Vector Storage ve službě Azure AI Search
Azure AI Search poskytuje vektorové úložiště a konfigurace pro vektorové vyhledávání a hybridní vyhledávání. Podpora je implementována na úrovni pole, což znamená, že můžete kombinovat vektorová a nevectorová pole ve stejném vyhledávacím korpusu.
Vektory jsou uloženy v indexu vyhledávání. K vytvoření úložiště vektorů použijte rozhraní REST API pro vytvoření indexu nebo ekvivalentní metodu sady Azure SDK.
Mezi důležité informace o vektorovém úložišti patří následující body:
- Navrhněte schéma tak, aby vyhovovalo vašemu případu použití na základě zamýšleného vzoru načítání vektorů.
- Odhad velikosti indexu a kontrola kapacity vyhledávací služby
- Správa úložiště vektorů
- Zabezpečení úložiště vektorů
Vzory načítání vektorů
Ve službě Azure AI Search existují dva vzory pro práci s výsledky hledání.
Generování vyhledávání Jazykové modely formuluje odpověď na dotaz uživatele pomocí dat z Azure AI Search. Tento vzor zahrnuje vrstvu orchestrace, která koordinuje výzvy a udržuje kontext. V tomto vzoru se výsledky hledání předávají do toků výzvy, které přijímají modely chatu, jako jsou GPT a Text-Davinci. Tento přístup je založený na architektuře RAG (Retrieval Augmented Generation), kde index vyhledávání poskytuje základní data.
Klasické vyhledávání pomocí vyhledávacího panelu, vstupního řetězce dotazu a vykreslených výsledků Vyhledávací web přijímá a spouští vektorový dotaz, formuluje odpověď a výsledky vykreslíte v klientské aplikaci. Ve službě Azure AI Search se výsledky vrátí v sadě plochých řádků a můžete zvolit pole, která mají obsahovat výsledky hledání. Vzhledem k tomu, že neexistuje žádný chatovací model, očekává se, že byste v odpovědi naplnili vektorové úložiště (index vyhledávání) nevectorovým obsahem, který je čitelný člověkem. I když se vyhledávací web shoduje s vektory, měli byste k naplnění výsledků hledání použít nevectorové hodnoty. Vektorové dotazy a hybridní dotazy pokrývají typy požadavků dotazů, které můžete formulovat pro klasické scénáře hledání.
Schéma indexu by mělo odrážet váš primární případ použití. Následující část popisuje rozdíly ve složení polí pro řešení vytvořená pro generování umělé inteligence nebo klasické vyhledávání.
Schéma úložiště vektorů
Schéma indexu pro úložiště vektorů vyžaduje název, pole klíče (řetězec), jedno nebo více vektorových polí a konfiguraci vektoru. Pole nevectoru se doporučují pro hybridní dotazy nebo pro vrácení doslovného doslovného obsahu, který nemusí procházet jazykovým modelem. Pokyny ke konfiguraci vektorů najdete v tématu Vytvoření vektorového úložiště.
Základní konfigurace vektorových polí
Vektorová pole se rozlišují podle jejich datového typu a vlastností specifických pro vektory. Vektorové pole vypadá v kolekci polí takto:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Vektorová pole mají konkrétní datové typy. V současné době je nejběžnější, Collection(Edm.Single) ale použití úzkých datových typů může ušetřit v úložišti.
Vektorová pole musí být prohledávatelná a načístelná, ale nemůžou být filtrovatelná, fasetová nebo řazená nebo mají analyzátory, normalizátory nebo přiřazení mapování synonym.
Vektorová pole musí být dimensions nastavena na počet vložených objektů vygenerovaných modelem vkládání. Například text-embedding-ada-002 generuje 1 536 vkládání pro každý blok textu.
Vektorová pole se indexují pomocí algoritmů označených profilem vektorového vyhledávání, který je definován jinde v indexu, a proto se v příkladu nezobrazuje. Další informace najdete v tématu Konfigurace vektorové vyhledávání.
