Datenprodukte für Analysen auf Cloudebene in Azure
Datenprodukte werden als Produkt und berechnet, gespeichert und von Polyglot-Persistenzdiensten bereitgestellt, die von bestimmten Anwendungsfällen benötigt werden können. Der Prozess der Erstellung und Bereitstellung eines Datenprodukts kann Dienste und Technologien erfordern, die nicht in den Kerndiensten der Datenzielzone enthalten sind. Ein Beispiel hierfür wäre die Berichterstattung mit Nischenanforderungen, z. B. Compliance- und Steuerberichterstattung.
Überlegungen zum Entwurf
Eine Datenzielzone kann mit mehreren Datenprodukten versorgt werden, die durch die Aufnahme von Daten aus derselben Datenzielzone oder aus mehreren Datenzielzonen erstellt werden. Dies ist im folgenden Diagramm dargestellt:
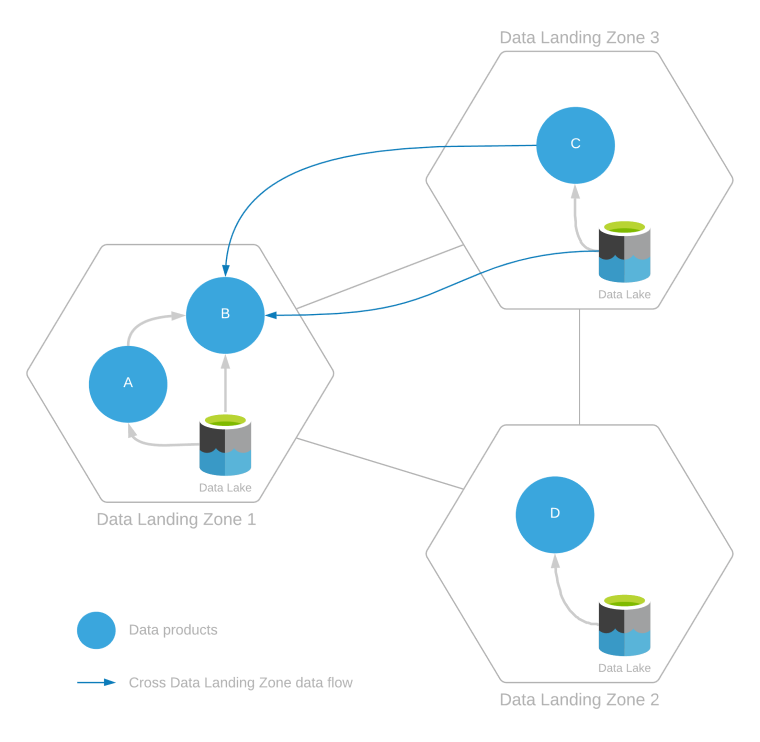
Das obige Beispiel zeigt Folgendes:
- Datennutzung innerhalb der Zone:
- Das Datenprodukt B verwendet Daten aus Datenprodukt A und anderen Daten oder Datenprodukten, die im Data Lake innerhalb einer eigenen Zielzone vorhanden sind.
- Die Datenprodukte C und D verbrauchen nur Daten innerhalb ihrer eigenen jeweiligen Datenzielzonen.
- Zonenübergreifende Datennutzung:
- Datenprodukt B nutzt auch Daten von Datenprodukt C und die Daten im Data Lake von Zielzone 3.
Wichtig
Da das Datenprodukt B durch Lesen aus der Datenzielzone 3 erstellt wird, muss dieser Lesezugriff von den Teams für Datenzielzonenbetrieb und Datenintegrationsbetrieb der Datenzielzone 3 genehmigt werden, wenn es sich um einen zonenübergreifenden Datenverbrauch handelt.
Wichtig
Datenprodukt B nutzt Daten aus Datenprodukt A und C. Bevor dies erfolgen kann ist, muss Datenprodukt B die Nutzung eines Datenprodukts über eine Datenfreigabevereinbarung registrieren. Diese Datenfreigabevereinbarung sollte die Datenherkunft von Datenprodukt A auf Datenprodukt B und von Datenprodukt C auf Datenprodukt B aktualisieren.
