Úvod do monitorování stavu Service Fabric
Azure Service Fabric představuje model stavu, který poskytuje bohaté, flexibilní a rozšiřitelné vyhodnocení stavu a vytváření sestav. Model umožňuje téměř v reálném čase monitorovat stav clusteru a služby spuštěné v něm. Můžete snadno získat informace o stavu a opravit potenciální problémy před jejich kaskádou a způsobit masivní výpadky. V typickém modelu služby odesílají sestavy na základě místních zobrazení a informace se agregují, aby poskytovaly celkové zobrazení na úrovni clusteru.
Komponenty Service Fabric používají tento bohatý model stavu k hlášení jejich aktuálního stavu. Stejný mechanismus můžete použít k hlášení stavu z vašich aplikací. Pokud investujete do vysoce kvalitního hlášení o stavu, které zachycuje vaše vlastní podmínky, můžete snadněji detekovat a opravit problémy pro spuštěnou aplikaci.
Poznámka:
Spustili jsme subsystém stavu, který řeší potřebu monitorovaných upgradů. Service Fabric poskytuje monitorované upgrady aplikací a clusterů, které zajišťují plnou dostupnost, žádné výpadky a minimální počet zásahů uživatelů. Aby bylo možné dosáhnout těchto cílů, upgrade kontroluje stav na základě nakonfigurovaných zásad upgradu. Upgrade může pokračovat pouze v případě, že stav respektuje požadované prahové hodnoty. Jinak se upgrade buď automaticky vrátí zpět, nebo se pozastaví, aby správci mohli problémy opravit. Další informace o upgradech aplikací najdete v tomto článku.
Úložiště stavu
Úložiště stavu uchovává informace o entitách v clusteru související se stavem, aby bylo snadné načtení a vyhodnocení. Implementuje se jako trvalá stavová služba Service Fabric, aby se zajistila vysoká dostupnost a škálovatelnost. Úložiště stavu je součástí prostředků infrastruktury:/Systémová aplikace a je k dispozici, když je cluster spuštěný.
Entity stavu a hierarchie
Entity stavu jsou uspořádány v logické hierarchii, která zachycuje interakce a závislosti mezi různými entitami. Úložiště stavu automaticky vytváří entity stavu a hierarchii na základě sestav přijatých z komponent Service Fabric.
Entity stavu zrcadlí entity Service Fabric. (Například entita aplikace stavu odpovídá instanci aplikace nasazené v clusteru, zatímco entita uzlu stavu odpovídá uzlu clusteru Service Fabric.) Hierarchie stavu zachycuje interakce systémových entit a je základem pro pokročilé vyhodnocení stavu. O klíčových konceptech Service Fabric se můžete dozvědět v technickém přehledu Service Fabric. Další informace o aplikaci najdete v tématu Model aplikace Service Fabric.
