Laden von Daten in Azure Data Lake Storage Gen2 mit Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Data Lake Storage Gen2 baut auf Azure Blob Storage auf und bietet eine Reihe von Funktionen für die Big Data-Analyse. Er ermöglicht Ihnen die Arbeit mit Ihren Daten über das Dateisystem und den Objektspeicher.
Azure Data Factory (ADF) ist ein vollständig verwalteter, cloudbasierter Datenintegrationsdienst. Mithilfe dieses Diensts können Sie den Lake mit Daten aus zahlreichen lokalen und cloudbasierten Datenspeichern füllen und Zeit beim Erstellen von Analyselösungen sparen. Eine ausführliche Liste der unterstützten Connectors finden Sie in der Tabelle Unterstützte Datenspeicher.
Azure Data Factory bietet eine Lösung zur horizontalen Skalierung und Verschiebung verwalteter Daten. Aufgrund der horizontal skalierbaren Architektur von ADF können Daten mit hohem Durchsatz erfasst werden. Weitere Informationen finden Sie unter Leistung der Kopieraktivität.
In diesem Artikel erfahren Sie, wie Sie das Tool zum Kopieren von Daten in Data Factory zum Laden von Daten aus Amazon Web Services S3 in Azure Data Lake Storage Gen2 verwenden. Sie können ähnliche Schritte zum Kopieren von Daten aus anderen Typen von Datenspeichern ausführen.
Tipp
Informationen zum Kopieren von Daten aus Azure Data Lake Storage Gen1 nach Gen2 finden Sie in dieser exemplarischen Vorgehensweise.
Voraussetzungen
- Azure-Abonnement: Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Azure Storage-Konto mit aktiviertem Data Lake Storage Gen2: Erstellen Sie ein Speicherkonto, wenn Sie noch keines besitzen.