Die Ressourcengruppe für ein Datenprodukt umfasst alle Dienste, die zum Erstellen und Verwalten erforderlich sind. Wir können diese Ressourcengruppe als Datenanwendung aufrufen. Beispiele für Dienste, die Teil einer Datenanwendung sein können, sind Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL-Datenbank, Azure Database for MySQL und Azure Cosmos DB. Weitere Informationen finden Sie unter Datenanwendungsbeispiele.
Datenprodukte verfügen über Daten aus READ-Datenquellen, die einige Datentransformationen angewendet haben. Beispiele hierfür könnten ein neu kuratierter Datensatz oder ein BI-Bericht sein.
Entwurfsempfehlungen
Erstellen Sie Datenprodukte innerhalb Ihrer Datenzielzone, indem Sie sich an Designprinzipien halten, die Ihnen eine Skalierung mit Data Governance ermöglichen. In den folgenden Abschnitten werden Designempfehlungen bereitgestellt, die Ihnen beim Planen Ihres Datenanwendungsökosystems helfen.
Stellen Sie mehrere Ressourcengruppen bereit
Jede Datenanwendung ist eine Ressourcengruppe. Da es sich bei Datenanwendungen um Rechendienste, mehrsprachige Persistenzdienste oder beides handelt, können sie nur in bestimmten Anwendungsfällen erforderlich sein. Als solche werden sie als optionale Komponente der Datenzielzone betrachtet. In einem Fall, in dem Sie Datenanwendungen benötigen, erstellen Sie mehrere Ressourcengruppen nach Datenanwendung, wie das folgende Diagramm zeigt.

Legen Sie Schutzmaßnahmen fest
Azure Policy steuert die Standardkonfiguration von Diensten innerhalb einer Datenzielzone. Betrachten Sie operative Analysen als mehrere Ressourcengruppen, die Ihr Datenproduktteam aus einem Standarddienstkatalog anfordern kann. Mithilfe von Azure Policy können Sie die Sicherheitsgrenze und den erforderlichen Funktionssatz konfigurieren.
Wichtig
Um die Konsistenz zu fördern, konfigurieren Sie eine Azure Policy für jede Datenanwendung.
Verbrauchen Sie Daten von vielen Stellen
Datenanwendungen verwalten, organisieren und verwerten Daten aus verschiedenen Datenbeständen und präsentieren die gewonnenen Erkenntnisse. Ein Datenprodukt ist das Ergebnis von Daten aus einer oder mehreren Datenanwendungen innerhalb von Datenzielzonen. Erlauben Sie Ihren Datenanwendungen, bei Bedarf auf Daten aus mehreren und verschiedenen Quellen zuzugreifen.
Skalieren Sie nach Bedarf
Dienste, die Datenanwendungen bilden, sind inkrementelle Bereitstellungen für die Datenzielzone. Skalieren Sie Ihre Datenanwendungen nach Bedarf.
Aktivieren Sie die Datenermittlung
Registrieren Sie Ihre Datenprodukte automatisch in einem Datenkatalog, z. B. Azure Purview, um Daten scannen zu können.
Identifizieren Sie Ihre Datenprodukte
Identifizieren Sie während der Planung einer Datenzielzone möglichst viele Datenprodukte (und die Datenanwendungen, die sie ausgeben und verwalten), um ihre Datenproduktanwendungsarchitektur zu fördern. Die Konformität mit implementierter Plattformgovernance sollte in Ihren Entscheidungen die größte Rolle spielen.
Konzentrieren Sie sich auf die Funktionsweise Ihrer Datenanwendungen als Datenhersteller und Verbraucher für andere. Angenommen, Sie haben eine Reihe von Datenprodukten (A, B, C und D) identifiziert, die produziert und verbraucht werden. Sie benötigen Datenprodukte A und D als Quellen für die Daten in Data Application B für Das Datenprodukt B. Datenprodukt B wird aus den Daten erstellt, die Data Application B aus Datenprodukten A und D verwendet. Data Application B fungiert als Datenhersteller selbst und erzeugt auch Daten für Datenprodukt C.
