Übersicht über Pools für elastische Hyperscale-Datenbanken in Azure SQL-Datenbank
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Dieser Artikel bietet eine Übersicht über Pools für elastische Hyperscale-Datenbanken in Azure SQL-Datenbank.
Mit einem Pool für elastische Datenbanken in Azure SQL-Datenbank kann bei der SaaS-Entwicklung (Software-as-a-Service) das Preis-Leistungs-Verhältnis für eine Gruppe von Datenbanken im Rahmen eines vorgegebenen Budgets optimiert und gleichzeitig eine flexible Leistung für jede Datenbank sichergestellt werden. Pools für elastische Datenbanken von Azure SQL-Datenbank auf der Dienstebene „Hyperscale“ bieten ein neues Ressourcenmodell für Hyperscale-Datenbanken.
Beispiele zum Erstellen, Skalieren oder Verschieben von Datenbanken in einen Pool für elastische Hyperscale-Datenbanken mithilfe der Azure CLI oder von PowerShell finden Sie unter Arbeiten mit Pools für elastische Hyperscale-Datenbanken mithilfe von Befehlszeilentools.
Hinweis
Pools für elastische Hyperscale-Datenbanken befinden sich derzeit in der Vorschauphase.
Übersicht
Stellen Sie Ihre Hyperscale-Datenbank in einem Pool für elastische Datenbanken bereit, um Ressourcen zwischen Datenbanken innerhalb des Pools gemeinsam zu nutzen und die Kosten für mehrere Datenbanken mit unterschiedlichen Nutzungsmustern zu optimieren.
Szenarien für die Verwendung eines Pools für elastische Datenbanken mit Ihren Hyperscale-Datenbanken:
- Die Computeressourcen, die dem Pool für elastische Datenbanken zugeordnet sind, müssen unabhängig von der Menge des zugeordneten Speichers in einem vorhersehbaren Zeitraum hoch- oder herunterskaliert werden.
- Die Computeressourcen, die dem Pool für elastische Datenbanken zugeordnet sind, sollen durch Hinzufügen eines oder mehrerer Leseskalierungsreplikate aufskaliert werden.
- Sie möchten auch bei geringeren Computeressourcen einen hohen Transaktionsprotokolldurchsatz für schreibintensive Workloads verwenden.
Das Hinzufügen von Nicht-Hyperscale-Datenbanken zu einem Pool für elastische Hyperscale-Datenbanken konvertiert die Datenbanken in die Hyperscale-Serviceebene.
Aufbau
Traditionell besteht die Architektur einer eigenständigen Hyperscale-Datenbank im Wesentlichen aus drei unabhängigen Komponenten: Compute, Speicher („Seitenserver“) und Protokoll („Protokolldienst“). Wenn Sie einen Pool für elastische Datenbanken für Ihre Hyperscale-Datenbanken erstellen, werden Compute- und Protokollressourcen von den Datenbanken innerhalb des Pools gemeinsam genutzt. Wenn Sie sich zudem für die Konfiguration von Hochverfügbarkeit entscheiden, wird jeder Hochverfügbarkeitspool mit einem gleichwertigen und unabhängigen Satz von Compute- und Protokollressourcen erstellt.
Im Folgenden wird die Architektur eines Pools für elastische Hyperscale-Datenbanken beschrieben:
- Ein Pool für elastische Hyperscale-Datenbanken besteht aus einem primären Pool, in dem die primären Hyperscale-Datenbanken gehostet werden, und, falls konfiguriert, bis zu vier zusätzlichen Hochverfügbarkeitspools.
- Primäre Hyperscale-Datenbanken, die im primären Pool für elastische Datenbanken gehostet werden, nutzen den Computeprozess der SQL Server-Datenbank-Engine (sqlservr.exe), virtuelle Kerne, Arbeitsspeicher und SSD-Cache gemeinsam.
- Durch das Konfigurieren von Hochverfügbarkeit für den primären Pool werden zusätzliche Hochverfügbarkeitspools erstellt, die schreibgeschützte Datenbankreplikate für die Datenbanken im primären Pool enthalten. Jeder primäre Pool kann über maximal vier Pools mit Hochverfügbarkeitsreplikaten verfügen. In jedem Hochverfügbarkeitspool werden Compute-, SSD-Cache- und Arbeitsspeicherressourcen für alle sekundären schreibgeschützten Datenbanken im Pool gemeinsam verwendet.
