Leistung und Skalierbarkeit in Durable Functions (Azure Functions)
Um die Leistung und Skalierbarkeit zu optimieren, ist es wichtig die eindeutigen Merkmale von Durable Functions zu verstehen. In diesem Artikel wird erläutert, wie Worker basierend auf der Last skaliert werden und wie die verschiedenen Parameter optimiert werden können.
Workerskalierung
Ein grundlegender Vorteil des Aufgabenhubkonzepts besteht darin, dass die Anzahl der Worker, die Aufgabenhub-Arbeitselemente verarbeiten, kontinuierlich angepasst werden können. Insbesondere können Anwendungen weitere Worker hinzufügen (Aufskalierung), wenn die Aufgabe schneller verarbeitet werden muss, und Worker entfernen (Abskalierung), wenn nicht genügend Aufgaben vorhanden sind, um die Worker zu beschäftigen. Es ist sogar möglich, auf Null zu skalieren, wenn sich der Aufgabenhub vollständig im Leerlauf befindet. Wenn auf Null skaliert wird, gibt es überhaupt keine Worker. Nur der Skalierungscontroller und der Speicher müssen aktiv bleiben.
Dieses Konzept wird im folgenden Diagramm veranschaulicht:
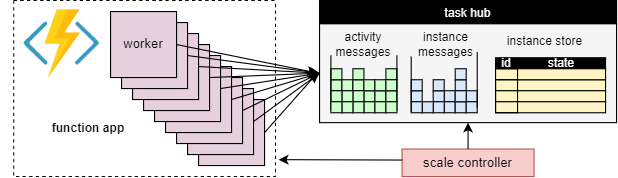
Autoskalierung
Wie bei allen Azure Functions-Vorgängen, die im Nutzungsplan oder Tarifen des Typs „Elastisch Premium“ ausgeführt werden, unterstützt Durable Functions die automatische Skalierung über den Azure Functions-Skalierungscontroller. Der Skalierungscontroller überwacht, wie lange Nachrichten und Tasks warten müssen, bevor sie verarbeitet werden. Basierend auf diesen Latenzen kann er entscheiden, ob Worker hinzugefügt oder entfernt werden sollen.
Hinweis
Ab Durable Functions 2.0 können Funktions-Apps so konfiguriert werden, dass Sie in VNET-geschützten Dienstendpunkten im Tarif „Elastisch Premium“ ausgeführt werden. In dieser Konfiguration initiieren die Durable Functions-Trigger Skalierungsanforderungen anstelle des Skalierungscontrollers. Weitere Informationen finden Sie unter Überwachung der Laufzeitskala.
Bei einem Premium-Plan kann automatische Skalierung dazu beitragen, die Anzahl der Worker (und damit die Betriebskosten) ungefähr proportional zur Last zu halten, der die Anwendung ausgesetzt ist.
CPU-Auslastung
Orchestratorfunktionen werden in einem einzelnen Thread ausgeführt, um sicherzustellen, dass die Ausführung in vielen Wiedergaben deterministisch sein kann. Aufgrund dieser Singlethreadausführung ist es wichtig, dass Orchestratorfunktionsthreads auf keinen Fall CPU-intensive Aufgaben, E/A-Vorgänge oder Blockierungsvorgänge ausführen. Alle Vorgänge, die möglicherweise E/A, die Blockierung oder mehrere Threads erfordern, sollten in die Aktivitätsfunktion verschoben werden.
Aktivitätsfunktionen weisen alle dasselbe Verhalten als reguläre, durch Warteschlangen ausgelöste Funktionen auf. Sie können problemlos E/A-Vorgänge und CPU-intensive Vorgänge ausführen sowie mehrere Threads verwenden. Da Aktivitätsauslöser zustandslos sind, können sie jederzeit auf eine unbegrenzte Anzahl von virtuellen Computern aufskaliert werden.
Entitätsfunktionen werden ebenfalls in einem einzelnen Thread ausgeführt, und Vorgänge werden nacheinander verarbeitet. Für Entitätsfunktionen gibt es jedoch keine Einschränkungen für den Typ des Codes, der ausgeführt werden kann.
Funktion-Timeouts
Für Aktivitäts-, Orchestrator- und Entitätsfunktionen gelten die gleichen Funktionstimeouts wie bei allen Azure-Funktionen. Funktionstimeouts werden von Durable Functions auf die gleiche Weise behandelt wie nicht behandelte Ausnahmen des Anwendungscodes.
