Diese Beispielarchitektur basiert auf der Beispielarchitektur der Basic-Webanwendung und erweitert diese, um zu zeigen:
- Bewährte Verfahren zur Verbesserung der Skalierbarkeit und Leistung einer Azure App Service-Webanwendung
- Wie Sie eine Azure App Service-Anwendung in mehreren Regionen ausführen, um hohe Verfügbarkeit zu erreichen
Aufbau
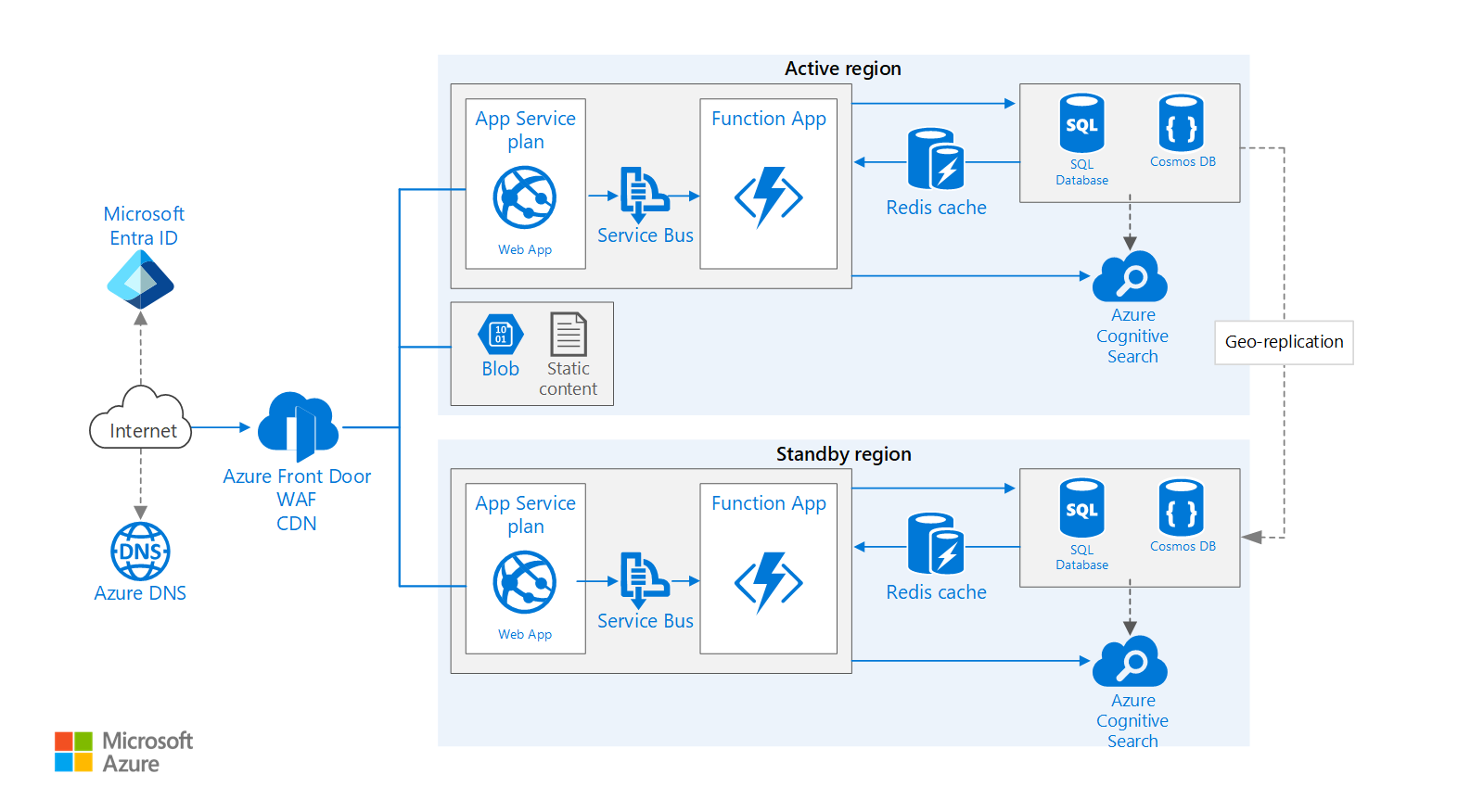
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Dieser Workflow befasst sich mit den multiregionalen Aspekten der Architektur und baut auf der Basic-Webanwendung auf.
- Primäre und sekundäre Regionen. Diese Architektur nutzt zwei Regionen, um eine höhere Verfügbarkeit zu erreichen. Die Anwendung wird in jeder Region bereitgestellt. Während des normalen Betriebs wird Netzwerkdatenverkehr an die primäre Region weitergeleitet. Wenn die primäre Region nicht verfügbar ist, wird der Datenverkehr an die sekundäre Region umgeleitet.
- Front Door. Azure Front Door ist der empfohlene Lastenausgleich für multiregionale Implementierungen. Es lässt sich in die Web Application Firewall (WAF) integrieren, um vor gängigen Exploits zu schützen, und nutzt die native Content Caching-Funktion von Front Door. In dieser Architektur ist Front Door für prioritäres Routing konfiguriert, das den gesamten Datenverkehr an die primäre Region sendet, es sei denn, diese ist nicht mehr verfügbar. Wenn die primäre Region nicht mehr verfügbar ist, leitet Front Door den gesamten Datenverkehr an die sekundäre Region um.
- Georeplikation von Speicherkonten, SQL-Datenbank und/oder Azure Cosmos DB.