- Hyperscale-Datenbanken im primären Pool für elastische Datenbanken nutzen alle denselben Protokolldienst. Da für Datenbanken in den Hochverfügbarkeitspools keine Schreibworkload vorliegt, verwenden sie den Protokolldienst nicht.
- Jede Hyperscale-Datenbank verfügt über eine eigene Menge an Seitenservern, und diese Seitenserver werden von der primären Datenbank im primären Pool und allen sekundären Replikatdatenbanken im Hochverfügbarkeitspool gemeinsam genutzt.
- Georeplizierte sekundäre Hyperscale-Datenbanken können in einen anderen Pool für elastische Datenbanken platziert werden.
- Wenn Sie in Ihrer Datenbankverbindungszeichenfolge
ApplicationIntent=ReadOnlyangeben, werden Sie an eine schreibgeschützte Replikatdatenbank in einem der Hochverfügbarkeitspools weitergeleitet.
Das folgende Diagramm zeigt die Architektur eines Pools für elastische Hyperscale-Datenbanken:
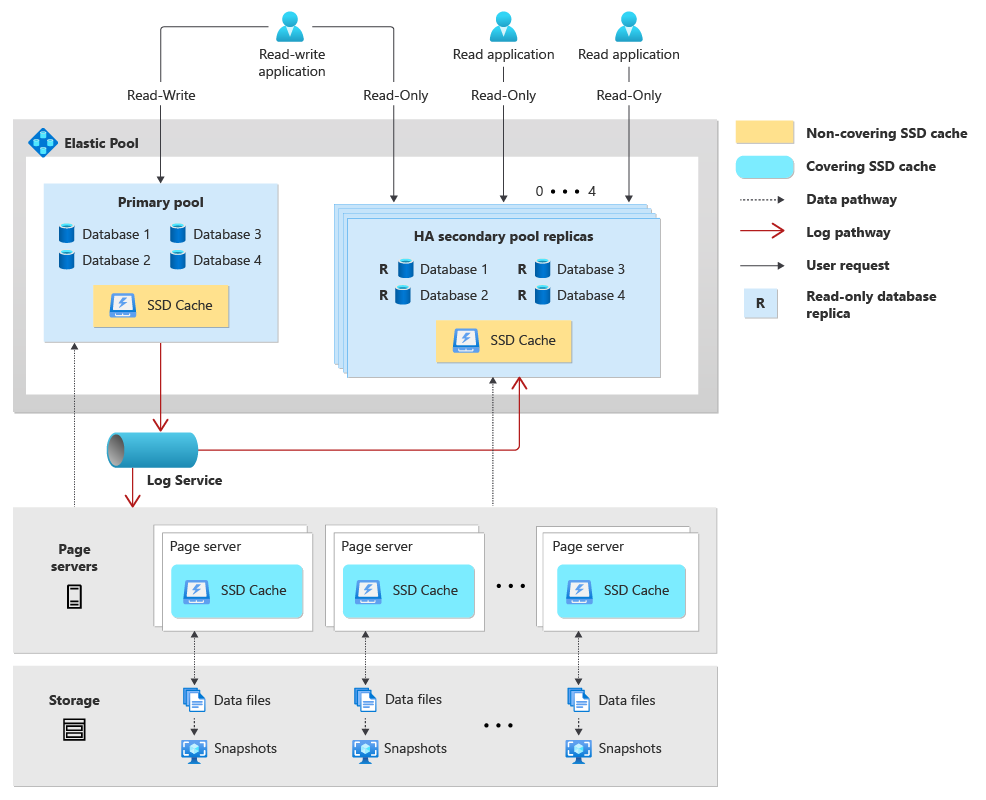
Verwalten von Datenbanken in einem Pool für elastische Hyperscale-Datenbanken
Sie können zum Verwalten von Hyperscale-Datenbanken in einem Pool dieselben Befehle verwenden wie für in einem Pool befindliche Datenbanken der anderen Dienstebenen. Stellen Sie sicher, dass Sie Hyperscale als Edition angeben, wenn Sie Ihren Pool für elastische Hyperscale-Datenbanken erstellen.