- AWS-Konto mit einem S3-Bereich, der Daten enthält: Dieser Artikel zeigt, wie Daten aus Amazon S3 kopiert werden. Sie können andere Datenspeicher verwenden, indem Sie ähnliche Schritte ausführen.
Erstellen einer Data Factory
Wenn Sie Ihre Data Factory noch nicht erstellt haben, befolgen Sie die Schritte im Schnellstart: Erstellen einer Data Factory mithilfe des Azure-Portals und Azure Data Factory Studio, um eine zu erstellen. Navigieren Sie nach dem Erstellen zur Data Factory im Azure-Portal.

Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Datenintegrationsanwendung in einer separaten Registerkarte zu starten.
Laden von Daten in Azure Data Lake Storage Gen2
Wählen Sie auf der Homepage von Azure Data Factory die Kachel Erfassung aus, um das Tool „Daten kopieren“ zu starten.
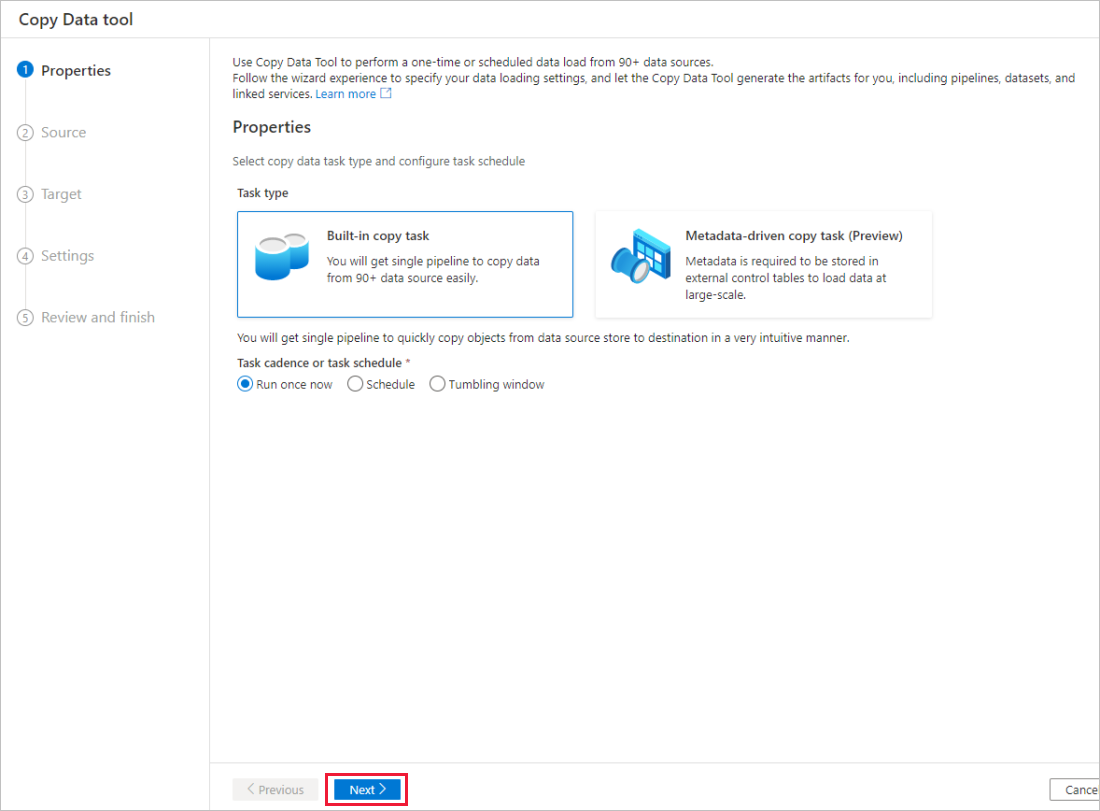
Navigieren Sie zu der Seite Eigenschaften und wählen Sie die Option Integrierte Kopieraufgabe unter dem Aufgabentyp aus. Wählen Sie nun unter Aufgabenintervall oder Aufgabenzeitplan die Option Jetzt einmal ausführen und klicken Sie dann auf Weiter.
Führen Sie auf der Seite Quelldatenspeicher die folgenden Schritte aus:
Wählen Sie + Neue Verbindung aus. Wählen Sie im Connectorkatalog Amazon S3 aus, und klicken Sie auf Weiter.

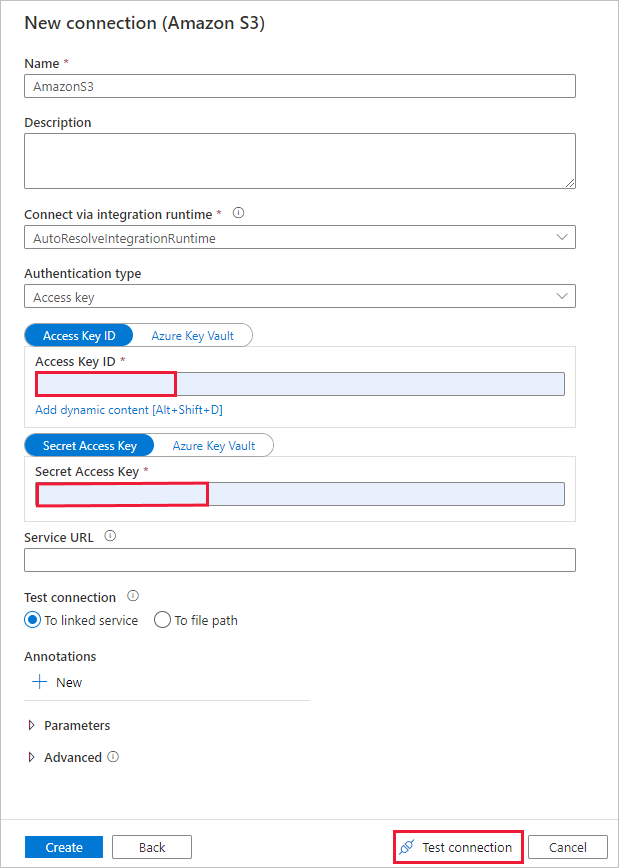
Führen Sie auf der Seite Neue Verbindung (Amazon S3) die folgenden Schritte aus:
- Geben Sie den Wert für die Zugriffsschlüssel-ID an.
- Geben Sie den Wert für den geheimen Zugriffsschlüssel an.