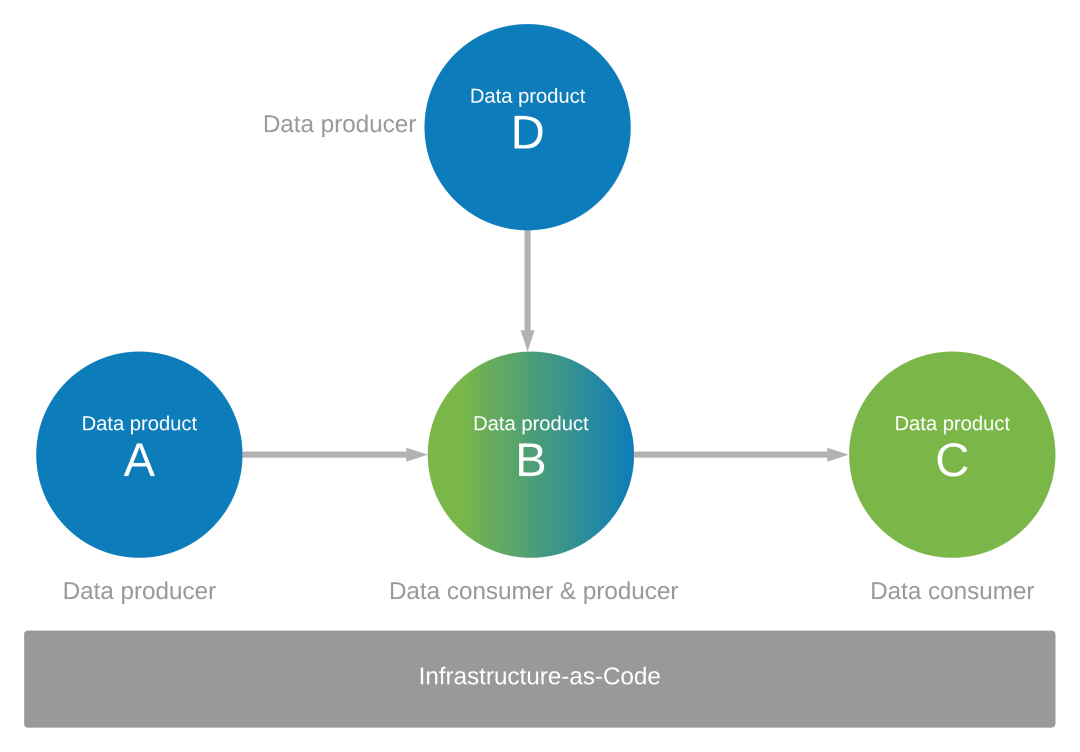
Steuern Ihrer Datenanwendungsumgebung mit Infrastruktur-as-Code
Governance und Infrastructure-as-Code sollten die Datenanwendungsumgebung im gesamten Ökosystem Ihrer Datenprodukte steuern, wie im vorherigen Diagramm dargestellt.
Veröffentlichen Sie die Datenmodellen
Ihre Datenproduktteams sollten ihre Datenmodelle in einem Modellierungsrepository veröffentlichen.
Legen Sie die Erwartungen für Datenproduktbenutzer fest
Aktualisieren Sie Ihre Datenfreigabeverträge mit Vereinbarungen auf Dienstebene und Zertifizierungen für Ihre Datenprodukte, sodass Sie genaue Erwartungen an potenzielle Benutzer des Datenprodukts vermitteln können.
Erfassungsherkunft
Wenn Datenprodukt B aus Daten, die aus Datenprodukten A und D stammen, erstellt wird, muss die Linienlinie von A und D bis B erfasst werden. Weitere Linien sollten auch für Datenprodukt C erfasst werden, da sie mithilfe von Daten aus Datenprodukt B erstellt wird. Aktualisierte Linien sollten in einer Datenlinienanwendung erfasst werden, bevor jedes Datenprodukt veröffentlicht wird.
Hinweis
Mit Azure Pipelines können Sie Genehmigungs-Gates erstellen und Funktionen aufrufen, die sicherstellen, dass Metadaten, Lineage und SLAs im richtigen Governance-Dienst registriert werden.
Definieren der Datenanwendungsarchitektur
Sie müssen eine detaillierte Architektur für jedes Datenprodukt erstellen, das seine Beziehung zu anderen Datenprodukten, seinen Abhängigkeiten und seinen Zugriffsanforderungen vollständig definiert.
Beispielentwurfsszenario
Um den Prozess der Architekturdefinition zu verstehen, schauen Sie sich das folgende Beispiel eines Finanzinstituts und dessen Datenprodukt zur Kreditüberwachung an.