Der einzige Unterschied besteht in der Möglichkeit, die Anzahl von Hochverfügbarkeitsreplikaten in einem vorhandenen Pool für elastische Hyperscale-Datenbanken zu ändern. Gehen Sie folgendermaßen vor:
- Verwenden Sie den Parameter
HighAvailabilityReplicaCountdes Azure PowerShell-Befehls Set-AzSqlElasticPool. - Verwenden Sie den Parameter
--ha-replicasdes Azure CLI-Befehls az sql elastic-pool update.
Mithilfe der folgenden Clienttools können Sie Ihre Hyperscale-Datenbanken in einem Pool für elastische Datenbanken verwalten:
- Azure PowerShell: Az.Sql.3.11.0 oder höher. „AzureRM.Sql“ in PowerShell wird nicht unterstützt.
- Azure CLI: Az, Version 2.40.0 oder höher.
- Transact-SQL (T-SQL): ab SQL Server Management Studio (SSMS) v18.12.1 oder Azure Data Studio v1.39.1.
Konvertieren von Nicht-Hyperscale-Datenbanken zu elastischen Hyperscale-Pools
Beim Konvertieren einer Datenbank zu Hyperscale können Sie die Datenbank zu einem vorhandenen elastischen Hyperscale-Pool hinzufügen. Bei diesen Konvertierungen muss sich der elastische Hyperscale-Pool auf demselben logischen Server wie die Quelldatenbank befinden.
Beachten Sie bei der Konvertierung von Datenbanken zu elastischen Hyperscale-Pools die maximale Anzahl von Datenbanken pro elastischem Hyperscale-Pool.
Konvertieren von Nicht-Hyperscale-Datenbanken zu elastischen Hyperscale-Pools mit T-SQL
Sie können T-SQL-Befehle verwenden, um mehrere Allgemeine Datenbanken zu konvertieren und sie einem vorhandenen elastischen Hyperscale-Pool mit dem Namen hsep1 hinzufügen:
ALTER DATABASE gpepdb1 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb2 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb3 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
ALTER DATABASE gpepdb4 MODIFY (SERVICE_OBJECTIVE = ELASTIC_POOL(NAME = [hsep1]))
In diesem Beispiel fordern Sie implizit eine Konvertierung von General Purpose zu Hyperscale an, indem Sie angeben, dass es sich bei dem Ziel SERVICE_OBJECTIVE um einen elastischen Hyperscale-Pool handelt. Jeder der oben genannten Befehle beginnt mit der Konvertierung der jeweiligen Datenbank für allgemeine Zwecke zu Hyperscale. Diese ALTER DATABASE-Befehle kehren schnell zurück und warten nicht, bis die Konvertierung abgeschlossen ist. Im gezeigten Beispiel würden Sie vier solche Konvertierungen von General Purpose zu Hyperscale parallel ausführen.
Sie können die dynamische Verwaltungsansicht sys.dm_operation_status abfragen, um den Status dieser Hintergrundkonvertierungsvorgänge zu überwachen.
Konvertieren von Nicht-Hyperscale-Datenbanken zu elastischen Hyperscale-Pools mithilfe von PowerShell
Sie können PowerShell-Befehle verwenden, um mehrere Datenbanken mit allgemeinem Zweck zu konvertieren und sie einem vorhandenen elastischen Hyperscale-Pool mit dem Namen hsep1 hinzuzufügen. Das Beispielskript führt folgende Schritte aus:
- Verwenden Sie das Cmdlet Get-AzSqlElasticPoolDatabase, um alle Datenbanken im elastischen Pool „General Purpose“
gpep1aufzulisten. - Das Cmdlet
Where-Objectfiltert die Liste nur auf diese Datenbanknamen, beginnend mitgpepdb. - Für jede Datenbank startet das Cmdlet Set-AzSqlDatabase eine Konvertierung. In diesem Fall fordern Sie implizit eine Konvertierung zur Hyperscale-Dienstebene an, indem Sie den elastischen Hyperscale-Zielpool mit dem Namen
hsep1angeben.- Mit dem Parameter
-AsJobkönnen alle AnforderungenSet-AzSqlDatabaseparallel ausgeführt werden. Wenn Sie die Konvertierungen lieber einzeln ausführen möchten, können Sie den Parameter-AsJobentfernen.