- Wählen Sie Verbindung testen aus, um die Einstellungen zu überprüfen. Wählen Sie dann Erstellen aus.
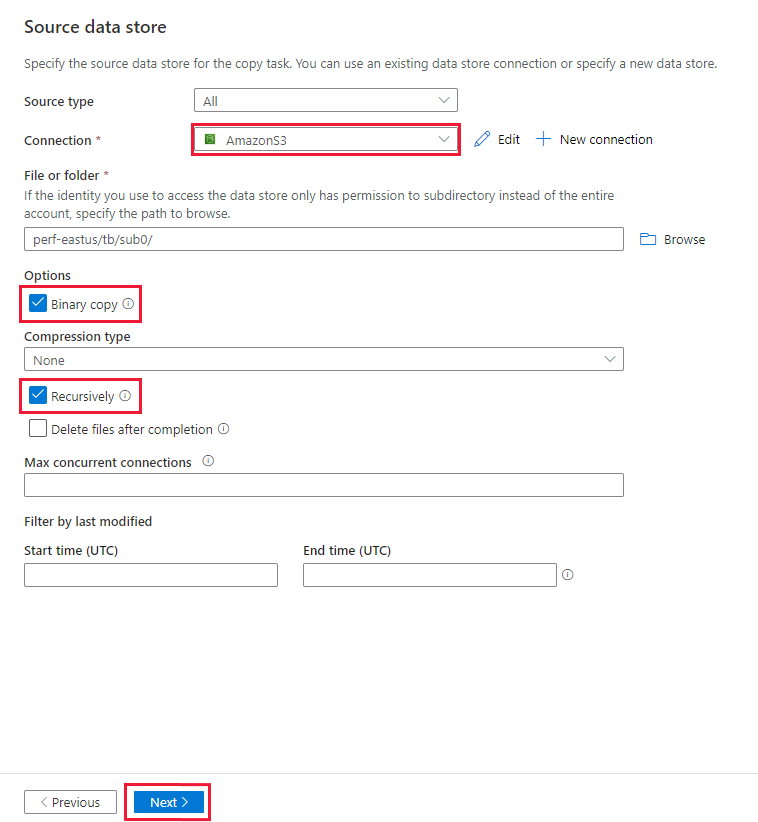
Stellen Sie auf der Seite Quelldatenspeicher sicher, dass die neu erstellte Amazon 3-Verbindung in dem Verbindungsblock ausgewählt ist.
Navigieren Sie auf der Seite Datei oder Ordner zu dem Ordner und der Datei, die Sie kopieren möchten. Wählen Sie den Ordner / die Datei und dann OK aus.
Geben Sie das Kopierverhalten an, indem Sie die Optionen Rekursiv und Binärkopie aktivieren. Wählen Sie Weiter aus.
Führen Sie auf der Seite Zieldatenspeicher die folgenden Schritte aus.
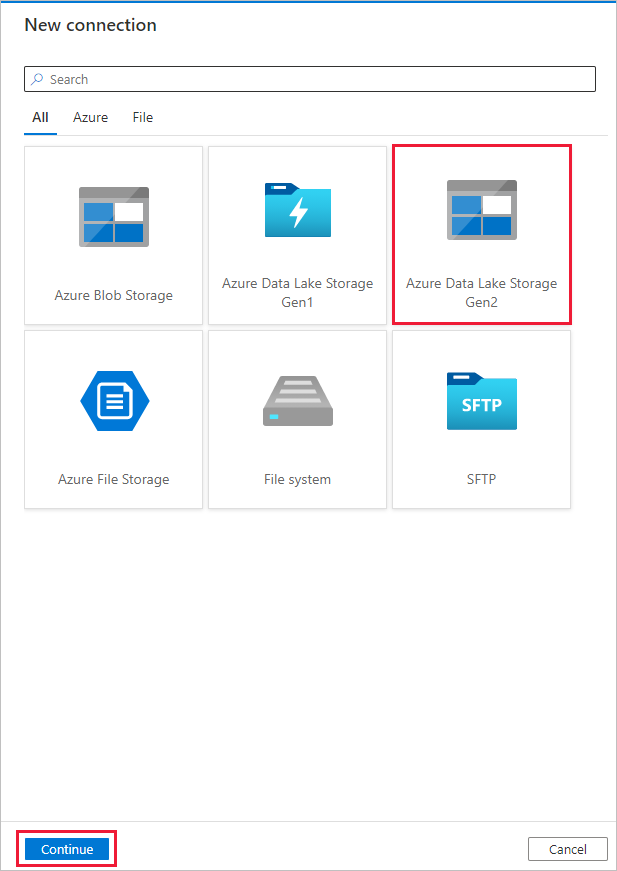
Wählen Sie + Neue Verbindung und dann Azure Data Lake Storage Gen2 aus. Klicken Sie anschließend auf Weiter.
