Vyrovnání clusteru Service Fabric
Resource Manager clusteru Service Fabric podporuje dynamické změny zatížení, reakce na přidání nebo odebrání uzlů nebo služeb. Zároveň automaticky opravuje porušení omezení a proaktivně znovu vyrovnává cluster. Jak často se ale tyto akce provádějí a co je aktivuje?
Existují tři různé kategorie práce, které Provádí Správce prostředků clusteru:
- Umístění – tato fáze se zabývá umístěním všech stavových replik nebo bezstavových instancí, které chybí. Umístění zahrnuje nové služby i zpracování stavových replik nebo bezstavových instancí, které selhaly. Tady se zpracovávají odstraněné repliky nebo instance.
- Kontroly omezení – tato fáze kontroluje a opravuje porušení různých omezení umístění (pravidel) v systému. Příklady pravidel jsou například zajištění, že uzly nejsou nad kapacitou a že jsou splněna omezení umístění služby.
- Vyrovnávání – tato fáze kontroluje, jestli se vyžaduje vyrovnávání na základě nakonfigurované požadované úrovně zůstatku pro různé metriky. Pokud ano, pokusí se najít uspořádání v clusteru, který je vyváženější.
Konfigurace časovačů Resource Manageru clusteru
První sada ovládacích prvků kolem vyrovnávání je sada časovačů. Tyto časovače určují, jak často Správce prostředků clusteru kontroluje cluster a provádí nápravné akce.
Každý z těchto různých typů oprav, které může Správce prostředků clusteru provést, je řízen jiným časovačem, který řídí jeho frekvenci. Při každém spuštění časovače je úkol naplánován. Ve výchozím nastavení Resource Manager:
- zkontroluje jeho stav a použije aktualizace (například záznam, že uzel je vypnutý) každých 1/10 sekundy.
- nastaví příznak kontroly umístění každou sekundu.
- nastaví příznak kontroly omezení každou sekundu.
- nastaví příznak vyrovnávání každých pět sekund.
Příklady konfigurace, které řídí tyto časovače, jsou následující:
ClusterManifest.xml:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="PLBRefreshGap" Value="0.1" />
<Parameter Name="MinPlacementInterval" Value="1.0" />
<Parameter Name="MinConstraintCheckInterval" Value="1.0" />
<Parameter Name="MinLoadBalancingInterval" Value="5.0" />
</Section>
prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "PLBRefreshGap",
"value": "0.10"
},
{
"name": "MinPlacementInterval",
"value": "1.0"
},
{
"name": "MinConstraintCheckInterval",
"value": "1.0"
},
{
"name": "MinLoadBalancingInterval",
"value": "5.0"
}
]
}
]
V současné době Správce prostředků clusteru provádí postupně pouze jednu z těchto akcí. Proto tyto časovače označujeme jako "minimální intervaly" a akce, které se provádějí, když časovače vypnou jako "nastavení příznaků". Správce prostředků clusteru se například stará o čekající žádosti o vytvoření služeb před vyrovnáváním clusteru. Jak vidíte ve výchozím časovém intervalu, který je zadaný, Správce prostředků clusteru vyhledá vše, co je potřeba udělat často. Obvykle to znamená, že sada změn provedených během každého kroku je malá. Malé a časté změny umožňují, aby Správce prostředků clusteru reagoval, když se něco děje v clusteru. Výchozí časovače poskytují určité dávky, protože mnoho stejných typů událostí se obvykle vyskytuje současně.
Když například uzly selžou, můžou to udělat najednou celé domény selhání. Všechna tato selhání se zaznamenávají během další aktualizace stavu po PLBRefreshGap. Opravy se určují během následujících spuštění umístění, kontroly omezení a vyrovnávání. Ve výchozím nastavení Správce prostředků clusteru neskenuje hodiny změn v clusteru a snaží se vyřešit všechny změny najednou. To by vedlo k nárůstům četnosti změn.
Správce prostředků clusteru také potřebuje další informace k určení, jestli je cluster nevyvážený. Pro to máme dvě další části konfigurace: BalancingThresholds a ActivityThresholds.