Hinweis
Einen detaillierten Überblick über die Verwendung von Azure Front Door für multiregionale Architekturen, auch in einer netzwerkgesicherten Konfiguration, finden Sie unter Implementierung von netzwerkgesicherten Eingangsvorgängen.
Komponenten
Die wichtigsten für die Implementierung dieser Architektur verwendeten Technologien sind:
- Microsoft Entra ID ist ein cloudbasierter Identitäts- und Zugriffsverwaltungsdienst, mit dem Mitarbeitende auf Cloud-Apps zugreifen können, die für Ihre Organisation entwickelt wurden.
- Azure DNS ist ein Hostingdienst für DNS-Domänen, der die Namensauflösung mithilfe der Microsoft Azure-Infrastruktur durchführt. Durch das Hosten Ihrer Domänen in Azure können Sie Ihre DNS-Einträge mithilfe der gleichen Anmeldeinformationen, APIs, Tools und Abrechnung wie für die anderen Azure-Dienste verwalten. Erstellen Sie zur Verwendung eines benutzerdefinierten Domänennamens (etwa
contoso.com) DNS-Einträge, die der IP-Adresse den benutzerdefinierten Domänennamen zuordnen. Weitere Informationen finden Sie unter Konfigurieren eines benutzerdefinierten Domänennamens in Azure App Service. - Azure Content Delivery Network ist eine globale Lösung für die Bereitstellung von Inhalten mit hoher Bandbreite durch Zwischenspeicherung an strategisch platzierten physischen Knotenpunkten auf der ganzen Welt.
- Azure Front Door ist ein Layer-7-Lastenausgleichsmodul. Bei dieser Architektur werden HTTP-Anforderungen an das Web-Front-End geleitet. Mit Front Door wird auch eine Web Application Firewall (WAF) bereitgestellt, mit der die Anwendung vor häufig auftretenden Exploits und Sicherheitsrisiken geschützt wird. Front Door wird auch für eine Content Delivery Network-Lösung (CDN) in diesem Entwurf verwendet.
- Azure App Service ist eine vollständig verwaltete Plattform für die Erstellung und Bereitstellung von Cloud-Anwendungen. Sie ermöglicht das Definieren einer Reihe von Computeressourcen zum Ausführen einer Web-App, das Bereitstellen von Web-Apps und das Konfigurieren von Bereitstellungsslots.
- Azure Function Apps kann zur Ausführung von Hintergrundaufgaben verwendet werden. Funktionen werden durch einen Trigger ausgelöst, etwa ein Timerereignis oder eine Nachricht, die in einer Warteschlange platziert wird. Verwenden Sie für zustandsbehaftete Aufgaben mit langer Ausführungsdauer Durable Functions.
- Azure Storage ist eine Cloudspeicherlösung für moderne Datenspeicherszenarien und bietet hochverfügbaren, massiv skalierbaren, langlebigen und sicheren Speicher für eine Vielzahl von Datenobjekten in der Cloud.
- Azure Redis Cache ist ein hochleistungsfähiger Caching-Dienst, der einen In-Memory-Datenspeicher für den schnelleren Abruf von Daten bietet und auf der Open-Source-Implementierung Redis Cache basiert.
- Azure SQL-Datenbank ist eine relationale Datenbank als Dienst (Database-as-a-Service, DaaS) in der Cloud. SQL-Datenbank nutzt diese Codebasis gemeinsam mit der Microsoft SQL Server-Datenbank-Engine.
- Azure Cosmos DB ist eine global verteilte, vollständig verwaltete, latenzarme Multi-Modell- und Multi Query-API-Datenbank für die Verwaltung von Daten in großem Maßstab.
- Azure Cognitive Search kann verwendet werden, um Suchfunktionen wie Suchvorschläge, unscharfe Suche und sprachspezifische Suche hinzuzufügen. Azure Search wird normalerweise in Verbindung mit einem anderen Datenspeicher verwendet, insbesondere dann, wenn der primäre Datenspeicher strikte Konsistenz erfordert. Bei dieser Vorgehensweise speichern Sie autorisierende Daten in dem anderen Datenspeicher und den Suchindex in Azure Search. Azure Search kann auch zum Konsolidieren eines einzelnen Suchindex aus mehreren Datenspeichern verwendet werden.
Szenariodetails
Es gibt mehrere allgemeine Vorgehensweisen für das Erreichen von Hochverfügbarkeit mit mehreren Regionen:
Aktiv/Passiv mit unmittelbar betriebsbereitem Standbyserver: Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Hot Standby wartet. Unmittelbar betriebsbereit (Hot Standby) bedeutet, dass die App Service-Instanz in der sekundären Region zugeordnet ist und immer ausgeführt wird.
Aktiv/Passiv mit verzögert betriebsbereitem Standbyserver: Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Cold Standby wartet. „Verzögert betriebsbereit“ (Cold Standby) bedeutet, dass die App Service-Instanz in der sekundären Region erst dann zugeordnet wird, wenn sie für ein Failover benötigt wird. Dieser Ansatz erfordert weniger Ausführungszeit, es dauert aber im Allgemeinen länger, bis bei einem Ausfall alle Komponenten online geschaltet sind.
Aktiv/Aktiv: Beide Regionen sind aktiv, und Anforderungen werden per Lastenausgleich zwischen ihnen verteilt. Wenn eine Region nicht mehr verfügbar ist, wird sie aus der Rotation genommen.