Wählen Sie auf der Seite Neue Verbindung (Azure Data Lake Storage Gen2) Ihr Data Lake Storage Gen2-fähiges Konto aus der Dropdown-Liste „Name des Speicherkontos“ aus und wählen Sie dann Erstellen, um die Verbindung zu erstellen.
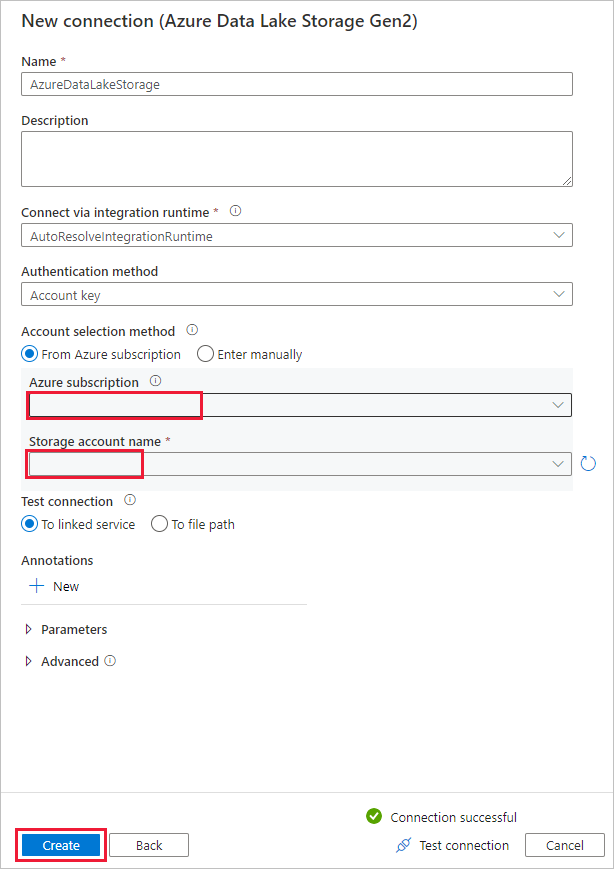
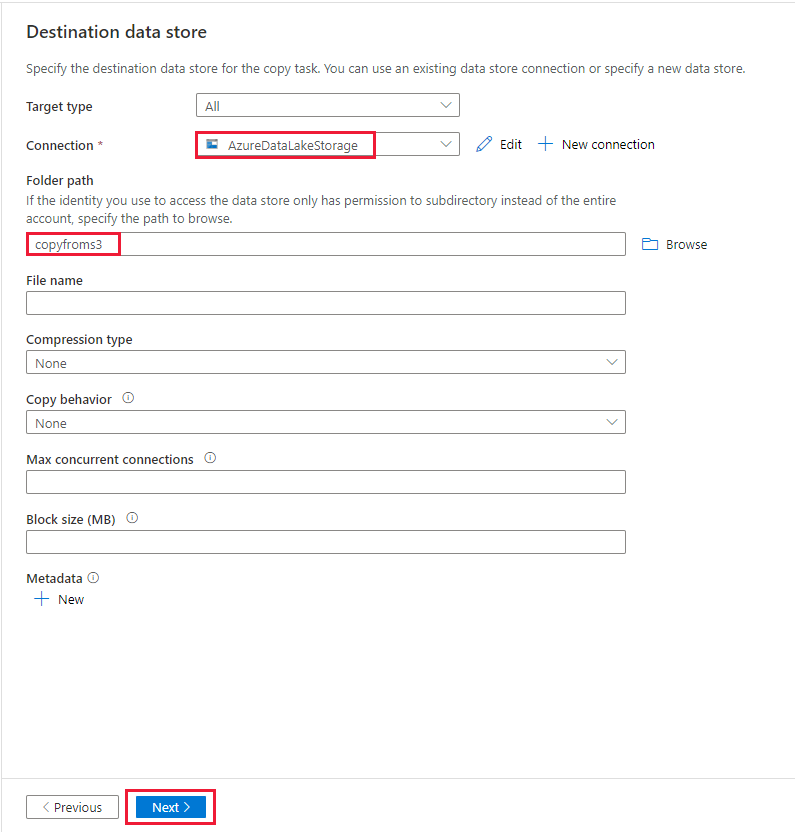
Wählen Sie auf der Seite Zieldatenspeicher die neu erstellte Verbindung in dem Block Verbindung aus. Geben Sie dann unter Ordnerpfad die Zeichenfolge copyfroms3 als Name für den Ausgabeordner ein, und klicken Sie dann auf Weiter. Die ADF erstellt das entsprechende ADLS Gen2-Dateisystem und die Unterordner während des Kopierens, wenn diese noch nicht existieren.