Wenn etwa für eine Aktivität ein Timeout auftritt, wird die Funktionsausführung als nicht erfolgreich erfasst, der Orchestrator wird benachrichtigt, und das Timeout wird wie jede andere Ausnahme behandelt: Es werden Wiederholungen durchgeführt, wenn dies durch den Aufruf angegeben wird, oder ein Ausnahmehandler wird ausgeführt.
Batchverarbeitung von Entitätsvorgängen
Um die Leistung zu verbessern und Kosten zu verringern, kann ein einzelnes Arbeitselement einen gesamten Batch von Entitätsvorgängen ausführen. Bei Verbrauchsplänen wird jeder Batch dann als einzelne Funktionsausführung abgerechnet.
Standardmäßig liegt die maximale Batchgröße bei 50 (Verbrauchspläne) bzw. bei 5.000 (alle anderen Pläne). Die maximale Batchgröße kann in der Datei host.json konfiguriert werden. Wenn die maximale Batchgröße auf „1“ festgelegt wird, ist die Batchverarbeitung faktisch deaktiviert.
Hinweis
Wenn die Ausführung einzelner Entitätsvorgänge sehr lange dauert, empfiehlt es sich gegebenenfalls, die maximale Batchgröße zu begrenzen, um das Risiko von Funktionstimeouts zu verringern. Dies gilt insbesondere bei Verbrauchsplänen.
Zwischenspeicherung von Instanzen
Im Allgemeinen muss ein Worker die folgenden Aufgabenausführen, um ein Orchestrierungsarbeitselement zu verarbeiten:
- Abrufen des Orchestrierungsverlaufs.
- Wiedergeben des Orchestratorcodes mithilfe des Verlaufs.
Wenn derselbe Worker mehrere Arbeitselemente für dieselbe Orchestrierung verarbeitet, kann der Speicheranbieter diesen Prozess optimieren, indem der Verlauf im Arbeitsspeicher des Workers zwischengespeichert wird, wodurch der erste Schritt entfällt. Darüber hinaus kann er den Mittelausführungsorchestrator zwischenspeichern, wodurch auch der zweite Schritt entfällt: die Wiedergabe des Verlaufs.
Die typische Auswirkung des Zwischenspeicherns ist die Verringerung der E/A für den zugrunde liegenden Speicherdienst und eine allgemeine Verbesserung des Durchsatzes und der Latenz. Andererseits erhöht das Zwischenspeichern den Arbeitsspeicherverbrauch für den Worker.
Das Zwischenspeichern von Instanzen wird derzeit vom Azure Storage-Anbieter und vom Netherite-Speicheranbieter unterstützt. Die nachstehende Tabelle enthält einen Vergleich.
| Azure Storage-Anbieter | Netherite-Speicheranbieter | MSSQL-Speicheranbieter | |
|---|---|---|---|
| Zwischenspeicherung von Instanzen | Unterstützt (Nur .NET-In-Process-Worker) |
Unterstützt | Nicht unterstützt |
| Standardeinstellung | Disabled | Aktiviert | – |
| Mechanismus | Erweiterte Sitzungen | Instanzcache | – |
| Dokumentation | Siehe Erweiterte Sitzungen | Siehe Instanzcache | – |
Tipp
Zwischenspeicherung kann reduzieren, wie oft Verläufe wiedergegeben werden, aber sie kann die Wiedergabe nicht vollständig beseitigen. Bei der Entwicklung von Orchestratoren empfehlen wir dringend, diese in einer Konfiguration zu testen, die Zwischenspeicherung deaktiviert. Dieses erzwungene Wiedergabeverhalten kann nützlich sein, um Verstöße gegen die Einschränkungen des Orchestratorfunktionscodes zur Entwicklungszeit zu erkennen.
Zwischenspeicherungsmechanismen im Vergleich
Die Anbieter verwenden unterschiedliche Mechanismen zum Implementieren von Zwischenspeicherung und bieten verschiedene Parameter zum Konfigurieren des Zwischenspeicherverhaltens an.