Entity stavu a hierarchie umožňují efektivní hlášení, ladění a monitorování clusteru a aplikací. Model stavu poskytuje přesné podrobné znázornění stavu mnoha pohyblivých částí v clusteru.
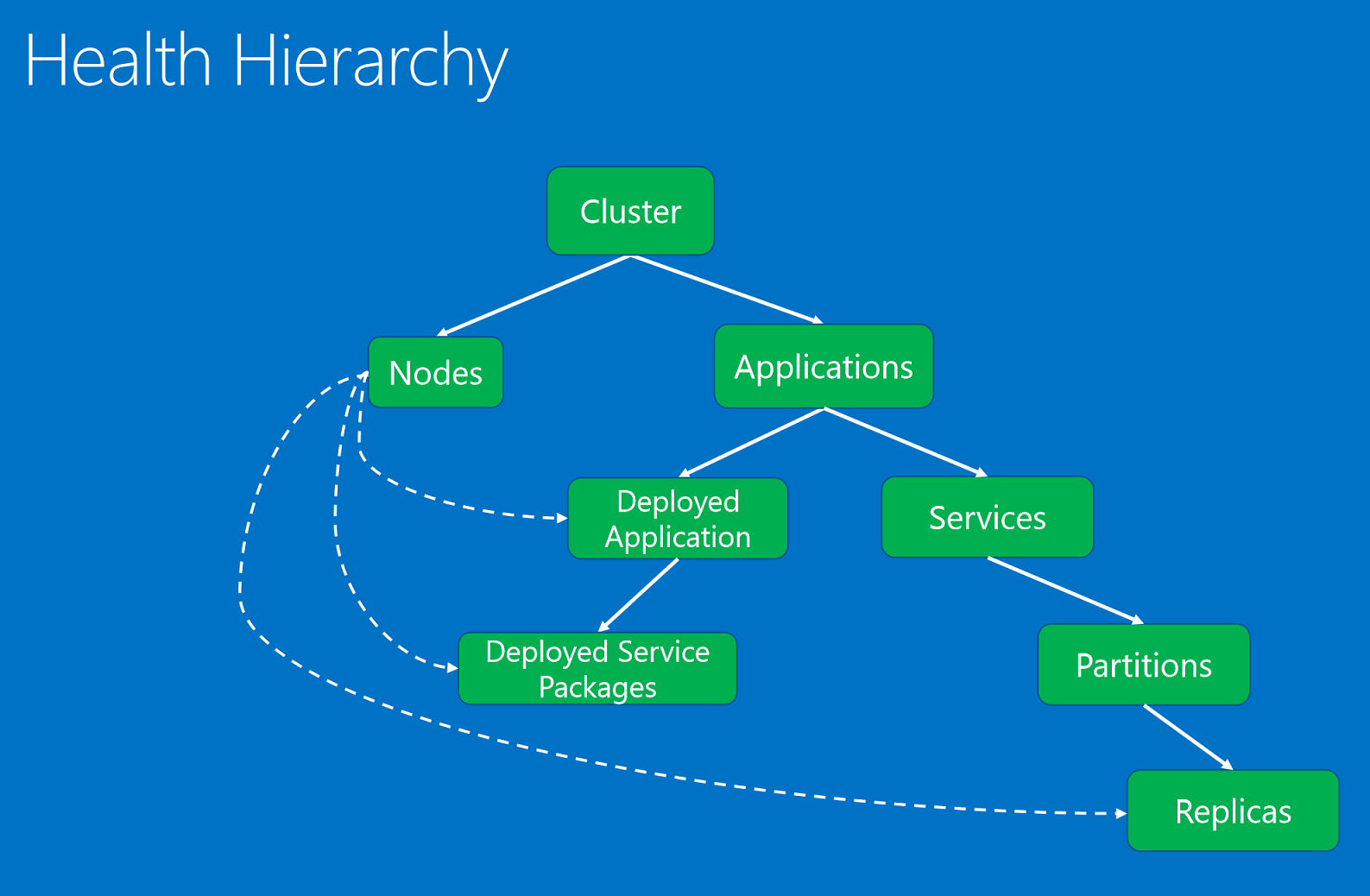 Entity stavu uspořádané v hierarchii na základě vztahů nadřazenosti a podřízenosti.
Entity stavu uspořádané v hierarchii na základě vztahů nadřazenosti a podřízenosti.
Entity stavu jsou:
- Cluster. Představuje stav clusteru Service Fabric. Sestavy stavu clusteru popisují podmínky, které ovlivňují celý cluster. Tyto podmínky ovlivňují více entit v clusteru nebo samotném clusteru. V závislosti na podmínce nemůže reportér problém zúžit na jednu nebo více podřízených položek, které nejsou v pořádku. Mezi příklady patří mozek rozdělení clusteru kvůli problémům se síťovým dělením nebo komunikací.
- Uzel. Představuje stav uzlu Service Fabric. Sestavy stavu uzlů popisují podmínky, které ovlivňují funkčnost uzlu. Obvykle ovlivňují všechny nasazené entity spuštěné na nich. Mezi příklady patří nedostatek místa na disku (nebo jiné vlastnosti celého počítače, například paměť, připojení) a kdy je uzel mimo provoz. Entita uzlu je identifikována názvem uzlu (řetězec).
- Aplikace. Představuje stav instance aplikace spuštěné v clusteru. Sestavy stavu aplikace popisují podmínky, které ovlivňují celkový stav aplikace. Nejde je zúžit na jednotlivé podřízené položky (služby nebo nasazené aplikace). Mezi příklady patří kompletní interakce mezi různými službami v aplikaci. Entita aplikace je identifikována názvem aplikace (URI).
- Služba. Představuje stav služby spuštěné v clusteru. Stav služby sestavy popisují podmínky, které ovlivňují celkový stav služby. Zpravodaj nemůže problém zúžit na oddíl nebo repliku, který není v pořádku. Mezi příklady patří konfigurace služby (například port nebo externí sdílená složka), která způsobuje problémy pro všechny oddíly. Entita služby je identifikována názvem služby (URI).
- Oddíl. Představuje stav oddílu služby. Sestavy stavu oddílů popisují podmínky, které ovlivňují celou sadu replik. Mezi příklady patří, když je počet replik nižší než cílový počet a kdy je oddíl v kvoru při ztrátě. Entita oddílu je identifikována ID oddílu (GUID).
- Replika. Představuje stav repliky stavové služby nebo bezstavové instance služby. Replika je nejmenší jednotka, na které se můžou sledovací a systémové komponenty hlásit pro aplikaci. Příklady stavových služeb zahrnují primární repliku, která nemůže replikovat operace do sekundárních a pomalých replikací. Bezstavová instance může také hlásit, když dochází k prostředkům nebo má problémy s připojením. Entita repliky je identifikována ID oddílu (GUID) a replikou nebo ID instance (long).