Dieser Verweis konzentriert sich auf aktiv/passiv mit unmittelbar betriebsbereitem Standbyserver. Informationen zum Entwerfen von Lösungen, die die anderen Ansätze verwenden, finden Sie unter Multi-Region App Service-Ansätze für die Notfallwiederherstellung.
Mögliche Anwendungsfälle
Bei folgenden Anwendungsfällen können Sie von einer Bereitstellung in mehreren Regionen profitieren:
Entwerfen eines BCDR-Plans (Business Continuity & Disaster Recovery) für Branchenanwendungen.
Bereitstellen unternehmenskritischer Anwendungen, die unter Windows oder Linux ausgeführt werden.
Verbessern der Benutzerfreundlichkeit, indem Anwendungen verfügbar bleiben.
Empfehlungen
Ihre Anforderungen können von der hier beschriebenen Architektur abweichen. Verwenden Sie die Empfehlungen in diesem Abschnitt als Ausgangspunkt.
Regionspaare
Viele Azure-Regionen werden mit einer anderen Region innerhalb derselben Geografie gekoppelt. Einige Regionen verfügen nicht über eine gekoppelte Region. Weitere Informationen zu Regionspaaren finden Sie unter Geschäftskontinuität und Notfallwiederherstellung: Azure-Regionspaare.
Wenn Ihre primäre Region über ein Paar verfügt, sollten Sie die gekoppelte Region als sekundäre Region (z. B. East US 2 und Central US) verwenden. Das bietet die folgenden Vorteile:
- Bei einem umfassenden Ausfall wird die Wiederherstellung mindestens einer Region aus jedem Paar priorisiert.
- Geplante Azure-Systemupdates werden in Regionspaaren nacheinander ausgeführt, um mögliche Ausfallzeiten zu minimieren.
- In den meisten Fällen befinden sich Regionspaare innerhalb desselben geografischen Gebiets, um spezifische regionale Anforderungen zu erfüllen.
Wenn Ihre primäre Region nicht über ein Paar verfügt, sollten Sie bei der Auswahl einer sekundären Region die folgenden Faktoren berücksichtigen:
- Minimieren Sie die Latenz, indem Sie Regionen auswählen, die ihren Benutzern geografisch nahe liegen.
- Erfüllen Sie Ihre Datenhaltungsanforderungen, indem Sie Regionen auswählen, in denen Sie Daten speichern und verarbeiten können.
Unabhängig davon, ob Ihre Regionen gekoppelt oder entkoppelt sind, stellen Sie sicher, dass beide Regionen alle azure-Dienste unterstützen, die für Ihre Anwendung erforderlich sind. Weitere Informationen finden Sie unter Dienste nach Region.
Ressourcengruppen
Sie sollten die primäre Region, die sekundäre Region und Front Door unterschiedlichen Ressourcengruppen zuordnen. Mit dieser Zuordnung können Sie die in jeder Region bereitgestellten Ressourcen als Einzelsammlungen verwalten.
App Service-Apps
Es wird empfohlen, die Webanwendung und die Web-API als separate App Service-Apps zu erstellen. Dieser Entwurf ermöglicht Ihnen die Ausführung in separaten App Service-Plänen, sodass sie unabhängig voneinander skaliert werden können. Wenn Sie diesen Grad an Skalierbarkeit anfänglich nicht benötigen, können Sie die Apps in demselben Plan bereitstellen und sie später bei Bedarf in separate Pläne verschieben.
Hinweis
Beim Basic-, Standard-, Premium- und Isolated-Plan werden Ihnen die VM-Instanzen im Plan und nicht pro App in Rechnung gestellt. Weitere Informationen finden Sie unter App Service – Preise.
Front Door-Konfiguration
Routing: Front Door unterstützt verschiedene Routingmechanismen. Verwenden Sie für das in diesem Artikel beschriebene Szenario das Routing nach Priorität. Bei dieser Einstellung sendet Front Door alle Anforderungen an die primäre Region, bis der Endpunkt für diese Region nicht mehr erreichbar ist. Zu diesem Zeitpunkt wird automatisch ein Failover zur sekundären Region ausgeführt. Konfigurieren Sie den Ursprungspool mit unterschiedlichen Prioritätswerten: 1 für die aktive Region und 2 oder höher für die Standbyregion oder passive Region.
Integritätstest: Front Door verwendet einen HTTPS-Test, um die Verfügbarkeit jedes Back-Ends zu überwachen. Der Test meldet Front Door seinen erfolgreichen oder fehlerhaften Abschluss, damit ggf. ein Failover zur sekundären Region ausgeführt werden kann. Dies erfolgt durch das Senden einer Anforderung an einen angegebenen URL-Pfad. Wenn der Test innerhalb des Zeitlimits eine andere Antwort als „200“ erhält, löst er einen Fehler aus. Sie können die Häufigkeit des Integritätstests, die Anzahl der erforderlichen Stichproben für die Bewertung sowie die Anzahl der erforderlichen Stichproben konfigurieren, die erforderlich sind, damit der Ursprung als fehlerfrei markiert werden kann. Wenn Front Door den Ursprung als beeinträchtigt kennzeichnet, wird ein Failover auf den anderen Ursprung ausgeführt. Einzelheiten hierzu finden Sie unter Integritätstests.
