Kurz: Trénování modelu ve službě Azure Machine Learning
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Zjistěte, jak datový vědec používá Azure Machine Learning k trénování modelu. V tomto příkladu použijete datovou sadu platební karty, abyste pochopili, jak použít Azure Machine Learning pro klasifikační problém. Cílem je předpovědět, jestli má zákazník vysokou pravděpodobnost výchozí platby platební kartou. Trénovací skript zpracovává přípravu dat. Skript pak trénuje a zaregistruje model.
Tento kurz vás provede postupem odeslání cloudové úlohy trénování (úloha příkazu).
- Získání popisovače pracovního prostoru Služby Azure Machine Learning
- Vytvoření výpočetního prostředku a prostředí úloh
- Vytvoření trénovacího skriptu
- Vytvoření a spuštění úlohy příkazu pro spuštění trénovacího skriptu na výpočetním prostředku
- Zobrazení výstupu trénovacího skriptu
- Nasazení nově natrénovaného modelu jako koncového bodu
- Volání koncového bodu služby Azure Machine Learning pro odvozování
Pokud se chcete dozvědět více o tom, jak načíst data do Azure, přečtěte si kurz : Nahrání, přístup a prozkoumání dat ve službě Azure Machine Learning.
Toto video ukazuje, jak začít studio Azure Machine Learning, abyste mohli postupovat podle kroků v tomto kurzu. Video ukazuje, jak vytvořit poznámkový blok, vytvořit výpočetní instanci a naklonovat poznámkový blok. Kroky jsou popsané také v následujících částech.
Požadavky
-
Pokud chcete používat Azure Machine Learning, potřebujete pracovní prostor. Pokud ho nemáte, dokončete vytváření prostředků, které potřebujete, abyste mohli začít vytvářet pracovní prostor a získat další informace o jeho používání.
Důležité
Pokud je váš pracovní prostor Azure Machine Learning nakonfigurovaný se spravovanou virtuální sítí, možná budete muset přidat odchozí pravidla, která povolí přístup k veřejným úložištím balíčků Pythonu. Další informace najdete v tématu Scénář: Přístup k veřejným balíčkům strojového učení.
-
Přihlaste se do studia a vyberte pracovní prostor, pokud ještě není otevřený.
-
Otevřete nebo vytvořte poznámkový blok v pracovním prostoru:
- Pokud chcete zkopírovat a vložit kód do buněk, vytvořte nový poznámkový blok.
- Nebo otevřete kurzy/get-started-notebooks/train-model.ipynb z části Ukázky studia. Potom vyberte Clone (Klonovat ) a přidejte poznámkový blok do složky Soubory. Ukázkové poznámkové bloky najdete v tématu Výuka z ukázkových poznámkových bloků.
Nastavení jádra a otevření v editoru Visual Studio Code (VS Code)
Na horním panelu nad otevřeným poznámkovým blokem vytvořte výpočetní instanci, pokud ji ještě nemáte.

Pokud je výpočetní instance zastavená, vyberte Spustit výpočetní prostředky a počkejte, až bude spuštěný.

Počkejte na spuštění výpočetní instance. Pak se ujistěte, že jádro, které se nachází v pravém horním rohu, je
Python 3.10 - SDK v2. Pokud ne, vyberte toto jádro pomocí rozevíracího seznamu.
Pokud toto jádro nevidíte, ověřte, že je vaše výpočetní instance spuštěná. Pokud ano, vyberte tlačítko Aktualizovat v pravém horním rohu poznámkového bloku.
Pokud se zobrazí banner s informací, že potřebujete být ověřeni, vyberte Ověřit.
Poznámkový blok můžete spustit tady nebo ho otevřít ve VS Code pro úplné integrované vývojové prostředí (IDE) s využitím prostředků Azure Machine Learning. Vyberte Otevřít v editoru VS Code a pak vyberte možnost Web nebo Desktop. Při spuštění tímto způsobem se VS Code připojí k vaší výpočetní instanci, jádru a systému souborů pracovního prostoru.