Prahové hodnoty vyrovnávání
Prahová hodnota vyrovnávání je hlavní kontrolou pro aktivaci vyrovnávání. Prahová hodnota vyrovnávání pro metriku je poměr. Pokud zatížení metriky na nejvíce načteném uzlu vydělené množstvím zatížení nejméně načteného uzlu překročí hodnotu BalanceThreshold této metriky, cluster se nevyrovná. Vyrovnávání výsledků se aktivuje při příští kontrole Resource Manageru clusteru. Časovač MinLoadBalancingInterval definuje, jak často má Správce prostředků clusteru zkontrolovat, jestli je potřeba obnovit rovnováhu. Kontrola neznamená, že se něco stane.
Prahové hodnoty vyrovnávání jsou definovány na základě metriky jako součást definice clusteru. Další informace o metrikách najdete v článku o metrikách.
ClusterManifest.xml
<Section Name="MetricBalancingThresholds">
<Parameter Name="MetricName1" Value="2"/>
<Parameter Name="MetricName2" Value="3.5"/>
</Section>
prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "MetricBalancingThresholds",
"parameters": [
{
"name": "MetricName1",
"value": "2"
},
{
"name": "MetricName2",
"value": "3.5"
}
]
}
]
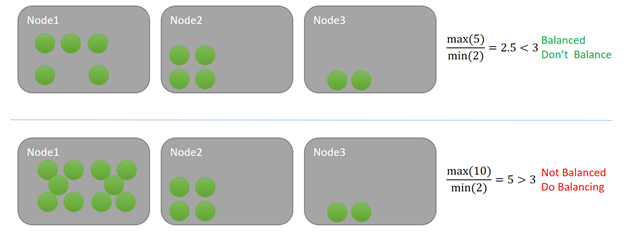
V tomto příkladu každá služba využívá jednu jednotku určité metriky. V horním příkladu je maximální zatížení uzlu pět a minimum je dva. Řekněme, že prahová hodnota vyrovnávání pro tuto metriku je tři. Vzhledem k tomu, že poměr v clusteru je 5/2 = 2,5 a je menší než zadaná prahová hodnota vyrovnávání ze tří, je cluster vyvážen. Při kontrole Resource Manageru clusteru se neaktivuje žádné vyrovnávání.
V dolním příkladu je maximální zatížení uzlu 10, zatímco minimum je dva, což vede k poměru pěti. Pětjech V důsledku toho se při příštím spuštění časovače vyrovnávání naplánuje vyrovnávání. V takové situaci se zatížení obvykle distribuuje do uzlu 3. Vzhledem k tomu, že Resource Manager clusteru Service Fabric nepoužívá přístup greedy, může být některé zatížení také distribuováno do uzlu 2.
Poznámka:
Vyrovnávání zpracovává dvě různé strategie správy zatížení v clusteru. Výchozí strategií, kterou Používá Správce prostředků clusteru, je distribuce zatížení mezi uzly v clusteru. Druhá strategie je defragmentace. Defragmentace se provádí během stejného spuštění vyrovnávání. Strategie vyrovnávání a defragmentace je možné použít pro různé metriky ve stejném clusteru. Služba může mít metriky vyrovnávání i defragmentace. U metrik defragmentace se poměr zatížení v clusteru aktivuje znovu, když je nižší než prahová hodnota vyrovnávání.
Získání pod prahovou hodnotu vyrovnávání není explicitním cílem. Prahové hodnoty vyrovnávání jsou jen aktivační událostí. Při vyrovnávání zatížení správce prostředků clusteru určuje, jaká vylepšení může provést, pokud existuje. Jen proto, že se spustí hledání vyrovnávání, neznamená, že se něco přesune. Někdy je cluster nevyvážený, ale je příliš omezený na opravu. Případně vylepšení vyžadují příliš nákladné pohyby.
Prahové hodnoty aktivity
Někdy, i když jsou uzly poměrně nevyvážené, celkové zatížení v clusteru je nízké. Nedostatek zatížení může být přechodným poklesem nebo kvůli tomu, že cluster je nový a právě se spouští. V obou případech možná nebudete chtít trávit čas vyrovnáváním clusteru, protože není možné ho získat. Pokud cluster prošel vyrovnáváním, utratili byste síťové a výpočetní prostředky, abyste mohli věci přesouvat, aniž byste udělali velký absolutní rozdíl. Abyste se vyhnuli zbytečným přesunům, existuje další ovládací prvek označovaný jako prahové hodnoty aktivity. Prahové hodnoty aktivity umožňují zadat pro aktivitu absolutní dolní mez. Pokud není nad touto prahovou hodnotou žádný uzel, vyrovnávání se neaktivuje ani v případě splnění prahové hodnoty vyrovnávání.
