RAG (Retrieval Augmented Generation) in Azure Databricks
Wichtig
Dieses Feature befindet sich in der Public Preview.
Agent Framework umfasst eine Reihe von Tools für Databricks, die Entwicklern beim Erstellen, Bereitstellen und Bewerten von Produktionsqualitäts-KI-Agenten wie Retrieval Augmented Generation (RAG)-Anwendungen helfen sollen.
Dieser Artikel befasst sich mit dem RAG und den Vorteilen der Entwicklung von RAG-Anwendungen auf Azure Databricks.
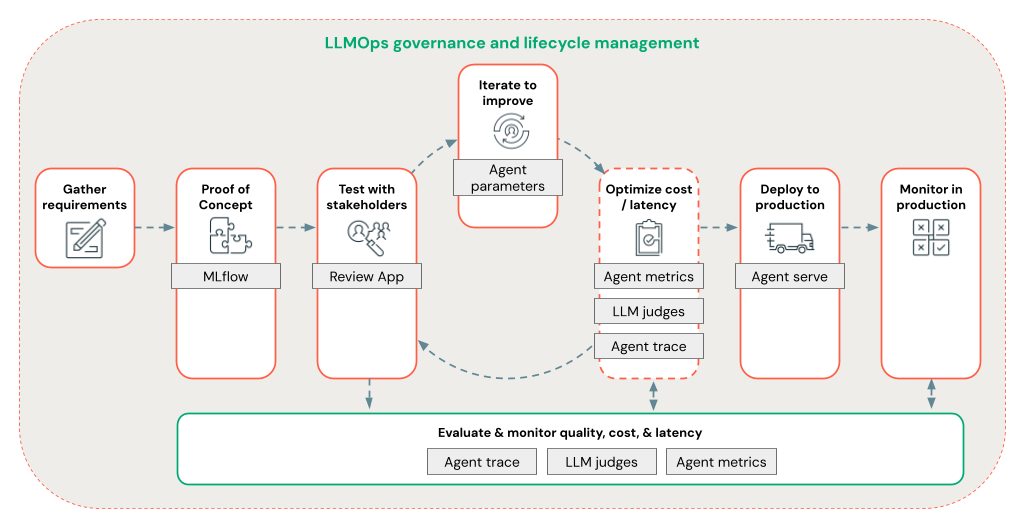
Mit Agent Framework können Entwickler schnell alle Aspekte der RAG-Entwicklung mithilfe eines End-to-End-LLMOps-Workflows durchlaufen.
Anforderungen
- Azure KI-gesteuerte KI-Hilfsfunktionen müssen für Ihren Arbeitsbereich aktiviert sein.
- Alle Komponenten einer Agentenanwendung müssen sich in einem einzigen Arbeitsbereich befindet. Beispielsweise müssen sich das Bereitstellungsmodell und die Vektorsuchinstanz im Falle einer RAG-Anwendung im selben Arbeitsbereich befinden.
Was ist RAG?
RAG ist eine generative KI-Designtechnik, die große Sprachmodelle (LLM) mit externen Kenntnissen verbessert. Diese Technik verbessert LLMs auf folgende Weise:
- Proprietäres Wissen: RAG kann proprietäre Informationen enthalten, die ursprünglich nicht zum Trainieren der LLM verwendet werden, z. B. Memos, E-Mails und Dokumente, um domänenspezifische Fragen zu beantworten.
- Aktuelle Informationen: Eine RAG-Anwendung kann die LLM mit Informationen aus aktualisierten Datenquellen bereitstellen.
- Quellen zitieren: RAG ermöglicht es LLMs, bestimmte Quellen zu zitieren, sodass Benutzer die tatsächliche Genauigkeit der Antworten überprüfen können.
- Datenquellensicherheits- und Zugriffssteuerungslisten (Access Control Lists, ACL): Der Abrufschritt kann so konzipiert werden, dass persönliche oder proprietäre Informationen basierend auf Benutzeranmeldeinformationen selektiv abgerufen werden.