Kolekce polí pro úlohy se základními vektory
Úložiště vektorů vyžadují další pole kromě vektorových polí. Pole klíče ("id" v tomto příkladu) je například požadavek indexu.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Další pole, například "content" pole, poskytují čitelný ekvivalent pole pro člověka "content_vector" . Pokud používáte jazykové modely výhradně pro formulaci odpovědí, můžete vynechat pole obsahu jiného typu nežvector, ale řešení, která odsílala výsledky hledání přímo do klientských aplikací, by měla obsahovat obsah nevectoru.
Pole metadat jsou užitečná pro filtry, zejména pokud metadata obsahují informace o zdroji zdrojového dokumentu. Vektorové pole nemůžete filtrovat přímo, ale můžete nastavit režimy prefilteru nebo postfilteru tak, aby filtrovali před nebo po spuštění vektorového dotazu.
Schéma generované průvodcem importem a vektorizací dat
Doporučujeme průvodce importem a vektorizací dat pro testování a testování konceptu. Průvodce vygeneruje ukázkové schéma v této části.
Předsudky tohoto schématu jsou založené na blocích dat. Pokud jazykový model formuluje odpověď, jak je typické pro aplikace RAG, chcete schéma navržené kolem bloků dat.
Vytváření bloků dat je nezbytné pro zachování vstupních limitů jazykových modelů, ale také zlepšuje přesnost vyhledávání podobnosti, když se dotazy dají spárovat s menšími bloky obsahu načítaným z více nadřazených dokumentů. A konečně, pokud používáte sémantický ranker, má sémantický ranker také limity tokenů, které jsou snadněji splněné, pokud je blok dat součástí vašeho přístupu.
V následujícím příkladu je pro každý hledaný dokument k dispozici jedno ID bloku, blok dat, název a vektorové pole. Id bloku dat a nadřazené ID se vyplní průvodcem pomocí kódování základního 64 metadat objektů blob (cesta). Blok dat a název se odvozují z obsahu objektu blob a názvu objektu blob. Vygeneruje se pouze vektorové pole. Jedná se o vektorizovanou verzi pole bloku. Vkládání se generuje voláním modelu vkládání Azure OpenAI, který zadáte.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schéma pro rag a aplikace ve stylu chatu
Pokud navrhujete úložiště pro generování hledání, můžete vytvořit samostatné indexy pro statický obsah, který jste indexovali a vektorizovali, a druhý index pro konverzace, které se dají použít v tocích výzvy. Následující indexy se vytvoří z akcelerátoru akcelerátoru řešení-data-data. >
Pole z indexu chatu, která podporují možnosti generování vyhledávání:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Pole z indexu konverzací, která podporují orchestraci a historii chatu:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
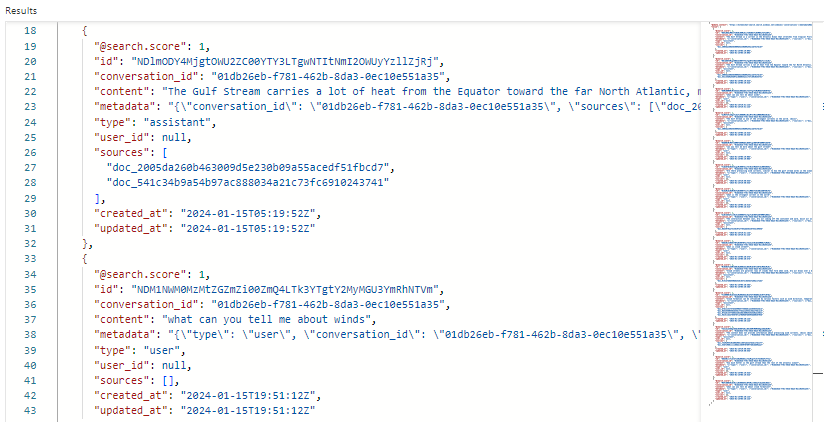
Tady je snímek obrazovky zobrazující výsledky hledání v Průzkumníku služby Search pro index konverzací. Skóre hledání je 1,00, protože hledání bylo nekvalifikované. Všimněte si polí, která existují pro podporu orchestrace a toků výzvy. ID konverzace identifikuje konkrétní chat. "type" určuje, zda je obsah od uživatele nebo asistenta. Kalendářní data se používají k oddálit chatům z historie.