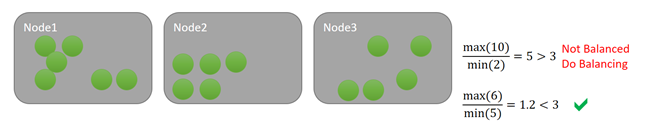
Řekněme, že pro tuto metriku zachováme prahovou hodnotu vyrovnávání ze tří. Řekněme také, že máme prahovou hodnotu aktivity 1536. V prvním případě, když je cluster nevyvážený podle prahové hodnoty vyrovnávání, neexistuje žádný uzel, který by splňoval tuto prahovou hodnotu aktivity, takže se nic nestane. V dolním příkladu je uzel 1 nad prahovou hodnotou aktivity. Vzhledem k tomu, že prahová hodnota vyrovnávání i prahová hodnota aktivity pro metriku jsou překročeny, je vyrovnávání naplánováno. Podívejme se například na následující diagram:

Stejně jako prahové hodnoty vyrovnávání se prahové hodnoty aktivity definují podle metrik prostřednictvím definice clusteru:
ClusterManifest.xml
<Section Name="MetricActivityThresholds">
<Parameter Name="Memory" Value="1536"/>
</Section>
prostřednictvím ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "MetricActivityThresholds",
"parameters": [
{
"name": "Memory",
"value": "1536"
}
]
}
]
Prahové hodnoty vyrovnávání i aktivity jsou svázané s konkrétní metrikou – vyrovnávání se aktivuje pouze v případě, že se pro stejnou metriku překročí prahová hodnota vyrovnávání i prahová hodnota aktivity.
Poznámka:
Pokud není zadáno, prahová hodnota vyrovnávání pro metriku je 1 a prahová hodnota aktivity je 0. To znamená, že se Správce prostředků clusteru pokusí zachovat tuto metriku dokonale vyváženou pro každou danou zátěž. Pokud používáte vlastní metriky, doporučujeme explicitně definovat vlastní prahové hodnoty vyrovnávání a aktivity pro metriky.
Vyrovnávání služeb společně
Bez ohledu na to, jestli je cluster nevyvážený, nebo ne, je rozhodnutí v celém clusteru. Opravíme ho ale přesunutím jednotlivých replik služeb a instancí. To dává smysl, že? Pokud je paměť skládaná na jednom uzlu, může do ní přispívat více replik nebo instancí. Oprava nerovnováhy může vyžadovat přesun jakékoli stavové repliky nebo bezstavové instance, které využívají nevyrovnanou metriku.
Občas se ale přesune služba, která nebyla sama o sobě nevyvážená (pamatujte si na diskuzi o místních a globálních váhách dříve). Proč by se služba přesunula, když byly všechny metriky této služby vyváženy? Podívejme se na příklad:
- Řekněme, že existují čtyři služby, Service 1, Service 2, Service 3 a Service 4.
- Služba 1 hlásí metriky metriky 1 a metriky 2.
- Služba 2 hlásí metriky 2 a metriky 3.
- Služba 3 hlásí metriky metriky 3 a metriky 4.
- Služba 4 hlásí metriku 99.
Ve skutečnosti nemáme čtyři nezávislé služby, máme tři služby, které souvisejí, a jednu, která je sama vypnutá.
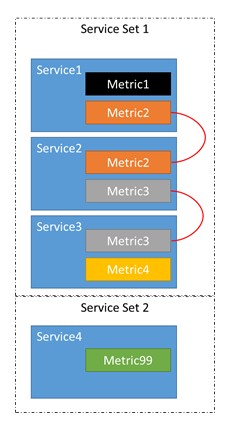
Z tohoto řetězce je možné, že nerovnováha v metrikách 1–4 může způsobit přesun replik nebo instancí patřících službám 1–3. Víme také, že nerovnováha v metrikách 1, 2 nebo 3 nemůže způsobit přesuny ve službě 4. Neexistuje žádný bod, protože přesun replik nebo instancí patřících do služby Service 4 kolem nemůže nijak ovlivnit zůstatek metrik 1–3.