Zusammengesetzte KI-Systeme
Eine RAG-Anwendung ist ein Beispiel für ein zusammengesetztes KI-System: Sie erweitert die Sprachfunktionen des LLM, indem sie mit anderen Tools und Verfahren kombiniert wird.
In der einfachsten Form führt eine RAG-Anwendung folgende Aktionen aus:
- Abrufen: Die Anforderung des Benutzers wird verwendet, um einen externen Datenspeicher abzufragen, z. B. einen Vektorspeicher, eine Textstichwortsuche oder eine SQL-Datenbank. Ziel ist es, unterstützende Daten für die Antwort des LLM zu erhalten.
- Augmentation: Die abgerufenen Daten werden mit der Anforderung des Benutzers kombiniert, häufig mithilfe einer Vorlage mit zusätzlicher Formatierung und Anweisungen, um eine Eingabeaufforderung zu erstellen.
- Generation: Die Eingabeaufforderung wird an die LLM übergeben, die dann eine Antwort auf die Abfrage generiert.
Unstrukturierte vs. strukturierte RAG-Daten
Die RAG-Architektur kann entweder mit unstrukturierten oder strukturierten unterstützenden Daten arbeiten. Die Daten, die Sie mit RAG verwenden, hängen von Ihrem Anwendungsfall ab.
Unstrukturierte Daten: Daten ohne eine bestimmte Struktur oder Organisation. Dokumente, die Text und Bilder oder Multimediainhalte wie Audio oder Videos enthalten.
- PDFs
- Google/Office-Dokumente
- Wikis
- Bilder
- Videos
Strukturierte Daten: Tabellendaten, die in Zeilen und Spalten mit einem bestimmten Schema angeordnet sind, z. B. Tabellen in einer Datenbank.
- Kundendatensätze in einem BI- oder Data Warehouse-System
- Transaktionsdaten aus einer SQL-Datenbank
- Daten aus Anwendungs-APIs (z. B. SAP, Salesforce usw.)
In den folgenden Abschnitten wird eine RAG-Anwendung für unstrukturierte Daten beschrieben.
RAG-Datenpipeline
Die RAG-Datenpipeline verarbeitet und indiziert Dokumente zum schnellen und genauen Abruf.
Das folgende Diagramm zeigt eine Beispieldatenpipeline für ein unstrukturiertes Dataset mithilfe eines semantischen Suchalgorithmus. Alle Schritte werden mit Databricks-Aufträgen orchestriert.