- Erweiterte Sitzungen, die vom Azure Storage-Anbieter verwendet werden, behalten Mittelausführungsorchestratoren im Arbeitsspeicher bei, bis diese sich einige Zeit im Leerlauf befinden. Die Parameter zum Steuern dieses Mechanismus sind
extendedSessionsEnabledundextendedSessionIdleTimeoutInSeconds. Weitere Details finden Sie im Abschnitt Erweiterte Sitzungen der Dokumentation des Azure Storage-Anbieters.
Hinweis
Erweiterte Sitzungen werden nur vom .NET-In-Process-Prozess-Worker unterstützt.
- Der Instanzcache, der vom Netherite-Speicheranbieter verwendet wird, behält den Status aller Instanzen (einschließlich ihrer Verläufe) im Arbeitsspeicher des Workers bei, während er den verwendeten Gesamtspeicher nachverfolgt. Wenn die Cachegröße den von
InstanceCacheSizeMBkonfigurierten Grenzwert überschreitet, werden die ältesten verwendeten Instanzdaten entfernt. WennCacheOrchestrationCursorsauf TRUE festgelegt ist, speichert der Cache auch die Mittelausführungsorchestratoren zusammen mit dem Instanzstatus. Weitere Details finden Sie im Abschnitt Instanzcache der Dokumentation des Netherite-Speicheranbieters.
Hinweis
Instanzencaches funktionieren für alle Sprach-SDKs, die Option CacheOrchestrationCursors ist jedoch nur für den .NET-In-Process-Worker verfügbar.
Drosselungen der Parallelität
Eine einzelne Workerinstanz kann mehrere Arbeitselemente gleichzeitig ausführen. Dies trägt dazu bei, die Parallelität zu erhöhen und die Worker effizienter zu nutzen. Wenn ein Worker jedoch versucht, zu viele Arbeitselemente gleichzeitig zu verarbeiten, kann er seine verfügbaren Ressourcen erschöpfen, z. B. die CPU-Auslastung, die Anzahl der Netzwerkverbindungen oder den verfügbaren Arbeitsspeicher.
Um sicherzustellen, dass ein einzelner Worker nicht zu viele Aufgaben ausführt, kann es notwendig sein, die Parallelität pro Instanz zu drosseln. Durch das Einschränken der Anzahl der Funktionen, die gleichzeitig auf jedem Worker ausgeführt werden, können wir verhindern, dass die Ressourcenbeschränkungen für diesen Worker erschöpft werden.
Hinweis
Die Parallelitätsdrosselungen gelten nur lokal, um die aktuelle Verarbeitung pro Worker einzuschränken. Der Gesamtdurchsatz des Systems wird daher durch diese Drosselungen nicht eingeschränkt.
Tipp
In einigen Fällen kann die Drosselung der Parallelität pro-Worker tatsächlich den Gesamtdurchsatz des Systems erhöhen. Dies kann der Fall sein, wenn jeder Worker weniger Aufgaben übernimmt, sodass der Skalierungscontroller weitere Worker hinzufügt, um mit den Warteschlangen Schritt zu halten, was wiederum den Gesamtdurchsatz erhöht.
Konfiguration von Drosselungen
Parallelitätslimits für Aktivitäts-, Orchestrator- und Entitätsfunktionen können in der Datei host.json konfiguriert werden. Die relevanten Einstellungen sind durableTask/maxConcurrentActivityFunctions für Aktivitätsfunktionen und durableTask/maxConcurrentOrchestratorFunctions sowohl für Orchestrator- als auch für Entitätsfunktionen. Diese Einstellungen steuern die maximale Anzahl von Orchestrator-, Entitäts- oder Aktivitätsfunktionen, die in den Arbeitsspeicher auf einem einzelnen Worker geladen werden.
Hinweis
Orchestrierungen und Entitäten werden nur in den Arbeitsspeicher geladen, wenn sie aktiv Ereignisse oder Vorgänge verarbeiten oder wenn Instanzzwischenspeicherung aktiviert ist. Nachdem sie ihre Logik ausgeführt und gewartet haben (d. h. auf eine await- (C#) oder yield-Anweisung (JavaScript, Python) im Funktionscode des Orchestrators getroffen sind), können sie aus dem Speicher entladen werden. Orchestrierungen und Entitäten, die aus dem Arbeitsspeicher entladen werden, werden nicht auf die maxConcurrentOrchestratorFunctions-Drosselung angerechnet. Auch wenn Millionen von Orchestrierungen oder Entitäten den Status „Wird ausgeführt“ aufweisen, werden diese nur dann in Bezug auf die Drosselungsgrenze angerechnet, wenn sie in den aktiven Speicher geladen werden. Eine Orchestrierung, die eine Aktivitätsfunktion auf ähnliche Weise plant, zählt nicht zur Drosselung, wenn die Orchestrierung auf den Abschluss der Ausführung der Aktivität wartet.