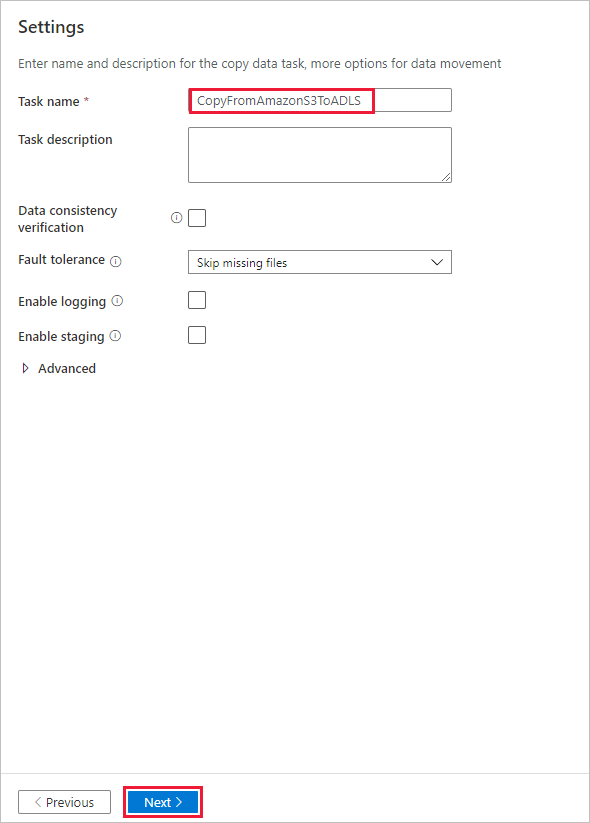
Geben Sie auf der Seite Einstellungen im Feld Aufgabenname den Namen CopyFromAmazonS3ToADLS ein und klicken Sie dann auf Weiter.
Überprüfen Sie auf der Seite Zusammenfassung die Einstellungen, und klicken Sie dann auf Weiter.

Klicken Sie auf der Seite Bereitstellung auf Überwachen, um die Pipeline (Task) zu überwachen.
Wenn die Pipelineausführung erfolgreich abgeschlossen ist, sehen Sie eine Pipelineausführung, die durch einen manuellen Trigger ausgelöst wird. Über die Links in der Spalte Name der Pipeline können Sie die Aktivitätsdetails anzeigen und die Pipeline erneut ausführen.