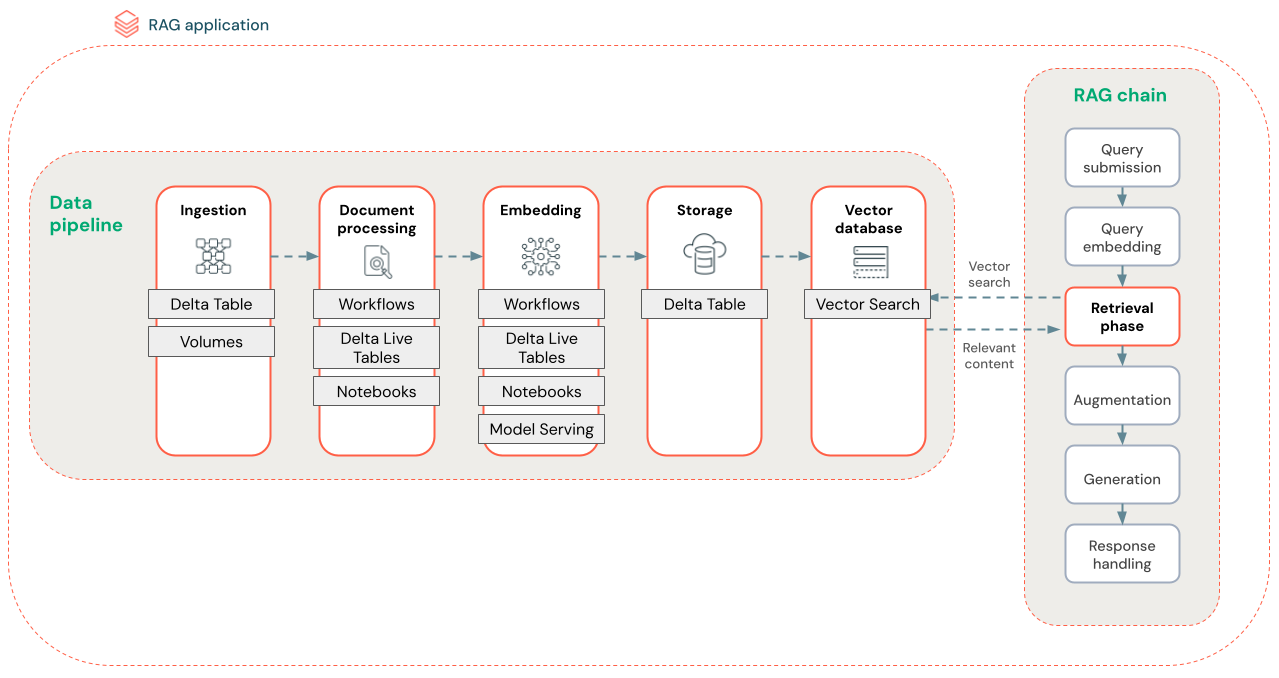
- Datenerfassung – Aufnehmen von Daten aus Ihrer proprietären Quelle. Speichern Sie diese Daten in einer Delta-Tabelle oder auf einem Unity Catalog-Volume.
- Dokumentenverarbeitung: Sie können diese Aufgaben mithilfe von Databricks-Aufträgen, Databricks-Notebooks und Delta Live-Tabellen ausführen.
- Analysieren von unformatierten Dokumenten: Transformieren sie die Rohdaten in ein verwendbares Format. Wenn Sie beispielsweise Text, Tabellen und Bilder aus einer Sammlung von PDF-Dateien extrahieren oder optische Zeichenerkennungstechniken verwenden, um Text aus Bildern zu extrahieren.
- Extrahieren von Metadaten: Extrahieren Sie Dokumentmetadaten wie Dokumenttitel, Seitenzahlen und URLs, um die Abrufschrittabfrage genauer zu unterstützen.
- Abschnittsdokumente: Teilen Sie die Daten in Blöcke auf, die in das LLM-Kontextfenster passen. Durch das Abrufen dieser fokussierten Blöcke statt vollständiger Dokumente erhält der LLM gezieltere Inhalte, um Antworten zu generieren.
- Einbettungsblöcke – Ein Einbettungsmodell verwendet die Blöcke, um numerische Darstellungen der Informationen zu erstellen, die als Vektoreinbettungen bezeichnet werden. Vektoren stellen die semantische Bedeutung des Texts dar, nicht nur Schlüsselwörter auf Oberflächenebene. In diesem Szenario berechnen Sie die Einbettungen und verwenden Model Serving um das Einbettungsmodell zu bedienen.
- Einbettungsspeicher – Speichern Sie die Vektoreinbettungen und den Text des Blocks in einer Delta-Tabelle, die mit der Vektorsuche synchronisiert ist.
- Vektordatenbank – Im Rahmen der Vektorsuche werden Einbettungen und Metadaten indiziert und in einer Vektordatenbank gespeichert, um die Abfrage durch den RAG-Agent zu vereinfachen. Wenn ein Benutzer eine Abfrage sendet, wird seine Anforderung in einen Vektor eingebettet. Die Datenbank verwendet dann den Vektorindex, um die ähnlichsten Blöcke zu finden und zurückzugeben.