- Mit dem Parameter
$dbs = Get-AzSqlElasticPoolDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -ElasticPoolName "gpep1"
$dbs | Where-Object { $_.DatabaseName -like "gpepdb*" } | % { Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "mylogicalserver" -DatabaseName ($_.DatabaseName) -ElasticPoolName "hsep1" -AsJob }
Zusätzlich zur dynamischen Verwaltungssicht sys.dm_operation_status können Sie das PowerShell-Cmdlet Get-AzSqlDatabaseActivity verwenden, um den Status dieser Hintergrundkonvertierungsvorgänge zu überwachen.
Ressourceneinschränkungen
Im Folgenden werden die unterstützten Grenzwerte für die Arbeit mit Hyperscale-Datenbanken in Pools für elastische Datenbanken aufgeführt:
- Unterstützte Hardware-Generierung: Standardserien (Gen5), Premium-Serie und optimierter Speicher der Premium-Serie.
- Maximum an virtuellen Kernen pro Pool: 80 oder 128 virtuelle Kerne, je nach Service-Level-Ziel.
- Maximal unterstützte Datenmenge pro Datenbank: 100 TB.
- Maximal unterstützte Gesamtdatenmenge für alle Datenbanken im Pool: 100 TB.
- Maximal unterstützter Transaktionsprotokolldurchsatz pro Datenbank: 100 MB.
- Maximal unterstützter Transaktionsprotokolldurchsatz insgesamt für alle Datenbanken im Pool: 131,25 MB/Sekunde.
- Jeder Pool für elastische Hyperscale-Datenbanken bis zu 25 Datenbanken enthalten.
Ausführlichere Informationen finden Sie in den Ressourcengrenzwerten für hyperskalige Pools Pool für elastische Datenbanken fürStandard-Serien, Premium-Serien und speicheroptimiert Premium-Serien.
Hinweis
Leistungsprofile, unterstützte Funktionen und veröffentlichte Grenzwerte können sich während der Vorschauphase des Features ändern. Daher ist es am besten, Ihren Anwendungsfall durch regelmäßige Funktions-, Leistungs- und Skalierungstests von Workloads zu überprüfen.
Begrenzungen
Beachten Sie die folgenden Einschränkungen:
- Das Ändern eines vorhandenen Pools für elastische Datenbanken ohne Hyperscale in die Hyperscale-Edition wird nicht unterstützt. Der Abschnitt „Konvertierung“ enthält einige Alternativen, die Sie verwenden können.
- Das Ändern der Edition eines Pools für elastische Hyperscale-Datenbanken in eine Nicht-Hyperscale-Edition wird nicht unterstützt.
- Um die Migration einer berechtigten Datenbank, die sich in einem Pool für elastische Hyperscale-Datenbanken befindet, rückgängig zu machen, muss diese zuerst aus dem Pool für elastische Hyperscale-Datenbanken entfernt werden. Die eigenständige Hyperscale-Datenbank kann dann wieder zu einer universellen eigenständigen Datenbank „zurück migriert werden“.
- Für die Hyperscale-Dienstebene kann die Zonenredundanzunterstützung nur während der Datenbank- oder elastischen Poolerstellung angegeben werden und kann nicht geändert werden, nachdem die Ressource bereitgestellt wurde. Weitere Informationen finden Sie unter Migrieren von Azure SQL Database zur Unterstützung von Verfügbarkeitszonen.
- Das Hinzufügen eines benannten Replikats in einem Hyperscale-Pool für elastische Datenbanken wird nicht unterstützt. Der Versuch, einem Pool für elastische Hyperscale-Datenbanken ein benanntes Replikat einer Hyperscale-Datenbank hinzuzufügen, führt zu einem
UnsupportedReplicationOperation-Fehler. Erstellen Sie stattdessen das benannte Replikat als einzelne Hyperscale-Datenbank.
Überlegungen zu zonenredundanten Pools für elastische Datenbanken
Im Folgenden finden Sie einige Überlegungen zu zonenredundanten Hyperscale Pools für elastische Datenbanken:
Hinweis
Zonenredundante Hyperscale Pools für elastische Datenbanken sind verfügbar, derzeit in der Vorschau. Weitere Informationen finden Sie im Blogbeitrag: Zonenredundante Hyperscale Pools für elastische Datenbanken.