- Nasazená aplikace Představuje stav aplikace spuštěné na uzlu. Nasazené sestavy stavu aplikace popisují podmínky specifické pro aplikaci v uzlu, které nelze zúžit na balíčky služeb nasazené na stejném uzlu. Mezi příklady patří chyby, kdy se balíček aplikace nedá stáhnout na daném uzlu a problémy s nastavením objektů zabezpečení aplikace na uzlu. Nasazená aplikace je identifikována názvem aplikace (URI) a názvem uzlu (řetězec).
- DeployedServicePackage. Představuje stav balíčku služby spuštěného na uzlu v clusteru. Popisuje podmínky specifické pro balíček služby, který nemá vliv na ostatní balíčky služby na stejném uzlu pro stejnou aplikaci. Příklady zahrnují balíček kódu v balíčku služby, který nelze spustit, a konfigurační balíček, který nelze přečíst. Nasazený balíček služby je identifikován názvem aplikace (URI), názvem uzlu (řetězec), názvem manifestu služby (řetězec) a ID aktivace balíčku služby (řetězec).
Členitost modelu stavu usnadňuje zjišťování a opravy problémů. Pokud například služba nereaguje, je možné nahlásit, že instance aplikace není v pořádku. Vytváření sestav na této úrovni ale není ideální, protože problém nemusí mít vliv na všechny služby v této aplikaci. Sestava by se měla použít pro službu, která není v pořádku, nebo na konkrétní podřízený oddíl, pokud na tento oddíl odkazuje další informace. Data se automaticky zobrazí v hierarchii a oddíl, který není v pořádku, je viditelný na úrovních služeb a aplikací. Tato agregace pomáhá rychleji určit a vyřešit původní příčinu problému.
Hierarchie stavu se skládá z vztahů nadřazenosti a podřízenosti. Cluster se skládá z uzlů a aplikací. Aplikace mají služby a nasazené aplikace. Nasazené aplikace mají nasazené balíčky služeb. Služby mají oddíly a každý oddíl má jednu nebo více replik. Mezi uzly a nasazenými entitami existuje zvláštní vztah. Uzel, který není v pořádku, jak hlásí jeho součást systému autority, služba Správce převzetí služeb při selhání, ovlivňuje nasazené aplikace, balíčky služeb a repliky nasazené na něm.
Hierarchie stavu představuje nejnovější stav systému na základě nejnovějších zpráv o stavu, což jsou téměř informace v reálném čase. Interní a externí watchdogs můžou hlásit stejné entity na základě logiky specifické pro aplikaci nebo vlastních monitorovaných podmínek. Uživatelské sestavy existují společně se systémovými sestavami.
Naplánujte investici do vytváření sestav a reakce na stav během návrhu velké cloudové služby. Tato počáteční investice usnadňuje ladění, monitorování a provoz služby.
Stavy
Service Fabric používá tři stavy stavu k popisu, jestli je entita v pořádku, nebo ne: OK, upozornění a chyba. Každá sestava odeslaná do úložiště stavu musí určovat jeden z těchto stavů. Výsledkem vyhodnocení stavu je jeden z těchto stavů.
Možné stavy jsou:
- OK. Entita je v pořádku. Nejsou hlášeny žádné známé problémy nebo jeho podřízené položky (pokud je to možné).
- Upozornění. Entita má nějaké problémy, ale přesto může správně fungovat. Dochází například ke zpožděním, ale zatím nezpůsobí žádné funkční problémy. V některých případech se stav upozornění může opravit bez externího zásahu. V těchto případech sestavy o stavu zvýší povědomí a poskytnou přehled o tom, co se děje. V jiných případech může stav upozornění snížit na závažný problém bez zásahu uživatele.
- Error. Entita není v pořádku. Je třeba provést akci, která opraví stav entity, protože nemůže správně fungovat.
- Neznámé: Entita v úložišti stavu neexistuje. Tento výsledek lze získat z distribuovaných dotazů, které sloučí výsledky z více součástí. Dotaz get node list například přejde do části FailoverManager, ClusterManager a HealthManager. Získání dotazu seznamu aplikací přejde do ClusterManageru a HealthManageru. Tyto dotazy sloučí výsledky z více systémových komponent. Pokud jiná systémová komponenta vrátí entitu, která není v úložišti stavu, má sloučený výsledek neznámý stav. Entita není v úložišti, protože sestavy stavu ještě nebyly zpracovány nebo byla entita po odstranění vyčištěna.
Zásady stavu
Úložiště stavu používá zásady stavu k určení, jestli je entita v pořádku na základě svých sestav a podřízených položek.
Poznámka:
Zásady stavu je možné zadat v manifestu clusteru (pro vyhodnocení stavu clusteru a uzlu) nebo v manifestu aplikace (pro vyhodnocení aplikace a v libovolné z podřízených položek). Žádosti o vyhodnocení stavu můžou také předávat vlastní zásady vyhodnocení stavu, které se používají jenom pro toto vyhodnocení.