Jeder Schritt umfasst technische Entscheidungen, die sich auf die Qualität der RAG-Anwendung auswirken. Wenn Sie z. B. die richtige Blockgröße in Schritt (3) auswählen, wird sichergestellt, dass die LLM spezifische, aber kontextbezogene Informationen erhält, während beim Auswählen eines geeigneten Einbettungsmodells in Schritt (4) die Genauigkeit der während des Abrufs zurückgegebenen Blöcke bestimmt wird.
Databricks-Vektorsuche
Das Berechnen von Ähnlichkeiten ist oft rechenintensiv, aber Vektorindizes wie Databricks Vektorsuche optimieren dies durch effizientes Organisieren von Einbettungen. Vektorsuchen rangieren schnell die relevantesten Ergebnisse, ohne jede Einbettung einzeln mit der Abfrage des Benutzers zu vergleichen.
Die Vektorsuche synchronisiert automatisch neue Einbettungen, die Ihrer Delta-Tabelle hinzugefügt werden, und aktualisiert den Vektorsuchindex.
Was ist ein RAG-Agent?
Ein RAG-Agent (Retrieval Augmented Generation) ist ein wichtiger Bestandteil einer RAG-Anwendung, die die Funktionen großer Sprachmodelle (LLMs) durch die Integration externer Datenabrufe verbessert. Der RAG-Agent verarbeitet Benutzerabfragen, ruft relevante Daten aus einer Vektordatenbank ab und übergibt diese Daten an eine LLM, um eine Antwort zu generieren.
Tools wie LangChain oder Pyfunc verknüpfen diese Schritte, indem sie ihre Eingaben und Ausgaben verbinden.
Das folgende Diagramm zeigt einen RAG-Agent für einen Chatbot und die Databricks-Features, die zum Erstellen der einzelnen Agenten verwendet werden.
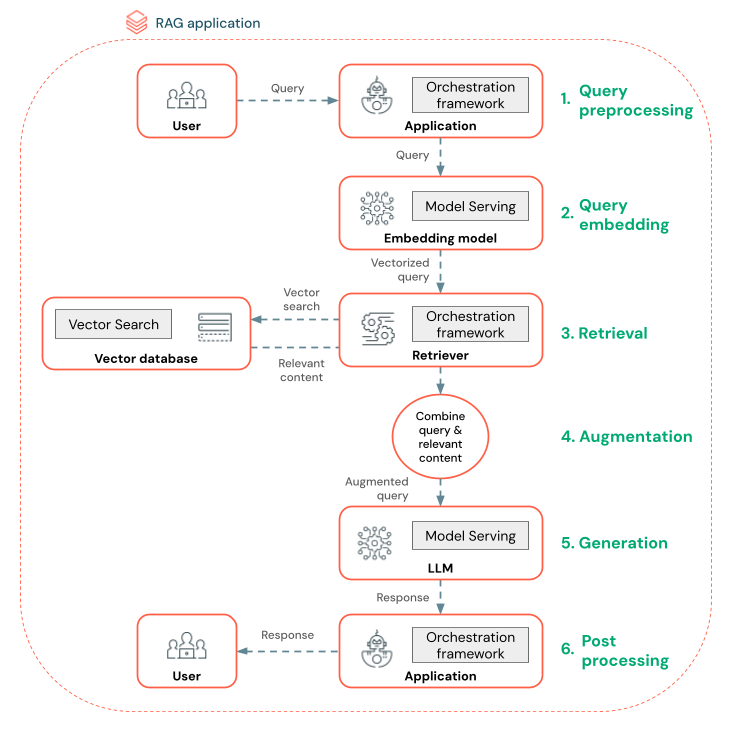
- Abfragevorverarbeitung – Ein Benutzer sendet eine Abfrage, die dann vorverarbeitet wird, um sie für die Abfrage der Vektordatenbank geeignet zu machen. Dies kann das Platzieren der Anforderung in eine Vorlage oder das Extrahieren von Schlüsselwörtern umfassen.