Es hat sich bewährt, einen Integritätstestpfad im Anwendungsursprung zu erstellen, der die Gesamtintegrität der Anwendung meldet. Von diesem Integritätstest sollten alle wichtigen Abhängigkeiten überprüft werden. Dazu gehören z. B. App Service-Apps, die Speicherwarteschlange und SQL-Datenbank. Andernfalls meldet der Test eventuell einen fehlerfreien Ursprung, obwohl wichtige Teile der Anwendung fehlerhaft sind. Andererseits sollten Sie den Integritätstest nicht zum Überprüfen von Diensten mit einer niedrigeren Priorität verwenden. Wenn beispielsweise ein E-Mail-Dienst ausfällt, kann die Anwendung zu einem zweiten Anbieter wechseln oder die E-Mails einfach später senden. Weitere Informationen zu diesem Entwurfsmuster finden Sie unter Muster für Überwachung der Integrität von Endpunkten.
Das Schützen von Ursprüngen vor dem Internet ist ein wichtiger Bestandteil der Implementierung einer öffentlich zugänglichen App. Weitere Informationen zu den von Microsoft empfohlenen Entwurfs- und Implementierungsmustern zum Schützen der eingehenden Kommunikation Ihrer App mit Front Door finden Sie in Implementierung des sicheren Netzwerkeingangs.
CDN. Verwenden Sie die native CDN-Funktionalität von Front Door für statisches Content Caching. Der wichtigste Vorteil eines CDN ist die verringerte Latenz für Benutzer, da Inhalte auf einem Edgeserver zwischengespeichert werden, der sich in geografischer Nähe zum Benutzer befindet. CDN kann auch die Auslastung der Anwendung verringern, da dieser Datenverkehr nicht von der Anwendung gehandhabt wird. Front Door bietet darüber hinaus eine dynamische Websitebeschleunigung, mit der Sie eine bessere allgemeine Benutzererfahrung für Ihre Web-App bereitstellen können, als dies nur mit statischem Content Caching möglich wäre.
Hinweis
Front Door CDN ist nicht für die Bereitstellung von Inhalten konzipiert, die eine Authentifizierung erfordern.
SQL-Datenbank
Verwenden Sie aktive Georeplikation und Autofailover-Gruppen, um Ihre Datenbanken resilient zu machen. Die aktive Georeplikation bietet die Möglichkeit, Ihre Datenbanken aus der primären Region in eine oder mehrere (bis zu vier) andere Regionen replizieren. Autofailover-Gruppen bauen auf der aktiven Georeplikation auf und ermöglichen ein Failover auf eine sekundäre Datenbank ohne Codeänderungen an Ihren Apps. Failover können abhängig von den geltenden Richtliniendefinitionen manuell oder automatisch ausgeführt werden. Um Autofailover-Gruppen verwenden zu können, müssen Sie Ihre Verbindungszeichenfolgen mit der Failoververbindungszeichenfolge konfigurieren, die automatisch für die Failovergruppe erstellt wird, und nicht mit den Verbindungszeichenfolgen der einzelnen Datenbanken.
Azure Cosmos DB
Azure Cosmos DB unterstützt die regionsübergreifende Georeplikation mit Aktiv-Aktiv-Muster und mehreren Schreibregionen. Alternativ können Sie eine Region als die schreibbare Region und die andere als schreibgeschützte Replikate festlegen. Fällt eine Region aus, können Sie ein Failover ausführen, indem Sie eine andere Region als schreibbare Region festlegen. Das Client-SDK sendet Schreibanforderungen automatisch an die aktuell schreibbare Region, daher müssen Sie die Clientkonfiguration nach einem Failover nicht aktualisieren. Weitere Informationen finden Sie unter Globale Datenverteilung mit Azure Cosmos DB.
Storage
Bei Azure Storage verwenden Sie RA-GRS (Read-Access Geo-Redundant Storage, georedundanter Speicher mit Lesezugriff). Mit RA-GRS werden die Daten in eine sekundäre Region repliziert. Sie haben über einen eigenen Endpunkt lediglich schreibgeschützten Zugriff auf die Daten in der sekundären Region. Für georeplizierte Speicherkonten wird ein vom Benutzer initiiertes Failover zur sekundären Region unterstützt. Bei der Initiierung eines Speicherkontofailovers werden DNS-Einträge automatisch aktualisiert, um das sekundäre Speicherkonto zum neuen primären Speicherkonto zu machen. Failover sollten nur durchgeführt werden, wenn Sie dies für notwendig erachten. Diese Anforderung wird durch den Notfallwiederherstellungsplan Ihrer Organisation bestimmt, und Sie sollten die Auswirkungen berücksichtigen (siehe Beschreibung im Abschnitt „Überlegungen“ weiter unten).
Tritt in einer Region ein Ausfall oder ein anderer Notfall ein, kann das Azure Storage-Team ein geografisches Failover auf die sekundäre Region ausführen. Bei derartigen Failovern ist hier keine Kundenaktion erforderlich. Das Failback zur primären Region wird in diesen Fällen auch vom Azure Storage-Team verwaltet.
In einigen Fällen ist die Objektreplikation für Blockblobs als Replikationslösung für Ihre Workload ausreichend. Mit diesem Replikationsfeature können Sie einzelne Blockblobs aus dem primären Speicherkonto in ein Speicherkonto in Ihrer sekundären Region kopieren. Der Vorteil dieses Ansatzes ist eine differenzierte Kontrolle über die Daten, die repliziert werden. Sie können eine Replikationsrichtlinie für eine differenziertere Kontrolle der Typen von Blockblobs definieren, die repliziert werden. Beispiele für Richtliniendefinitionen sind unter anderem:
- Nur Blockblobs, die nach dem Erstellen der Richtlinie hinzugefügt wurden, werden repliziert.
- Nur Blockblobs, die nach einem bestimmten Datum und einer bestimmten Uhrzeit hinzugefügt wurden, werden repliziert.