Service Fabric ve výchozím nastavení používá přísná pravidla (vše musí být v pořádku) pro hierarchický vztah nadřazeného a podřízeného objektu. Pokud i jedna z podřízených položek má jednu událost, která není v pořádku, nadřazená položka se považuje za poškozenou.
Zásady stavu clusteru
Zásady stavu clusteru slouží k vyhodnocení stavu clusteru a stavu uzlů. Zásady je možné definovat v manifestu clusteru. Pokud není k dispozici, použije se výchozí zásada (nulová tolerovaná selhání).
Zásady stavu clusteru obsahují:
ConsiderWarningAsError. Určuje, jestli se má upozornění na zprávy o stavu považovat za chyby při vyhodnocování stavu. Výchozí hodnota: false.
MaxPercentUnhealthyApplications. Určuje maximální tolerované procento aplikací, které mohou být v pořádku, než se cluster považuje za chybný.
MaxPercentUnhealthyNodes. Určuje maximální tolerované procento uzlů, které může být v pořádku, než se cluster považuje za chybný. Ve velkých clusterech jsou některé uzly vždy mimo provoz pro opravy, takže toto procento by mělo být nakonfigurováno tak, aby tolerovaly.
ApplicationTypeHealthPolicyMap. Mapu zásad stavu typu aplikace je možné použít při vyhodnocování stavu clusteru k popisu speciálních typů aplikací. Ve výchozím nastavení se všechny aplikace zadají do fondu a vyhodnotí se pomocí MaxPercentUnhealthyApplications. Pokud by se některé typy aplikací měly zacházet odlišně, mohou být odebrány z globálního fondu. Místo toho se vyhodnocují s procenty přidruženými k názvu typu aplikace v mapě. Například v clusteru existují tisíce aplikací různých typů a několik řídicích instancí aplikace speciálního typu aplikace. Řídicí aplikace by nikdy neměly být chybné. Můžete zadat globální MaxPercentUnhealthyApplications na 20 % pro tolerování některých selhání, ale pro typ aplikace ControlApplicationType nastavte MaxPercentUnhealthyApplications na hodnotu 0. To znamená, že pokud některé z mnoha aplikací nejsou v pořádku, ale pod globálním procentem špatného stavu, cluster by se vyhodnotil jako Upozornění. Stav upozornění nemá vliv na upgrade clusteru ani na jiné monitorování aktivované stavem chyb. Dokonce i jedna řídicí aplikace v chybě způsobí, že cluster není v pořádku, což v závislosti na konfiguraci upgradu aktivuje vrácení zpět nebo pozastaví upgrade clusteru. U typů aplikací definovaných v mapě jsou všechny instance aplikace odebrány z globálního fondu aplikací. Vyhodnocují se na základě celkového počtu aplikací typu aplikace pomocí konkrétní hodnoty MaxPercentUnhealthyApplications z mapy. Všechny zbývající aplikace zůstávají v globálním fondu a vyhodnocují se pomocí MaxPercentUnhealthyApplications.
Následující příklad je výňatek z manifestu clusteru. Chcete-li definovat položky v mapě typu aplikace, předpona název parametru "ApplicationTypeMaxPercentUnhealthyApplications-" následovaný názvem typu aplikace.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Mapu zásad stavu typu uzlu je možné použít při vyhodnocování stavu clusteru k popisu speciálních typů uzlů. Typy uzlů se vyhodnocují s procenty přidruženými k názvu typu uzlu v mapě. Nastavení této hodnoty nemá žádný vliv na globální fond uzlů používaných proMaxPercentUnhealthyNodes. Cluster má například stovky uzlů různých typů a několik typů uzlů, které hostují důležitou práci. V daném typu by neměly být žádné uzly. Můžete zadat globálníMaxPercentUnhealthyNodesaž 20 % pro tolerování některých selhání pro všechny uzly, ale pro typSpecialNodeTypeuzlu nastavteMaxPercentUnhealthyNodeshodnotu 0. To znamená, že pokud některé z mnoha uzlů nejsou v pořádku, ale pod globálním procentem špatného stavu, cluster by se vyhodnotil jako ve stavu Upozornění. Stav upozornění nemá vliv na upgrade clusteru ani na jiné monitorování aktivované stavem chyb. I jeden uzel typuSpecialNodeTypev chybovém stavu by ale cluster v závislosti na konfiguraci upgradu aktivoval vrácení zpět nebo pozastavil upgrade clusteru. Naopak nastavení globálníMaxPercentUnhealthyNodeshodnoty 0 a nastaveníSpecialNodeTypemaximálního procenta uzlů, které nejsou v pořádku, na 100 s jedním uzlem typuSpecialNodeTypev chybovém stavu by cluster stále umístil do chybového stavu, protože v tomto případě je globální omezení přísnější.Následující příklad je výňatek z manifestu clusteru. Chcete-li definovat položky v mapování typu uzlu, předpona název parametru nodeTypeMaxPercentUnhealthyNodes-, následovaný názvem typu uzlu.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Zásady stavu aplikace
Zásady stavu aplikace popisují, jak se pro aplikace a jejich podřízené aplikace provádí vyhodnocení agregace událostí a podřízených stavů. Dá se definovat v manifestu aplikace ApplicationManifest.xml v balíčku aplikace. Pokud nejsou zadány žádné zásady, Service Fabric předpokládá, že entita není v pořádku, pokud má v upozornění nebo chybovém stavu podřízenou zprávu o stavu. Konfigurovatelné zásady jsou:
- ConsiderWarningAsError. Určuje, jestli se má upozornění na zprávy o stavu považovat za chyby při vyhodnocování stavu. Výchozí hodnota: false.
