Nasazení modelu jako online koncového bodu
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Naučte se nasadit model do online koncového bodu pomocí sady Azure Machine Learning Python SDK v2.
V tomto kurzu nasadíte a použijete model, který předpovídá pravděpodobnost výchozího zákazníka při platbě platební kartou.
Kroky, které provedete, jsou:
- Registrace modelu
- Vytvoření koncového bodu a prvního nasazení
- Nasazení zkušebního spuštění
- Ruční odeslání testovacích dat do nasazení
- Získání podrobností o nasazení
- Vytvoření druhého nasazení
- Ruční škálování druhého nasazení
- Aktualizace přidělení produkčního provozu mezi oběma nasazeními
- Získání podrobností o druhém nasazení
- Zavedení nového nasazení a odstranění prvního nasazení
Toto video ukazuje, jak začít studio Azure Machine Learning, abyste mohli postupovat podle kroků v tomto kurzu. Video ukazuje, jak vytvořit poznámkový blok, vytvořit výpočetní instanci a naklonovat poznámkový blok. Kroky jsou popsané také v následujících částech.
Požadavky
-
Pokud chcete používat Azure Machine Learning, potřebujete pracovní prostor. Pokud ho nemáte, dokončete vytváření prostředků, které potřebujete, abyste mohli začít vytvářet pracovní prostor a získat další informace o jeho používání.
Důležité
Pokud je váš pracovní prostor Azure Machine Learning nakonfigurovaný se spravovanou virtuální sítí, možná budete muset přidat odchozí pravidla, která povolí přístup k veřejným úložištím balíčků Pythonu. Další informace najdete v tématu Scénář: Přístup k veřejným balíčkům strojového učení.
-
Přihlaste se do studia a vyberte pracovní prostor, pokud ještě není otevřený.
-
Otevřete nebo vytvořte poznámkový blok v pracovním prostoru:
- Pokud chcete zkopírovat a vložit kód do buněk, vytvořte nový poznámkový blok.
- Nebo otevřete kurzy/get-started-notebooks/deploy-model.ipynb v části Ukázky studia. Potom vyberte Clone (Klonovat ) a přidejte poznámkový blok do složky Soubory. Ukázkové poznámkové bloky najdete v tématu Výuka z ukázkových poznámkových bloků.
Prohlédněte si kvótu virtuálního počítače a ujistěte se, že máte k dispozici dostatečnou kvótu pro vytváření online nasazení. V tomto kurzu potřebujete alespoň 8 jader
STANDARD_DS3_v2a 12 jaderSTANDARD_F4s_v2. Pokud chcete zobrazit využití kvóty virtuálních počítačů a požádat o navýšení kvóty, přečtěte si téma Správa kvót prostředků.
Nastavení jádra a otevření v editoru Visual Studio Code (VS Code)
Na horním panelu nad otevřeným poznámkovým blokem vytvořte výpočetní instanci, pokud ji ještě nemáte.

Pokud je výpočetní instance zastavená, vyberte Spustit výpočetní prostředky a počkejte, až bude spuštěný.

Počkejte na spuštění výpočetní instance. Pak se ujistěte, že jádro, které se nachází v pravém horním rohu, je
Python 3.10 - SDK v2. Pokud ne, vyberte toto jádro pomocí rozevíracího seznamu.
Pokud toto jádro nevidíte, ověřte, že je vaše výpočetní instance spuštěná. Pokud ano, vyberte tlačítko Aktualizovat v pravém horním rohu poznámkového bloku.
Pokud se zobrazí banner s informací, že potřebujete být ověřeni, vyberte Ověřit.
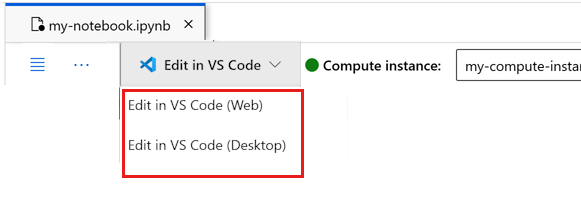
Poznámkový blok můžete spustit tady nebo ho otevřít ve VS Code pro úplné integrované vývojové prostředí (IDE) s využitím prostředků Azure Machine Learning. Vyberte Otevřít v editoru VS Code a pak vyberte možnost Web nebo Desktop. Při spuštění tímto způsobem se VS Code připojí k vaší výpočetní instanci, jádru a systému souborů pracovního prostoru.