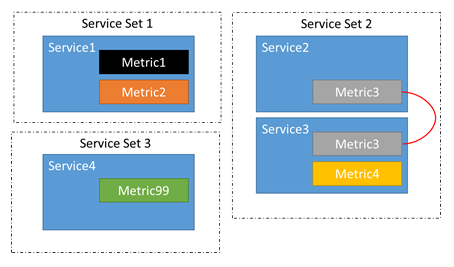
Správce prostředků clusteru automaticky zjistí, které služby souvisejí. Přidání, odebrání nebo změna metrik pro služby může mít vliv na jejich vztahy. Například mezi dvěma spuštěními služby vyrovnávání service 2 bylo možné aktualizovat, aby se odebrala metrika 2. Tím se přeruší řetěz mezi službou 1 a službou 2. Teď jsou místo dvou skupin souvisejících služeb tři:
Vyrovnávání clusteru na typ uzlu
Jak jsme popsali v předchozích částech, hlavními ovládacími prvky aktivace vyrovnávání jsou prahové hodnoty aktivity, prahové hodnoty vyrovnávání a časovače. Resource Manager clusteru Service Fabric poskytuje podrobnější kontrolu nad aktivací vyrovnávání zadáním parametrů na typ uzlu a povolením pohybu pouze u nevyvážených typů uzlů. Hlavní výhodou vyrovnávání na typ uzlu je povolení zlepšení výkonu u typů uzlů, které vyžadují přísnější pravidla vyrovnávání, bez snížení výkonu u jiných typů uzlů. Tato funkce obsahuje dvě hlavní části:
- Detekce nerovnováhy se provádí pro jednotlivé typy uzlů. Pro každý typ uzlu se počítá dříve globální výpočet nerovnováhy. Pokud jsou všechny typy uzlů vyváženy, CRM neaktivuje fázi vyrovnávání. Jinak platí, že pokud je alespoň jeden typ uzlu nevyvážený, je nutná fáze vyrovnávání.
- Vyrovnávání přesouvá repliky pouze na typy uzlů, které jsou nevyvážené, jiné typy uzlů nemají vliv na fázi vyrovnávání.
Vliv vyrovnávání na typ uzlu na cluster
Během vyrovnávání clusteru na typ uzlu vypočítá Resource Manager clusteru Service Fabric nevyrovnaný stav pro každý typ uzlu. Pokud je alespoň jeden typ uzlu nevyvážený, aktivuje se fáze vyrovnávání. Fáze vyrovnávání nepřesune repliky na typy uzlů, které jsou nevyvážené, pokud je vyrovnávání na těchto typech uzlů dočasně pozastavené (např. minimální interval vyrovnávání se od předchozí fáze vyrovnávání nepředá). Detekce nevyváženého stavu používá běžné mechanismy, které jsou již k dispozici pro vyrovnávání klasických clusterů, ale zlepšuje členitost konfigurace a flexibilitu. Mechanismy používané pro vyrovnávání na typ uzlu k detekci nerovnováhy jsou uvedeny v následujícím seznamu:
- Prahové hodnoty vyrovnávání metrik na typ uzlu jsou hodnoty, které mají podobnou roli jako globálně definovaná prahová hodnota vyrovnávání použitá v klasickém vyrovnávání. Pro každý typ uzlu se vypočítá poměr minimálního a maximálního zatížení metriky. Pokud je tento poměr typu uzlu vyšší než definovaná prahová hodnota vyrovnávání typu uzlu, označí se typ uzlu jako nevyvážený. Další podrobnosti týkající se konfigurace prahových hodnot aktivit metrik na typ uzlu najdete v části Vyrovnávání prahových hodnot pro jednotlivé typy uzlů.
- Prahové hodnoty aktivity metriky na typ uzlu jsou hodnoty, které mají podobnou roli jako globálně definovaná prahová hodnota aktivity použitá v klasickém vyrovnávání. Maximální zatížení metriky se vypočítá pro každý typ uzlu. Pokud je maximální zatížení typu uzlu vyšší než definovaná prahová hodnota aktivity pro daný typ uzlu, označí se typ uzlu jako nevyvážený. Další podrobnosti týkající se konfigurace prahových hodnot aktivit metrik na typ uzlu najdete v části prahové hodnoty aktivit na jednotlivé uzly.
- Minimální interval vyrovnávání na typ uzlu má podobnou roli jako globálně definovaný minimální interval vyrovnávání. Pro každý typ uzlu zachová Resource Manager časové razítko posledního vyrovnávání. V rámci definovaného minimálního intervalu vyrovnávání nešlo spustit dvě po sobě jdoucí fáze vyrovnávání. Další podrobnosti o konfiguraci minimálního intervalu vyrovnávání na typ uzlu najdete v části Minimální interval vyrovnávání na typ uzlu.
