služby zazipují a nahrají do cloudu.
Následující konfigurace odvozování určuje, že nasazení strojového učení použije soubor echo_score.py v ./source_dir adresáři ke zpracování příchozích požadavků a že použije image Dockeru s balíčky Pythonu zadanými v project_environment prostředí.
Při vytváření prostředí projektu můžete jako základní image Dockeru použít libovolná kurátorovaná prostředí azure Machine Learning. Na začátek nainstalujeme požadované závislosti a uložíme výslednou image Dockeru do úložiště, které je přidružené k vašemu pracovnímu prostoru.
Poznámka:
Nahrání zdrojového adresáře pro odvozování ve službě Azure Machine Learning nerespektuje .gitignore ani .amlignore
PLATÍ PRO: Rozšíření Azure CLI ml v1
Minimální konfiguraci odvozování lze zapsat takto:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Uložte tento soubor s názvem dummyinferenceconfig.json.
Podrobnější diskuzi o konfiguracích odvozování najdete v tomto článku .
Definování konfigurace nasazení
Konfigurace nasazení určuje množství paměti a jader, které vaše webová služba potřebuje ke spuštění. Poskytuje také podrobnosti o konfiguraci základní webové služby. Například konfigurace nasazení umožňuje určit, že vaše služba potřebuje 2 gigabajty paměti, 2 jádra procesoru, 1 jádro GPU a že chcete povolit automatické škálování.
Možnosti dostupné pro konfiguraci nasazení se liší v závislosti na zvoleném cílovém výpočetním objektu. V místním nasazení můžete zadat vše, na kterém portu bude webová služba obsluhována.
PLATÍ PRO: Rozšíření Azure CLI ml v1
Položky v deploymentconfig.json dokumentu se mapují na parametry pro LocalWebservice.deploy_configuration. Následující tabulka popisuje mapování mezi entitami v dokumentu JSON a parametry metody:
| Entita JSON | Parametr metody | Popis |
|---|---|---|
computeType |
NA | Cílový výpočetní objekt. Pro místní cíle musí být localhodnota . |
port |
port |
Místní port, na kterém se má zveřejnit koncový bod HTTP služby. |
Tento JSON je ukázková konfigurace nasazení pro použití s rozhraním příkazového řádku:
{
"computeType": "local",
"port": 32267
}
Uložte tento JSON jako soubor s názvem deploymentconfig.json.
Nasazení modelu strojového učení
Teď jste připraveni k nasazení modelu.
PLATÍ PRO: Rozšíření Azure CLI ml v1
Nahraďte bidaf_onnx:1 názvem modelu a jeho číslem verze.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Volání do modelu
Pojďme zkontrolovat, jestli se model echo úspěšně nasadil. Měli byste být schopni provést jednoduchou žádost o liveness a také žádost o bodování:
PLATÍ PRO: Rozšíření Azure CLI ml v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definování vstupního skriptu
Teď je čas načíst model. Nejprve upravte vstupní skript:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Uložte tento soubor jako score.py uvnitř source_dirsouboru .
Všimněte si použití proměnné prostředí k vyhledání registrovaného AZUREML_MODEL_DIR modelu. Teď, když jste přidali nějaké balíčky pip.
PLATÍ PRO: Rozšíření Azure CLI ml v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Uložit tento soubor jako inferenceconfig.json
Opětovné nasazení a volání služby
Znovu nasaďte službu:
PLATÍ PRO: Rozšíření Azure CLI ml v1
Nahraďte bidaf_onnx:1 názvem modelu a jeho číslem verze.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Pak se ujistěte, že do služby můžete odeslat žádost o příspěvek:
PLATÍ PRO: Rozšíření Azure CLI ml v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Volba cílového výpočetního objektu
Cílový výpočetní objekt, který použijete k hostování modelu, ovlivní náklady a dostupnost nasazeného koncového bodu. Tato tabulka slouží k výběru vhodného cílového výpočetního objektu.