Důležité
Zbytek tohoto kurzu obsahuje buňky poznámkového bloku kurzu. Pokud jste ho naklonovali, zkopírujte je a vložte do nového poznámkového bloku nebo ho teď přepněte do poznámkového bloku.
Poznámka:
- Bezserverové výpočetní prostředí Spark není
Python 3.10 - SDK v2ve výchozím nastavení nainstalované. Doporučujeme uživatelům vytvořit výpočetní instanci a vybrat ji před pokračováním v tomto kurzu.
Vytvoření popisovače do pracovního prostoru
Než se pustíte do kódu, potřebujete způsob, jak odkazovat na pracovní prostor. Vytvořte ml_client popisovač pracovního prostoru a použijte ho ml_client ke správě prostředků a úloh.
Do další buňky zadejte ID předplatného, název skupiny prostředků a název pracovního prostoru. Tyto hodnoty najdete takto:
- V pravém horním studio Azure Machine Learning panelu nástrojů vyberte název pracovního prostoru.
- Zkopírujte hodnotu pro pracovní prostor, skupinu prostředků a ID předplatného do kódu.
- Potřebujete zkopírovat jednu hodnotu, zavřít oblast a vložit a pak se vrátit k další hodnotě.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Poznámka:
Vytvoření MLClient se nepřipojí k pracovnímu prostoru. Inicializace klienta je opožděná a čeká na první volání (k tomu dojde v další buňce kódu).
Registrace modelu
Pokud jste už dokončili předchozí trénovací kurz, natrénujte model, zaregistrovali jste model MLflow jako součást trénovacího skriptu a můžete přeskočit na další část.
Pokud jste nedokončili trénovací kurz, musíte model zaregistrovat. Osvědčeným postupem je registrace modelu před nasazením.
Následující kód určuje vložený path kód (odkud se mají nahrát soubory). Pokud jste naklonovali složku tutorials, spusťte následující kód tak, jak je. V opačném případě stáhněte soubory a metadata modelu ze složky credit_defaults_model. Uložte soubory, které jste stáhli, do místní verze složky credit_defaults_model v počítači a aktualizujte cestu v následujícím kódu na umístění stažených souborů.
Sada SDK automaticky nahraje soubory a zaregistruje model.
Další informace o registraci modelu jako prostředku najdete v tématu Registrace modelu jako prostředku ve službě Machine Learning pomocí sady SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
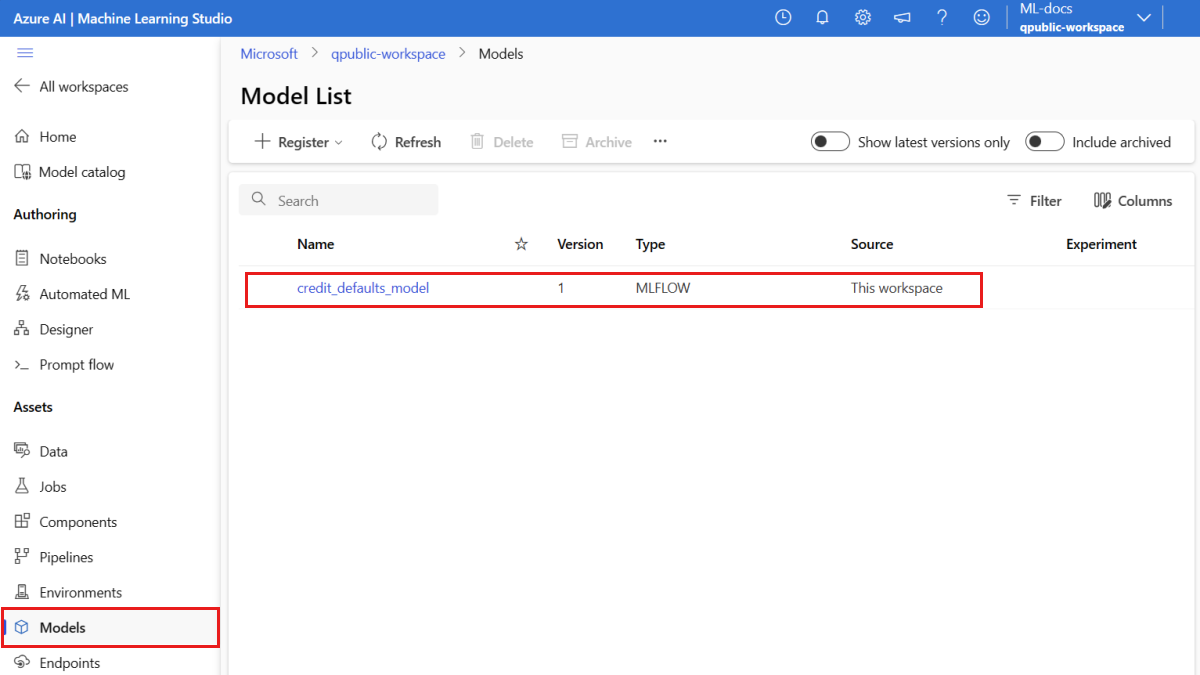
Ověřte, že je model zaregistrovaný.
Na stránce Modely v studio Azure Machine Learning můžete zkontrolovat nejnovější verzi registrovaného modelu.
Případně následující kód načte nejnovější číslo verze, které můžete použít.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Teď, když máte zaregistrovaný model, můžete vytvořit koncový bod a nasazení. Další část stručně popisuje některé klíčové podrobnosti o těchto tématech.