- Nur Blockblobs, die einem bestimmten Präfix entsprechen, werden repliziert.
Als alternative Messagingoption für Azure Service Bus für dieses Szenario kommt ein Warteschlangenspeicher infrage. Wenn Sie jedoch Warteschlangenspeicher für Ihre Messaginglösung verwenden, gilt hier die oben angegebene Anleitung in Bezug auf die Georeplikation, da sich der Warteschlangenspeicher in Speicherkonten befindet. Es muss klar sein, dass Nachrichten allerdings nicht in der sekundären Region repliziert werden und ihr Zustand von der Region untrennbar ist.
Azure-Servicebus
Um die höchste Resilienz nutzen zu können, die für Azure Service Bus angeboten wird, verwenden Sie den Premium-Tarif für Ihre Namespaces. Der Premium-Tarif nutzt Verfügbarkeitszonen, die Ihre Namespaces resilient gegenüber Rechenzentrumsausfällen machen. Wenn es zu einem weiträumigen Notfall kommt, der mehrere Rechenzentren betrifft, kann das Feature für die georedundante Notfallwiederherstellung im Premium-Tarif für eine Wiederherstellung hilfreich sein. Die georedundante Notfallwiederherstellung stellt sicher, dass die gesamte Konfiguration eines Namespace (Warteschlangen, Themen, Abonnements und Filter) ständig von einem primären Namespace in einen sekundären Namespace repliziert wird, wenn diese gekoppelt sind. Sie können mit ihr jederzeit ein einmaliges Failover vom primären auf den sekundären Namespace auslösen. Beim Failover wird der ausgewählte Aliasname für den Namespace dem sekundären Namespace zugeordnet, dann wird die Kopplung aufgehoben. Das Failover erfolgt nach der Initiierung fast unmittelbar.
Azure Cognitive Search
Verfügbarkeit wird bei Cognitive Search durch mehrere Replikate erreicht. Geschäftskontinuität und Notfallwiederherstellung (Business Continuity & Disaster Recovery, BCDR) werden dagegen durch mehrere Suchdienste erreicht.
In Cognitive Search handelt es sich bei Replikaten um Kopien Ihres Index. Wenn Sie also mehrere Replikate einrichten, können in Azure Cognitive Search Computerneustarts und Wartungsaktivitäten für ein Replikat durchgeführt werden, während gleichzeitig in den anderen Replikaten weiterhin Abfragen ausgeführt werden. Weitere Informationen zum Hinzufügen von Replikaten finden Sie unter Hinzufügen oder Reduzieren von Replikaten und Partitionen.
Sie können Verfügbarkeitszonen mit Azure Cognitive Search nutzen, indem Sie Ihrem Suchdienst zwei oder mehr Replikate hinzufügen. Jedes Replikat wird in einer anderen Verfügbarkeitszone innerhalb der Region platziert.
BCDR-Überlegungen finden Sie in der Dokumentation zu mehreren Diensten in getrennten geografischen Regionen.
Azure Cache for Redis
Während alle Ebenen von Azure Cache for Redis eine Standardreplikation für Hochverfügbarkeit bieten, wird der Premium- oder Enterprise-Tarif empfohlen, um ein höheres Maß an Resilienz und Wiederherstellbarkeit zu erreichen. Im Artikel zu Hochverfügbarkeit und Notfallwiederherstellung finden Sie eine vollständige Liste der Resilienz- und Wiederherstellbarkeitsfeatures und -optionen für diese Tarife. Ihre geschäftlichen Anforderungen bestimmen, welcher Tarif am besten für Ihre Infrastruktur geeignet ist.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Zuverlässigkeit
Zuverlässigkeit stellt sicher, dass Ihre Anwendung Ihre Verpflichtungen gegenüber den Kunden erfüllen kann. Weitere Informationen finden Sie in der Überblick über die Säule „Zuverlässigkeit“. Bedenken Sie die folgenden Punkte beim Entwerfen für Hochverfügbarkeit über mehrere Regionen hinweg:
Azure Front Door
Azure Front Door führt automatisch ein Failover aus, wenn die primäre Region nicht mehr verfügbar ist. Wenn Front Door ein Failover ausführt, können die Clients die Anwendung für eine bestimmte Zeit (normalerweise 20 bis 60 Sekunden) nicht erreichen. Die Dauer wird durch folgende Faktoren beeinflusst:
- Häufigkeit der Integritätstests. Je häufiger die Integritätstests gesendet werden, desto schneller kann Front Door feststellen, dass ein Ursprung ausfällt oder wieder in den fehlerfreien Zustand zurückkehrt.
- Konfiguration des Stichprobenumfangs. Mit dieser Konfiguration wird gesteuert, wie viele Stichproben erforderlich sind, damit der Integritätstest feststellen kann, dass der primäre Ursprung nicht erreichbar ist. Wenn dieser Wert zu niedrig ist, erhalten Sie möglicherweise falsch positive Meldungen zu zeitweiligen Problemen.
Front Door ist eine potenzielle Fehlerquelle im System. Wenn beim Dienst ein Fehler auftritt, können Clients während der Ausfallzeit nicht auf Ihre Anwendung zugreifen. In der Vereinbarung zum Servicelevel (SLA) für Front Door erfahren Sie, ob Ihre geschäftlichen Anforderungen für Hochverfügbarkeit mit Front Door allein erfüllt werden. Wenn dies nicht der Fall ist, erwägen Sie als Alternative eine andere Verwaltungslösung für den Datenverkehr. Wenn der Front Door-Dienst fehlerhaft ist, ändern Sie die kanonischen Namensdatensätze (CNAME) im DNS, sodass sie auf die andere Verwaltungslösung für den Datenverkehr verweisen. Dieser Schritt muss manuell durchgeführt werden. Bis die DNS-Änderungen weitergegeben wurden, ist die Anwendung nicht verfügbar.