- MaxPercentUnhealthyDeployedApplications. Určuje maximální tolerované procento nasazených aplikací, které můžou být v pořádku, než se aplikace považuje za chybnou. Toto procento se vypočítá tak, že vydělí počet nasazených aplikací, které nejsou v pořádku, na počet uzlů, na které jsou aktuálně nasazené aplikace v clusteru. Výpočet zaokrouhlí nahoru tak, aby toleroval jedno selhání u malých čísel uzlů. Výchozí procento: nula.
- DefaultServiceTypeHealthPolicy. Určuje výchozí zásady stavu typu služby, které nahradí výchozí zásady stavu pro všechny typy služeb v aplikaci.
- ServiceTypeHealthPolicyMap. Poskytuje mapu zásad stavu služeb pro jednotlivé typy služeb. Tyto zásady nahrazují výchozí zásady stavu typu služby pro každý zadaný typ služby. Pokud má například aplikace typ služby bezstavové brány a typ služby stavového stroje, můžete nakonfigurovat zásady stavu pro jejich vyhodnocení odlišně. Při zadávání zásad na typ služby můžete získat podrobnější kontrolu nad stavem služby.
Zásady stavu typu služby
Zásady stavu typu služby určují, jak vyhodnotit a agregovat služby a podřízené služby. Zásady obsahují:
- MaxPercentUnhealthyPartitionsPerService. Určuje maximální tolerované procento oddílů, které nejsou v pořádku, než se služba považuje za poškozenou. Výchozí procento: nula.
- MaxPercentUnhealthyReplicasPerPartition. Určuje maximální tolerované procento replik, které nejsou v pořádku, než se oddíl považuje za v pořádku. Výchozí procento: nula.
- MaxPercentUnhealthyServices. Určuje maximální tolerované procento služeb, které nejsou v pořádku, než bude aplikace považována za poškozenou. Výchozí procento: nula.
Následující příklad je výňatek z manifestu aplikace:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Vyhodnocení stavu
Uživatelé a automatizované služby můžou kdykoli vyhodnotit stav pro libovolnou entitu. Aby bylo možné vyhodnotit stav entity, úložiště stavu agreguje všechny sestavy o stavu entity a vyhodnotí všechny její podřízené položky (pokud je to možné). Algoritmus agregace stavu používá zásady stavu, které určují, jak vyhodnotit sestavy stavu a jak agregovat podřízené stavy (pokud je to možné).
Agregace sestavy stavu
Jedna entita může mít více sestav o stavu odesílaných různými reportéry (systémovými komponentami nebo watchdogs) v různých vlastnostech. Agregace používá přidružené zásady stavu, zejména u člena aplikace nebo zásad stavu clusteru ConsiderWarningAsError. ConsiderWarningAsError určuje, jak vyhodnotit upozornění.
Agregovaný stav je aktivován sestavou nejhoršího stavu entity. Pokud existuje alespoň jedna zpráva o stavu chyby, agregovaný stav je chybou.
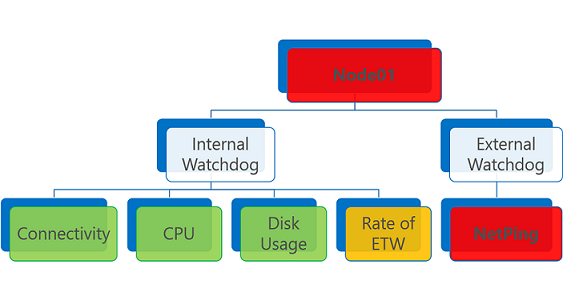
Entita stavu, která obsahuje jednu nebo více zpráv o stavu chyb, se vyhodnotí jako Chyba. Totéž platí pro zprávu o stavu s vypršenou platností bez ohledu na stav.