Popis vyrovnávání na typ uzlu
Aby bylo možné povolit vyrovnávání na typ uzlu, musí být v manifestu clusteru povolen parametr SeparateBalancingStrategyPerNodeType. Kromě toho je potřeba povolit i funkci podclusteringu. Příklad oddílu PlacementAndLoadBalancing manifestu clusteru pro povolení funkce:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="SeparateBalancingStrategyPerNodeType" Value="true" />
<Parameter Name="SubclusteringEnabled" Value="true" />
<Parameter Name="SubclusteringReportingPolicy" Value="1" />
</Section>
ClusterConfig.json pro samostatná nasazení nebo Template.json pro clustery hostované v Azure:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "SeparateBalancingStrategyPerNodeType",
"value": "true"
},
{
"name": "SubclusteringEnabled",
"value": "true"
},
{
"name": "SubclusteringReportingPolicy",
"value": "1"
},
]
}
]
Jak jsme popsali v předchozí části, prahové hodnoty a intervaly můžou být zadané pro jednotlivé typy uzlů. Další podrobnosti o aktualizaci konkrétního parametru najdete v následujících částech:
- Prahové hodnoty vyrovnávání metrik na typ uzlu
- Prahové hodnoty aktivity metriky na typ uzlu
- Minimální interval vyrovnávání na typ uzlu
Vyrovnávání prahových hodnot na typ uzlu
Prahová hodnota vyrovnávání metrik může být definována pro jednotlivé typy uzlů, aby se zvýšila členitost konfigurace vyrovnávání. Prahové hodnoty vyrovnávání mají typ s plovoucí desetinou čárkou, protože představují prahovou hodnotu pro poměr maximální a minimální hodnoty zatížení v rámci konkrétního typu uzlu. Prahové hodnoty vyrovnávání jsou definovány v části PlacementAndLoadBalancingOverrides pro každý typ uzlu:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricBalancingThresholdsPerNodeType>
<BalancingThreshold Name="Metric1" Value="2.5">
<BalancingThreshold Name="Metric2" Value="4">
<BalancingThreshold Name="Metric3" Value="3.25">
</MetricBalancingThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Pokud prahová hodnota vyrovnávání metriky není definovaná pro typ uzlu, prahová hodnota zdědí hodnotu prahové hodnoty vyrovnávání metrik definované globálně v části PlacementAndLoadBalancing . V opačném případě platí, že pokud prahová hodnota pro metriku není definována pro typ uzlu ani globálně v oddílu PlacementAndLoadBalancing, bude mít prahová hodnota výchozí hodnotu.
Prahové hodnoty aktivit na typ uzlu
Prahová hodnota aktivity metriky může být definována pro jednotlivé typy uzlů, aby se zvýšila členitost konfigurace vyrovnávání. Prahové hodnoty aktivity mají celočíselné typy, protože představují prahovou hodnotu maximální hodnoty zatížení v rámci konkrétního typu uzlu. Prahové hodnoty aktivity jsou definovány v části PlacementAndLoadBalancingOverrides pro každý typ uzlu:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricActivityThresholdsPerNodeType>
<ActivityThreshold Name="Metric1" Value="500">
<ActivityThreshold Name="Metric2" Value="40">
<ActivityThreshold Name="Metric3" Value="1000">
</MetricActivityThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Pokud prahová hodnota aktivity pro metriku není definovaná pro typ uzlu, prahová hodnota dědí hodnotu z prahové hodnoty aktivity metriky definované globálně v části PlacementAndLoadBalancing . Jinak pokud prahová hodnota aktivity pro metriku není definována pro typ uzlu ani globálně v oddílu PlacementAndLoadBalancing , prahová hodnota bude mít výchozí hodnotu nula.
Minimální interval vyrovnávání na typ uzlu
Minimální interval vyrovnávání může být definován na typ uzlu, aby se zvýšila členitost konfigurace vyrovnávání. Minimální interval vyrovnávání má celočíselné typy, protože představuje minimální dobu, která musí proběhnout před dvěma po sobě jdoucími zaokrouhlováním na stejném typu uzlu. Minimální interval vyrovnávání je definován v části PlacementAndLoadBalancingOverrides pro každý typ uzlu:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MinLoadBalancingIntervalPerNodeType>100</MinLoadBalancingIntervalPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
Pokud pro typ uzlu není definován minimální interval vyrovnávání, interval dědí hodnotu z minimálního intervalu vyrovnávání definovaného globálně v části PlacementAndLoadBalancing . Pokud není definován minimální interval pro typ uzlu ani globálně v oddílu PlacementAndLoadBalancing , minimální interval bude mít výchozí hodnotu nula , což značí, že pozastavení mezi po sobě jdoucími kruhy vyrovnávání není povinné.