Důležité
Zbytek tohoto kurzu obsahuje buňky poznámkového bloku kurzu. Pokud jste ho naklonovali, zkopírujte je a vložte do nového poznámkového bloku nebo ho teď přepněte do poznámkového bloku.
Použití úlohy příkazu k trénování modelu ve službě Azure Machine Learning
Pokud chcete vytrénovat model, musíte odeslat úlohu. Azure Machine Learning nabízí několik různých typů úloh pro trénování modelů. Uživatelé si můžou vybrat metodu trénování na základě složitosti modelu, velikosti dat a požadavků na rychlost trénování. V tomto kurzu se dozvíte, jak odeslat úlohu příkazu pro spuštění trénovacího skriptu.
Úloha příkazu je funkce, která umožňuje odeslat vlastní trénovací skript pro trénování modelu. Tuto úlohu lze také definovat jako vlastní trénovací úlohu. Úloha příkazu ve službě Azure Machine Learning je typ úlohy, která spouští skript nebo příkaz v zadaném prostředí. Pomocí úloh příkazů můžete trénovat modely, zpracovávat data nebo jakýkoli jiný vlastní kód, který chcete spustit v cloudu.
Tento kurz se zaměřuje na použití úlohy příkazu k vytvoření vlastní trénovací úlohy, kterou používáte k trénování modelu. Každá vlastní trénovací úloha vyžaduje následující položky:
- prostředí
- data
- příkazová úloha
- trénovací skript
Tento kurz poskytuje tyto položky pro příklad: vytvoření klasifikátoru pro predikci zákazníků, kteří mají vysokou pravděpodobnost výchozího nastavení plateb platební kartou.
Vytvoření popisovače do pracovního prostoru
Než se pustíte do kódu, potřebujete způsob, jak odkazovat na pracovní prostor. Vytvořte ml_client popisovač pracovního prostoru. Pak se používá ml_client ke správě prostředků a úloh.
Do další buňky zadejte ID předplatného, název skupiny prostředků a název pracovního prostoru. Tyto hodnoty najdete takto:
- V pravém horním studio Azure Machine Learning panelu nástrojů vyberte název pracovního prostoru.
- Zkopírujte hodnotu pro pracovní prostor, skupinu prostředků a ID předplatného do kódu. Potřebujete zkopírovat jednu hodnotu, zavřít oblast a vložit a pak se vrátit k další hodnotě.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Poznámka:
Vytvoření MLClient se nepřipojí k pracovnímu prostoru. Inicializace klienta je opožděná. Čeká na první volání, ke kterému dojde v další buňce kódu.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Vytvoření prostředí úlohy
Ke spuštění úlohy Azure Machine Learning na výpočetním prostředku potřebujete prostředí. Prostředí obsahuje seznam softwarových modulů runtime a knihoven, které chcete nainstalovat do výpočetních prostředků, ve kterých se trénování provede. Je to podobné prostředí Pythonu na místním počítači. Další informace najdete v tématu Co jsou prostředí Azure Machine Learning?
Azure Machine Learning poskytuje mnoho kurátorovaných nebo připravených prostředí, která jsou užitečná pro běžné scénáře trénování a odvozování.
V tomto příkladu vytvoříte vlastní prostředí Conda pro vaše úlohy pomocí souboru conda yaml.
Nejprve vytvořte adresář pro uložení souboru.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Další buňka používá magii IPython k zápisu souboru conda do vytvořeného adresáře.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
Specifikace obsahuje některé obvyklé balíčky, které používáte ve své úloze, například numpy a pip.