Pokud neexistují žádné zprávy o chybách a jedno nebo více upozornění, agregovaný stav je buď upozornění, nebo chyba v závislosti na příznaku zásady ConsiderWarningAsError.
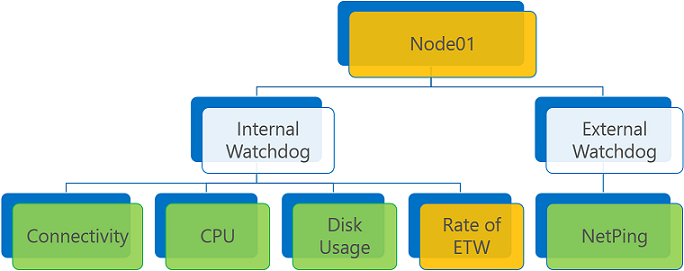
Agregace sestavy stavu se sestavou upozornění a chybou ConsiderWarningAsError nastavenou na false (výchozí).
Agregace podřízeného stavu
Agregovaný stav entity odráží stav podřízených stavů (pokud je to možné). Algoritmus pro agregaci podřízených stavů používá zásady stavu použitelné na základě typu entity.
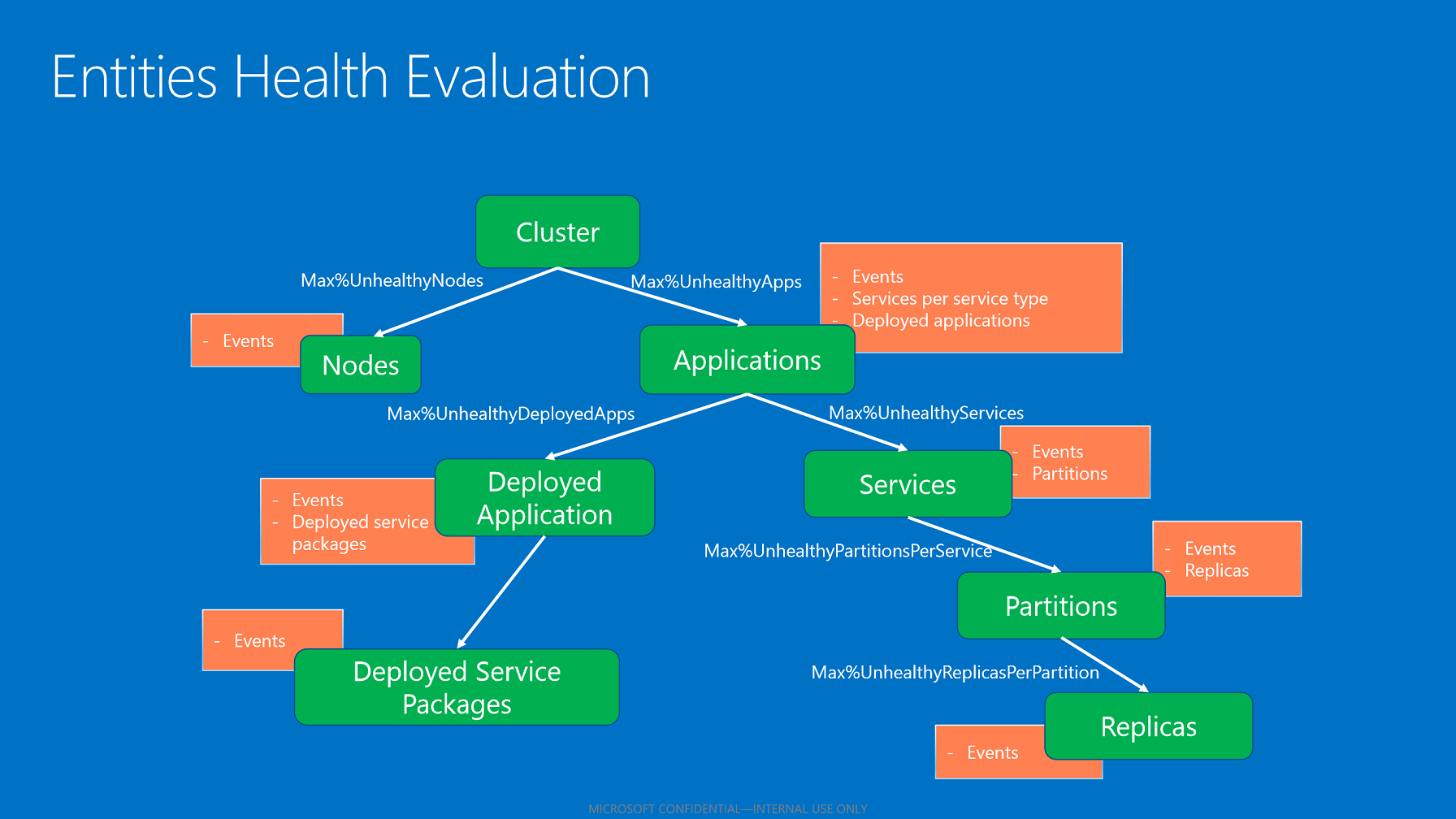
Podřízená agregace založená na zásadách stavu
Jakmile úložiště stavu vyhodnotí všechny podřízené položky, agreguje jejich stavy na základě nakonfigurovaného maximálního procenta dětí, které nejsou v pořádku. Toto procento vychází ze zásad na základě entity a podřízeného typu.