Functions 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Sprachlaufzeitüberlegungen
Die von Ihnen ausgewählte Sprachlaufzeit kann strenge Parallelitätseinschränkungen oder Ihre Funktionen erzwingen. Beispielsweise unterstützen Durable Function-Apps, die in Python oder PowerShell geschrieben sind, nur die gleichzeitige Ausführung einer einzelnen Funktion auf einem einzelnen virtuellen Computer. Dies kann zu erheblichen Leistungsproblemen führen, wenn sie nicht sorgfältig berücksichtigt werden. Wenn z. B. ein Orchestrator auf 10 Aktivitäten auffächert, aber die Sprachlaufzeit die Gleichzeitigkeit auf nur eine Funktion beschränkt, dann bleiben 9 der 10 Aktivitätsfunktionen hängen und warten auf eine Gelegenheit zur Ausführung. Darüber hinaus kann für diese 9 hängen gebliebenen Aktivitäten kein Lastenausgleich für andere Arbeitsauslastungen ausgeführt werden, da die Durable Functions Laufzeit sie bereits in den Arbeitsspeicher geladen hat. Dies wird besonders problematisch, wenn die Aktivitätsfunktionen lange ausgeführt werden.
Wenn die von Ihnen verwendete Sprachlaufzeit eine Einschränkung der Parallelität vorsieht, sollten Sie die Durable Functions-Parallelitätseinstellungen so aktualisieren, dass sie mit den Parallelitätseinstellungen Ihrer Sprachlaufzeit übereinstimmen. Dadurch wird sichergestellt, dass die Durable Functions-Laufzeit nicht versucht, mehr Funktionen gleichzeitig auszuführen, als von der Sprachlaufzeit zugelassen wird, sodass für alle ausstehenden Aktivitäten ein Lastenausgleich auf andere virtuelle Computer möglich ist. Wenn Sie beispielsweise über eine Python-App verfügen, die die Parallelität auf 4 Funktionen einschränkt (möglicherweise nur mit 4 Threads in einem einzelnen Sprachworkerprozess oder 1 Thread in 4 Sprachworkerprozessen konfiguriert), sollten Sie sowohl maxConcurrentOrchestratorFunctions als auch maxConcurrentActivityFunctions mit dem Wert 4 konfigurieren.
Weitere Informationen und Leistungsempfehlungen für Python finden Sie unter Verbessern der Durchsatzleistung von Python-Apps in Azure Functions. Die in dieser Python-Entwicklerreferenzdokumentation erwähnten Techniken können erhebliche Auswirkungen auf die Durable Functions Leistung und Skalierbarkeit haben.
Partitionsanzahl
Einige der Speicheranbieter verwenden einen Partitionierungsmechanismus und ermöglichen das Angeben eines partitionCount-Parameters.
Bei Verwendung von Partitionierung konkurrieren Worker nicht direkt um einzelne Arbeitselemente. Stattdessen werden die Arbeitselemente zuerst in partitionCount-Partitionen gruppiert. Diese Partitionen werden dann Workern zugewiesen. Dieser partitionierte Ansatz zum Laden der Verteilung kann dazu beitragen, die Gesamtzahl der erforderlichen Speicherzugriffe zu verringern. Außerdem kann er Instanzspeicherung aktivieren und die Lokalität verbessern, da Affinität erschaffen wird: Alle Arbeitselemente für dieselbe Instanz werden von demselben Worker verarbeitet.
Hinweis
Partitionierungsgrenzwerte werden aufskaliert, weil partitionCount-Worker höchstens Arbeitselemente aus einer partitionierten Warteschlange verarbeiten können.