- Abfragevektorisierung – Verwenden Sie die Modellbereitstellung, um die Anforderung mithilfe des gleichen Einbettungsmodells einzubetten, das zum Einbetten der Blöcke in der Datenpipeline verwendet wird. Diese Einbettungen ermöglichen einen Vergleich der semantischen Ähnlichkeit zwischen der Anforderung und den vorverarbeiteten Blöcken.
- Abrufphase: Der Retriever, eine Anwendung, die für das Abrufen relevanter Informationen verantwortlich ist, übernimmt die vektorisierte Abfrage und führt eine Vektor-Ähnlichkeitssuche mithilfe der Vektorsuche aus. Die relevantesten Datenblöcke werden basierend auf ihrer Ähnlichkeit mit der Abfrage bewertet und abgerufen.
- Eingabeaufforderungserweiterung – Der Retriever kombiniert die abgerufenen Datenblöcke mit der ursprünglichen Abfrage, um zusätzlichen Kontext für die LLM bereitzustellen. Die Aufforderung ist sorgfältig strukturiert, um sicherzustellen, dass der LLM den Kontext der Abfrage versteht. Häufig verfügt das LLM über eine Vorlage zum Formatieren der Antwort. Dieser Prozess zum Anpassen der Eingabeaufforderung wird als Prompt Engineering bezeichnet.
- LLM-Generationsphase – Die LLM generiert eine Antwort mithilfe der erweiterten Abfrage, die durch die Abrufergebnisse erweitert wird. Das LLM kann ein benutzerdefiniertes Modell oder ein Foundation-Modell sein.
- Nachbearbeitung – Die Antwort des LLM kann verarbeitet werden, um zusätzliche Geschäftslogik anzuwenden, Zitate hinzuzufügen oder den generierten Text basierend auf vordefinierten Regeln oder Einschränkungen zu verfeinern
In diesem Prozess können verschiedene Schutzschienen angewendet werden, um die Einhaltung von Unternehmensrichtlinien sicherzustellen. Dies kann das Filtern nach geeigneten Anforderungen, das Überprüfen von Benutzerberechtigungen vor dem Zugriff auf Datenquellen und die Verwendung von Inhaltsmoderationstechniken für die generierten Antworten umfassen.
Entwicklung von RAG-Agenten auf Produktionsniveau
Schnelles Durchlaufen der Agententwicklung mithilfe der folgenden Features:
Erstellen und Protokollieren von Agents mithilfe einer beliebigen Bibliothek und eines MLflows. Parametrisieren Sie Ihre Agents, um schnell zu experimentieren und die Agententwicklung zu durchlaufen.
Stellen Sie Agents für die Produktion mit systemeigener Unterstützung für Tokenstreaming und Anforderungs-/Antwortprotokollierung sowie eine integrierte Prüf-App bereit, um Benutzerfeedback für Ihren Agent zu erhalten.
Mit der Agent-Ablaufverfolgung können Sie Ablaufverfolgungen in Ihrem Agentcode protokollieren, analysieren und vergleichen, um zu debuggen und zu verstehen, wie Ihr Agent auf Anforderungen reagiert.
Auswertung und Überwachung
Bewertung und Überwachung helfen ihnen zu ermitteln, ob Ihre RAG-Anwendung Ihre Qualitäts-, Kosten- und Latenzanforderungen erfüllt. Die Auswertung erfolgt während der Entwicklung, während die Überwachung erfolgt, sobald die Anwendung in der Produktion bereitgestellt wird.
RAG über unstrukturierte Daten verfügt über viele Komponenten, die sich auf die Qualität auswirken. Datenformatierungsänderungen können z. B. die abgerufenen Blöcke und die Fähigkeit der LLM zum Generieren relevanter Antworten beeinflussen. Daher ist es wichtig, einzelne Komponenten zusätzlich zur Gesamtanwendung zu bewerten.
Weitere Informationen finden Sie unter Was ist Auswertung von Mosaic AI Agent?.
Regionale Verfügbarkeit
Informationen zur regionalen Verfügbarkeit von Agent Framework finden Sie unter Features mit eingeschränkter regionaler Verfügbarkeit.