Koncové body a nasazení
Po vytrénování modelu strojového učení ho musíte nasadit, aby ho ostatní mohli použít k odvozování. Pro tento účel vám Azure Machine Learning umožňuje vytvářet koncové body a přidávat do nich nasazení.
Koncový bod v tomto kontextu je cesta HTTPS, která klientům poskytuje rozhraní pro odesílání požadavků (vstupních dat) do natrénovaného modelu a příjem výsledků odvozování (bodování) z modelu. Koncový bod poskytuje:
- Ověřování pomocí ověřování založeného na klíči nebo tokenu
- Ukončení protokolu TLS (SSL)
- Stabilní identifikátor URI bodování (endpoint-name.region.inference.ml.azure.com)
Nasazení je sada prostředků vyžadovaných pro hostování modelu, který provádí skutečné odvozování.
Jeden koncový bod může obsahovat více nasazení. Koncové body a nasazení jsou nezávislé prostředky Azure Resource Manageru, které se zobrazují na webu Azure Portal.
Azure Machine Learning umožňuje implementovat online koncové body pro odvozování dat v reálném čase a dávkové koncové body pro odvozování velkých objemů dat v určitém časovém období.
V tomto kurzu si projdete kroky implementace spravovaného online koncového bodu. Spravované online koncové body pracují s výkonnými procesory a počítači GPU v Azure škálovatelným a plně spravovaným způsobem, který vám uvolní režii při nastavování a správě základní infrastruktury nasazení.
Vytvoření online koncového bodu
Teď, když máte zaregistrovaný model, je čas vytvořit online koncový bod. Název koncového bodu musí být jedinečný v celé oblasti Azure. Pro účely tohoto kurzu vytvoříte jedinečný název pomocí univerzálního jedinečného identifikátoru UUID. Další informace o pravidlech pojmenování koncových bodů najdete v tématu Omezení koncových bodů.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Nejprve definujte koncový bod pomocí ManagedOnlineEndpoint třídy.
Tip
auth_mode: Sloužíkeyk ověřování na základě klíčů. Používá seaml_tokenpro ověřování na základě tokenů služby Azure Machine Learning. PlatnostkeyA nevyprší, aleaml_tokenvyprší. Další informace o ověřování najdete v tématu Ověřování klientů pro online koncové body.Volitelně můžete do koncového bodu přidat popis a značky.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Pomocí dříve vytvořeného MLClient koncového bodu vytvořte v pracovním prostoru. Tento příkaz spustí vytvoření koncového bodu a během vytváření koncového bodu vrátí potvrzovací odpověď.