Die folgende Tabelle zeigt für jeden Speicheranbieter, welche Warteschlangen partitioniert werden, sowie die zulässigen Bereichs- und Standardwerte für den partitionCount-Parameter.
| Azure Storage-Anbieter | Netherite-Speicheranbieter | MSSQL-Speicheranbieter | |
|---|---|---|---|
| Instanznachrichten | Partitioned | Partitioned | Nicht partitioniert |
| Aktivitätsnachrichten | Nicht partitioniert | Partitioned | Nicht partitioniert |
Standardwert partitionCount |
4 | 12 | – |
Höchstwert partitionCount |
16 | 32 | – |
| Dokumentation | Siehe Horizontale Skalierung des Orchestrators | Siehe Überlegungen zur Partitionsanzahl | – |
Warnung
Die Partitionsanzahl kann nach dem Erstellen eines Aufgabenhubs nicht mehr geändert werden. Daher ist es ratsam, sie auf einen ausreichend großen Wert festzulegen, um zukünftige Aufskalierungsanforderungen für die Aufgabenhubinstanz zu erfüllen.
Konfiguration der Partitionsanzahl
Der partitionCount-Parameter kann in der Datei host.json angegeben werden. Mit dem folgenden Beispielcodeausschnitt in „host.json“ wird die durableTask/storageProvider/partitionCount-Eigenschaft (oder durableTask/partitionCount in Durable Functions 1.x) auf 3 festgelegt.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Überlegungen zur Minimierung der Aufruflatenz
Unter normalen Umständen sollten Aufrufanforderungen (für Aktivitäten, Orchestratoren, Entitäten usw.) ziemlich schnell verarbeitet werden. Es gibt jedoch keine Garantie für die maximale Latenz jeder Aufrufanforderung, da sie von Faktoren wie dem Typ des Skalierungsverhaltens, die Ihr App-Serviceplan, Ihre Parallelitätseinstellungen und die Größe des Anwendungsrückstands abhängt. Daher empfehlen wir, in Stresstests zu investieren, um die Taillatenz Ihrer Anwendung zu messen und zu optimieren.
Leistungsziele
Bei der Planung der Verwendung von Durable Functions für eine Produktionsanwendung müssen die Leistungsanforderungen frühzeitig im Planungsprozess berücksichtigt werden. Die grundlegenden Verwendungsszenarien sind:
- Sequenzielle Aktivitätsausführung: Dieses Szenario beschreibt eine Orchestratorfunktion, mit der nacheinander eine Reihe von Aktivitätsfunktionen ausgeführt wird. Am ehesten ähnelt es dem Beispiel zur Funktionsverkettung.
- Parallele Aktivitätsausführung: Dieses Szenario beschreibt eine Orchestratorfunktion, mit der mithilfe des Musters Auffächern nach außen/innen viele Aktivitätsfunktionen parallel ausgeführt werden.
- Parallele Antwortverarbeitung: Dieses Szenario stellt die zweite Hälfte des Musters Auffächern nach außen/innen dar. Es konzentriert sich auf die Leistung der Auffächerung nach innen. Es muss beachtet werden, dass im Unterschied zur Auffächerung nach außen die Auffächerung nach innen durch eine einzelne Orchestratorfunktionsinstanz erfolgt und daher nur auf einem einzelnen virtuellen Computer ausgeführt werden kann.
- Externe Ereignisverarbeitung: Dieses Szenario stellt eine einzelne Orchestratorfunktionsinstanz dar, die nacheinander auf externe Ereignisse wartet.
- Vorgangsverarbeitung durch Entität: In diesem Szenario wird getestet, wie schnell eine einzelneLeistungsindikatorentität einen konstanten Stream von Vorgängen verarbeiten kann.
Wir stellen Durchsatzwerte für diese Szenarien in der jeweiligen Dokumentation für den Speicheranbieter bereit. Dies gilt insbesondere für:
- Den Azure Storage-Anbieter, siehe Leistungsziele.
- Den Netherite-Speicheranbieter, siehe Grundlegende Szenarien.
- Den MSSQL-Speicheranbieter, siehe Benchmarks für den Orchestrierungsdurchsatz.
Tipp
Im Gegensatz zur Auffächerung nach außen sind Vorgänge zur Auffächerung nach innen auf einen einzelnen virtuellen Computer beschränkt. Wenn in Ihrer Anwendung das Muster „Auffächern nach außen/innen“ verwendet wird und Sie die Leistung im Hinblick auf die Auffächerung nach innen optimieren möchten, können Sie die Auffächerung der Aktivitätsfunktionen nach außen in mehrere untergeordnete Orchestrierungen unterteilen.