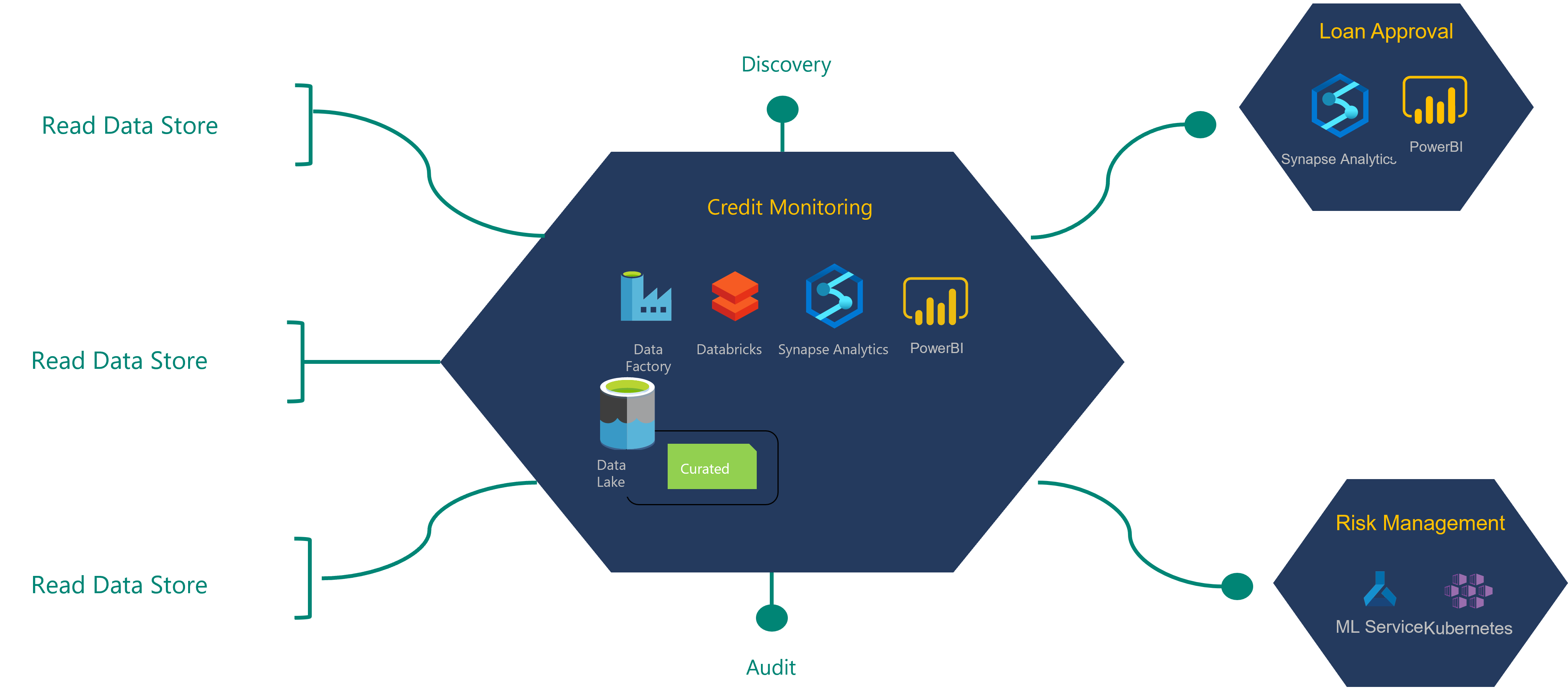
Das in diesem Diagramm gezeigte Kreditüberwachungsdatenprodukt nutzt Daten aus einem Lesedatenspeicher, der vom Integrationsteam eingelesen wurde. Es erzeugt auch Datenprodukte, die von zwei anderen Datenprodukten verbraucht werden.
Hinweis
Eine Lesedatenquelle oder -speicher wird auch als Golden Record Source bezeichnet. Diese Datenquellen wurden bereinigt, aber es wurden keine Transformationen auf sie angewendet.
Das Team für Kreditüberwachungsdaten beantragt Lesezugriff auf die Datenspeicher, die sie für die Erstellung ihres Datenprodukts benötigen. Ihre Anfragen werden zur Genehmigung an die Datenbesitzer weitergeleitet. Sobald sie eine Genehmigung erhalten, kann das Produktteam mit der Erstellung ihrer Datenanwendung beginnen.