Poznámka:
Počítejte s tím, že vytvoření koncového bodu bude trvat přibližně 2 minuty.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Po vytvoření koncového bodu ho můžete načíst následujícím způsobem:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Principy online nasazení
Mezi klíčové aspekty nasazení patří:
-
name– Název nasazení. -
endpoint_name– Název koncového bodu, který bude obsahovat nasazení. -
model– Model, který se má použít pro nasazení. Tato hodnota může být odkazem na existující model verze v pracovním prostoru nebo specifikace vloženého modelu. -
environment– Prostředí, které se má použít pro nasazení (nebo pro spuštění modelu). Tato hodnota může být odkazem na existující prostředí s verzí v pracovním prostoru nebo specifikaci vloženého prostředí. Prostředí může být image Dockeru se závislostmi Conda nebo souborem Dockerfile. -
code_configuration– konfigurace zdrojového kódu a bodovacího skriptu.-
path- Cesta k adresáři zdrojového kódu pro bodování modelu. -
scoring_script- Relativní cesta k souboru bodování v adresáři zdrojového kódu. Tento skript spustí model na daném vstupním požadavku. Příklad bodovacího skriptu najdete v článku Nasazení modelu ML s online koncovým bodem v tématu Vysvětlení hodnoticího skriptu .
-
-
instance_type– Velikost virtuálního počítače, která se má použít pro nasazení. Seznam podporovaných velikostí najdete v seznamu skladových položek spravovaných online koncových bodů. -
instance_count– Počet instancí, které se mají použít pro nasazení.
Nasazení pomocí modelu MLflow
Azure Machine Learning podporuje nasazení modelu vytvořeného a protokolovaného pomocí MLflow bez kódu. To znamená, že během nasazování modelu nemusíte poskytovat bodovací skript ani prostředí, protože při trénování modelu MLflow se skript bodování a prostředí automaticky vygenerují. Pokud jste ale používali vlastní model, museli byste během nasazování zadat prostředí a bodovací skript.
Důležité
Pokud obvykle nasazujete modely pomocí hodnoticích skriptů a vlastních prostředí a chcete dosáhnout stejné funkce pomocí modelů MLflow, doporučujeme přečíst si pokyny pro nasazení modelů MLflow.
Nasazení modelu do koncového bodu
Začněte vytvořením jednoho nasazení, které zpracovává 100 % příchozího provozu. Zvolte libovolný název barvy (modrý) pro nasazení. K vytvoření nasazení pro koncový bod použijte ManagedOnlineDeployment třídu.
Poznámka:
Není nutné zadávat prostředí ani bodovací skript, protože model, který se má nasadit, je model MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Pomocí dříve vytvořeného MLClient prostředí teď vytvořte nasazení v pracovním prostoru. Tento příkaz spustí vytvoření nasazení a během vytváření nasazení vrátí potvrzovací odpověď.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Kontrola stavu koncového bodu
Můžete zkontrolovat stav koncového bodu a zjistit, jestli se model nasadil bez chyby:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testování koncového bodu s ukázkovými daty
Teď, když je model nasazený do koncového bodu, můžete s ním spustit odvozování. Začněte vytvořením ukázkového souboru požadavku, který následuje po návrhu očekávaném v metodě spuštění nalezené ve skriptu bodování.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Teď vytvořte soubor v adresáři nasazení. Následující buňka kódu používá magii IPython k zápisu souboru do adresáře, který jste právě vytvořili.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Pomocí dříve vytvořeného MLClient popisovače přejděte ke koncovému bodu. Koncový bod můžete vyvolat pomocí invoke příkazu s následujícími parametry:
-
endpoint_name– Název koncového bodu -
request_file- Soubor s daty žádosti -
deployment_name– Název konkrétního nasazení pro testování v koncovém bodu
Otestujte modré nasazení s ukázkovými daty.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Získání protokolů nasazení
V protokolech zkontrolujte, jestli se koncový bod nebo nasazení úspěšně vyvolaly. Pokud dojde k chybám, přečtěte si téma Řešení potíží s nasazením online koncových bodů.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Vytvoření druhého nasazení
Nasaďte model jako druhé nasazení s názvem green. V praxi můžete vytvořit několik nasazení a porovnat jejich výkon. Tato nasazení můžou používat jinou verzi stejného modelu, jiný model nebo výkonnější výpočetní instanci.