- Nur Datenbanken mit zonenredundanten Speicherredundanz (ZRS oder GZRS) können zonenredundanten Hyperscale Pools für elastische Datenbanken hinzugefügt werden.
- Eine eigenständige Hyperscale-Datenbank muss mit Zonenredundanz und zonenredundantem Backup-Storage (ZRS oder GZRS) erstellt werden, um sie zu einem zonenredundanten Hyperscale Pool für elastische Datenbanken hinzuzufügen. Bei Hyperscale-Datenbanken ohne Zonenredundanz führen Sie einen Datentransfer zu einer neuen Hyperscale-Datenbank mit aktivierter Zonenredundanz-Option durch. Dabei muss ein Klon muss mit einer Datenbankkopie, einer Point-in-Time-Wiederherstellung oder einem Geo-Replikat erstellt werden. Weitere Informationen finden Sie unter Neueinteilung (Hyperscale).
- Um eine Hyperscale-Datenbank von einem Pool für elastische Datenbanken in einen anderen zu verschieben, müssen die Einstellungen für die Zonenredundanz und den zonenredundanten Sicherungsspeicher übereinstimmen.
- So konvertieren Sie eine Datenbank von einer anderen Nicht-Hyperscale-Serviceebene in einen zonenredundanten Hyperscale Pool für elastische Datenbanken:
- Aktivieren Sie zunächst über das Azure-Portal sowohl die Zonenredundanz als auch den zonenredundanten Backup-Speicher (Zone Redundant Backup Storage, ZRS). Dann können Sie die Datenbank zum zonenredundanten Hyperscale Pool für elastische Datenbanken hinzufügen.
- Aktivieren Sie zunächst über die PowerShell die Zonenredundanz. Stellen Sie dann mit Set-AzSqlDatabase sicher, dass der
-BackupStorageRedundancy-Parameter verwendet wird, um zonenredundanten Sicherungsspeicher (ZRS oder GZRS) anzugeben.
Bekannte Probleme
| Problem | Empfehlung |
|---|---|
| Wenn Sie sich den Abschnitt „Konfigurieren“ für einen vorhandenen Hyperscale-Pool für elastische Datenbanken im Azure-Portal ansehen, werden die geschätzten Preise in bestimmten Fällen unter Umständen nicht angezeigt. Die Ursache dieses Problem ist ein Codefehler. Bei Nicht-Hyperscale-Pools für elastische Datenbanken ist dieses Problem nicht festzustellen. | Durch Aktualisieren des Browsers oder Wechseln zum Abschnitt „Übersicht“ und dann wieder zurück zum Abschnitt „Konfigurieren“ kann das Problem behoben werden. |
Beim Hinzufügen einer Nicht-Hyperscale-Datenbank zu einem Hyperscale-Pool für elastische Datenbanken wird eventuell ein Fehler {"code":"ElasticPoolDatabaseCountOverLimit","message":"The elastic pool 'MyHyperscaleElasticPool' has reached its database count limit. The database count for the elastic pool cannot exceed (25) for service tier 'Hyperscale'."} angezeigt, obwohl es im Hyperscale-Pool für elastische Datenbanken weniger als 25 Datenbanken gibt. Die Ursache dieses Problem ist ein Codefehler. |
Zum Umgehen des Problems können Sie die Nicht-Hyperscale-Datenbank zuerst in eine eigenständige Hyperscale-Datenbank konvertieren, bevor Sie sie zum Hyperscale-Pool für elastische Datenbanken hinzufügen. |
Wenn Sie viele Nicht-Hyperscale-Datenbanken zu einem Hyperscale Pool für elastische Datenbanken hinzufügen, wird möglicherweise ein Fehler Could not perform the operation because server would exceed the allowed Database Throughput Unit quota of 54000. (Code: ServerDtuQuotaExceeded) angezeigt. Obwohl sich die Nachricht auf Datenbankdurchsatzeinheiten (DTU) bezieht, bezieht sie sich auf das freigegebene DTU/vCore-Kontingent, das auf jedem logischen Server erzwungen wird. Dieses Problem ist auf einen Fehler zurückzuführen, bei dem die virtuellen Kerne fälschlicherweise auf Ebene der einzelnen Datenbanken berechnet werden. |