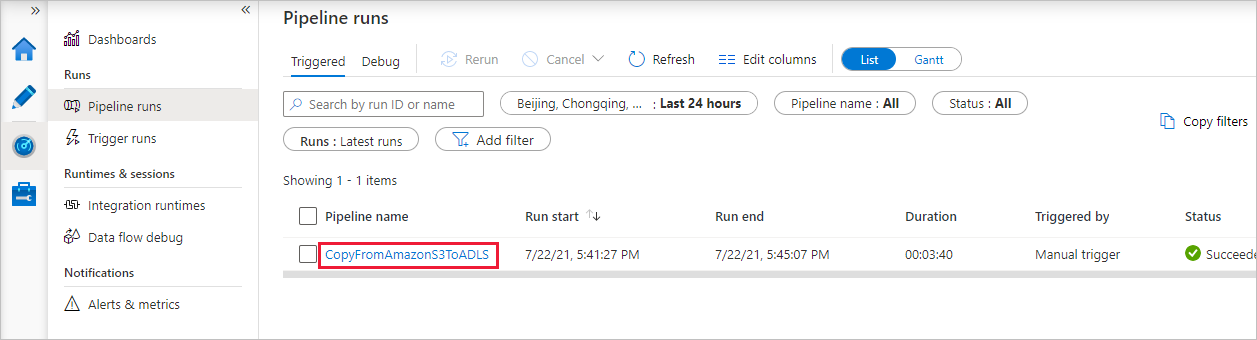
Um die der Pipelineausführung zugeordneten Aktivitätsausführungen anzuzeigen, wählen Sie in der Spalte Name der Pipeline den Link CopyFromAmazonS3ToADLS aus. Wenn Sie Details zum Kopiervorgang anzeigen möchten, wählen Sie unter der Spalte Activity name (Aktivitätsname) den Link Details (das Brillensymbol) aus. Sie können Details wie die Menge der Daten, die aus der Quelle in die Senke kopiert wurden, den Datendurchsatz, die Ausführungsschritte mit entsprechender Dauer sowie die verwendete Konfiguration überwachen.
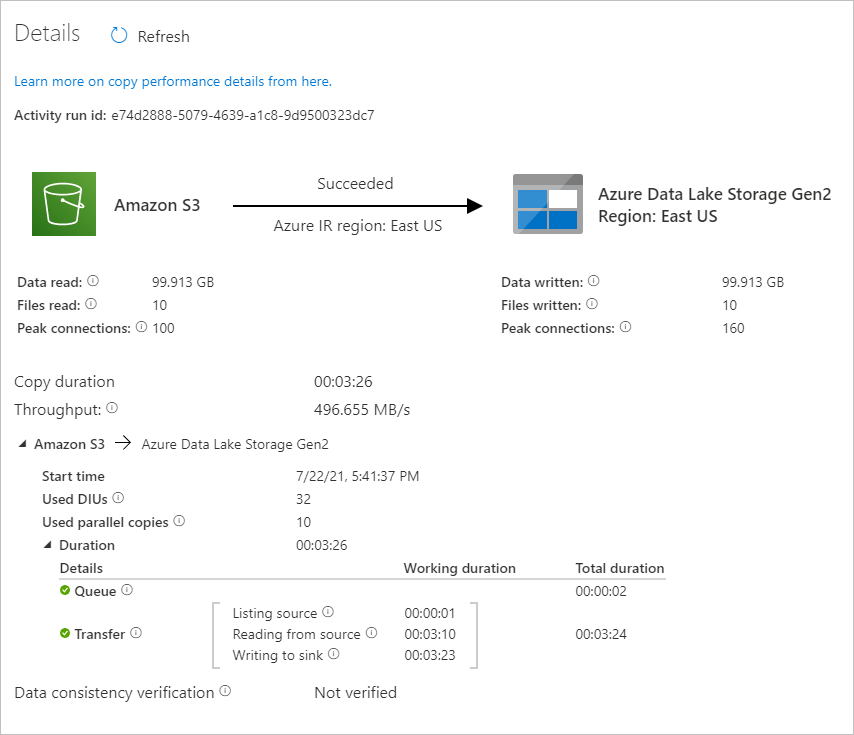
Klicken Sie zum Aktualisieren der Ansicht auf Aktualisieren. Wählen Sie oben Alle Pipelineausführungen aus, um zurück zur Ansicht mit den „Pipelineausführungen“ zu wechseln.
Stellen Sie sicher, dass die Daten in Ihr Data Lake Storage Gen2-Konto kopiert werden.