Die Standard- und die Premium-Ebene von Azure Front Door kombinieren Funktionen von Azure Front Door (klassisch), Azure CDN Standard von Microsoft (klassisch) und Azure WAF auf einer einzigen Plattform. Die Verwendung von Azure Front Door Standard oder Premium reduziert die Fehlerpunkte und ermöglicht eine verbesserte Kontrolle, Überwachung und Sicherheit. Weitere Informationen finden Sie unter Übersicht über die Azure Front Door-Dienstebenen.
SQL-Datenbank
Die Recovery Point Objective (RPO) und die Wiederherstellungszeitvorgabe (Recover Time Objective, RTO) für SQL-Datenbank sind in Übersicht über die Geschäftskontinuität mit Azure SQL-Datenbank dokumentiert.
Beachten Sie, dass die aktive Georeplikation die Kosten jeder replizierten Datenbank effektiv verdoppelt. Daher ist es normalerweise nicht empfehlenswert, Sandbox-, Test- und Entwicklungsdatenbanken zu replizieren.
Azure Cosmos DB
RPO und RTO (Recovery Time Objective) für Azure Cosmos DB können über die verwendeten Konsistenzebenen konfiguriert werden, die Kompromisse zwischen Verfügbarkeit, Datenbeständigkeit und Durchsatz bieten. Azure Cosmos DB bietet den RTO-Mindestwert 0 für eine gelockerte Konsistenzebene mit Multimaster oder den RPO-Wert 0 für hohe Konsistenz mit Einzelmaster. Weitere Informationen zu den Konsistenzebenen von Azure Cosmos DB finden Sie unter Konsistenzebenen und Datendauerhaftigkeit in Azure Cosmos DB.
Storage
RA-GRS-Speicher ermöglicht eine dauerhafte Speicherung. Wenn Sie ein Failover in Betracht ziehen, müssen aber die folgenden Faktoren berücksichtigt werden:
Rechnen Sie mit Datenverlusten: Die Datenreplikation zur sekundären Region wird asynchron ausgeführt. Wenn ein Geofailover ausgeführt wird, muss daher mit Datenverlusten gerechnet werden, wenn Änderungen am primären Konto nicht vollständig mit dem sekundären Konto synchronisiert wurden. Sie können anhand der Eigenschaft für den Zeitpunkt der letzten Synchronisierung des sekundären Speicherkontos feststellen, zu welcher Zeit Daten aus der primären Region zuletzt erfolgreich in die sekundäre Region geschrieben wurden.
Planen Sie die maximale Wiederherstellungszeit nach einem Ausfalle (Recovery Time Objective, RTO) entsprechend: Das Failover auf die sekundäre Region dauert in der Regel etwa eine Stunde. Daher sollte Ihr Notfallwiederherstellungsplan dies bei der Berechnung Ihrer RTO-Parameter berücksichtigen.
Planen Sie Ihr Failback sorgfältig: Sie müssen wissen, dass bei einem Failover eines Speicherkontos Daten im ursprünglichen primären Konto verloren gehen. Daher ist ein Failback auf die primäre Region ohne sorgfältige Planung riskant. Nach Abschluss des Failovers wird der neue primäre Speicher in der Failoverregion als lokal redundanter Speicher (LRS) konfiguriert. Sie müssen ihn manuell als georeplizierten Speicher neu konfigurieren, um die Replikation zur primären Region zu initiieren, und dann genügend Zeit für die Synchronisierung der Konten lassen.
Vorübergehende Fehler, etwa Netzwerkausfälle, lösen kein Speicherfailover aus. Entwerfen Sie Ihre Anwendung flexibel gegenüber vorübergehenden Fehlern. Beispiele für Risikominderungsoptionen:
- Lesen aus der sekundären Region.
- Wechseln Sie vorübergehend für neue Schreibvorgänge (z.B. in Warteschlangennachrichten) zu einem anderen Speicherkonto.
- Kopieren Sie Daten aus der sekundären Region in ein anderes Speicherkonto.
- Stellen Sie eine eingeschränkte Funktionalität bereit, bis das Failback für das System ausgeführt wurde.
Weitere Informationen finden Sie unter Vorgehensweise beim Ausfall von Azure Storage.
Überlegungen zur Verwendung der Objektreplikation für Blockblobs finden Sie in der Dokumentation zu Voraussetzungen und Einschränkungen für die Objektreplikation.
Azure Service Bus
Sie müssen wissen, dass das Feature für die georedundante Notfallwiederherstellung im Premium-Tarif für Azure Service Bus eine sofortige Kontinuität von Vorgängen mit derselben Konfiguration ermöglicht. Nachrichten in Warteschlangen, Themenabonnements oder Warteschlangen für unzustellbare Nachrichten werden jedoch nicht repliziert. Insofern ist eine geeignete Entschärfungsstrategie erforderlich, um ein reibungsloses Failover in die sekundäre Region sicherzustellen. Eine ausführliche Beschreibung anderer Überlegungen und Entschärfungsstrategien finden Sie in der Dokumentation zu wichtigen zu berücksichtigenden Punkten und zu Überlegungen zur Notfallwiederherstellung.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Eingehenden Datenverkehr einschränken: Konfigurieren Sie die Anwendung so, dass sie nur Datenverkehr von Front Door akzeptiert. So stellen Sie sicher, dass der gesamte Datenverkehr die Web Application Firewall (WAF) durchläuft, bevor er die App erreicht. Weitere Informationen finden Sie unter Wie kann ich den Zugriff auf mein Back-End nur auf Azure Front Door beschränken?