- Pokud mají všechny děti stavy OK, je agregovaný stav dítěte v pořádku.
- Pokud podřízené položky mají stavy OK i upozornění, je podřízený agregovaný stav upozornění.
- Pokud existují podřízené položky s chybovými stavy, které nerespektují maximální povolenou procentuální hodnotu podřízených položek, které nejsou v pořádku, je agregovaný nadřazený stav chybou.
- Pokud podřízené položky s chybami respektují maximální povolené procento podřízených položek, které nejsou v pořádku, je agregovaný nadřazený stav upozornění.
Generování sestav o stavu
Systémové komponenty, aplikace System Fabric a interní/externí watchdogs můžou hlásit entity Service Fabric. Zpravodajé provádějí místní určení stavu monitorovaných entit na základě podmínek, které monitorují. Nemusí se dívat na žádná globální stav ani agregovaná data. Požadované chování je mít jednoduché reportéry, a ne složité organismy, které se musí podívat na mnoho věcí, aby odvozovaly informace, které mají být odeslány.
Pokud chcete odeslat data o stavu do úložiště stavu, musí reportér identifikovat ovlivněnou entitu a vytvořit sestavu stavu. K odeslání sestavy použijte rozhraní API FabricClient.HealthClient.ReportHealth , rozhraní API pro stav sestavy vystavená pro Partition CodePackageActivationContext objekty, rutiny PowerShellu nebo REST.
Sestavy stavu
Sestavy stavu pro každou entitu v clusteru obsahují následující informace:
SourceId. Řetězec, který jednoznačně identifikuje reportér události stavu.
Identifikátor entity. Identifikuje entitu, ve které se sestava používá. Liší se podle typu entity:
- Shluk. Nezaokrouhlovat.
- Uzel. Název uzlu (řetězec)
- Aplikace. Název aplikace (URI). Představuje název instance aplikace nasazené v clusteru.
- Služba. Název služby (URI). Představuje název instance služby nasazené v clusteru.
- Oddíl. ID oddílu (GUID). Představuje jedinečný identifikátor oddílu.
- Replika. ID repliky stavové služby nebo ID instance bezstavové služby (INT64).
- Nasazená aplikace Název aplikace (URI) a název uzlu (řetězec).
- DeployedServicePackage. Název aplikace (URI), název uzlu (řetězec) a název manifestu služby (řetězec).
Vlastnost. Řetězec (nikoli pevný výčet), který zpravodaji umožňuje kategorizovat událost stavu pro konkrétní vlastnost entity. Například reportér A může hlásit stav vlastnosti Node01 Storage a reporter B může hlásit stav vlastnosti Připojení Node01. V úložišti stavu se tyto sestavy považují za samostatné události stavu pro entitu Node01.
Popis. Řetězec, který zpravodaji umožňuje poskytnout podrobné informace o události stavu. SourceId, Property a HealthState by měly plně popsat sestavu. Popis přidá o sestavě čitelné informace pro člověka. Text usnadňuje správcům a uživatelům pochopení sestavy stavu.
Stav. Výčet, který popisuje stav sestavy. Akceptované hodnoty jsou OK, Warning a Error.
TimeToLive. Časový interval označující, jak dlouho je zpráva o stavu platná. Ve spojení s RemoveWhenExpired umožňuje úložišti stavu zjistit, jak vyhodnotit události s vypršenou platností. Ve výchozím nastavení je hodnota nekonečná a sestava je navždy platná.
RemoveWhenExpired. Logická hodnota. Pokud je nastavená hodnota true, sestava stavu s vypršenou platností se automaticky odebere z úložiště stavu a sestava nemá vliv na vyhodnocení stavu entit. Používá se, když je sestava platná jenom pro určité časové období a reportér ji nemusí explicitně vymazat. Používá se také k odstranění sestav z úložiště stavu (například watchdog se změní a přestane odesílat sestavy s předchozím zdrojem a vlastností). Může odeslat sestavu se stručným časem TimeToLive spolu s RemoveWhenExpired a vymazat všechny předchozí stavy z úložiště stavu. Pokud je hodnota nastavena na false, sestava s vypršenou platností se považuje za chybu při vyhodnocování stavu. Falešná hodnota signalizuje úložiště stavu, které má zdroj pravidelně hlásit pro tuto vlastnost. Pokud ne, musí být něco špatného u sledovacího zařízení. Stav sledovacího zařízení je zachycen zvážením události jako chyby.