Na tento soubor yaml se můžete odkazovat a vytvořit a zaregistrovat toto vlastní prostředí ve vašem pracovním prostoru:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Konfigurace trénovací úlohy pomocí funkce příkazu
Vytvoříte úlohu příkazu Azure Machine Learning pro trénování modelu pro výchozí predikci kreditu. Úloha příkazu spustí trénovací skript v zadaném prostředí pro zadaný výpočetní prostředek. Prostředí a výpočetní cluster jste už vytvořili. Dále vytvořte trénovací skript. V tomto případě trénujete datovou sadu tak, abyste pomocí modelu vytvořili klasifikátor GradientBoostingClassifier .
Trénovací skript zpracovává přípravu, trénování a registraci trénovaného modelu. Metoda train_test_split rozdělí datovou sadu na testovací a trénovací data. V tomto kurzu vytvoříte trénovací skript Pythonu.
Úlohy příkazů je možné spouštět z rozhraní příkazového řádku, sady Python SDK nebo studia. V tomto kurzu pomocí sady Azure Machine Learning Python SDK v2 vytvořte a spusťte úlohu příkazu.
Vytvoření trénovacího skriptu
Začněte vytvořením trénovacího skriptu: main.py souboru pythonu. Nejprve vytvořte zdrojovou složku pro skript:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Tento skript předzpracuje data a rozdělí je na testovací a trénovací data. Potom data spotřebuje k trénování modelu založeného na stromové struktuře a vrácení výstupního modelu.
MLFlow se používá k protokolování parametrů a metrik během této úlohy. Balíček MLFlow umožňuje sledovat metriky a výsledky pro každý model, který Azure trénuje. Použijte MLFlow k získání nejlepšího modelu pro vaše data. Pak si prohlédněte metriky modelu v nástroji Azure Studio. Další informace najdete v tématu MLflow a Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
V tomto skriptu se po vytrénování modelu soubor modelu uloží a zaregistruje do pracovního prostoru. Registrace modelu umožňuje ukládat a vytvářet verze modelů v cloudu Azure ve vašem pracovním prostoru. Po registraci modelu najdete všechny ostatní zaregistrované modely na jednom místě v Nástroji Azure Studio označované jako registr modelů. Registr modelů vám pomůže organizovat a sledovat trénované modely.
Konfigurace příkazu
Teď, když máte skript, který může provádět úlohu klasifikace, použijte příkaz pro obecné účely, který může spouštět akce příkazového řádku. Tato akce příkazového řádku může být přímo voláním systémových příkazů nebo spuštěním skriptu.
Vytvořte vstupní proměnné pro zadání vstupních dat, poměru rozdělení, rychlosti učení a názvu registrovaného modelu. Skript příkazu:
- Používá prostředí vytvořené dříve.
@latestZápis použijte k označení nejnovější verze prostředí při spuštění příkazu. - Nakonfiguruje samotnou akci příkazového řádku.
python main.pyVstupy a výstupy v příkazu můžete získat pomocí${{ ... }}zápisu. - Vzhledem k tomu, že nebyl zadán výpočetní prostředek, skript se spustí na bezserverovém výpočetním clusteru , který se automaticky vytvoří.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Odeslání úlohy
Odešlete úlohu, která se má spustit v studio Azure Machine Learning. Tentokrát použijte create_or_update na ml_client.
ml_client je klientská třída, která umožňuje připojit se k předplatnému Azure pomocí Pythonu a pracovat se službami Azure Machine Learning.
ml_client umožňuje odesílat úlohy pomocí Pythonu.
ml_client.create_or_update(job)
Zobrazení výstupu úlohy a čekání na dokončení úlohy
Pokud chcete zobrazit úlohu v studio Azure Machine Learning, vyberte odkaz ve výstupu předchozí buňky. Výstup této úlohy vypadá v studio Azure Machine Learning takto. Prozkoumejte karty pro různé podrobnosti, jako jsou metriky, výstupy atd. Po dokončení úlohy zaregistruje v pracovním prostoru model v důsledku trénování.