Daten aus der Lesedatenquelle werden in das/die Datenprodukt(e) zur Kreditüberwachung transformiert. Alle neuen Datenprodukte werden in der kuratierten Ebene des Datensees gespeichert. Diese neuen Datenprodukte und die neue Datenabfolge sollten im Rahmen des DevOps-Bereitstellungsprozesses registriert werden. Eine Funktion kann registrierte Metadaten mit der physischen Struktur der Datenressource überprüfen. Sie sollte die Abhängigkeit von den Datenressourcen der Lesedatenquelle und Datenprodukten registrieren.
Das Produktteam für Kreditgenehmigungsdaten ist von einigen der Datenprodukte zur Kreditüberwachung abhängig. Das Kreditgenehmigungsteam kann Lesezugriff auf die Kreditüberwachungsdaten verlangen, die es für seine Datenprodukte benötigt. Sobald sie ihr Kreditgenehmigungsdatenprodukt und seine Datenanwendung freigeben, sollten alle Datenproduktressourcen, Linien und Modelle in den relevanten Governance-Diensten registriert werden.
Beispieldatenanwendungen
Die folgenden Abschnitte enthalten Beispieldatenanwendungen, um Datenanwendungsszenarien weiter zu veranschaulichen.
Datenanalyse- und Data Science-Datenanwendung
Eine Anwendung für Datenanalyse und Datenwissenschaft könnte die in der Beispieldatenanwendung product-analytics-rg gezeigten Dienste enthalten.

Hinweis
Sie können die vorherige Datenanwendung als Vorlage verwenden. Diese Vorlage stellt eine Reihe von Diensten bereit, die Sie für Datenanalysen und Data Science verwenden können. Anhand dieser Vorlage für Datenproduktanwendungen können Sie schnell Umgebungen für funktionsübergreifende Teams erstellen. Sie müssen alle Dienste, die Sie nicht benötigen, explizit deaktivieren.
Die Vorlage „Data Product Analytics“ enthält alle Vorlagen für die Bereitstellung eines Datenprodukts für Analysen und Datenwissenschaft innerhalb einer Cloud-Analyseszenario-Zielzone.
Die Bereitstellungs- und Codeartefakte umfassen die folgenden Dienste:
- Machine Learning
- Schlüsseltresor
- Application Insights
- Storage
- Containerregistrierung
- Cognitive Services (optional)
- Data Factory (Auswählen zwischen Data Factory und Synapse)
- Synapse Workspace (wählen Sie zwischen Data Factory und Synapse)
- Azure Search (optional)
- SQL Pool (optional)
- BigData-Pool (optional)
Batch-Datenanwendung
Die Vorlage „Batchdatenanwendung“ enthält alle Vorlagen für die Bereitstellung eines Datenprodukts für die Batchdatenverarbeitung in einer Cloud-Skalierungsanalyseszenario-Zielzone.
Die Bereitstellungs- und Codeartefakte umfassen die folgenden Dienste:

- Schlüsseltresor
- Data Factory (Auswählen zwischen Data Factory und Synapse)
- Azure Cosmos DB (optional)
- Synapse Workspace (wählen Sie zwischen Data Factory und Synapse)
- MySQL-Datenbank (optional)
- Azure SQL-Datenbank (optional)
- PostgreSQL-Datenbank (optional)
- MariaDB-Datenbank (optional)
- SQL Pool (optional)
- SQL Server (optional)
- SQL Pool für elastische Datenbanken (optional)
- BigData Pool
Streamingdatenanwendung
Die Vorlage „Streamingdatenanwendung“ enthält alle Vorlagen für die Bereitstellung eines Datenprodukts für die Echtzeitdatenverarbeitung in einer Cloud-Skalierungsanalyseszenario-Zielzone.
Die Bereitstellungs- und Codeartefakte umfassen die folgenden Dienste:

- Schlüsseltresor
- Event Hubs
- IoT Hub
- Stream Analytics (optional)
- Azure Cosmos DB (optional)
- Synapse-Arbeitsbereich
- Azure SQL-Datenbank (optional)
- SQL Pool (optional)
- SQL Server (optional)
- SQL Pool für elastische Datenbanken (optional)
- BigData Pool
- Data Explorer (optional)
Informationen zum Suchen der Repositorys mit den zuvor erwähnten Bereitstellungsvorlagen finden Sie in den Bereitstellungsvorlagen für Cloud-Skalierungsanalysen