Cross-Origin Resource Sharing (CORS): Wenn Sie eine Website und eine Web-API als separate Anwendungen erstellen, kann die Website keine clientseitigen AJAX-Aufrufe an die API tätigen, es sei denn, Sie aktivieren CORS.
Hinweis
Die Browsersicherheit verhindert, dass eine Webseite AJAX-Anforderungen an eine andere Domäne richtet. Diese Einschränkung wird als Richtlinie des gleichen Ursprungs bezeichnet und verhindert, dass eine schädliche Website sensible Daten von einer anderen Website liest. CORS ist ein W3C-Standard, der einem Server eine weniger strenge Anwendung der Richtlinie des gleichen Ursprungs ermöglicht und einige Anforderungen zwischen verschiedenen Ursprüngen zulässt, während andere abgelehnt werden.
App Services verfügt über integrierte Unterstützung für CORS, ohne dass Anwendungscode geschrieben werden muss. Weitere Informationen finden Sie unter Nutzen einer API-App aus JavaScript mit CORS. Fügen Sie die Website zur Liste der zulässigen Ursprünge für die API hinzu.
SQL-Datenbankverschlüsselung: Verwenden Sie die transparente Datenverschlüsselung, wenn Sie Daten im Ruhezustand in der Datenbank verschlüsseln müssen. Dieses Feature führt eine Ver- und Entschlüsselung einer gesamten Datenbank (einschließlich Sicherungen und Transaktionsprotokolldateien) in Echtzeit durch und erfordert keine Änderungen an der Anwendung. Die Verschlüsselung führt zu höherer Latenz, und es empfiehlt sich daher, die Daten zu trennen, die in einer eigenen Datenbank gesichert werden müssen, und die Verschlüsselung nur für diese Datenbank zu aktiveren.
Identität: Wenn Sie Identitäten für die Komponenten in dieser Architektur definieren, verwenden Sie nach Möglichkeit vom System verwaltete Identitäten, um den Bedarf an der Verwaltung von Anmeldeinformationen und die damit verbundenen Risiken zu verringern. Wenn es nicht möglich ist, systemseitig verwaltete Identitäten zu verwenden, stellen Sie sicher, dass jede benutzerseitig verwaltete Identität nur in einer Region vorhanden ist und niemals über Regionsgrenzen hinweg gemeinsam genutzt wird.
Dienst-Firewalls: Stellen Sie bei der Konfiguration der Dienst-Firewalls für die Komponenten sicher, dass nur die regionslokalen Dienste Zugriff auf die Dienste haben und dass die Dienste nur ausgehende Verbindungen zulassen, was für die Replikation und die Anwendungsfunktionalität ausdrücklich erforderlich ist. Ziehen Sie die Verwendung von Azure Private Link für eine noch bessere Kontrolle und Segmentierung in Betracht. Weitere Informationen zum Sichern von Webanwendungen finden Sie unter Einrichten von Baselines für hochverfügbare, zonenredundante Webanwendungen.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Zwischenspeichern: Verwenden Sie das Zwischenspeichern, um die Belastung von Servern zu verringern, die Inhalte bereitstellen, die sich nicht häufig ändern. Jeder Renderzyklus einer Seite kann sich auf die Kosten auswirken, da er Compute, Arbeitsspeicher und Bandbreite beansprucht. Diese Kosten können mithilfe von Zwischenspeichern erheblich reduziert werden, insbesondere bei statischen Inhaltsdiensten wie z. B. bei einseitigen JavaScript-Apps und Medienstreaming-Inhalten.
Wenn Ihre App statische Inhalte aufweist, verwenden Sie CDN, um die Auslastung der Front-End-Server zu verringern. Verwenden Sie für Daten, die sich nicht häufig ändern, Azure Cache for Redis.
Zustand: Zustandslose Anwendungen, die für die automatische Skalierung konfiguriert sind, sind kostengünstiger als zustandsabhängige Anwendungen. Speichern Sie den Sitzungszustand für eine ASP.NET-Anwendung, die ihn nutzt, mit Azure Cache for Redis im Arbeitsspeicher. Weitere Informationen finden Sie unter ASP.NET-Sitzungszustandsanbieter für Azure Cache for Redis. Eine andere Möglichkeit besteht darin, Azure Cosmos DB über einen Sitzungszustandsanbieter als Back-End-Zustandsspeicher zu verwenden. Mehr dazu finden Sie unter Verwenden von Azure Cosmos DB als ASP.NET-Sitzungszustands- und Cacheanbieter.
Funktionen: Ziehen Sie in Erwägung, eine Funktions-App in einen dedizierten App Service-Plan aufzunehmen, damit Hintergrundaufgaben nicht auf denselben Instanzen laufen, die auch HTTP-Anforderungen bearbeiten. Werden Hintergrundaufgaben nur zeitweilig ausgeführt, empfiehlt sich die Nutzung eines Verbrauchstarifs. Bei diesem Tarif erfolgt die Abrechnung basierend auf der Anzahl der Ausführungen und genutzten Ressourcen und nicht auf Stundenbasis.
Weitere Informationen finden Sie im Microsoft Azure Well-Architected Framework unter Grundsätze der Kostenoptimierung.