V tomto příkladu nasadíte stejnou verzi modelu pomocí výkonnější výpočetní instance, která by mohla potenciálně zlepšit výkon.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Škálování nasazení pro zpracování většího provozu
Pomocí dříve vytvořeného MLClient nástroje můžete získat popisovač nasazení green . Pak ho můžete škálovat zvýšením nebo snížením instance_count.
V následujícím kódu zvýšíte instanci virtuálního počítače ručně. Je ale také možné automaticky škálovat online koncové body. Automatické škálování automaticky spustí správné množství prostředků ke zvládnutí zatížení u vaší aplikace. Spravované online koncové body podporují automatické škálování prostřednictvím integrace s funkcí automatického škálování služby Azure Monitor. Informace o konfiguraci automatického škálování najdete v tématu Automatické škálování online koncových bodů.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Aktualizace přidělení provozu pro nasazení
Produkční provoz můžete rozdělit mezi nasazení. Nasazení můžete nejprve otestovat green s ukázkovými daty, stejně jako jste to udělali blue pro nasazení. Po otestování zeleného nasazení přidělte malé procento provozu.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Test přidělení provozu vyvoláním koncového bodu několikrát:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Zobrazte protokoly z green nasazení a zkontrolujte, že došlo k příchozím požadavkům a že se model úspěšně ohodnotil.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Zobrazení metrik pomocí služby Azure Monitor
Různé metriky (čísla požadavků, latence požadavků, bajty sítě, využití procesoru, GPU, disku nebo paměti a další) pro online koncový bod a jeho nasazení můžete zobrazit pomocí odkazů na stránce podrobností koncového bodu v sadě Studio. Po každém z těchto odkazů přejdete na přesnou stránku metrik na webu Azure Portal pro koncový bod nebo nasazení.

Pokud otevřete metriky pro online koncový bod, můžete stránku nastavit tak, aby zobrazovala metriky, jako je průměrná latence požadavku, jak je znázorněno na následujícím obrázku.

Další informace o tom, jak zobrazit metriky online koncových bodů, najdete v tématu Monitorování online koncových bodů.
Odeslání veškerého provozu do nového nasazení
Jakmile budete plně spokojeni s nasazením green , přepněte do něj veškerý provoz.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Odstranění starého nasazení
Odeberte staré (modré) nasazení:
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Vyčištění prostředků
Pokud po dokončení tohoto kurzu nepoužíváte koncový bod a nasazení, měli byste je odstranit.
Poznámka:
Očekáváme, že úplné odstranění bude trvat přibližně 20 minut.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Odstranit vše
Pomocí těchto kroků odstraňte pracovní prostor Služby Azure Machine Learning a všechny výpočetní prostředky.
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Na webu Azure Portal do vyhledávacího pole zadejte skupiny prostředků a vyberte je z výsledků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Na stránce Přehled vyberte Odstranit skupinu prostředků.
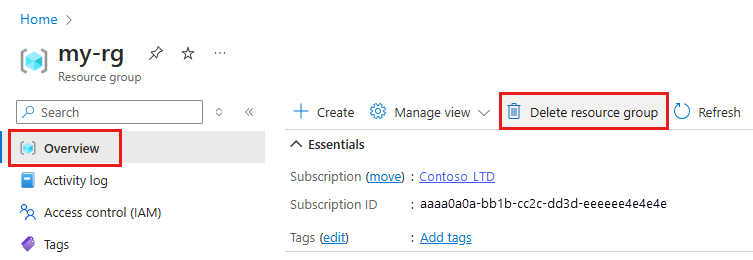
Zadejte název skupiny prostředků. Poté vyberte Odstranit.