Důležité
Než se vrátíte do tohoto poznámkového bloku, počkejte na dokončení stavu úlohy. Spuštění úlohy trvá 2 až 3 minuty. Pokud se výpočetní cluster škáloval na nula uzlů a vlastní prostředí stále vytváří, může to trvat až 10 minut.
Po spuštění buňky se ve výstupu poznámkového bloku zobrazí odkaz na stránku podrobností úlohy v nástroji Machine Learning Studio. Alternativně můžete také vybrat Úlohy v levé navigační nabídce.
Úloha je seskupení mnoha spuštění ze zadaného skriptu nebo části kódu. Informace o spuštění jsou uloženy v rámci této úlohy. Stránka s podrobnostmi poskytuje přehled úlohy, čas, který trvalo jeho spuštění, kdy byla vytvořena, a další informace. Stránka obsahuje také karty s dalšími informacemi o úloze, jako jsou metriky, výstupy a protokoly a kód. Tady jsou karty, které jsou k dispozici na stránce podrobností úlohy:
- Přehled: Základní informace o úloze, včetně jejího stavu, časů zahájení a ukončení a typu spuštěné úlohy
- Vstupy: Data a kód, které byly použity jako vstupy pro úlohu. Tato část může zahrnovat datové sady, skripty, konfigurace prostředí a další prostředky, které byly použity během trénování.
- Výstupy + protokoly: Protokoly vygenerované během spuštění úlohy. Tato karta vám pomůže s řešením potíží, pokud se s trénovacím skriptem nebo vytvořením modelu něco nepovede.
- Metriky: Klíčové metriky výkonu z modelu, jako je trénovací skóre, skóre f1 a skóre přesnosti.
Vyčištění prostředků
Pokud chcete pokračovat v dalších kurzech, přejděte na související obsah.
Zastavení výpočetní instance
Pokud ji teď nebudete používat, zastavte výpočetní instanci:
- V sadě Studio v levé navigační oblasti vyberte Compute.
- Na horních kartách vyberte Výpočetní instance.
- V seznamu vyberte výpočetní instanci.
- Na horním panelu nástrojů vyberte Zastavit.
Odstranění všech prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Na webu Azure Portal do vyhledávacího pole zadejte skupiny prostředků a vyberte je z výsledků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Na stránce Přehled vyberte Odstranit skupinu prostředků.
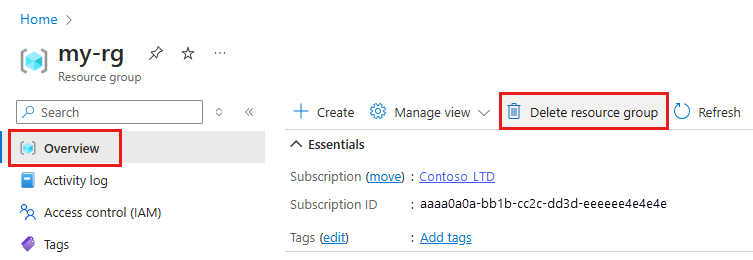
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Související obsah
Další informace o nasazení modelu:
V tomto kurzu jste použili online datový soubor. Další informace o dalších způsobech přístupu k datům najdete v kurzu Nahrání, přístup a prozkoumání dat ve službě Azure Machine Learning.
Automatizované strojové učení je doplňkový nástroj, který zkracuje dobu, po kterou datový vědec stráví hledáním modelu, který nejlépe vyhovuje jejich datům. Další informace najdete v tématu Co je automatizované strojové učení.
Pokud byste chtěli další příklady podobné tomuto kurzu, přečtěte si téma Learn from sample notebooks. Tyto ukázky jsou k dispozici na stránce s příklady GitHubu. Příklady zahrnují kompletní poznámkové bloky Pythonu, které můžete spouštět kód a učit se trénovat model. Můžete upravit a spustit existující skripty z ukázek, které obsahují scénáře včetně klasifikace, zpracování přirozeného jazyka a detekce anomálií.