Příklady
Příklad 1
Pojďme se podívat na případ, kdy cluster obsahuje dva typy uzlů, typ uzlu A a typ uzlu B. Všechny služby hlásí stejnou metriku a jsou rozdělené mezi tyto typy uzlů, a proto se pro ně statistiky načítání liší. V příkladu má typ uzlu A maximální zatížení 300 a minimálně 100 a typ uzlu B má maximální zatížení 700 a minimální zatížení 500:
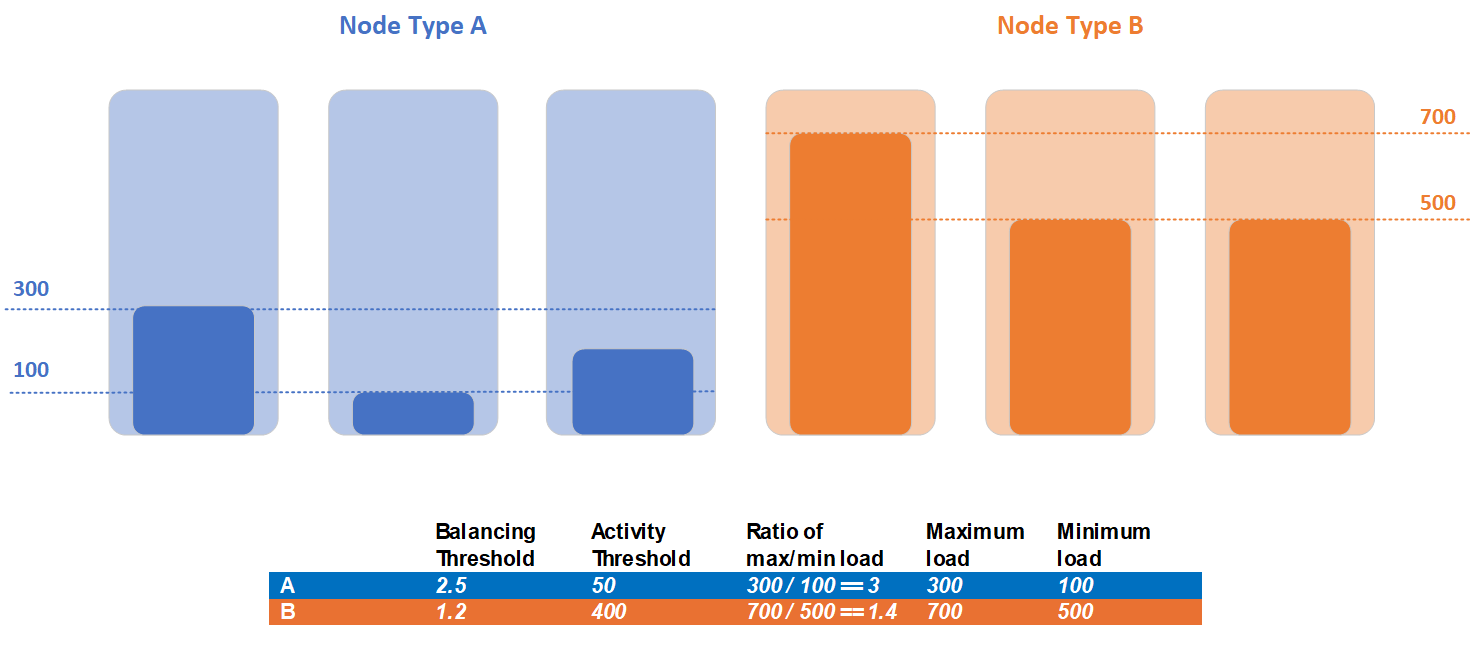
Zákazník zjistil, že úlohy dvou typů uzlů mají různé potřeby vyrovnávání a rozhodli se nastavit různé vyrovnávání a prahové hodnoty aktivit pro jednotlivé typy uzlů. Prahová hodnota vyrovnávání typu uzlu A je 2,5 a prahová hodnota aktivity je 50. Pro typ uzlu B zákazník nastavil prahovou hodnotu vyrovnávání na 1,2 a prahovou hodnotu aktivity na 400.