| Cílový výpočetní objekt | Použití | Podpora GPU | Popis |
|---|---|---|---|
| Místní webová služba | Testování/ladění | Slouží k omezenému testování a řešení potíží. Hardwarová akcelerace závisí na použití knihoven v místním systému. | |
| Azure Machine Learning Kubernetes | Odvozování v reálném čase | Ano | Spouštění odvozování úloh v cloudu |
| Azure Container Instances | Odvození v reálném čase Doporučuje se pouze pro účely vývoje/testování. |
Používá se pro úlohy založené na procesoru s nízkou škálou, které vyžadují méně než 48 GB paměti RAM. Nevyžaduje správu clusteru. Vhodné pouze pro modely menší než 1 GB. Podporováno v návrháři. |
Poznámka:
Při výběru skladové položky clusteru nejprve vertikálně navyšte kapacitu a pak vertikálně navyšte kapacitu. Začněte počítačem, který má 150 % paměti RAM, který váš model vyžaduje, profilujte výsledek a najděte počítač, který má požadovaný výkon. Jakmile se to naučíte, zvyšte počet počítačů tak, aby vyhovoval vašim potřebujete pro souběžné odvozování.
Poznámka:
Koncové body služby Azure Machine Learning (v2) poskytují vylepšené a jednodušší prostředí pro nasazení. Koncové body podporují scénáře odvození v reálném čase i dávkového odvozu. Koncové body poskytují jednotné rozhraní pro vyvolání a správu nasazení modelu napříč typy výpočetních prostředků. Podívejte se, co jsou koncové body služby Azure Machine Learning?
Nasazení do cloudu
Jakmile potvrdíte, že vaše služba funguje místně a zvolíte vzdálený cílový výpočetní objekt, můžete ho nasadit do cloudu.
Změňte konfiguraci nasazení tak, aby odpovídala zvolenému cílovému výpočetnímu objektu, v tomto případě azure Container Instances:
PLATÍ PRO: Rozšíření Azure CLI ml v1
Možnosti dostupné pro konfiguraci nasazení se liší v závislosti na zvoleném cílovém výpočetním objektu.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Uložte tento soubor jako re-deploymentconfig.json.
Další informace najdete v této referenční dokumentaci.
Znovu nasaďte službu:
PLATÍ PRO: Rozšíření Azure CLI ml v1
Nahraďte bidaf_onnx:1 názvem modelu a jeho číslem verze.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Pokud chcete zobrazit protokoly služby, použijte následující příkaz:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Volání vzdálené webové služby
Při vzdáleném nasazení můžete mít povolené ověřování pomocí klíče. Následující příklad ukazuje, jak získat klíč služby pomocí Pythonu, aby bylo možné provést žádost o odvození.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Další příklady klientů v jiných jazycích najdete v článku o klientských aplikacích pro využívání webových služeb .
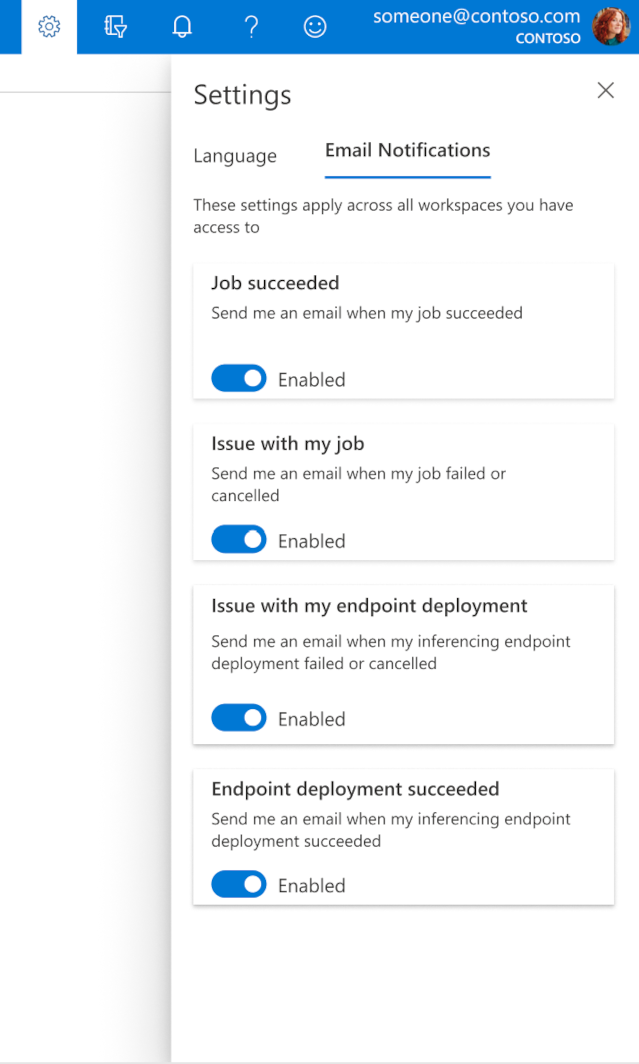
Jak nakonfigurovat e-maily v sadě Studio
Pokud chcete začít přijímat e-maily po dokončení úlohy, online koncového bodu nebo dávkového koncového bodu nebo v případě, že došlo k problému (selhání, zrušení), postupujte následovně:
- V nástroji Azure ML Studio přejděte na nastavení výběrem ikony ozubeného kola.
- Vyberte kartu E-mailová oznámení.
- Přepnutím povolíte nebo zakážete e-mailová oznámení pro konkrétní událost.
Principy stavu služby
Během nasazování modelu se může během plného nasazení zobrazit změna stavu služby.
Následující tabulka popisuje různé stavy služeb:
| Stav webové služby | Popis | Koncový stav? |
|---|---|---|
| Probíhá přechod | Služba probíhá v procesu nasazení. | No |
| Není v pořádku | Služba se nasadila, ale momentálně je nedostupná. | No |
| Nenaplánovatelné | Službu nelze v tuto chvíli nasadit kvůli nedostatku prostředků. | No |
| Neúspěšný | Službě se nepodařilo nasadit kvůli chybě nebo chybě. | Ano |
| V pořádku | Služba je v pořádku a koncový bod je k dispozici. | Ano |
Tip
Při nasazování se image Dockeru pro cílové výpočetní objekty sestavují a načítají ze služby Azure Container Registry (ACR). Azure Machine Learning ve výchozím nastavení vytvoří službu ACR, která používá úroveň služby Basic . Změna služby ACR pro váš pracovní prostor na úroveň Standard nebo Premium může zkrátit dobu potřebnou k sestavení a nasazení imagí do vašich cílových výpočetních prostředků. Další informace najdete v článku Úrovně služby Azure Container Registry.
Poznámka:
Pokud nasazujete model do služby Azure Kubernetes Service (AKS), doporučujeme pro příslušný cluster povolit Azure Monitor. Pomůže vám to pochopit celkový stav clusteru a využití prostředků. Užitečné by pro vás mohly být také následující zdroje informací:
- Kontrola událostí Resource Health, které ovlivňují cluster AKS
- Diagnostika služby Azure Kubernetes Service
Pokud se snažíte model nasadit do přetíženého clusteru nebo clusteru, který není v pořádku, očekává se, že dojde k problémům. Pokud potřebujete pomoc s řešením potíží s clusterem AKS, obraťte se na podporu AKS.
Odstranění prostředků
PLATÍ PRO: Rozšíření Azure CLI ml v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Pokud chcete odstranit nasazenou webovou službu, použijte az ml service delete <name of webservice>.
Pokud chcete odstranit zaregistrovaný model z pracovního prostoru, použijte az ml model delete <model id>
Přečtěte si další informace o odstranění webové služby a odstranění modelu.
Další kroky
- Řešení potíží s neúspěšným nasazením
- Aktualizace webové služby
- Jedno kliknutí nasazení pro automatizované strojové učení spuštěné v studio Azure Machine Learning
- Zabezpečení webové služby prostřednictvím služby Azure Machine Learning s využitím protokolu TLS
- Monitorování modelů Azure Machine Learning pomocí Application Insights
- Vytváření upozornění a triggerů událostí pro nasazení modelů