Verwenden Sie den Preisrechner, um Ihre Kosten zu ermitteln. Die Empfehlungen in diesem Abschnitt helfen Ihnen dabei, die Kosten zu senken.
Azure Front Door
Die Azure Front Door-Abrechnung umfasst drei Tarife: ausgehende Datenübertragungen, eingehende Datenübertragungen und Routingregeln. Weitere Informationen finden Sie unter Azure Front Door – Preise. Die Preisübersicht beinhaltet keine Kosten für den Zugriff auf Daten aus den Ursprungsdiensten und die Übertragung an Front Door. Diese Kosten werden basierend auf den Gebühren für die Datenübertragung abgerechnet, wie unter Preisübersicht Bandbreite beschrieben.
Azure Cosmos DB
Es gibt zwei Faktoren, die die Preise für Azure Cosmos DB bestimmen:
Der bereitgestellte Durchsatz oder die Anforderungseinheiten pro Sekunde (RU/s)
Es gibt zwei Arten von Durchsatz, die in Azure Cosmos DB bereitgestellt werden können: Standard und Autoskalierung. Beim Standarddurchsatz werden die Ressourcen zugewiesen, die für die festgelegten RU/s erforderlich sind. Bei der Autoskalierung stellen Sie den maximalen Durchsatz bereit, und Azure Cosmos DB führt abhängig von der Auslastung sofort eine Hoch- oder Herunterskalierung durch, wobei mindestens 10 % des maximalen Durchsatz für die Autoskalierung genutzt werden. Der Standarddurchsatz wird stundenweise nach dem bereitgestellten Durchsatz in Rechnung gestellt. Der Durchsatz bei Autoskalierung wird stundenweise nach dem maximalen Durchsatz abgerechnet.
Speichernutzung. Für die Gesamtmenge des Speichers (GB), der für Daten und Indizes für eine bestimmte Stunde genutzt wird, wird eine Pauschale berechnet.
Weitere Informationen finden Sie im Abschnitt zu Kosten im Microsoft Azure Well-Architected Framework.
Effiziente Leistung
Ein großer Vorteil von Azure App Service ist die Möglichkeit, Ihre Anwendung abhängig von der Last zu skalieren. Hier sind einige Punkte aufgeführt, die beim Planen der Skalierung für Ihre Anwendung zu bedenken sind.
App Service-App
Wenn Ihre Lösung mehrere App Service-Apps enthält, sollten Sie deren Bereitstellung in separaten App Service-Plänen in Betracht ziehen. Dieser Ansatz ermöglicht es Ihnen, diese unabhängig voneinander zu skalieren, da sie auf separaten Instanzen ausgeführt werden.
SQL-Datenbank
Erhöhen Sie die Skalierbarkeit einer SQL-Datenbank durch Sharding der Datenbank. Sharding bezeichnet ein horizontales Partitionieren der Datenbank. Durch Sharding können Sie die Datenbank mithilfe von Tools für elastische Datenbanken aufskalieren. Sharding kann unter anderem folgende Vorteile bieten:
- Besserer Transaktionsdurchsatz
- Abfragen können schneller für eine Teilmenge der Daten ausgeführt werden
Azure Front Door
Front Door kann SSL-Vorgänge auslagern und reduziert zudem die Gesamtzahl von TCP-Verbindungen mit der Back-End-Web-App. Damit wird die Skalierbarkeit verbessert, weil die Web-App weniger SSL-Handshakes und TCP-Verbindungen verarbeitet. Diese Leistungssteigerungen werden auch dann erzielt, wenn Sie die Anforderungen als HTTPS an die Web-App weiterleiten, weil die Verbindungen in hohem Maß wiederverwendet werden.
Azure Search
Azure Search erspart den Aufwand komplexer Datensuchen aus dem primären Datenspeicher und ermöglicht eine Skalierung zur Handhabung von Lasten. Weitere Informationen finden Sie unter Skalieren von Ressourcenebenen für Abfrage und Indizierung von Workloads in Azure Search.
Erstklassige Betriebsprozesse
Mit erstklassige Betriebsprozesse sind die Betriebsprozesse gemeint, die eine Anwendung bereitstellen und für deren Ausführung in der Produktion sorgen. Sie sind eine Erweiterung des Leitfadens zur Zuverlässigkeit des Well-Architected Frameworks. Dieser Leitfaden bietet eine detaillierte Übersicht über die Architekturresilienz in Ihrem Anwendungsframework, um sicherzustellen, dass Ihre Workloads verfügbar sind und nach Ausfällen in jedem Ausmaß wiederhergestellt werden können. Ein Kerngrundsatz dieses Ansatzes besteht darin, Ihre Anwendungsinfrastruktur so zu entwerfen, dass sie hochverfügbar ist, optimalerweise in mehreren geografischen Regionen, wie dieser Entwurf veranschaulicht.
Nächste Schritte
Weitere Informationen finden Sie unter Unterschiedliche Methoden des Datenverkehrsroutings in Azure Front Door.
Erstellen Sie Integritätstest, die die allgemeine Integrität der Anwendung basierend auf Mustern für die Endpunktüberwachung melden.
Aktivieren Sie Azure SQL-Autofailover-Gruppen.
Sicherstellen von Geschäftskontinuität und Notfallwiederherstellung mit Azure-Regionspaaren
Zugehörige Ressourcen
Die n-schichtige Anwendung mit mehreren Regionen ist ein ähnliches Szenario. Es zeigt eine n-schichtige Anwendung, die in mehreren Azure-Regionen ausgeführt wird.