Hier sind einige Optionen zum Umgehen des Problems: • Fügen Sie die Datenbanken nacheinander zu einem Hyperscale-Pool für elastische Datenbanken hinzu. • Konvertieren Sie die Datenbank zuerst in eine eigenständige Hyperscale-Datenbank, bevor Sie sie zum Hyperscale-Pool für elastische Datenbanken hinzufügen. • Fordern Sie eine Erhöhung des Kontingents auf Serverebene an, wie hier beschrieben. |
Das Einrichten derGeoreplikation für eine Datenbank aus einem zonenredundanten Hyperscale Pool für elastische Datenbanken in einem nicht zonenfremden redundanten Hyperscale Pool für elastische Datenbanken in einer anderen Region schlägt mit dem Fehler Provisioning of zone redundant Hyperscale database with local backup redundancy is not supported. Zone redundant Hyperscale databases must use either zone or geo zone backup redundancy fehl. Dieser Fehler tritt nicht auf, wenn der zweite Hyperscale Pool für elastische Datenbanken entweder zonenredundant ist oder sich in derselben Region befindet. |
Um dieses Problem zu umgehen, können Sie Azure PowerShell verwenden und in der Befehlszeile New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false explizit nicht zonenredundant angeben |
| Das Hinzufügen einer Datenbank aus einem zonenredundanten Hyperscale Pool für elastische Datenbanken zu einer Failovergruppe mit einem nicht zonenfremden redundanten Hyperscale Pool für elastische Datenbanken in einer anderen Region schlägt intern fehl, der Vorgang kann jedoch ohne Fortschritt ausgeführt werden. Möglicherweise wird die geo-sekundäre Datenbank angezeigt, wenn Sie Tools wie SSMS verwenden, aber Sie können keine Verbindung mit der geo-sekundären Datenbank herstellen und verwenden. Die Failovergruppe kann den Status „Seeding 0 %“ für die geo-sekundäre Datenbank anzeigen. Dieses Problem tritt nicht auf, wenn der zweite Hyperscale Pool für elastische Datenbanken zonenredundant ist. | Um dieses Problem zu umgehen, richten Sie die Georeplikation außerhalb der Failovergruppe mithilfe von Azure PowerShell ein und geben explizit nicht zonenredundant in der Befehlszeile New-AzSqlDatabaseSecondary -ResourceGroupName "primary-rg" -ServerName "primary-server" -DatabaseName "hsdb1" -PartnerResourceGroupName "secondary-rg" -PartnerServerName "secondary-server" -AllowConnections "All" -SecondaryElasticPoolName "secondary-nonzr-pool" -BackupStorageRedundancy Local -ZoneRedundant:$false an. Anschließend können Sie die Datenbank zur Failovergruppe hinzufügen. |
In seltenen Fällen erhalten Sie möglicherweise den Fehler 45122 - This Hyperscale database cannot be added into an elastic pool at this time. In case of any questions, please contact Microsoft support, wenn Sie versuchen, eine Hyperscale-Datenbank in einen Pool für elastische Datenbanken zu verschieben, wiederherzustellen oder zu kopieren. |
Diese Einschränkung ist auf implementierungsspezifische Details zurückzuführen. Wenn dieser Fehler Ihre Arbeit blockiert, erstellen Sie einen Supportincident aus, und fordern Sie Unterstützung an. |
Zugehöriger Inhalt
- Arbeiten mit Pools für elastische Hyperscale-Datenbanken mithilfe von Befehlszeilentools
- Pools für elastische Datenbanken – Preisgestaltung
- Skalieren von Ressourcen für Pools für elastische Datenbanken in Azure SQL-Datenbank
- Verwenden von PowerShell zum Überwachen und Skalieren eines Pools für elastische Datenbanken in Azure SQL-Datenbank
- Mandantenmuster für mehrinstanzenfähige SaaS-Datenbanken
- Einführung in eine mehrinstanzenfähige SaaS-App, die das Muster mit einer Datenbank pro Mandant mit Azure SQL-Datenbank verwendet
- Ressourcenverwaltung in umfangreichen Pools für elastische Datenbanken