Fyzická struktura a velikost
Ve službě Azure AI Search je fyzická struktura indexu z velké části interní implementací. Ke svému schématu, načtení a dotazování na jeho obsah můžete přistupovat, monitorovat jeho velikost a spravovat kapacitu, ale samotné clustery (invertované a vektorové indexy) a další soubory a složky spravuje Microsoft interně.
Velikost a látka indexu jsou určeny takto:
- Množství a složení dokumentů
- Atributy pro jednotlivá pole Například pro filtrovatelná pole je vyžadováno více úložiště.
- Konfigurace indexu, včetně konfigurace vektoru, která určuje způsob vytváření interních navigačních struktur na základě toho, jestli zvolíte HNSW nebo vyčerpávající KNN pro vyhledávání podobnosti.
Azure AI Search omezuje úložiště vektorů, což pomáhá udržovat vyvážený a stabilní systém pro všechny úlohy. Abychom vám pomohli zůstat pod limity, využití vektorů se sleduje a hlásí samostatně na webu Azure Portal a programově prostřednictvím statistik služby a indexu.
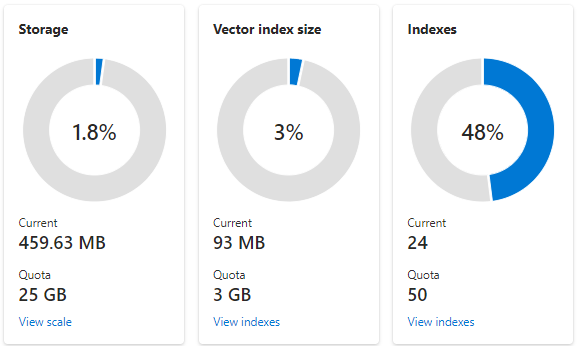
Následující snímek obrazovky ukazuje službu S1 nakonfigurovanou s jedním oddílem a jednou replikou. Tato konkrétní služba má v průměru 24 malých indexů s jedním vektorovým polem, přičemž každé pole se skládá z 1536 vkládání. Druhá dlaždice zobrazuje kvótu a využití vektorových indexů. Vektorový index je interní datová struktura vytvořená pro každé vektorové pole. Úložiště pro vektorové indexy je proto vždy zlomkem úložiště, které index celkově používá. Ostatní nevectorová pole a datové struktury spotřebovávají zbytek.
Omezení a odhady vektorového indexu jsou popsány v jiném článku, ale dva body, které je potřeba zdůraznit předem, je to, že maximální úložiště se liší podle úrovně služby a také podle toho, kdy byla vyhledávací služba vytvořena. Novější služby stejné vrstvy mají výrazně větší kapacitu pro indexy vektorů. Z těchto důvodů proveďte následující akce:
Zkontrolujte datum nasazení vyhledávací služby. Pokud byla vytvořena před 3. dubnem 2024, zvažte vytvoření nové vyhledávací služby pro větší kapacitu.
Pokud očekáváte kolísání požadavků na vektorové úložiště, zvolte škálovatelnou úroveň . Úroveň Basic je pevná na jednom oddílu ve starších vyhledávacích službách. Zvažte standard 1 (S1) a vyšší, abyste měli větší flexibilitu a rychlejší výkon, nebo vytvořte novou vyhledávací službu, která používá vyšší limity a více oddílů na každé úrovni.
Základní operace a interakce
Tato část představuje operace doby spuštění vektoru, včetně připojení a zabezpečení jednoho indexu.