SequenceNumber. Kladné celé číslo, které se musí neustále zvětšovat, představuje pořadí sestav. Úložiště stavu ho používá k detekci zastaralých sestav, které jsou přijaty pozdě kvůli zpoždění sítě nebo jiným problémům. Sestava se odmítne, pokud je pořadové číslo menší nebo rovno naposledy použitému číslu pro stejnou entitu, zdroj a vlastnost. Pokud není zadané, vygeneruje se pořadové číslo automaticky. Je nutné zadat pořadové číslo pouze v případě, že se hlásí přechody stavu. V takovém případě si zdroj musí pamatovat, které zprávy odeslal, a zachovat informace pro obnovení při převzetí služeb při selhání.
Tyto čtyři části informací – SourceId, entity identifier, Property a HealthState – jsou vyžadovány pro každou zprávu o stavu. Řetězec SourceId nesmí začínat předponou System., která je vyhrazena pro systémové sestavy. Pro stejnou entitu existuje pouze jedna sestava pro stejný zdroj a vlastnost. Více sestav pro stejný zdroj a vlastnost se navzájem přepíše, a to buď na straně klienta stavu (pokud jsou dávkové) nebo na straně úložiště stavu. Nahrazení je založeno na pořadových číslech; novější sestavy (s vyššími pořadovými čísly) nahrazují starší sestavy.
Události stavu
Úložiště stavu interně uchovává události stavu, které obsahují všechny informace ze sestav a další metadata. Metadata zahrnují čas, kdy byla sestava předána klientovi stavu a čas jeho změny na straně serveru. Události stavu jsou vráceny dotazy na stav.
Přidaná metadata obsahují:
- SourceUtcTimestamp. Čas, kdy byla sestava předána klientovi stavu (koordinovaný univerzální čas).
- LastModifiedUtcTimestamp. Čas poslední změny sestavy na straně serveru (Koordinovaný univerzální čas).
- IsExpired. Příznak označující, jestli vypršela platnost sestavy při spuštění dotazu úložištěm stavu. Platnost události může být ukončena pouze v případě, že removeWhenExpired je false. Jinak se událost nevrátí dotazem a odebere se z úložiště.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Čas posledního přechodu OK, upozornění nebo chyby. Tato pole poskytují historii přechodů stavu události.
Pole přechodu stavu se dají použít pro inteligentnější výstrahy nebo "historické" informace o událostech stavu. Umožňují scénáře, jako jsou:
- Výstraha, pokud je vlastnost v upozornění nebo chybě delší než X minut. Kontrola podmínky po určitou dobu zabrání upozorněním na dočasné podmínky. Upozornění, pokud je například stav upozornění delší než pět minut, lze přeložit do stavu (HealthState == Warning and Now - LastWarningTransitionTime > 5 minut).
- Upozornění pouze na podmínky, které se v posledních X minutách změnily. Pokud už sestava byla před zadaným časem chybná, může být ignorována, protože už byla signalována dříve.
- Pokud vlastnost přepíná mezi upozorněním a chybou, určete, jak dlouho není v pořádku (to znamená, že není v pořádku). Upozornění, pokud vlastnost nebyla v pořádku déle než pět minut, lze například přeložit do stavu (HealthState != OK a Now – LastOkTransitionTime > 5 minut).
Příklad: Sestava a vyhodnocení stavu aplikace
Následující příklad odešle sestavu stavu prostřednictvím PowerShellu v prostředcích infrastruktury aplikace :/WordCount ze zdrojového souboru MyWatchdog. Sestava stavu obsahuje informace o vlastnosti stavu "availability" ve stavu chyby s nekonečným TimeToLive. Potom se dotazuje na stav aplikace, který vrací agregované chyby stavu a hlášené události stavu v seznamu událostí stavu.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Využití modelu stavu
Model stavu umožňuje škálovat cloudové služby a základní platformu Service Fabric, protože stanovení stavu a monitorování se distribuují mezi různé monitorování v rámci clusteru. Ostatní systémy mají jednu centralizovanou službu na úrovni clusteru, která analyzuje všechny potenciálně užitečné informace generované službami. Tento přístup brání jejich škálovatelnosti. Neumožňuje jim také shromažďovat konkrétní informace, které jim pomůžou identifikovat problémy a potenciální problémy co nejblíže původní příčině.
Model stavu se intenzivně používá pro monitorování a diagnostiku, pro vyhodnocení stavu clusteru a aplikací a pro monitorované upgrady. Jiné služby používají data o stavu k provádění automatických oprav, sestavení historie stavu clusteru a vydávání výstrah za určitých podmínek.
Další kroky
Zobrazení sestav stavu Service Fabric
Řešení potíží s využitím sestav stavu systému
Jak hlásit a zkontrolovat stav služby
Přidání vlastních sestav stavu Service Fabric