Během detekce nevyváženosti clusteru v tomto příkladu oba typy uzlů porušují prahovou hodnotu aktivity. Maximální zatížení typu A uzlu 300 je vyšší než definovaná prahová hodnota aktivity 50. Maximální zatížení typu uzlu B 700 je vyšší než definovaná prahová hodnota aktivity 400. Typ uzlu A porušuje kritéria prahové hodnoty vyrovnávání, protože aktuální poměr maximálního a minimálního zatížení je 3 a prahová hodnota vyrovnávání je 2,5. Naopak typ uzlu B nesplňuje kritéria prahové hodnoty vyrovnávání, protože aktuální poměr maximálního a minimálního zatížení pro tento typ uzlu je 1,2, ale prahová hodnota vyrovnávání je 1,4. Vyrovnávání je vyžadováno pouze pro repliky typu A a jediná sada replik, které budou způsobilé pro přesuny během fáze vyrovnávání, jsou repliky umístěné v typu A uzlu.
Příklad 2
Pojďme se podívat na případ, kdy cluster obsahuje tři typy uzlů, typ uzlu A, B a C. Všechny služby hlásí stejnou metriku a jsou rozdělené mezi tyto typy uzlů, a proto se pro ně statistiky načítání liší. V příkladu má typ uzlu A maximální zatížení 600 a minimálně 100, typ uzlu B má maximální zatížení 900 a minimální zatížení 100 a typ uzlu C má maximální zatížení 600 a minimální zatížení 300:

Zákazník zjistil, že úlohy těchto typů uzlů mají různé potřeby vyrovnávání a rozhodli se nastavit různé vyrovnávání a prahové hodnoty aktivit pro jednotlivé typy uzlů. Prahová hodnota vyrovnávání typu uzlu A je 5 a prahová hodnota aktivity je 700. Pro typ uzlu B zákazník nastavil prahovou hodnotu vyrovnávání na 10 a prahovou hodnotu aktivity na 200. Pro typ uzlu C zákazník nastavil prahovou hodnotu vyrovnávání na 2 a prahovou hodnotu aktivity na 300.
Maximální zatížení typu A uzlu 600 je nižší než definovaná prahová hodnota aktivity 700, takže typ uzlu A nebude vyvážen. Maximální zatížení typu uzlu B 900 je vyšší než definovaná prahová hodnota aktivity 200. Typ uzlu B porušuje kritéria prahové hodnoty aktivity. Maximální zatížení typu uzlu C 600 je vyšší než definovaná prahová hodnota aktivity 300. Typ uzlu C porušuje kritéria prahové hodnoty aktivity. Typ uzlu B nesplňuje kritéria prahové hodnoty vyrovnávání, protože aktuální poměr maximálního a minimálního zatížení pro tento typ uzlu je 9, ale prahová hodnota vyrovnávání je 10. Typ uzlu C porušuje kritéria prahové hodnoty vyrovnávání, protože aktuální poměr maximálního a minimálního zatížení je 2 a prahová hodnota vyrovnávání je 2. Vyrovnávání se vyžaduje pouze pro repliky typu C a jediná sada replik, které budou způsobilé pro přesuny během fáze vyrovnávání, jsou repliky umístěné v typu uzlu C.
Další kroky
- Metriky jsou způsob, jakým správce prostředků clusteru Service Fabric spravuje spotřebu a kapacitu v clusteru. Další informace o metrikách a jejich konfiguraci najdete v článku o metrikách.
- Náklady na přesun jsou jedním ze způsobů, jak signalizovat Správce prostředků clusteru, že některé služby jsou dražší než jiné. Další informace onákladechch
- Správce prostředků clusteru má několik omezení, která můžete nakonfigurovat tak, aby zpomalovala četnost změn v clusteru. Obvykle nejsou nezbytné, ale pokud je potřebujete, můžete se o nich dozvědět více v článku o pokročilém omezování.
- Správce prostředků clusteru dokáže rozpoznat a zpracovat podkluz. K podkluzu může dojít při použití omezení umístění a vyrovnávání. Informace o tom, jak může podclustering ovlivnit vyrovnávání a způsob jeho zpracování, najdete v článku o podkluzu.