Poznámka:
Při správě indexu mějte na paměti, že neexistuje žádná podpora portálu nebo rozhraní API pro přesun nebo kopírování indexu. Místo toho zákazníci obvykle nasměrují řešení nasazení aplikace na jinou vyhledávací službu (pokud používá stejný název indexu) nebo název revidují tak, aby vytvořili kopii v aktuální vyhledávací službě, a pak ji sestavili.
Nepřetržitě dostupný
Index je okamžitě k dispozici pro dotazy hned po indexování prvního dokumentu, ale nebude plně funkční, dokud nebudou indexovány všechny dokumenty. Interně se index distribuuje mezi oddíly a spouští se na replikách. Fyzický index se spravuje interně. Logický index spravujete vy.
Index je nepřetržitě dostupný a není možné ho pozastavit nebo převést do offline režimu. Vzhledem k tomu, že je určená pro průběžné operace, probíhají všechny aktualizace obsahu nebo přidání samotného indexu v reálném čase. V důsledku toho můžou dotazy dočasně vrátit neúplné výsledky, pokud se požadavek shoduje s aktualizací dokumentu.
Všimněte si, že kontinuita dotazů existuje pro operace dokumentů (aktualizace nebo odstranění) a pro úpravy, které neovlivňují stávající strukturu a integritu aktuálního indexu (například přidání nových polí). Pokud potřebujete provést strukturální aktualizace (změna existujících polí), ty se obvykle spravují pomocí pracovního postupu vyřazení a opětovného sestavení ve vývojovém prostředí nebo vytvořením nové verze indexu v produkční službě.
Aby se zabránilo opětovnému sestavení indexu, někteří zákazníci, kteří provádějí malé změny, zvolí pole "verze" vytvořením nového, který společně s předchozí verzí existuje. V průběhu času to vede k osamocenému obsahu ve formě zastaralých polí nebo zastaralých definic vlastních analyzátorů, zejména v produkčním indexu, který je nákladný k replikaci. Tyto problémy můžete vyřešit u plánovaných aktualizací indexu v rámci správy životního cyklu indexu.
Připojení koncového bodu
Všechny vektorové indexování a požadavky dotazu cílí na index. Koncové body jsou obvykle jedním z následujících způsobů:
| Koncový bod | Připojení a řízení přístupu |
|---|---|
<your-service>.search.windows.net/indexes |
Cílí na kolekci indexů. Používá se při vytváření, výpisu nebo odstraňování indexu. Pro tyto operace jsou vyžadována práva správce, která jsou k dispozici prostřednictvím klíčů rozhraní API správce nebo role Přispěvatel vyhledávání. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Cílí na kolekci dokumentů jednoho indexu. Používá se při dotazování indexu nebo aktualizace dat. Pro dotazy jsou dostatečná práva ke čtení a jsou k dispozici prostřednictvím klíčů rozhraní API pro dotazy nebo role čtenáře dat. Pro aktualizaci dat jsou vyžadována práva správce. |
Jak se připojit ke službě Azure AI Search
Ujistěte se, že máte oprávnění nebo přístupový klíč rozhraní API. Pokud se dotazujete na existující index, potřebujete oprávnění správce nebo přiřazení role přispěvatele ke správě a zobrazení obsahu ve vyhledávací službě.
Začněte s webem Azure Portal. Osoba, která vytvořila vyhledávací službu, může zobrazit a spravovat vyhledávací službu, včetně udělení přístupu ostatním prostřednictvím stránky Řízení přístupu (IAM).
Přejděte k dalším klientům pro programový přístup. Pro první kroky doporučujeme rychlé starty a ukázky:
Zabezpečený přístup k vektorům dat
Azure AI Search implementuje šifrování dat, privátní připojení pro scénáře bez internetu a přiřazení rolí pro zabezpečený přístup prostřednictvím ID Microsoft Entra. Úplný rozsah podnikových funkcí zabezpečení je popsaný v části Zabezpečení ve službě Azure AI Search.
Správa úložišť vektorů
Azure poskytuje monitorovací platformu, která zahrnuje protokolování diagnostiky a upozorňování. Doporučujeme následující osvědčené postupy: